Recognition: no theorem link
Euclid Quick Data Release (Q1). AgileLens: A scalable CNN-based pipeline for strong gravitational lens identification
Pith reviewed 2026-05-10 18:36 UTC · model grok-4.3
The pith
An iterative CNN pipeline applied to Euclid Q1 imaging recovers 82 percent of known strong lenses and identifies 130 new high-grade candidates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
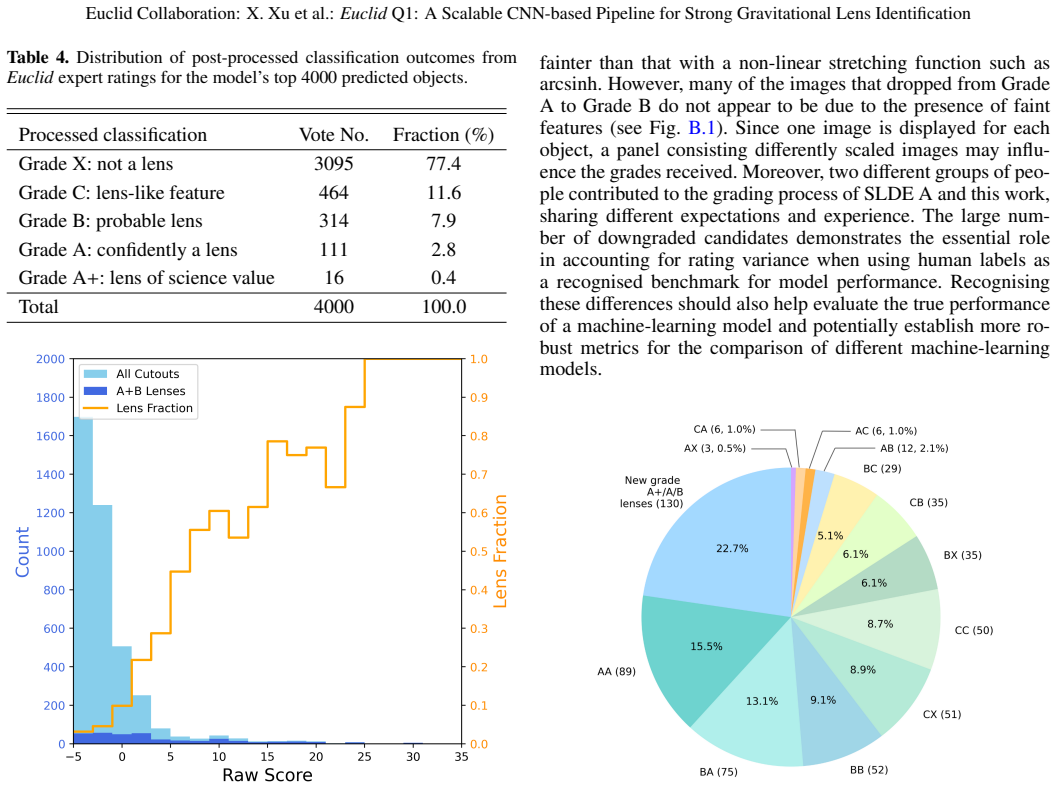
Starting from VIS catalogues, rejecting point sources, applying a magnitude cut at I_E ≤ 24, and constructing 96 × 96 pixel VIS+NISP colour composites, the authors train a modified VGG16 network whose training set grows iteratively from 1809 augmented positives and 2000 negatives to over 30,000 images; after three fine-tuning rounds the network ranks the full Q1 sample so that the top 4000 objects contain 441 Grade A/B lens candidates (311 already known plus 130 new) and recovers 740 of 905 known Q1 lenses inside the top 20,000 predictions.
What carries the argument
An iteratively fine-tuned modified VGG16 CNN (GlobalAveragePooling plus 256/128 dense layers, last nine layers trainable) that produces a scalar ranking score for each 96 × 96 pixel VIS+NISP cutout.
