ARETE: Attention-based Rasterized Encoding for Topology Estimation using HSV-transformed Crowdsourced Vehicle Fleet Data
Pith reviewed 2026-05-08 04:36 UTC · model grok-4.3
The pith
Rasterizing crowdsourced vehicle paths with HSV encoding lets a DETR model extract directed centerlines and constrained lane dividers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
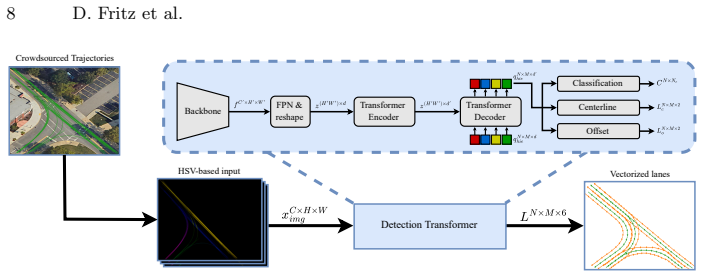
The central claim is that an attention-based Detection Transformer can recover accurate vectorized lane topology directly from rasterized representations of aggregated crowdsourced trajectories. Each input tile is formed by binning vehicle paths, then applying an HSV transform that stores presence in one channel and direction in the hue and saturation channels. The network predicts centerlines carrying explicit direction together with associated lane dividers whose positions are forced to remain consistent with the centerline geometry. Experiments on an internal fleet dataset plus the public nuScenes and nuPlan collections are used to measure how well the predicted lanes match ground-truthHD
What carries the argument
HSV-transformed rasterized encoding of aggregated vehicle trajectories, which packs presence and direction into a single image-like input for a Detection Transformer that outputs geometrically constrained vectorized lanes.
If this is right
- Produces lanes that each consist of one directed centerline and multiple dividers whose geometry is explicitly constrained by the centerline.
- Supports automated, frequent updates to HD maps using only data already collected by production vehicle fleets.
- Runs on both proprietary fleet recordings and public benchmarks such as nuScenes and nuPlan.
Where Pith is reading between the lines
- The same raster-plus-transformer pipeline could be applied to other sparse trajectory sources, such as delivery fleets or rideshare logs, to bootstrap maps in new cities.
- Adding a second stage that refines divider positions with raw point clouds might reduce residual geometric error where raster binning smooths sharp turns.
- The directed-centerline output naturally supplies the input needed for downstream lane-following planners, so the topology estimates could be plugged directly into existing autonomy stacks.
Load-bearing premise
Aggregating and HSV-coloring the trajectories into fixed raster tiles keeps enough precise geometric information that the transformer can reconstruct accurate directed centerlines and their dividers without losing critical detail or introducing encoding artifacts.
What would settle it
Systematic misalignment between the model's predicted centerlines and the actual dominant paths visible in the raw trajectory points on a held-out set of curved or merging road segments.
Figures


read the original abstract
The continuous advancement of autonomous driving (AD) introduces challenges across multiple disciplines to ensure safe and efficient driving. One such challenge is the generation of High-Definition (HD) maps, which must remain up to date and highly accurate for downstream automotive tasks. One promising approach is the use of crowdsourced data from a vehicle fleet, representing road topology and lane-level features. This work focuses on the generation of centerlines and lane dividers from crowdsourced vehicle trajectories. We adopt a Detection Transformer (DETR)-based approach, where a rasterized representation of vehicle trajectories is used as input to predict vectorized lane representations. Each lane consists of a centerline with an associated direction and corresponding lane dividers that are geometrically constrained by the centerline. Our method includes the extraction of local tiles, from which crowdsourced vehicle trajectories are aggregated. Each tile undergoes a transformation into a rasterized representation encoding both the presence and direction of each trajectory, enabling the prediction of vectorized directed lanes. Experiments are conducted on an internal dataset as well as on the public datasets nuScenes and nuPlan.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ARETE, a DETR-based approach for HD map topology estimation from crowdsourced vehicle fleet trajectories. Local tiles are extracted and aggregated trajectories are rasterized with an HSV transformation to encode both presence and direction; the transformer then predicts vectorized lane representations consisting of a directed centerline plus geometrically constrained lane dividers. Experiments are reported on an internal dataset together with nuScenes and nuPlan.
Significance. If the quantitative claims hold, the work would demonstrate a scalable, data-driven route to up-to-date lane-level maps that relies only on fleet trajectories rather than dedicated mapping sensors. The combination of rasterized directional encoding with a DETR decoder for constrained vector output is a timely technical choice. No machine-checked proofs, open code, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the description supplies no quantitative results, ablation studies, error metrics, or validation details, making it impossible to assess whether the DETR recovers the claimed topology from the rasterized input.
- [Method] Method section (rasterization and encoding): no tile resolution, HSV mapping function, or constraint mechanism (learned loss versus post-hoc projection) is specified. Rasterization and hue quantization can introduce aliasing or merging at intersections; without an explicit demonstration that the DETR decoder plus any constraint term recovers metric centerline-divider relations, the geometric-constraint claim rests on an unverified information-preservation step.
minor comments (2)
- [Abstract] The acronym ARETE is not expanded in the abstract or title footnote.
