Recognition: unknown
Chart-FR1: Visual Focus-Driven Fine-Grained Reasoning on Dense Charts
Pith reviewed 2026-05-10 16:02 UTC · model grok-4.3
The pith
Chart-FR1 uses explicit visual focus chains and targeted reinforcement learning to handle dense charts better than prior multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
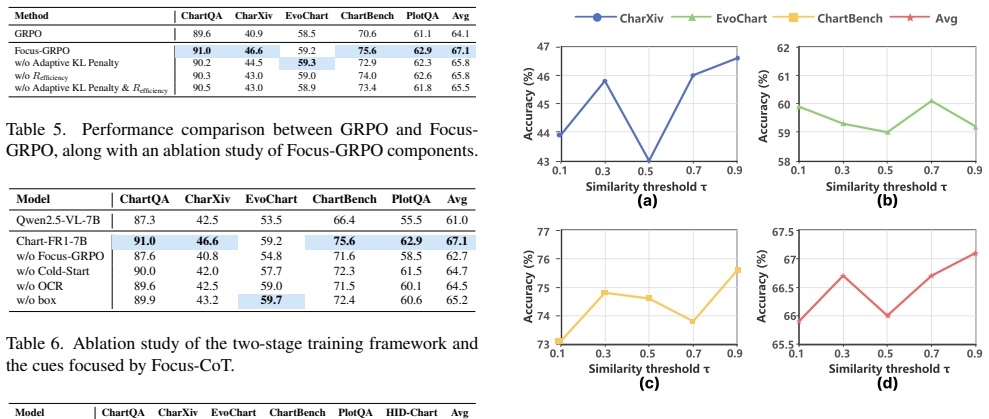
Chart-FR1 improves perception, focusing efficiency, and adaptive deep reasoning on high information density charts by proposing Focus-CoT, a visual focusing chain-of-thought that explicitly links reasoning steps to key visual cues such as local image regions and OCR signals, and Focus-GRPO, a focus-driven reinforcement learning algorithm that applies an information-efficiency reward to compress redundant visual information and an adaptive KL penalty to control reasoning depth flexibly as more cues are discovered. The work also introduces the HID-Chart benchmark with an information-density metric to evaluate these capabilities, and shows through experiments that the resulting model surpasses
What carries the argument
Focus-CoT, which ties each step of reasoning to specific visual regions and OCR signals, paired with Focus-GRPO, which uses an efficiency reward and adaptive penalty during reinforcement learning to manage information load and reasoning length.
If this is right
- Models can maintain accuracy on charts that contain multiple subplots, legends, and dense annotations without dropping critical details.
- Reasoning can be made more efficient by actively discarding redundant visual tokens rather than processing the entire image.
- Reasoning depth can increase automatically once additional visual cues are located, without fixed length limits.
- A dedicated benchmark with an explicit information-density score allows consistent comparison of fine-grained chart reasoning methods.
- The same focus-driven training pattern can be applied to other chart datasets to measure gains in understanding and reasoning tasks.
Where Pith is reading between the lines
- The same explicit cue-linking pattern could be tested on other cluttered visual domains such as scientific figures or technical diagrams to check if the gains transfer.
- Removing the adaptive penalty might reveal whether fixed reasoning budgets are enough or whether depth must truly scale with discovered information.
- If the efficiency reward generalizes, similar compression terms could be added to training of general-purpose multimodal models facing high-detail inputs.
- Future benchmarks could add time-varying or interactive charts to see whether the focus mechanism still works when visual content changes.
Load-bearing premise
That explicitly linking reasoning steps to key visual cues via Focus-CoT combined with an information-efficiency reward and adaptive KL penalty in Focus-GRPO will sufficiently overcome the three stated challenges of limited fine-grained perception, redundant visual information, and lack of adaptive deep reasoning.
What would settle it
A direct ablation on the HID-Chart benchmark in which the Focus-CoT linking mechanism and the Focus-GRPO reward-penalty terms are removed from the training pipeline and performance falls to the level of unmodified baseline MLLMs on fine-grained questions.
