Continuous Knowledge Metabolism: Generating Scientific Hypotheses from Evolving Literature
Pith reviewed 2026-05-10 16:23 UTC · model grok-4.3
The pith
Processing scientific literature in sliding time windows with incremental updates generates better and cheaper hypotheses than batch analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CKM processes literature through sliding time windows to incrementally update a structured knowledge base, allowing hypothesis generation to condition on the trajectory of knowledge changes rather than a static snapshot. CKM-Lite demonstrates superior performance over batch methods in hit rate, hypothesis yield, alignment, and efficiency. CKM-Full further shows that incremental processing outperforms batch, change-aware methods increase novelty but reduce coverage, field stability correlates with success, and convergence signals predict higher hit rates than contradictions.
What carries the argument
Sliding time window processing for incremental knowledge base updates, together with LLM categorization of each new finding as novel, confirming, or contradicting to condition hypothesis generation on the detected evolution trajectory.
Load-bearing premise
That an LLM can categorize new findings as novel, confirming, or contradicting in a manner that faithfully reflects real scientific knowledge dynamics without systematic bias from its training data or judgment process.
What would settle it
If a batch system run on the same sequence of papers achieves equal or higher hit rates, hypothesis yields, and best-match alignment scores than CKM-Lite while using comparable tokens, the claimed advantage of incremental accumulation collapses.
Figures


read the original abstract
Identifying promising research directions in fast-moving subareas is one of the most cognitively expensive tasks in modern AI research. Existing LLM-driven scientific discovery systems are typically limited to one-shot prompting on static literature snapshots and are validated only against contemporary judges such as human reviewers, agent peer review, wet-lab assays, or self-evaluation, leaving open whether they can anticipate future trends. We present Continuous Knowledge Metabolism (CKM), an AI workflow for hypothesis generation with three key capabilities: (i) continuous literature metabolism via sliding windows that maintain an evolving knowledge state; (ii) predictive evaluation, which grades hypotheses against papers published after the generation window; and (iii) practitioner-grade failure detection that diagnoses workflow failure modes from its outputs. On a 50-topic machine learning benchmark, CKM-Lite produces at least one validated hypothesis on 72% of topics (36 out of 50), more than doubling a one-shot baseline (30%) at approximately 3 dollars per topic and achieving 91% lower token cost. Validated hypotheses precede their matched papers by an average of 404 days (55 hits across 36 topics; median 399 days, range 66-757 days). Broadly, predictive validation against future literature provides a falsifiable, low-cost alternative to contemporary-judge evaluation protocols and can be applied wherever a corpus has dated publication records.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
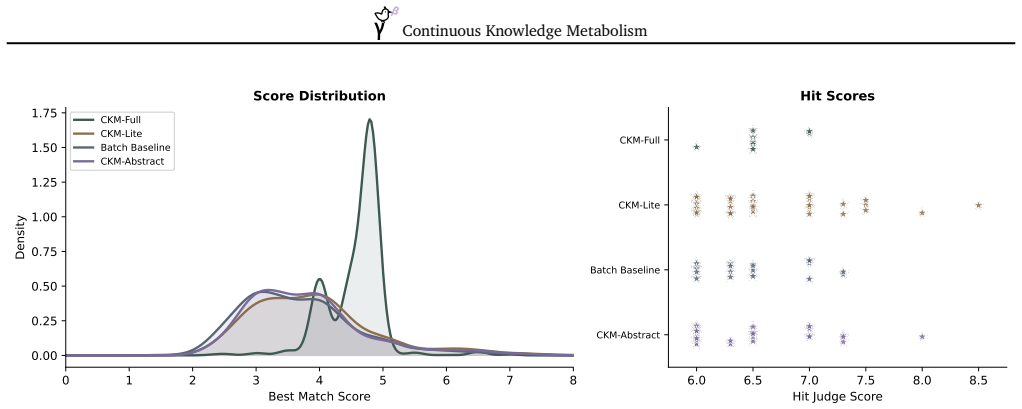
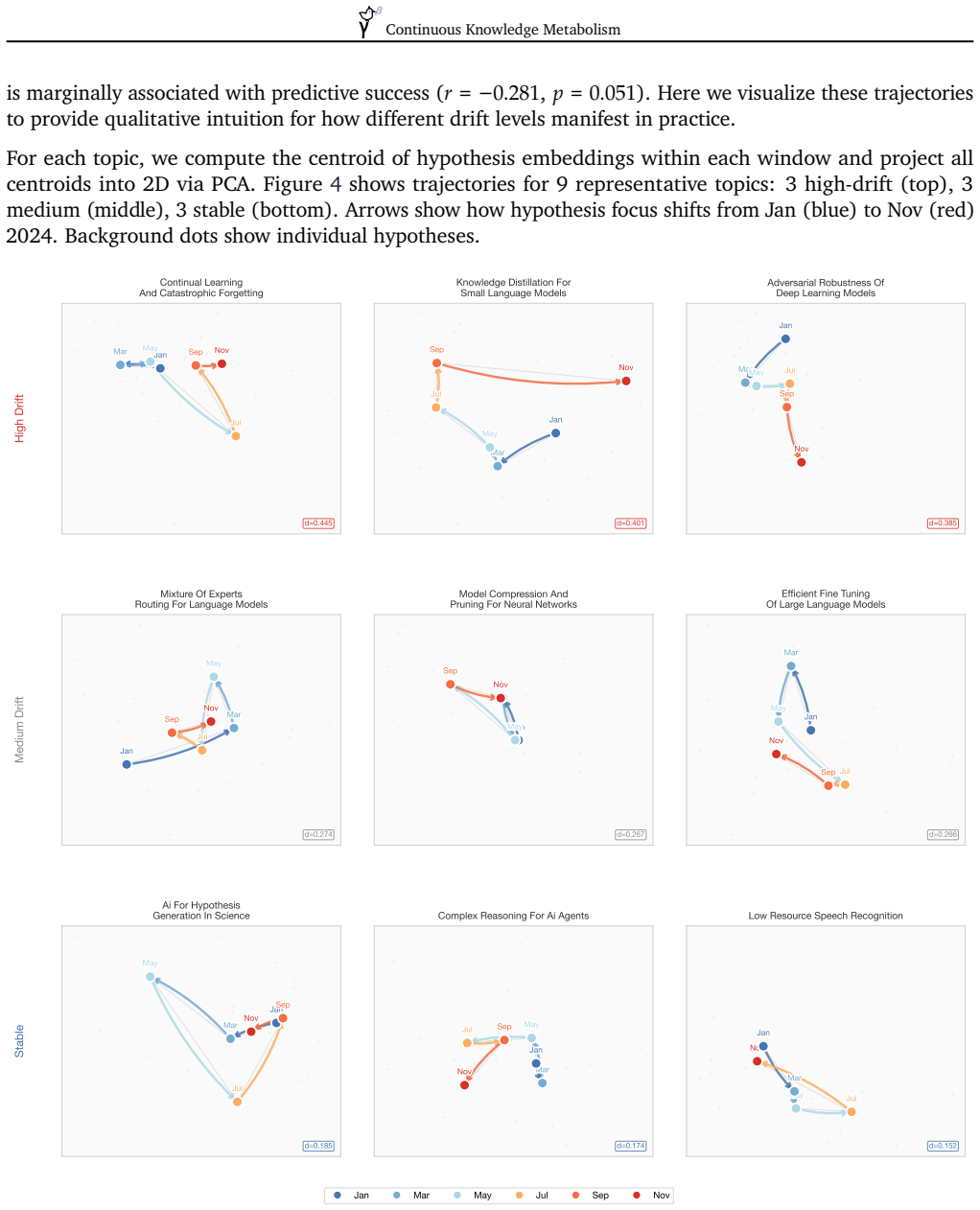
Summary. The paper introduces Continuous Knowledge Metabolism (CKM), a framework that processes scientific literature via sliding time windows to incrementally update a structured knowledge base for hypothesis generation. It evaluates CKM-Lite (efficient incremental variant) against batch processing, reporting gains in hit rate (+2.8%, p=0.006), hypothesis yield (+3.6, p<0.001), best-match alignment (+0.43, p<0.001), and 92% token cost reduction. CKM-Full adds instrumentation for categorizing findings as novel/confirming/contradicting and conditioning on evolution trajectories, yielding four observations from 892 hypotheses across 50 topics: incremental superiority, a quality-coverage trade-off (higher novelty but lower coverage with change-awareness), trajectory stability correlation (r=-0.28), and 5x higher hit rates for convergence vs. contradiction signals.
Significance. If the quantitative results hold under unbiased evaluation, the work provides evidence that incremental accumulation and change-signal conditioning can improve efficiency and predictive coverage in literature-based hypothesis generation compared to batch methods. The scale of the experiment (892 hypotheses, 50 topics, statistical reporting) and identification of a quality-coverage trade-off represent concrete contributions to automated scientific discovery, with potential to guide design of dynamic knowledge systems. The differential predictability by change type is a falsifiable observation worth further testing.
major comments (3)
- [§4] §4 (Experimental results on 892 hypotheses): Hit rate and best-match alignment are computed via LLM judgments or embedding similarity to future papers, the same mechanism used for novelty scoring (Cohen's d=3.46) and change categorization. This risks systematic bias favoring CKM-Lite's incremental outputs due to stylistic consistency with the evaluator model, while batch outputs may be under-scored; no independent human validation or objective held-out metric is described, directly undermining the central claim of +2.8% hit rate and +0.43 alignment gains.
