Recognition: no theorem link
When Are Experts Misrouted? Counterfactual Routing Analysis in Mixture-of-Experts Language Models
Pith reviewed 2026-05-11 01:41 UTC · model grok-4.3
The pith
In mixture-of-experts models the standard router selects worse routes than available alternatives precisely on the uncertain tokens that drive hard reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Holding the model fixed, the standard top-k router assigns routes that match the utility of sampled equal-compute alternatives on confident tokens but fail to do so on fragile tokens, where alternatives with higher next-token probability for the realized token exist but are not selected; this pattern is structural to the training objective and a minimal router-only update suffices to improve downstream performance.
What carries the argument
Counterfactual comparison of the standard route against sampled equal-compute alternatives, scored by the next-token probability assigned to the realized token in a verified reasoning trajectory.
If this is right
- The router aligns with route utility on confident tokens.
- Lower-loss equal-compute routes exist for fragile tokens but remain unselected.
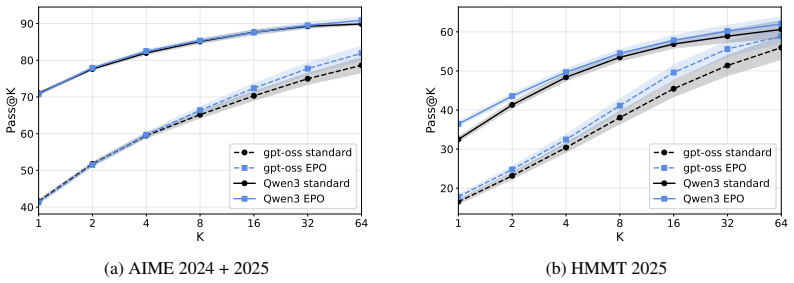
- A router-only update to the final layer alone improves pass@K on AIME 2024+2025 and HMMT 2025.
- The misalignment appears across Qwen3-30B-A3B, GPT-OSS-20B, DeepSeek-V2-Lite, and OLMoE-1B-7B.
- Training scores only the executed route and aggregate load statistics, leaving individual route quality unoptimized.
Where Pith is reading between the lines
- Some performance limits attributed to expert capacity may instead be reachable by better route selection within the existing model.
- Training objectives could incorporate direct signals about route quality on uncertain tokens rather than relying on indirect load balancing.
- The same counterfactual method could be applied to identify misrouting in other conditional-computation or sparse architectures.
Load-bearing premise
That the sampled equal-compute alternative routes represent the space of possible routes and that next-token probability on a verified trajectory serves as a sufficient proxy for overall route quality on downstream tasks.
What would settle it
Observing no increase in pass@K on AIME 2024+2025 and HMMT 2025 after the minimal final-layer router update, or finding that sampled alternatives never show lower loss than the standard route on fragile tokens.
Figures

read the original abstract
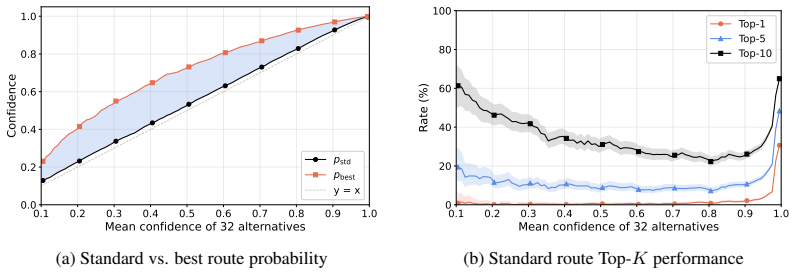
Mixture-of-Experts (MoE) language models route each token to a small subset of experts, but whether the routes selected by a trained top-$k$ router are good ones is rarely evaluated directly. Holding the model fixed, we compare each standard route against sampled equal-compute alternatives for the same token and score each by the next-token probability it assigns to the realized token in a verified reasoning trajectory. The result is sharply token-conditional: the standard router is well-aligned with route utility on confident tokens but uninformative on the fragile tokens that drive hard reasoning, where lower-loss equal-compute routes consistently exist inside the frozen model but are not selected. The same pattern holds across Qwen3-30B-A3B, GPT-OSS-20B, DeepSeek-V2-Lite, and OLMoE-1B-7B, and follows structurally from how standard top-$k$ training evaluates routing decisions: the language modeling loss scores only the executed route, and load balancing depends only on aggregate routing statistics. A minimal router-only update to the final-layer router, leaving every expert and every other router frozen, is sufficient to shift pass@K on AIME 2024+2025 and HMMT 2025 for both Qwen3-30B-A3B and GPT-OSS-20B, suggesting that at least part of the failure reflects router-reachable misallocation rather than expert capacity alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard top-k routers in MoE language models are well-aligned with route utility on confident tokens but uninformative on fragile tokens that drive hard reasoning, where lower-loss equal-compute alternative routes exist inside the frozen model. This pattern is shown via counterfactual scoring of routes by next-token probability on verified trajectories, holds across Qwen3-30B-A3B, GPT-OSS-20B, DeepSeek-V2-Lite, and OLMoE-1B-7B, follows from the training objective, and is addressed by a minimal final-layer router update that improves pass@K on AIME 2024+2025 and HMMT 2025.