Figures









read the original abstract
Multimodal large language models (MLLMs) have shown considerable potential in chart understanding and reasoning tasks. However, they still struggle with high information density (HID) charts characterized by multiple subplots, legends, and dense annotations due to three major challenges: (1) limited fine-grained perception results in the omission of critical visual cues; (2) redundant or noisy visual information undermines the performance of multimodal reasoning; (3) lack of adaptive deep reasoning relative to the amount of visual information. To tackle these challenges, we present a novel focus-driven fine-grained chart reasoning model, Chart-FR1, to improve perception, focusing efficiency, and adaptive deep reasoning on HID charts. Specifically, we propose Focus-CoT, a visual focusing chain-of-thought that enhances fine-grained perception by explicitly linking reasoning steps to key visual cues, such as local image regions and OCR signals. Building on this, we introduce Focus-GRPO, a focus-driven reinforcement learning algorithm with an information-efficiency reward that compresses redundant visual information for efficient focusing, and an adaptive KL penalty mechanism that enables flexible control over reasoning depth as more visual cues are discovered. Furthermore, to fill the gap in benchmarks for HID charts, we build HID-Chart, a challenging benchmark with an information-density metric designed to evaluate fine-grained chart reasoning capabilities. Extensive experiments on multiple chart benchmarks demonstrate that Chart-FR1 outperforms state-of-the-art MLLMs in chart understanding and reasoning. Code is available at https://github.com/phkhub/Chart-FR1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Chart-FR1, a focus-driven fine-grained chart reasoning model for MLLMs targeting high information density (HID) charts. It proposes Focus-CoT to explicitly link reasoning steps to key visual cues such as local image regions and OCR signals, Focus-GRPO as a reinforcement learning algorithm incorporating an information-efficiency reward to compress redundancy and an adaptive KL penalty to control reasoning depth, and the HID-Chart benchmark equipped with an information-density metric. The central claim is that these components overcome limited fine-grained perception, redundant visual information, and non-adaptive reasoning, with extensive experiments showing outperformance over state-of-the-art MLLMs on multiple chart benchmarks.
Significance. If the experimental results and ablations hold, the work could meaningfully advance MLLM capabilities on dense visual data such as multi-subplot charts, with potential applications in automated data analysis and visualization interpretation. The introduction of a dedicated HID-Chart benchmark with a density metric fills an evaluation gap and may enable more targeted future research, provided the metric is shown to align with actual model failure modes.
major comments (2)
- [Abstract] Abstract: The manuscript asserts that 'extensive experiments on multiple chart benchmarks demonstrate that Chart-FR1 outperforms state-of-the-art MLLMs' yet supplies no quantitative results, tables, error bars, ablation studies, or experimental details. This prevents assessment of whether the data support the central claim that Focus-CoT combined with the information-efficiency reward and adaptive KL penalty in Focus-GRPO is sufficient to overcome the three stated challenges.
- [Abstract] Abstract: The information-density metric introduced for the HID-Chart benchmark is presented without validation or correlation analysis demonstrating that it aligns with the claimed MLLM failure modes (limited fine-grained perception, redundancy, non-adaptive depth). This is load-bearing for the benchmark's role in evaluating the proposed method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will implement to strengthen the presentation and validation of our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that 'extensive experiments on multiple chart benchmarks demonstrate that Chart-FR1 outperforms state-of-the-art MLLMs' yet supplies no quantitative results, tables, error bars, ablation studies, or experimental details. This prevents assessment of whether the data support the central claim that Focus-CoT combined with the information-efficiency reward and adaptive KL penalty in Focus-GRPO is sufficient to overcome the three stated challenges.
Authors: We agree that the abstract would be strengthened by including key quantitative highlights to support the central claims. The full manuscript (Section 4) contains detailed tables with performance metrics, error bars, ablation studies on Focus-CoT and Focus-GRPO, and comparisons against state-of-the-art MLLMs across multiple benchmarks, including specific gains on HID-Chart. We will revise the abstract to incorporate representative numerical results (e.g., accuracy improvements and references to the relevant tables and figures) while maintaining its concise format. revision: yes
-
Referee: [Abstract] Abstract: The information-density metric introduced for the HID-Chart benchmark is presented without validation or correlation analysis demonstrating that it aligns with the claimed MLLM failure modes (limited fine-grained perception, redundancy, non-adaptive depth). This is load-bearing for the benchmark's role in evaluating the proposed method.