- [§3.2] §3.2 (CKM-Full instrumentation): Conditioning hypothesis generation on LLM-categorized evolution trajectories (novel/confirming/contradicting) creates potential circularity, as the same model family performs both categorization and generation. This could artifactually inflate the reported novelty advantage and the 5x hit-rate difference between convergence and contradiction signals, rather than reflecting genuine knowledge dynamics.
- [Results] Results paragraph on trajectory stability: The reported correlation (r=-0.28, p=0.051) between field stability and hypothesis success is marginal and presented as an association without correction for multiple comparisons or sensitivity analysis; this weakens the boundary-condition claim and requires explicit qualification or additional controls to support the four empirical observations.
minor comments (2)
- [Abstract] Abstract and §4: The exact statistical tests, sample sizes per comparison, and any multiple-testing corrections for the reported p-values are not detailed; these should be added to the methods for reproducibility.
- [Notation] Notation throughout: A comparison table explicitly listing the components, parameters, and differences among CKM, CKM-Lite, and CKM-Full would clarify the variants for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and outline revisions that will strengthen the manuscript while preserving its core contributions.
read point-by-point responses
-
Referee: [§4] §4 (Experimental results on 892 hypotheses): Hit rate and best-match alignment are computed via LLM judgments or embedding similarity to future papers, the same mechanism used for novelty scoring (Cohen's d=3.46) and change categorization. This risks systematic bias favoring CKM-Lite's incremental outputs due to stylistic consistency with the evaluator model, while batch outputs may be under-scored; no independent human validation or objective held-out metric is described, directly undermining the central claim of +2.8% hit rate and +0.43 alignment gains.
Authors: We agree that LLM-based evaluation introduces a risk of stylistic bias. Because the identical protocol is applied uniformly to CKM-Lite, batch, and CKM-Full outputs, relative differences remain informative, but we accept that absolute claims would benefit from independent validation. In the revised manuscript we will add a human evaluation on a random sample of 100 hypotheses (with inter-annotator agreement reported) to corroborate the LLM judgments and embedding similarities. revision: yes
-
Referee: [§3.2] §3.2 (CKM-Full instrumentation): Conditioning hypothesis generation on LLM-categorized evolution trajectories (novel/confirming/contradicting) creates potential circularity, as the same model family performs both categorization and generation. This could artifactually inflate the reported novelty advantage and the 5x hit-rate difference between convergence and contradiction signals, rather than reflecting genuine knowledge dynamics.
Authors: This is a legitimate concern about circularity. We will revise the methods section to use a separate model family for the change-categorization step in CKM-Full, re-run the 892-hypothesis analysis, and report the resulting novelty and hit-rate differences to confirm robustness. revision: yes
-
Referee: [Results] Results paragraph on trajectory stability: The reported correlation (r=-0.28, p=0.051) between field stability and hypothesis success is marginal and presented as an association without correction for multiple comparisons or sensitivity analysis; this weakens the boundary-condition claim and requires explicit qualification or additional controls to support the four empirical observations.
Authors: We concur that p=0.051 is marginal and that multiple-comparison correction is warranted. The revised manuscript will present this result as exploratory, apply Bonferroni correction across the four observations, include a sensitivity analysis, and qualify the boundary-condition claim accordingly. revision: yes
Circularity Check
No significant circularity; empirical metrics anchored externally
full rationale
The paper's central claims rest on empirical comparisons of CKM-Lite against batch baselines using hit rate, hypothesis yield, and best-match alignment, all defined by reference to actual later literature findings rather than internal parameters or self-referential definitions. No equations, fitted inputs renamed as predictions, or self-citation chains appear in the provided text as load-bearing for the results. LLM judgments are used for both generation and evaluation, but the metrics remain externally falsifiable against held-out future papers and are applied uniformly across conditions, satisfying the criteria for independent support. The four reported observations are statistical associations from 892 generated hypotheses, not derivations that reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scientific knowledge evolves continuously and can be modeled effectively using sliding time windows for incremental updates to a structured knowledge base.
invented entities (3)
-
Continuous Knowledge Metabolism (CKM)
no independent evidence
-
CKM-Lite
no independent evidence
-
CKM-Full
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Equilibrium Gibbs Bifurcations of Bardeen-AdS Black Holes at Fixed Pressure
Bardeen-AdS black holes at fixed pressure show an intermediate Gibbs curve sequence between RN-AdS swallow-tails and single branches, with the three topology boundaries controlled by the combination 8πPg².
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.