Recognition: unknown
CGC: Compositional Grounded Contrast for Fine-Grained Multi-Image Understanding
Pith reviewed 2026-05-08 12:22 UTC · model grok-4.3
The pith
Compositional Grounded Contrast improves fine-grained multi-image understanding in multimodal models by building contrastive examples from single-image annotations plus spatial rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
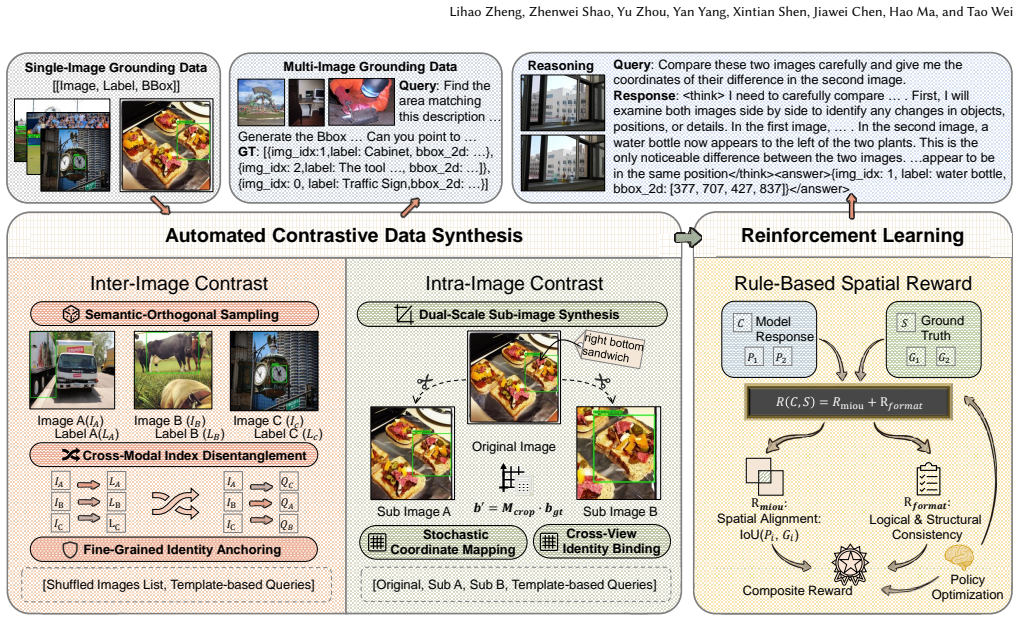
CGC constructs compositional multi-image training instances through Inter-Image Contrast, which introduces semantically decoupled distractor contexts for cross-image discrimination, and Intra-Image Contrast, which supplies correlated cross-view samples for object constancy. It further adds a Rule-Based Spatial Reward inside the GRPO framework to enforce source-image attribution, spatial alignment, and valid structured output under a Think-before-Grounding paradigm. This combination, built entirely on existing single-image grounding annotations, yields state-of-the-art results on fine-grained multi-image benchmarks including MIG-Bench and VLM2-Bench and produces consistent gains when the same
What carries the argument
Compositional Grounded Contrast framework that generates multi-image training data from single-image grounding annotations via inter-image and intra-image contrasts, paired with a rule-based spatial reward inside GRPO.
If this is right
- State-of-the-art results on MIG-Bench and VLM2-Bench for fine-grained multi-image understanding.
