Recognition: unknown
Learning Illumination Control in Diffusion Models
Pith reviewed 2026-05-08 04:13 UTC · model grok-4.3
The pith
An open-source data engine creates synthetic triplets that let diffusion models adjust image lighting from plain-language instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a synthetic data engine can generate supervised triplets of poorly-illuminated input images, natural-language lighting instructions, and well-illuminated target images, and that finetuning a diffusion model on this data yields better perceptual similarity, structural similarity, and identity preservation than baseline SD 1.5, SDXL, and FLUX.1-dev models.
What carries the argument
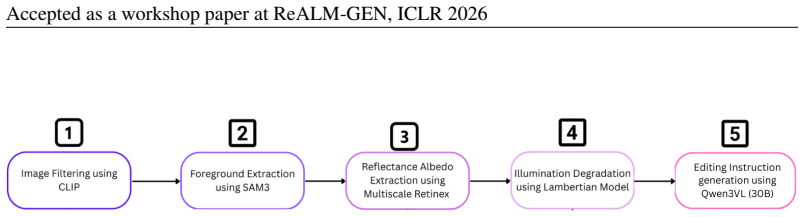
The synthetic data engine that converts well-lit images into training triplets of a poorly-illuminated input, a lighting instruction in natural language, and the original well-lit output.
If this is right
- The same triplet-generation process can be applied to other diffusion backbones to add illumination control without redesigning the model architecture.
- Users can edit lighting in images using ordinary text prompts rather than providing depth maps or other heavy conditioning inputs.
- All training data, code, and weights being public allows independent verification and further adaptation by anyone with standard hardware.
- The improvements in identity preservation suggest the method keeps subject appearance stable while only changing illumination.
Where Pith is reading between the lines
- The approach could be extended to other image attributes such as color balance or weather effects by swapping the synthetic degradation step in the data engine.
- Because the pipeline is fully open, it lowers the barrier for small teams or individuals to create specialized lighting-control models for domains like product photography or medical imaging.
- If the synthetic data generalizes well, similar engines might be used to teach diffusion models other low-level photographic controls without collecting new real-world datasets.
Load-bearing premise
The synthetic poorly-lit images and instructions created by the engine are realistic enough that a model trained on them will work on real-world photos and user prompts.
What would settle it
Run the finetuned model on a held-out set of real poorly illuminated photographs with matching text instructions and measure whether perceptual and structural similarity scores remain higher than the untuned baselines.
Figures






read the original abstract
Controlling illumination in images is essential for photography and visual content creation. While closed-source models have demonstrated impressive illumination control, open-source alternatives either require heavy control inputs like depth maps or do not release their data and code. We present a fully open-source and reproducible pipeline for learning illumination control in diffusion models. Our approach builds a data engine that transforms well-lit images into supervised training triplets consisting of a poorly-illuminated input image, a natural language lighting instruction, and a well-illuminated output image. We finetune a diffusion model on this data and demonstrate significant improvements over baseline SD 1.5, SDXL, and FLUX.1-dev models in perceptual similarity, structural similarity, and identity preservation. Our work provides a reproducible solution built entirely with open-source tools and publicly available data. We release all our code, data, and model weights publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a fully open-source and reproducible pipeline for learning illumination control in diffusion models. It builds a synthetic data engine that transforms well-lit images into supervised training triplets (poorly-illuminated input image, natural-language lighting instruction, well-illuminated target), fine-tunes diffusion models on these triplets, and reports significant improvements over baseline SD 1.5, SDXL, and FLUX.1-dev in perceptual similarity, structural similarity, and identity preservation. All code, data, and model weights are released publicly.