Authors: We acknowledge the importance of validating the information-density metric against the targeted failure modes. The metric is defined in Section 3.2 based on visual element counts and subplot density, and experiments already show performance trends with increasing density. In the revision, we will add an explicit correlation analysis (including plots and statistical measures) linking higher density scores to specific error types such as omitted visual cues and redundant reasoning, supported by error case studies from baseline MLLMs. This will be placed in Section 3 or as an appendix subsection. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces Focus-CoT and Focus-GRPO as novel mechanisms (with information-efficiency reward and adaptive KL penalty) to address stated challenges in HID chart reasoning, without any equations, parameters, or performance claims reducing by construction to fitted inputs, self-defined quantities, or load-bearing self-citations. The HID-Chart benchmark and its information-density metric are presented as newly constructed rather than derived from prior fitted results. Central claims rest on experimental comparisons to SOTA MLLMs rather than tautological renaming or ansatz smuggling. This is a standard non-circular presentation of new modules grounded in existing MLLM and RL techniques.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal large language models can be improved for dense visual inputs by explicitly focusing reasoning on key image regions and OCR signals
- domain assumption Reinforcement learning with an information-efficiency reward and adaptive KL penalty can produce more efficient and depth-adaptive reasoning
invented entities (3)
-
Focus-CoT
no independent evidence
-
Focus-GRPO
no independent evidence
-
HID-Chart
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[3]
Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020. 2
1901
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 2
2024
-
[7]
Introducing gemini 2.0: our new ai model for the agentic era, 2024
Google DeepMind. Introducing gemini 2.0: our new ai model for the agentic era, 2024. 7
2024
-
[8]
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. Openvlthinker: Complex vision- language reasoning via iterative sft-rl cycles.arXiv preprint arXiv:2503.17352, 2025. 2, 3, 7
-
[9]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM international conference on multimedia, pages 11198–11201, 2024. 14
2024
-
[10]
Nuno Fachada, Daniel Fernandes, et al. Gpt-4.1 sets the stan- dard in automated experiment design using novel python li- braries.arXiv preprint arXiv:2508.00033, 2025. 7
-
[11]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025. 2, 3
2025
-
[12]
Chartllama: A multimodal llm for chart understanding and generation
Yucheng Han, Chi Zhang, Xin Chen, Xu Yang, Zhibin Wang, Gang Yu, Bin Fu, and Hanwang Zhang. Chartllama: A mul- timodal llm for chart understanding and generation.arXiv preprint arXiv:2311.16483, 2023. 2
-
[13]
Novachart: A large- scale dataset towards chart understanding and generation of multimodal large language models
Linmei Hu, Duokang Wang, Yiming Pan, Jifan Yu, Yingxia Shao, Chong Feng, and Liqiang Nie. Novachart: A large- scale dataset towards chart understanding and generation of multimodal large language models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 3917–3925, 2024. 6
2024
-
[14]
Evochart: A benchmark and a self-training approach towards real-world chart understand- ing
Muye Huang, Han Lai, Xinyu Zhang, Wenjun Wu, Jie Ma, Lingling Zhang, and Jun Liu. Evochart: A benchmark and a self-training approach towards real-world chart understand- ing. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3680–3688, 2025. 2, 3, 6, 7, 14
2025
-
[15]
ChartSketcher: Reasoning with Multimodal Feedback and Re$ection for Chart Understanding
Muye Huang, Lingling Zhang, Jie Ma, Han Lai, Fangzhi Xu, Yifei Li, Wenjun Wu, Yaqiang Wu, and Jun Liu. Charts- ketcher: Reasoning with multimodal feedback and reflection for chart understanding.arXiv preprint arXiv:2505.19076,
-
[16]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review arXiv
-
[17]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 1, 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Caijun Jia, Nan Xu, Jingxuan Wei, Qingli Wang, Lei Wang, Bihui Yu, and Junnan Zhu. Chartreasoner: Code-driven modality bridging for long-chain reasoning in chart question answering.arXiv preprint arXiv:2506.10116, 2025. 1, 3, 7