- A diagram showing an example HSV-encoded tile and the corresponding ground-truth centerlines/dividers would clarify the input-output relationship.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have prepared revisions to the manuscript that incorporate the requested clarifications, details, and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description supplies no quantitative results, ablation studies, error metrics, or validation details, making it impossible to assess whether the DETR recovers the claimed topology from the rasterized input.
Authors: We agree that the original abstract omitted numerical results and validation details. In the revised version we will expand the abstract to include key quantitative outcomes (e.g., centerline and divider F1 scores on nuScenes and nuPlan) together with a concise reference to the ablation studies and error metrics reported in the experiments section. revision: yes
-
Referee: [Method] Method section (rasterization and encoding): no tile resolution, HSV mapping function, or constraint mechanism (learned loss versus post-hoc projection) is specified. Rasterization and hue quantization can introduce aliasing or merging at intersections; without an explicit demonstration that the DETR decoder plus any constraint term recovers metric centerline-divider relations, the geometric-constraint claim rests on an unverified information-preservation step.
Authors: We acknowledge that the submitted manuscript did not provide the concrete implementation parameters. We will revise the method section to state the tile resolution, give the exact HSV mapping (hue encodes normalized direction, saturation encodes presence), and clarify that geometric constraints are enforced by a dedicated loss term rather than post-hoc projection. We will also add a short analysis and visualizations addressing potential aliasing at intersections, showing that the attention mechanism separates trajectories sufficiently for the decoder to recover metric centerline-divider relations; quantitative verification of these relations will be included in the experiments. revision: yes
Circularity Check
No circularity: standard learned DETR pipeline on rasterized inputs
full rationale
The paper presents a data-driven pipeline: aggregate crowdsourced trajectories into tiles, apply rasterization with HSV encoding of presence and direction, then feed to a DETR model that outputs vectorized centerlines plus geometrically constrained dividers. No equations define outputs in terms of themselves, no fitted parameters are relabeled as predictions, and no self-citations or uniqueness theorems are invoked to force the architecture. The geometric constraints are part of the model output specification, not a reduction of the result to the input by construction. Evaluation on nuScenes/nuPlan and internal data provides external grounding. This is a conventional supervised prediction setup with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Multimedia pp
Bai, W., Zhang, Y., Guo, Q., Liu, W., Du, S., Hu, J., Cheng, S., Ning, Z.: Dynamic query management and internal consistency representation based transformer for online vectorized hd map construction. IEEE Transactions on Multimedia pp. 1–15 (2026)
work page 2026
-
[2]
In: Computer Vision – ECCV 2020
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: Computer Vision – ECCV 2020. pp. 213–229. Springer International Publishing, Cham (2020)
work page 2020
-
[3]
IEEE Robotics and Automation Letters9(6), 5735–5742 (2024)
Chen, P., Jiang, X., Zhang, Y., Tan, J., Jiang, R.: Mapcvv: On-cloud map construc- tion using crowdsourcing visual vectorized elements towards autonomous driving. IEEE Robotics and Automation Letters9(6), 5735–5742 (2024)
work page 2024
-
[4]
In: 2020 IEEE Winter Conference on Applications of Computer Vision (WACV)
Djuric, N., Radosavljevic, V., Cui, H., Nguyen, T., Chou, F.C., Lin, T.H., Singh, N., Schneider, J.: Uncertainty-aware short-term motion prediction of traffic ac- tors for autonomous driving. In: 2020 IEEE Winter Conference on Applications of Computer Vision (WACV). pp. 2084–2093 (2020)
work page 2020
-
[5]
IEEE Open Journal of Intelligent Transportation Systems4, 527–550 (2023)
Elghazaly, G., Frank, R., Harvey, S., Safko, S.: High-definition maps: Comprehen- sive survey, challenges, and future perspectives. IEEE Open Journal of Intelligent Transportation Systems4, 527–550 (2023)
work page 2023
-
[6]
In: 2025 IEEE 28th International Conference on Intelligent Transporta- tion Systems (ITSC)
Fritz, D., Lagamtzis, D., Mink, M., Schober, S.: ADVNTG: Autonomous Driving Vehicle and Neural Transformer-Based HD Map Generation Using Crowd-Sourced Fleet Data. In: 2025 IEEE 28th International Conference on Intelligent Transporta- tion Systems (ITSC). pp. 1954–1959. IEEE, Gold Coast, Australia (Nov 2025)
work page 2025
-
[7]
ISPRS International Journal of Geo-Information 13(3) (2024)
Guo, Y., Zhou, J., Li, X., Tang, Y., Lv, Z.: A review of crowdsourcing update methods for high-definition maps. ISPRS International Journal of Geo-Information 13(3) (2024)