Significance. If the central empirical pattern holds, the work isolates routing decisions as a separable and addressable source of suboptimality in MoE models, distinct from expert capacity limits. The token-conditional analysis and the demonstration that router-only updates (leaving experts and other routers frozen) can shift downstream math benchmark performance provide a concrete, low-cost intervention path. Cross-model replication and the structural explanation tied to the LM loss and load-balancing objective add generality.
major comments (3)
- [§4] §4 (Counterfactual Analysis): The scoring of alternative routes solely by next-token probability assigned to the realized token from the original trajectory assumes invariance of the target under routing changes. For fragile tokens this assumption is load-bearing, because an alternative route alters the hidden state and subsequent distribution, so the original token may no longer be the relevant target; the paper does not provide a direct test of this invariance.
- [§5] §5 (Router Update Experiment): While the final-layer router fine-tuning improves pass@K, the experiment does not retroactively validate the per-token proxy used to label tokens as fragile or to assert existence of superior routes inside the frozen model; the benchmark gains could arise from a different mechanism than the one identified in the counterfactual analysis.
- [Methods] Methods section: The sampling procedure for equal-compute alternatives, the definition of 'verified reasoning trajectory,' the number of alternatives per token, and controls for multiple random seeds or statistical significance of the misalignment metric are not specified with sufficient detail to allow independent verification of the token-conditional claims.
minor comments (2)
- [Abstract] Abstract: 'Fragile tokens' and 'confident tokens' are introduced without a precise operational definition (e.g., threshold on loss or entropy); a short formal definition would improve readability.
- [Figures/Tables] Figure captions and tables reporting per-token statistics should include the exact number of tokens and models over which the 'uninformative' claim is aggregated.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which identifies key areas for clarification and strengthening. We agree that the Methods section requires expansion for reproducibility and that the links between the counterfactual proxy and the router update results need to be made more explicit. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Counterfactual Analysis): The scoring of alternative routes solely by next-token probability assigned to the realized token from the original trajectory assumes invariance of the target under routing changes. For fragile tokens this assumption is load-bearing, because an alternative route alters the hidden state and subsequent distribution, so the original token may no longer be the relevant target; the paper does not provide a direct test of this invariance.
Authors: We acknowledge that scoring alternatives by the probability assigned to the original realized token assumes the target remains relevant despite the altered hidden state. This is a simplifying assumption in the proxy, and for fragile tokens it is particularly important since the continuation could shift. The current manuscript does not include a direct test, such as executing alternative routes and measuring changes in the subsequent target distribution. We will revise §4 to explicitly state this limitation of the local proxy metric, discuss its implications for interpretation, and note that the structural argument from the LM loss and load-balancing objective, together with cross-model replication, provides complementary support for the observed pattern. revision: partial
-
Referee: [§5] §5 (Router Update Experiment): While the final-layer router fine-tuning improves pass@K, the experiment does not retroactively validate the per-token proxy used to label tokens as fragile or to assert existence of superior routes inside the frozen model; the benchmark gains could arise from a different mechanism than the one identified in the counterfactual analysis.
Authors: We agree that the router-update results demonstrate a performance benefit from final-layer router adjustment but do not directly validate that the gains arise specifically from correcting the fragile-token misroutes identified by the counterfactual proxy; other mechanisms are possible. In the revision we will add analysis that examines how the fine-tuned router alters routing decisions on the tokens previously labeled fragile, and we will correlate those changes with the original proxy scores. We will also include a discussion of alternative explanations for the pass@K improvements to clarify the connection between the two parts of the work. revision: partial
-
Referee: Methods section: The sampling procedure for equal-compute alternatives, the definition of 'verified reasoning trajectory,' the number of alternatives per token, and controls for multiple random seeds or statistical significance of the misalignment metric are not specified with sufficient detail to allow independent verification of the token-conditional claims.