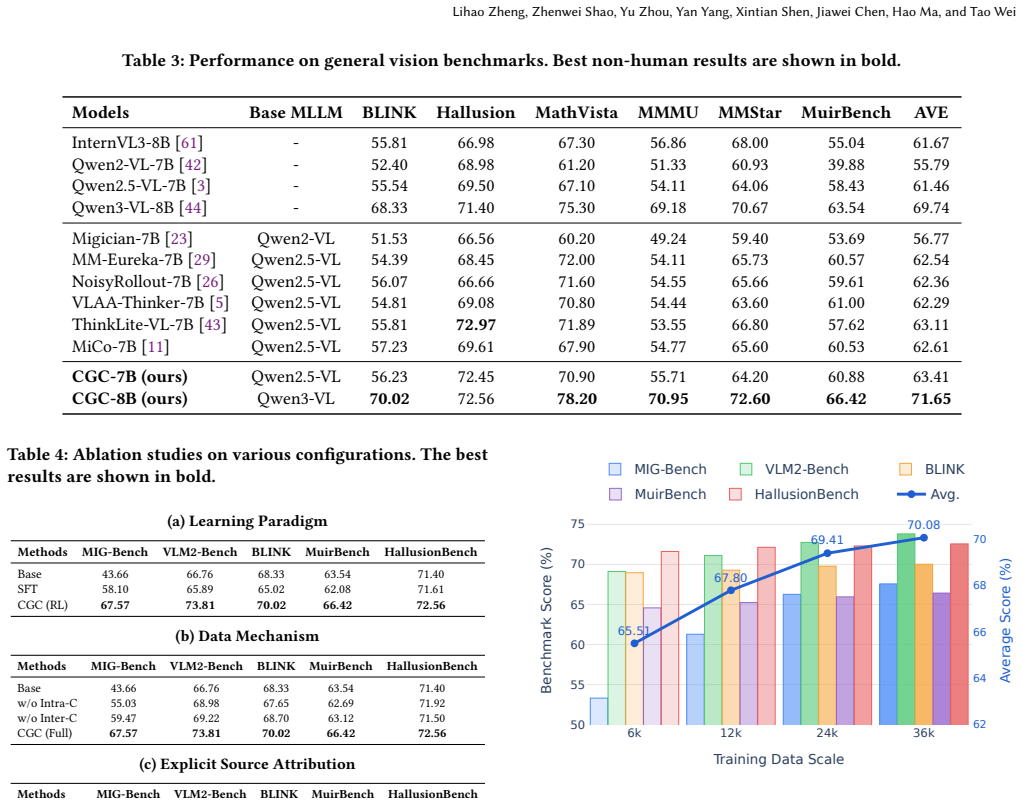
- Transfer gains of 2.90 on MathVista, 2.88 on MuirBench, 1.93 on MMStar, 1.77 on MMMU, and 1.69 on BLINK over the Qwen3-VL-8B base model.
- Reduced need for expensive human multi-image annotations or large-scale chain-of-thought data.
- Improved source-image attribution, spatial alignment, and structured output validity.
Where Pith is reading between the lines
- The method could substantially lower the cost of scaling multi-image capabilities by recycling existing single-image grounding datasets.
- Similar contrast constructions might help with consistency problems in video or 3D scene understanding where object identity across frames matters.
- The rule-based spatial reward could be ported to other reinforcement-learning setups that train models to cite evidence from visual inputs.
- If the approach generalizes, it suggests that many grounding failures in multimodal models stem from missing contrastive signals rather than from insufficient model capacity.
Load-bearing premise
That contrastive data built from single-image annotations plus the spatial reward is sufficient to correct spatial hallucination, attention leakage, and object constancy failures without creating new biases or requiring extensive tuning.
What would settle it
An evaluation set of multi-image questions where distractors are deliberately chosen to violate the semantic decoupling or object-constancy assumptions used in training, then checking whether accuracy gains over the base model disappear.
Figures








read the original abstract
Although Multimodal Large Language Models (MLLMs) have advanced rapidly, they still face notable challenges in fine-grained multi-image understanding, often exhibiting spatial hallucination, attention leakage, and failures in object constancy. In addition, existing approaches typically rely on expensive human annotations or large-scale chain-of-thought (CoT) data generation. We propose Compositional Grounded Contrast (abbr. CGC), a low-cost full framework for boosting fine-grained multi-image understanding of MLLMs. Built on existing single-image grounding annotations, CGC constructs compositional multi-image training instances through Inter-Image Contrast and Intra-Image Contrast, which introduce semantically decoupled distractor contexts for cross-image discrimination and correlated cross-view samples for object constancy, respectively. CGC further introduces a Rule-Based Spatial Reward within the GRPO framework to improve source-image attribution, spatial alignment, and structured output validity under a Think-before-Grounding paradigm. Experiments show that CGC achieves state-of-the-art results on fine-grained multi-image benchmarks, including MIG-Bench and VLM2-Bench. The learned multi-image understanding capability also transfers to broader multimodal understanding and reasoning tasks, yielding consistent gains over the Qwen3-VL-8B base model on MathVista (+2.90), MuirBench (+2.88), MMStar (+1.93), MMMU (+1.77), and BLINK (+1.69).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Compositional Grounded Contrast (CGC), a low-cost framework that builds compositional multi-image training instances from existing single-image grounding annotations via Inter-Image Contrast (semantically decoupled distractors) and Intra-Image Contrast (correlated cross-view samples), augmented by a Rule-Based Spatial Reward inside the GRPO optimization under a Think-before-Grounding paradigm. It reports state-of-the-art results on fine-grained multi-image benchmarks (MIG-Bench, VLM2-Bench) and consistent transfer gains over Qwen3-VL-8B on MathVista (+2.90), MuirBench (+2.88), MMStar (+1.93), MMMU (+1.77), and BLINK (+1.69).