Significance. If the central claims hold, the work supplies a practical, reproducible route to add illumination control to open-source diffusion models without requiring auxiliary inputs such as depth maps. The explicit release of the full pipeline, synthetic data engine, training code, and weights is a clear strength that supports community adoption and further experimentation in controllable image synthesis.
major comments (2)
- [Methods / Data Engine] The data engine (described in the Methods section) is load-bearing for the generalization claim, yet the manuscript supplies no concrete specification of the illumination transformations applied to well-lit images. It is unclear whether these operations are physically motivated (directional lighting, cast shadows, inter-reflections, spatially varying illumination) or rely on global intensity scaling, color shifts, or templated prompts. Without this detail, it is impossible to evaluate whether the reported gains in perceptual similarity, SSIM, and identity preservation reflect learned lighting control or merely dataset-specific artifacts, directly threatening transfer to real-world photographs.
- [Abstract and Results] The abstract asserts 'significant improvements' on three metrics but the manuscript text provides neither the numerical values, standard deviations, nor the corresponding tables/figures that would allow verification of these claims. The absence of quantitative results, ablation studies on the data engine, or real-world validation experiments leaves the central empirical claim unsupported in its current form.
minor comments (1)
- [Abstract] The abstract would benefit from a single sentence stating the magnitude of the reported gains (e.g., 'ΔLPIPS = X, ΔSSIM = Y') so that readers can immediately gauge the effect size.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and quantitative details.
read point-by-point responses
-
Referee: [Methods / Data Engine] The data engine (described in the Methods section) is load-bearing for the generalization claim, yet the manuscript supplies no concrete specification of the illumination transformations applied to well-lit images. It is unclear whether these operations are physically motivated (directional lighting, cast shadows, inter-reflections, spatially varying illumination) or rely on global intensity scaling, color shifts, or templated prompts. Without this detail, it is impossible to evaluate whether the reported gains in perceptual similarity, SSIM, and identity preservation reflect learned lighting control or merely dataset-specific artifacts, directly threatening transfer to real-world photographs.
Authors: We acknowledge that the current manuscript provides only a high-level description of the data engine and lacks the concrete, technical specification of the illumination transformations. This is a valid concern that affects the ability to assess generalization. In the revised manuscript, we will add a dedicated subsection in Methods that precisely details the operations used to generate poorly-illuminated inputs from well-lit images, including the specific image-processing steps (e.g., intensity scaling, localized shadow simulation, color temperature shifts), whether they incorporate physically motivated elements such as directional lighting or cast shadows, and the procedure for creating the accompanying natural-language lighting instructions. This expansion will allow readers to determine whether the observed gains reflect genuine lighting control rather than dataset artifacts. revision: yes
-
Referee: [Abstract and Results] The abstract asserts 'significant improvements' on three metrics but the manuscript text provides neither the numerical values, standard deviations, nor the corresponding tables/figures that would allow verification of these claims. The absence of quantitative results, ablation studies on the data engine, or real-world validation experiments leaves the central empirical claim unsupported in its current form.
Authors: We agree that the abstract and main text should explicitly present the supporting quantitative evidence. In the revision, we will update the abstract to report the specific numerical improvements (including deltas and standard deviations) in perceptual similarity, SSIM, and identity preservation relative to the SD 1.5, SDXL, and FLUX.1-dev baselines. The Results section will be expanded to state these values directly in the text with references to the corresponding tables and figures. We will also add ablation studies on the data engine components and include real-world validation experiments on natural photographs to strengthen the empirical support for the claims. revision: yes
Circularity Check
No circularity: standard empirical fine-tuning on synthetic data
full rationale
The paper describes an empirical workflow: a data engine generates triplets (poorly-lit input, lighting instruction, well-lit target) from existing images, followed by fine-tuning of diffusion models and evaluation on perceptual/structural metrics. No mathematical derivations, equations, or self-referential definitions appear. No load-bearing self-citations or uniqueness theorems are invoked. The claimed improvements are measured against independent baselines (SD 1.5, SDXL, FLUX) on held-out data, keeping the chain self-contained without reduction to fitted inputs or prior author results by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be effectively fine-tuned on synthetic conditional triplets for image-editing tasks.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.