work page 2024
-
[8]
Hao, X., Zhao, Y., Ji, Y., Dai, L., Hao, P., Li, D., Cheng, S., Yin, R.: What really matters for robust multi-sensor hd map construction? In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 1298–1304 (2025)
work page 2025
-
[9]
Hubbertz, M., Colling, P., Han, Q., Meisen, T.: Inferring driving maps by deep learning-based trail map extraction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 2450–2459 (June 2025)
work page 2025
-
[10]
In: The Fourteenth International Conference on Learning Representations (ICLR) (2024)
Li, T., Jia, P., Wang, B., Chen, L., Jiang, K., Yan, J., Li, H.: Lanesegnet: Map learning with lane segment perception for autonomous driving. In: The Fourteenth International Conference on Learning Representations (ICLR) (2024)
work page 2024
-
[11]
In: European Conference on Computer Vision (2023)
Liao, B., Chen, S., Jiang, B., Cheng, T., Zhang, Q., Liu, W., Huang, C., Wang, X.: Lane graph as path: Continuity-preserving path-wise modeling for online lane graph construction. In: European Conference on Computer Vision (2023)
work page 2023
-
[12]
In: Computer Vision – ECCV 2024
Liao, B., Chen, S., Jiang, B., Cheng, T., Zhang, Q., Liu, W., Huang, C., Wang, X.: Lane graph as path: Continuity-preserving path-wise modeling for online lane graph construction. In: Computer Vision – ECCV 2024. pp. 334–351. Springer Nature Switzerland, Cham (2025)
work page 2024
-
[13]
In: International Conference on Learning Representations (2023)
Liao, B., Chen, S., Wang, X., Cheng, T., Zhang, Q., Liu, W., Huang, C.: Maptr: Structured modeling and learning for online vectorized hd map construction. In: International Conference on Learning Representations (2023)
work page 2023
-
[14]
International Journal of Computer Vision pp
Liao, B., Chen, S., Zhang, Y., Jiang, B., Zhang, Q., Liu, W., Huang, C., Wang, X.: Maptrv2: An end-to-end framework for online vectorized hd map construction. International Journal of Computer Vision pp. 1–23 (2024) 14 D. Fritz et al
work page 2024
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Lilja, A., Fu, J., Stenborg, E., Hammarstrand, L.: Localization is all you evaluate: Data leakage in online mapping datasets and how to fix it. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22150–22159 (June 2024)
work page 2024
-
[16]
IEEE Robotics and Automation Letters11(4), 4793–4800 (2026)
Liu, G., Zhang, D., Xu, C., Zhang, X., Zhang, Z., Zhao, J., Wu, Z., Zhang, J.: City-scale lane-level mapping from crowdsourced trajectories and satellite imagery. IEEE Robotics and Automation Letters11(4), 4793–4800 (2026)
work page 2026
-
[17]
In: International conference on machine learning
Liu, Y., Yuan, T., Wang, Y., Wang, Y., Zhao, H.: Vectormapnet: End-to-end vec- torized hd map learning. In: International conference on machine learning. PMLR (2023)
work page 2023
-
[18]
Journal of Sensor and Actuator Networks14(1) (2025)
Lyu, H., Berrio Perez, J.S., Huang, Y., Li, K., Shan, M., Worrall, S.: Online high- definition map construction for autonomous vehicles: A comprehensive survey. Journal of Sensor and Actuator Networks14(1) (2025)
work page 2025
-
[19]
In: 2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC)
Mink, M., Monninger, T., Staab, S.: Lmt-net: Lane model transformer network for automated hd mapping from sparse vehicle observations. In: 2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC). pp. 1203– 1210 (2024)
work page 2024
-
[20]
IEEE Robotics and Automation Letters8(8), 5077–5083 (2023)
Qin, T., Huang, H., Wang, Z., Chen, T., Ding, W.: Traffic flow-based crowdsourced mapping in complex urban scenario. IEEE Robotics and Automation Letters8(8), 5077–5083 (2023)
work page 2023
-
[21]
IEEE Transactions on Intelligent Vehicles9(10), 5973–5994 (2024)
Tang, X., Jiang, K., Yang, M., Liu, Z., Jia, P., Wijaya, B., Wen, T., Cui, L., Yang, D.: High-definition maps construction based on visual sensor: A comprehensive survey. IEEE Transactions on Intelligent Vehicles9(10), 5973–5994 (2024)
work page 2024
-
[22]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2025)
Xu, L., Wu, Z., Qiu, W., Pang, S., Bai, X., Mei, K., Xue, J.: Redundant queries in detr-based 3d detection methods: Unnecessary and prunable. In: Proceedings of the AAAI Conference on Artificial Intelligence (2025)
work page 2025
-
[23]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Yuan, T., Liu, Y., Wang, Y., Wang, Y., Zhao, H.: Streammapnet: Streaming map- ping network for vectorized online hd map construction. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 7356–7365 (January 2024)
work page 2024
-
[24]
IEEE Transactions on Intelligent Transportation Systems26(12), 21502–21525 (2025)
Zhang, Y., Qian, Y., Meng, C., Zhang, R., Yi, H., Wang, C., Yang, M.: Local vectorized high definition map construction for autonomous driving: A compre- hensive review. IEEE Transactions on Intelligent Transportation Systems26(12), 21502–21525 (2025)
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.