Significance. If the reported gains prove robust under controlled evaluation, CGC would demonstrate an efficient way to leverage single-image annotations for multi-image spatial and compositional reasoning without expensive new data collection or CoT generation. The integration of rule-based rewards with GRPO is a concrete strength that could generalize to other grounding tasks.
major comments (2)
- [§3] §3 (Method): The central claim that Inter-Image Contrast and Intra-Image Contrast constructions, together with the Rule-Based Spatial Reward, jointly resolve spatial hallucination, attention leakage, and object constancy rests on the unverified assumption that simple composition from single-image annotations preserves fine-grained relations and avoids new leakage or bias. No explicit verification, semantic-decoupling metrics, or failure-mode-targeted ablations are described to confirm the generated instances actually test the targeted weaknesses rather than reinforce base-model errors.
- [§5] §5 (Experiments): The abstract states SOTA performance and specific transfer deltas, yet provides no details on experimental controls, baseline implementations, statistical significance testing, or post-hoc selection safeguards. This absence makes it impossible to assess whether the gains are attributable to the proposed components or to uncontrolled factors, directly undermining evaluation of the load-bearing performance claims.
minor comments (2)
- [§3.3] Notation for the GRPO reward components and the Think-before-Grounding paradigm could be formalized with explicit equations to improve reproducibility.
- [Figure 2] Figure captions for the contrast construction diagrams should explicitly label the source annotations and distractor selection heuristics.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing honest responses and committing to revisions that strengthen the manuscript without overstating our current results.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central claim that Inter-Image Contrast and Intra-Image Contrast constructions, together with the Rule-Based Spatial Reward, jointly resolve spatial hallucination, attention leakage, and object constancy rests on the unverified assumption that simple composition from single-image annotations preserves fine-grained relations and avoids new leakage or bias. No explicit verification, semantic-decoupling metrics, or failure-mode-targeted ablations are described to confirm the generated instances actually test the targeted weaknesses rather than reinforce base-model errors.
Authors: We agree that the manuscript would benefit from explicit verification of the contrast constructions. While the Inter-Image Contrast and Intra-Image Contrast are designed to introduce semantically decoupled distractors and correlated cross-view samples respectively, the original submission did not include quantitative semantic-decoupling metrics or failure-mode ablations. In the revised version, we will add (1) semantic-decoupling metrics such as average CLIP embedding cosine similarity between source and distractor images in inter-image pairs, and (2) targeted ablations measuring reduction in spatial hallucination and attention leakage on held-out failure cases. These additions will directly test whether the generated instances address the intended weaknesses. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract states SOTA performance and specific transfer deltas, yet provides no details on experimental controls, baseline implementations, statistical significance testing, or post-hoc selection safeguards. This absence makes it impossible to assess whether the gains are attributable to the proposed components or to uncontrolled factors, directly undermining evaluation of the load-bearing performance claims.
Authors: We acknowledge that the current experimental section lacks the requested details on controls and statistical rigor. In the revision, we will expand §5 and the appendix to include: full specifications of baseline reproduction (including exact prompts, decoding parameters, and checkpoint versions), results across multiple random seeds with standard deviations and significance tests (e.g., paired t-tests), and explicit discussion of safeguards against post-hoc selection. These changes will allow clearer attribution of gains to the CGC components. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes CGC as a compositional construction of multi-image training instances (Inter-Image Contrast and Intra-Image Contrast) directly from existing single-image grounding annotations, combined with a Rule-Based Spatial Reward inside the GRPO framework under a Think-before-Grounding paradigm. All reported gains (SOTA on MIG-Bench/VLM2-Bench and transfer improvements on MathVista etc.) are presented as outcomes of empirical experiments rather than mathematical predictions or quantities defined by the method's own fitted parameters. No self-definitional equations, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatzes that reduce the central claims to the inputs by construction appear in the abstract or method description. The approach builds on established contrastive and RL techniques without internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing single-image grounding annotations can be repurposed to construct effective compositional multi-image training instances that mitigate spatial hallucination and object constancy issues
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. 2025. V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning.arXiv e-prints(2025), arXiv–2506
2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review arXiv 2025
-
[4]
Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, and Xiaodan Liang
- [5]
- [6]
- [7]
-
[8]
Jiawei Chen, Xintian Shen, Lihao Zheng, Lifu Mu, Haoyi Sun, Ning Mao, Hao Ma, Tao Wei, Pan Zhou, and Kun Zhan. 2026. Evaluating the Search Agent in a Parallel World.arXiv preprint arXiv:2603.04751(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [9]
-
[10]
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao
-
[11]
Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195(2023)
work page internal anchor Pith review arXiv 2023
-
[12]
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Shengyi Qian, Jianing Yang, David F Fouhey, and Joyce Chai. 2024. Multi-object hallucination in vision language models. InProceedings of the 38th International Conference on Neural Information Processing Systems. 44393–44418
2024
- [13]
-
[14]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al . 2024. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review arXiv 2024
-
[15]
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang
- [16]
-
[17]
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. 2024. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision. Springer, 148–166
2024
- [18]
-
[19]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. 2024. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InCVPR
2024
-
[20]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review arXiv 2025
-
[21]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. 2025. Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models. arXiv:2503.06749 [cs.CV] https://arxiv.org/abs/2503.06749
work page internal anchor Pith review arXiv 2025
- [22]
-
[23]
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. 2024. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9579–9589
2024
-
[24]
Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela, et al. 2023. Obelics: An open web-scale filtered dataset of interleaved image-text documents.Advances in Neural Information Processing Systems36 (2023), 71683–71702
2023
-
[25]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326(2024)
work page internal anchor Pith review arXiv 2024
- [26]
-
[27]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
- [28]
- [29]
-
[30]
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. 2025. Visual-rft: Visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785(2025)
work page internal anchor Pith review arXiv 2025
- [31]
-
[32]
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. 2025. MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning.arXiv preprint arXiv:2503.07365(2025)
work page Pith review arXiv 2025
- [33]
- [34]
-
[35]
Sungjune Park, Hyunjun Kim, Junho Kim, Seongho Kim, and Yong Man Ro
- [36]
- [37]
-
[38]
Khoi Pham, Kushal Kafle, Zhe Lin, Zhihong Ding, Scott Cohen, Quan Tran, and Abhinav Shrivastava. 2021. Learning to predict visual attributes in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 13018–13028
2021
-
[39]
Tingrui Qiao, Di Zhao, Yuzhuo Li, Bo Pang, Caroline Walker, Chris W Cunning- ham, and Yun Sing Koh. [n. d.]. Multiple Images Distract Large Multimodal Models via Attention Fragmentation. ([n. d.])
-
[40]
Samuel Schulter, Yumin Suh, Konstantinos M Dafnis, Zhixing Zhang, Shiyu Zhao, Dimitris Metaxas, et al. 2023. Omnilabel: A challenging benchmark for language-based object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision. 11953–11962
2023
-
[41]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al . 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review arXiv 2024
-
[42]
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. 2025. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615(2025)
work page internal anchor Pith review arXiv 2025
-
[43]
Xintian Shen, Jiawei Chen, Lihao Zheng, Hao Ma, Tao Wei, and Kun Zhan
- [44]
-
[45]
OpenGVLab Team. 2024. Internvl2: Better than the best—expanding performance boundaries of open-source multimodal models with the progressive scaling strategy
2024
- [46]
-
[47]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review arXiv 2024
- [48]
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review arXiv 2025
-
[50]
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. 2024. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800(2024)
work page internal anchor Pith review arXiv 2024
- [51]
-
[52]
Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, and Fei Huang. 2024. mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. InCVPR
2024
- [53]
- [54]
-
[55]
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg
-
[56]
InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14
Modeling context in referring expressions. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14. Springer, 69–85
2016
-
[57]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al . 2024. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13807–13816
2024
-
[58]
Xiang Yuan, Gong Cheng, Kebing Yan, Qinghua Zeng, and Junwei Han. 2023. Small object detection via coarse-to-fine proposal generation and imitation learning. InProceedings of the IEEE/CVF international conference on computer vision. 6317–6327
2023
-
[59]
Yufei Zhan, Yousong Zhu, Zhiyang Chen, Fan Yang, Ming Tang, and Jinqiao Wang. 2024. Griffon: Spelling out all object locations at any granularity with large language models. InEuropean Conference on Computer Vision. Springer, 405–422
2024
- [60]
- [61]
-
[62]
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. 2024. Long context transfer from language to vision.arXiv:2406.16852(2024)
work page internal anchor Pith review arXiv 2024
-
[63]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. 2024. Video instruction tuning with synthetic data.arXiv:2410.02713(2024)
work page internal anchor Pith review arXiv 2024
- [64]
- [65]
- [66]
-
[67]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. 2025. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479(2025). A Implementation Details Source datasets and preprocessing.We build the source ground- ing p...
work page internal anchor Pith review arXiv 2025
-
[68]
**maximum kinetic energy K**
**Intercept with frequency axis**: When \( K_{\text{max}} = 0 \), we get \( h\nu = \phi \), so \( \nu = \frac{\phi}{h} \). This is the **threshold frequency** — the minimum frequency required to eject electrons. - So, the line crosses the x-axis at this threshold frequency. 3. **Slope**: The slope of the line is \( h \), which is positive → so as frequenc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.