-
[19]
Reinforcement learning: A survey.Journal of artifi- cial intelligence research, 4:237–285, 1996
Leslie Pack Kaelbling, Michael L Littman, and Andrew W Moore. Reinforcement learning: A survey.Journal of artifi- cial intelligence research, 4:237–285, 1996. 2, 3
1996
-
[20]
Dvqa: Understanding data visualizations via ques- tion answering
Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. Dvqa: Understanding data visualizations via ques- tion answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5648– 5656, 2018. 3
2018
-
[21]
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkin- son, Akos Kadar, Adam Trischler, and Yoshua Bengio. Fig- ureqa: An annotated figure dataset for visual reasoning. arXiv preprint arXiv:1710.07300, 2017. 3
work page Pith review arXiv 2017
-
[22]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- 9 ceedings of the 29th symposium on operating systems prin- ciples, pages 611–626, 2023. 14
2023
-
[23]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023. 2
2023
-
[25]
Xiangyan Liu, Jinjie Ni, Zijian Wu, Chao Du, Longxu Dou, Haonan Wang, Tianyu Pang, and Michael Qizhe Shieh. Noisyrollout: Reinforcing visual reasoning with data aug- mentation.arXiv preprint arXiv:2504.13055, 2025. 3
-
[26]
Chartqa: A benchmark for question answer- ing about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answer- ing about charts with visual and logical reasoning. InFind- ings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022. 2, 3, 6, 14
2022
-
[27]
Ahmed Masry, Megh Thakkar, Aayush Bajaj, Aaryaman Kartha, Enamul Hoque, and Shafiq Joty. Chartgemma: Vi- sual instruction-tuning for chart reasoning in the wild.arXiv preprint arXiv:2407.04172, 2024. 2, 7
-
[28]
Plotqa: Reasoning over scientific plots
Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, and Pratyush Kumar. Plotqa: Reasoning over scientific plots. InProceedings of the ieee/cvf winter conference on appli- cations of computer vision, pages 1527–1536, 2020. 2, 3, 6, 14
2020
-
[29]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023. 2, 3
2023
-
[30]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx- iao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Hybridflow: A flexible and efficient rlhf frame- work
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf frame- work. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025. 12
2025
-
[33]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 3, 5, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.arXiv preprint arXiv:2403.05530, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Rame, Morgane Riv- iere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 1, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Kwai keye-vl technical report.arXiv preprint arXiv:2507.01949, 2025
Kwai Keye Team, Biao Yang, Bin Wen, Changyi Liu, Chen- glong Chu, Chengru Song, Chongling Rao, Chuan Yi, Da Li, Dunju Zang, et al. Kwai keye-vl technical report.arXiv preprint arXiv:2507.01949, 2025. 2, 7
-
[37]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Roziere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jin- guo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Sheng- long Ye, Xizhou Zhu, et al. Visualprm: An effective pro- cess reward model for multimodal reasoning.arXiv preprint arXiv:2503.10291, 2025. 3
-
[39]
Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural In- formation Processing Systems, 37:113569–113697, 2024
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sad- hika Malladi, et al. Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural In- formation Processing Systems, 37:113569–113697, 2024. 2, 3, 6, 14
2024
-
[40]
Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 3
2022
-
[41]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of- experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024. 2, 7
work page internal anchor Pith review arXiv 2024
-
[42]
Chartbench: A benchmark for complex visual reasoning in charts
Zhengzhuo Xu, Sinan Du, Yiyan Qi, Chengjin Xu, Chun Yuan, and Jian Guo. Chartbench: A benchmark for complex visual reasoning in charts.arXiv preprint arXiv:2312.15915,
-
[43]
Chartpoint: Guiding mllms with grounding reflection for chart reasoning
