High-Dimensional Statistics: Reflections on Progress and Open Problems
Pith reviewed 2026-05-08 15:30 UTC · model grok-4.3
The pith
High-dimensional statistics has evolved to tackle sophisticated problems in complex datasets by building connections across multiple mathematical and computational fields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
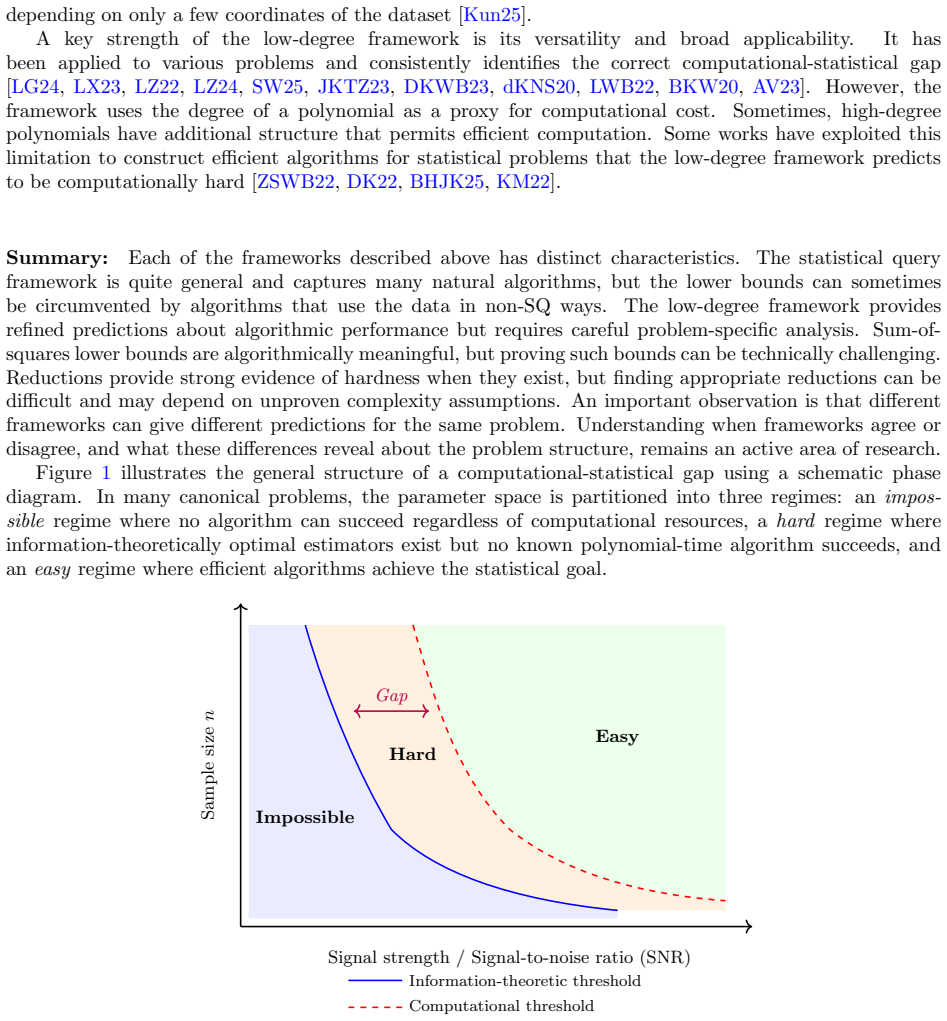
Over the past two decades, the field of high-dimensional statistics has experienced substantial progress, driven largely by technological advances that have dramatically reduced the cost and effort for data collection and storage across a broad range of domains. Modern datasets are increasingly complex, often exhibiting rich dependency, heterogeneity, and other features that challenge traditional statistical methods. In response, high-dimensional statistics has evolved to address more sophisticated estimation and inference problems, fostering deep connections with optimization, concentration of measure, random matrix theory, information theory, and theoretical computer science.
What carries the argument
The synthesis of representative advances, common themes, and open problems that serve as entry points into high-dimensional statistics.
If this is right
- The field's connections to other areas will continue to produce new tools for data analysis.
- Open problems identified will direct research toward handling data dependency and heterogeneity.
- Entry points provided will help new researchers engage with the literature efficiently.
- Practical applications in medicine and astronomy will benefit from refined estimation methods.
Where Pith is reading between the lines
- The review implies that ignoring these interdisciplinary links could slow progress in statistical methodology.
- Future work might test whether addressing the open problems leads to measurable improvements in prediction accuracy on real datasets.
- Connections to theoretical computer science could influence algorithm design for large-scale data processing.
Load-bearing premise
The chosen representative advances and open problems accurately reflect the field's key developments without significant omissions.
What would settle it
A systematic survey revealing a major unmentioned advance or open problem in high-dimensional statistics would falsify the completeness of this reflection.
Figures


read the original abstract
Over the past two decades, the field of high-dimensional statistics has experienced substantial progress, driven largely by technological advances that have dramatically reduced the cost and effort for data collection and storage across a broad range of domains, including biology, medicine, astronomy, and the social and environmental sciences. Modern datasets are increasingly complex, often exhibiting rich dependency, heterogeneity, and other features that challenge traditional statistical methods. In response, high-dimensional statistics has evolved to address more sophisticated estimation and inference problems. This evolution has, in turn, fostered deep connections with and contributions to a wide range of research areas, including optimization, concentration of measure, random matrix theory, information theory, and theoretical computer science. Given the rapid pace of recent developments in high-dimensional statistics, our goal is to synthesize representative advances, highlight common themes and open problems, and point to important works that offer entry points into the field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a reflective survey on high-dimensional statistics over the past two decades. It claims that technological advances enabling large-scale data collection have produced complex datasets with dependencies and heterogeneity, driving the field to develop more sophisticated estimation and inference techniques. These developments have created interdisciplinary links with optimization, concentration of measure, random matrix theory, information theory, and theoretical computer science. The paper synthesizes representative advances, identifies common themes and open problems, and provides pointers to key literature as entry points, while explicitly framing the selection as non-exhaustive.
Significance. If the synthesis is balanced, the paper offers a useful high-level overview and set of entry points for a rapidly evolving field. Its explicit acknowledgment of non-exhaustiveness and focus on interdisciplinary connections could help orient new researchers and highlight cross-field opportunities. The survey format itself is a strength when it successfully points readers to primary sources rather than attempting exhaustive coverage.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the manuscript's intended audience (e.g., researchers new to the area versus specialists) to help readers calibrate expectations for depth versus breadth.
- [Introduction] Section headings and transitions between thematic blocks could be strengthened with short forward-looking sentences that preview how each advance connects to the open problems listed later.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The manuscript is framed as a non-exhaustive synthesis of representative advances, common themes, open problems, and interdisciplinary connections in high-dimensional statistics, with pointers to key entry-point works.
Circularity Check
No significant circularity in this reflective review
full rationale
This paper is a high-level synthesis and reflection on progress in high-dimensional statistics. It explicitly frames its goal as summarizing representative advances from the literature, highlighting themes and open problems, and directing readers to external entry-point works. No original derivations, theorems, predictions, fitted parameters, or equations are presented that could reduce to the paper's own inputs by construction. Central claims are descriptive and non-exhaustive, with no self-citation chains serving as load-bearing justifications for any technical result. The structure relies on external references rather than internal self-reference, satisfying the criteria for a self-contained review with no circularity.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.