If this is right
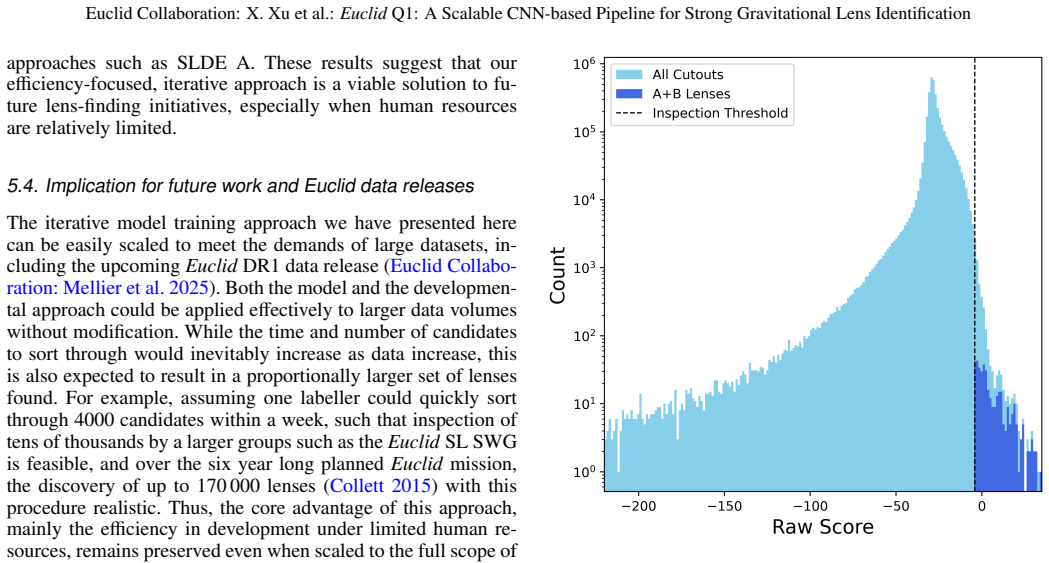
- The same iterative workflow can be rerun on future Euclid data releases with only one week of small-team effort per cycle.
- The 130 new candidates extend the known sample of massive early-type deflectors at I_E magnitudes 17–24.
- The 81.8 percent recall within the top 20,000 predictions shows that most known lenses remain detectable even when the training set begins small.
- Colour composites anchored on VIS morphology preserve the arc features that human graders use for final classification.
Where Pith is reading between the lines
- Adding lens-injection simulations would convert the current ranking scores into a calibrated selection function that quantifies completeness as a function of deflector magnitude and lens geometry.
- The same pipeline could incorporate uncertainty estimates from the CNN to prioritise objects for active-learning rounds that further reduce human review time.
- Combining the ranked list with fast automated lens modeling as a post-hoc vetter would move the workflow closer to fully automated confirmation of new systems.
- The observed preference for redder Y_E–H_E colours among candidates suggests the method is already biased toward the massive early-type population expected to dominate strong-lensing statistics.
Load-bearing premise
The iteratively trained CNN generalizes from a few dozen seed lenses to the full Q1 catalogue without flooding the top ranks with false positives, and human visual grading of those top candidates accurately separates real lenses from impostors.
What would settle it
A spectroscopic or high-resolution imaging follow-up campaign that measures the true lensing fraction among a random subset of the 130 newly reported Grade A/B candidates; a confirmation rate well below the purity implied by the Grade A/B labels would falsify the pipeline's claimed reliability.
Figures










read the original abstract
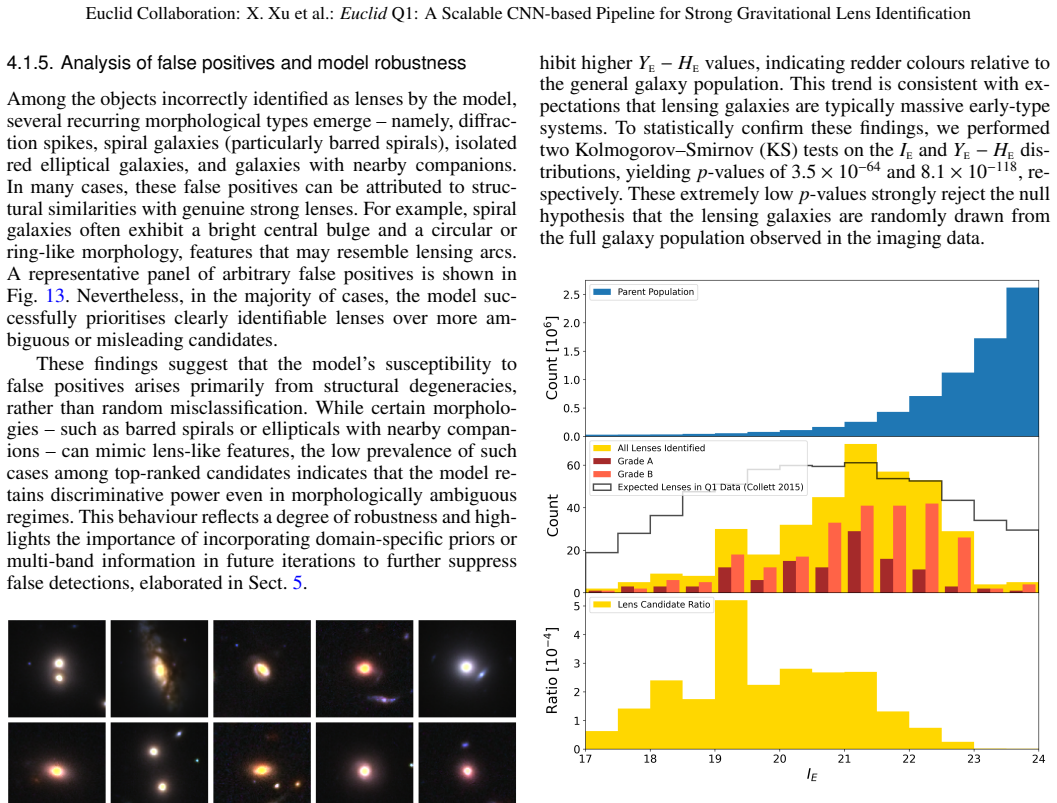
We present an end-to-end, iterative pipeline for efficient identification of strong galaxy--galaxy lensing systems, applied to the Euclid Q1 imaging data. Starting from VIS catalogues, we reject point sources, apply a magnitude cut (I$_E$ $\leq$ 24) on deflectors, and run a pixel-level artefact/noise filter to build 96 $\times$ 96 pix cutouts; VIS+NISP colour composites are constructed with a VIS-anchored luminance scheme that preserves VIS morphology and NISP colour contrast. A VIS-only seed classifier supplies clear positives and typical impostors, from which we curate a morphology-balanced negative set and augment scarce positives. Among the six CNNs studied initially, a modified VGG16 (GlobalAveragePooling + 256/128 dense layers with the last nine layers trainable) performs best; the training set grows from 27 seed lenses (augmented to 1809) plus 2000 negatives to a colour dataset of 30,686 images. After three rounds of iterative fine-tuning, human grading of the top 4000 candidates ranked by the final model yields 441 Grade A/B candidate lensing systems, including 311 overlapping with the existing Q1 strong-lens catalogue, and 130 additional A/B candidates (9 As and 121 Bs) not previously reported. Independently, the model recovers 740 out of 905 (81.8%) candidate Q1 lenses within its top 20,000 predictions, considering off-centred samples. Candidates span I$_E$ $\simeq$ 17--24 AB mag (median 21.3 AB mag) and are redder in Y$_E$--H$_E$ than the parent population, consistent with massive early-type deflectors. Each training iteration required a week for a small team, and the approach easily scales to future Euclid releases; future work will calibrate the selection function via lens injection, extend recall through uncertainty-aware active learning, explore multi-scale or attention-based neural networks with fast post-hoc vetters that incorporate lens models into the classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AgileLens, an end-to-end iterative CNN pipeline for strong galaxy-galaxy lens identification in Euclid Q1 VIS+NISP imaging. It begins with VIS catalogue cuts (point-source rejection, I_E ≤ 24, artefact filtering) to produce 96×96 pixel cutouts and VIS-anchored colour composites, trains a modified VGG16 (GlobalAveragePooling + 256/128 dense layers, last nine layers trainable) on an augmented set grown from 27 seeds to 30,686 images over three fine-tuning rounds, and reports 441 Grade A/B candidates from human grading of the top 4000 ranked predictions (311 overlapping the existing Q1 catalogue plus 130 new systems) together with an 81.8 % recovery of 740/905 known candidates inside the top 20 000 predictions.
Significance. If the purity of the new sample can be demonstrated, the work supplies a practical, computationally lightweight template for scaling lens searches to the full Euclid dataset and future wide-field surveys. The reported recovery rate on an independent catalogue and the explicit scaling statement (one week per iteration for a small team) are concrete strengths that would be useful to the community even if the absolute number of new lenses requires further vetting.
major comments (3)
- [Abstract / Results (human grading paragraph)] Abstract and results section on final candidate selection: the headline claim of 130 new A/B systems rests entirely on human visual grading of the top 4000 cutouts, yet no inter-rater reliability statistic (Cohen’s κ, Fleiss’ κ, or equivalent) or blind test against confirmed non-lenses is reported; without these the false-positive rate at the adopted threshold remains unknown and directly affects the reliability of the 130 new discoveries.