Zhengzhuo Xu, SiNan Du, Yiyan Qi, Siwen Lu, Chengjin Xu, Chun Yuan, and Jian Guo. Chartpoint: Guiding mllms with grounding reflection for chart reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 426–436, 2025. 3, 7
2025
-
[44]
R1-onevision: Advancing gen- eralized multimodal reasoning through cross-modal formal- ization
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1-onevision: Advancing gen- eralized multimodal reasoning through cross-modal formal- ization. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 2376–2385, 2025. 2, 3, 7
2025
-
[45]
arXiv preprint arXiv:2505.16673 (2025)
Huanjin Yao, Qixiang Yin, Jingyi Zhang, Min Yang, Yibo Wang, Wenhao Wu, Fei Su, Li Shen, Minghui Qiu, Dacheng Tao, et al. R1-sharevl: Incentivizing reasoning capability of multimodal large language models via share-grpo.arXiv preprint arXiv:2505.16673, 2025. 3
-
[46]
Fine-tuning large vision-language models as decision-making agents via reinforcement learn- 10 ing
Yuexiang Zhai, Hao Bai, Zipeng Lin, Jiayi Pan, Shengbang Tong, Yifei Zhou, Alane Suhr, Saining Xie, Yann LeCun, Yi Ma, and Sergey Levine. Fine-tuning large vision-language models as decision-making agents via reinforcement learn- 10 ing. InAdvances in Neural Information Processing Systems, pages 110935–110971, 2024. 3
2024
-
[47]
R1-vl: Learn- ing to reason with multimodal large language models via step-wise group relative policy optimization
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-vl: Learn- ing to reason with multimodal large language models via step-wise group relative policy optimization. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 1859–1869, 2025. 2, 3, 7
2025
-
[48]
Liang Zhang, Anwen Hu, Haiyang Xu, Ming Yan, Yichen Xu, Qin Jin, Ji Zhang, and Fei Huang. Tinychart: Efficient chart understanding with visual token merging and program- of-thoughts learning.arXiv preprint arXiv:2404.16635,
-
[49]
Llamafactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd an- nual meeting of the association for computational linguistics (volume 3: system demonstrations), pages 400–410, 2024. 12
2024
-
[50]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 7 11 Appendix In this appendix, we provide additional details and results to complement the main ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
If the model's answer is incorrect, identify the error in the reasoning and focus on the relevant information, using <ocr> and <box> tags to mark information in the image within the <focus> tag. After focusing on the information, point out logical errors, missing image information, or information inconsistent with the image in the second <think> tag, and ...
-
[52]
After focusing on the information, use the second <think> tag to verify the reasoning steps related to the information
If the model's answer is correct, insert <focus> tags at appropriate points in the reasoning process, using <ocr> and <box> tags to mark information in the image within the <focus> tag. After focusing on the information, use the second <think> tag to verify the reasoning steps related to the information. Do not modify the reasoning content
-
[53]
The content within the <focus> tag must include necessary <ocr> and <box> tags
-
[54]
There must be one <focus> tag between two <think> sections
-
[55]
bbox_2d":[x1,y1,x2,y2],
During the process of reasoning and focusing on the information, avoid making statements that imply you already know the correct answer . Format requirements (simulating adaptive focus): - The reasoning process must be enclosed in <think> tags. - During verification, you must use <focus> tags to simulate adaptive focus analysis of image-related areas and ...
-
[56]
It's acceptable to have dif ferent grammar or form (e.g., α and alpha; $R^2_{{t,h,v ,m}}$ and R^2_t,h,v ,m)
Give a score of 1 if and only if the final answer and the ground truth answer are referring to the same term. It's acceptable to have dif ferent grammar or form (e.g., α and alpha; $R^2_{{t,h,v ,m}}$ and R^2_t,h,v ,m). It's also acceptable to have dif ferent orders of the terms when question asks for multiple terms
-
[57]
extract_answer
Give a score of 0 if any term (e.g., ACC+ and ACC; P-101 and P=101) is dif ferent between the final answer and the ground truth. Example 1 Starts * Question: What is the name of the curve that intersects y=\\lambda exactly three times? * Ground T ruth: P56962 * Response: There is only one curve that intersects y=\\lambda exactly three times. The name of t...