- [Methods (iterative fine-tuning subsection)] Methods and iterative-training description: the training loop re-uses the same human graders both to label new positives and to curate negatives across rounds; this creates a potential self-reinforcing bias that is not quantified by any held-out blind test set or cross-validation against an independent lens catalogue beyond the recovery statistic.
- [Results / Discussion (future-work paragraph)] Results and discussion: no lens-injection recovery test or purity estimate is supplied at the operating point used to select the top 4000 candidates, so the 81.8 % recall on known lenses cannot be translated into an expected contamination fraction for the 130 new systems; this is load-bearing for any claim that the new sample is scientifically usable without further vetting.
minor comments (3)
- [Methods (data-preparation paragraph)] The description of the VIS-anchored luminance scheme for colour composites is clear in principle but would benefit from an explicit figure or equation showing how the NISP bands are scaled relative to VIS.
- [Methods (CNN comparison)] Table or supplementary material listing the exact layer counts, learning-rate schedule, and augmentation parameters for each of the six initial CNN architectures would allow readers to reproduce the model-selection step.
- [Results (candidate properties)] The magnitude range and colour properties of the new candidates are stated; adding a simple histogram or cumulative distribution comparing them to the parent Q1 population would strengthen the consistency argument.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript on the AgileLens pipeline. We have addressed each major comment point by point below, providing clarifications and indicating revisions made to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results (human grading paragraph)] Abstract and results section on final candidate selection: the headline claim of 130 new A/B systems rests entirely on human visual grading of the top 4000 cutouts, yet no inter-rater reliability statistic (Cohen’s κ, Fleiss’ κ, or equivalent) or blind test against confirmed non-lenses is reported; without these the false-positive rate at the adopted threshold remains unknown and directly affects the reliability of the 130 new discoveries.
Authors: We agree that formal inter-rater reliability metrics and a dedicated blind test would provide additional quantitative support for the human grading results. The original submission described the grading only briefly. In the revised manuscript we have expanded the relevant results paragraph to detail the grading protocol: cutouts were reviewed independently by two experienced strong-lensing researchers, with a third grader consulted on any disagreements, and all Grade A/B assignments required consensus. We have also added an explicit limitations statement noting that a pre-planned blind test against confirmed non-lenses was not performed for this Q1 demonstration and that the false-positive rate is therefore not statistically quantified. The 130 new systems are now presented more clearly as expert-vetted candidates requiring spectroscopic follow-up, consistent with standard practice in lens searches. We view this as a partial but substantive improvement. revision: partial
-
Referee: [Methods (iterative fine-tuning subsection)] Methods and iterative-training description: the training loop re-uses the same human graders both to label new positives and to curate negatives across rounds; this creates a potential self-reinforcing bias that is not quantified by any held-out blind test set or cross-validation against an independent lens catalogue beyond the recovery statistic.
Authors: This is a legitimate methodological concern for any iterative human-in-the-loop approach. The initial positive seeds were generated by an independent VIS-only classifier that was not part of the iterative loop, and the negative set was deliberately balanced to include common contaminants (spirals, mergers, artefacts) identified from the parent catalogue. The principal external check remains the 81.8 % recovery of the full Q1 lens catalogue, which was never used for training or grading at any stage. In the revised methods section we have clarified these design choices and added a short discussion of the residual grader-bias risk, together with the mitigation steps already taken. We have not performed an additional held-out blind test beyond the existing recovery statistic, as that would require new data collection outside the scope of the current Q1 analysis. revision: partial
-
Referee: [Results / Discussion (future-work paragraph)] Results and discussion: no lens-injection recovery test or purity estimate is supplied at the operating point used to select the top 4000 candidates, so the 81.8 % recall on known lenses cannot be translated into an expected contamination fraction for the 130 new systems; this is load-bearing for any claim that the new sample is scientifically usable without further vetting.