-
[58]
Information Richness (weight: 0.5): Amount, diversity , and complexity of information (e.g., number of data series, dimensions, annotations, subplots)
-
[59]
Information Ef ficiency (weight: 0.2): How ef fectively the information is delivered without unnecessary redundancy
-
[60]
Information Clarity (weight: 0.2): V isual readability and ease of understanding (e.g., labeling, layout, absence of clutter)
-
[61]
bbox_2d\
Information Interactivity (weight: 0.1): How easily the user can capture and interpret the key insights from the chart (e.g., whether important trends, comparisons, or anomalies stand out quickly). Finally , compute the overall_score as a weighted sum: overall_score = 0.5 * richness + 0.2 * ef ficiency + 0.2 * clarity + 0.1 * interactivity Round the resul...
-
[64]
bbox_2d\
Read the y-value (points earned) from the y-axis for that point. From the graph: - The x-axis value of 14721.8 is approximately aligned with the point where the orange line (class=0) intersects the y-axis. V erify using <ocr>972.00</ocr>, <box>{\"bbox_2d\":[150,95,235,140], \"label\": \"annotated y-value near the left orange point (x≈14721.8)\"}</box>, <o...
-
[65]
Identify the x-axis value of 14721.8 on the graph
-
[66]
Look at the corresponding point on the orange line (class=0) since it represents the points earned for non-complain cases
-
[67]
menus.amountMax\
Read the y-value (points earned) from the y-axis for that point. From the graph: - The x-axis value of 14721.8 is approximately aligned with the point where the orange line (class=0) intersects the y-axis. - The y-value for this point is around 590.00. Therefore, the y-value for x=14721.8 and class=0 is approximately 590.00. <answer>590.00</answer> 18 Que...
-
[68]
Living Area Above Ground.\
Identify the x-axis label: \"Living Area Above Ground.\"
-
[69]
Locate the horizontal line at the value 4000 on the x-axis
-
[70]
bbox_2d\
Count all the data points (dots) that fall on or to the right of this horizontal line. From the graph, the horizontal line at 4000 on the x-axis separates the data points into two regions: - T o the left of the line (x < 4000), there are many data points. - T o the right of the line (x ≥ 4000), there are fewer data points. By visually inspecting the graph...
-
[71]
**Identify the box plots for 'car'**: The orange box represents the 'car' condition in both the 'baseline' and 'ERP' categories
-
[72]
- In the 'ERP' category , the 'car' box plot shows a wider box and larger whisker range, indicating higher dispersion
**Compare the dispersion in the 'car' box plots**: - In the 'baseline' category , the 'car' box plot shows a relatively narrow box and a small whisker range, indicating low dispersion. - In the 'ERP' category , the 'car' box plot shows a wider box and larger whisker range, indicating higher dispersion
-
[73]
bbox_2d\
**Conclusion**: The 'ERP' category shows a greater dispersion of Mean RMS values for the 'car' condition compared to the 'baseline' category . V erify using <ocr>Mean RMS, car , baseline, ERP</ocr>, <box>{\"bbox_2d\": [100,100,500,500], \"label\":\"the legend and box plots in plot A\"}</box> The focus on the legend and box plots in plot A shows the 'car' ...
1947
-
[74]
Locate the graph for JPN 1947 grandchildren (the second row , first column)
1947
-
[76]
Find the value of the blue \"var\" line at the 60th age mark
-
[77]
Locate the graph for JPN 2019 grandchildren (the second row , second column)
2019
-
[78]
Identify the blue \"var\" line in this graph
-
[79]
var\" line at the 60th age mark. By visually comparing the two values, we can determine which one is higher . <ocr>JPN 1947 grandchildren</ocr>, <box>{\
Find the value of the blue \"var\" line at the 60th age mark. By visually comparing the two values, we can determine which one is higher . <ocr>JPN 1947 grandchildren</ocr>, <box>{\"bbox_2d\":[100,300,300,400], \"label\": \"the second row , first column graph label\"}</box> The focus is on the label of the graph for JPN 1947 grandchildren, which indicates...
1947
-
[80]
Identify the cluster with a 1000-sequence y-axis
-
[81]
Single, non-parent\
Check the color distribution for the \"Single, non-parent\" category (yellow) in the specified time period (months 18 to 36). The cluster with a 1000-sequence y-axis is the bottom-left plot labeled \"Short Cohabitation, Delayed or No Parenthood (20.35%)\". Now , let's analyze the color distribution in this plot between months 18 and 36: - The yellow color...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.