Authors: We concur that a lens-injection test at the precise operating point would enable a direct purity estimate and that the recall figure alone does not fully constrain contamination in the new sample. Such a test was not feasible within the resource envelope of this initial Q1 demonstration, whose focus was pipeline scalability and candidate discovery. In the revised discussion we have strengthened the caveats, explicitly stating that the 130 new Grade A/B systems are candidates identified by the pipeline and human vetting and should be regarded as requiring further confirmation before scientific use. We have also expanded the future-work paragraph to prioritise lens-injection simulations for selection-function calibration in subsequent Euclid releases, as already foreshadowed in the original text. The reported recall on the independent catalogue and the human grading together provide the current basis for the candidate list. revision: yes
Circularity Check
No circularity: empirical pipeline relies on external human grading and independent catalog comparison
full rationale
The paper presents an iterative CNN training pipeline starting from 27 seed lenses, augmented and refined over three rounds using human grading of top-ranked candidates. The central claims (441 Grade A/B systems including 130 new ones, and 81.8% recovery of the existing 905-candidate catalog) are produced by direct human visual inspection of the model's output rankings and by overlap counting against a pre-existing external catalog. No equations, fitted parameters, or self-citations reduce the reported counts to the inputs by construction; the human grading step and catalog comparison are independent of the model training loop. No self-definitional, fitted-prediction, or uniqueness-theorem patterns appear.
Axiom & Free-Parameter Ledger
free parameters (3)
- magnitude cut I_E <= 24
- cutout size 96x96 pixels
- number of trainable layers and dense-layer sizes in modified VGG16
axioms (2)
- domain assumption Human visual grading of top-ranked candidates provides reliable ground truth for true versus false lenses
- ad hoc to paper Augmented seed lenses plus curated negatives represent the statistical distribution of real lenses and impostors in Q1 data
Forward citations
Cited by 1 Pith paper
-
\textit{Euclid} preparation. Baryon acoustic oscillations extraction techniques: comparison and optimisation
End-to-end validation on Euclid-like mocks shows RecSym and RecIso reconstruction yield unbiased BAO measurements, improving figure of merit for Omega_m and H0 rs by factor of ~3 across 0.9<z<1.8.
Reference graph
Works this paper leans on
-
[1]
Acevedo Barroso, J. A., Clément, B., Courbin, F., et al. 2026, A&A, 706, A146 Acevedo Barroso, J. A., O’Riordan, C. M., Clément, B., et al. 2025, A&A, 697, A14 Aihara, H., Arimoto, N., Armstrong, R., et al. 2018, PASJ, 70, S4 Bolton, A. S., Burles, S., Koopmans, L. V . E., Treu, T., & Moustakas, L. A. 2006, ApJ, 638, 703 Bottrell, C., Hani, M. H., Teimoor...
-
[2]
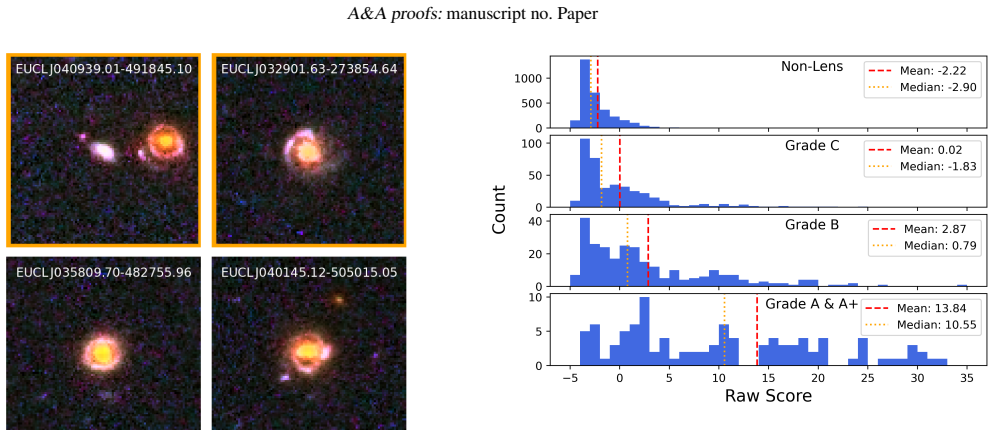
The 441 includes 74 additional candidates that received AC, BC, AX and BX union grades. These candidates are shown in Fig. B.1. Article number, page 21 of 30 A&A proofs:manuscript no. Paper (a) (b) (c) Fig. B.1.Centred lens candidates that received lower grades in this work compared with SLDE A. Panel (a) displays objects that received Grade A in SLDE A b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.