Authors: We thank the referee for highlighting the insufficient detail. In the revised manuscript we will expand the Methods section to specify: the exact sampling procedure used to generate equal-compute alternative routes, the definition and verification criteria for reasoning trajectories, the number of alternatives evaluated per token, the random seeds employed, and the statistical tests (including significance thresholds) applied to the misalignment metrics. These additions will enable independent replication of the token-conditional findings. revision: yes
- A direct empirical test of the invariance of the target token under alternative routing for fragile tokens.
Circularity Check
No significant circularity; empirical analysis is self-contained
full rationale
The paper performs direct empirical comparisons inside frozen models: for each token it samples equal-compute alternative routes and scores them by next-token probability on the realized token from a verified trajectory. No equations or derivations reduce by construction to fitted parameters, self-definitions, or self-citations. The structural observation about top-k training (loss only on executed route, load balancing on aggregates) is a general property of the objective, not a self-referential prediction. The router-only update experiment measures downstream pass@K directly and does not rely on the per-token proxy for its validity. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[3]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review arXiv 2006
-
[4]
Adaptive mixtures of local experts , author=. Neural computation , volume=. 1991 , publisher=
work page 1991
-
[5]
International conference on machine learning , pages=
Glam: Efficient scaling of language models with mixture-of-experts , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[6]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
St-moe: Designing stable and transferable sparse expert models , author=. arXiv preprint arXiv:2202.08906 , year=
work page internal anchor Pith review arXiv
-
[12]
International Conference on Machine Learning , pages=
Base layers: Simplifying training of large, sparse models , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[13]
Advances in Neural Information Processing Systems , volume=
Mixture-of-experts with expert choice routing , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
From sparse to soft mixtures of experts.arXiv preprint arXiv:2308.00951,
From sparse to soft mixtures of experts , author=. arXiv preprint arXiv:2308.00951 , year=
-
[15]
arXiv preprint arXiv:2412.14711 , year=
Remoe: Fully differentiable mixture-of-experts with relu routing , author=. arXiv preprint arXiv:2412.14711 , year=
-
[16]
Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv:2408.15664,
Auxiliary-loss-free load balancing strategy for mixture-of-experts , author=. arXiv preprint arXiv:2408.15664 , year=
-
[17]
Openmoe: An early effort on open mixture-of-experts language models , author=. arXiv preprint arXiv:2402.01739 , year=
-
[18]
Olmoe: Open mixture-of-experts language models
Olmoe: Open mixture-of-experts language models , author=. arXiv preprint arXiv:2409.02060 , year=
-
[19]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
A closer look into mixture-of-experts in large language models , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
work page 2025
-
[20]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Let the expert stick to his last: Expert-specialized fine-tuning for sparse architectural large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[21]
NeurIPS 2025 Workshop on Structured Probabilistic Inference \ & \ Generative Modeling , year=
DenseMixer: Improving MoE Post-Training with Precise Router Gradient , author=. NeurIPS 2025 Workshop on Structured Probabilistic Inference \ & \ Generative Modeling , year=
work page 2025
-
[22]
Findings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
Exploration-Driven Reinforcement Learning for Expert Routing Improvement in Mixture-of-Experts Language Models , author=. Findings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
work page 2025
-
[23]
arXiv preprint arXiv:2509.22745 , year=
Defending MoE LLMs against Harmful Fine-Tuning via Safety Routing Alignment , author=. arXiv preprint arXiv:2509.22745 , year=
-
[24]
arXiv preprint arXiv:2603.24984 , year=
MoE-GRPO: Optimizing Mixture-of-Experts via Reinforcement Learning in Vision-Language Models , author=. arXiv preprint arXiv:2603.24984 , year=
-
[25]
The Fourteenth International Conference on Learning Representations , year=
Balancing the Experts: Unlocking LoRA-MoE for GRPO via Mechanism-Aware Rewards , author=. The Fourteenth International Conference on Learning Representations , year=
-
[26]
Certain Head, Uncertain Tail: Expert-Sample for Test-Time Scaling in Fine-Grained MoE
Certain Head, Uncertain Tail: Expert-Sample for Test-Time Scaling in Fine-Grained MoE , author=. arXiv preprint arXiv:2602.02443 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Ban&Pick: Achieving Free Performance Gains and Inference Speedup via Smarter Routing in MoE-LLMs , author=. arXiv e-prints , pages=
-
[28]
arXiv preprint arXiv:2504.07964 , year=
C3po: Critical-layer, core-expert, collaborative pathway optimization for test-time expert re-mixing , author=. arXiv preprint arXiv:2504.07964 , year=
-
[29]
Zhongyang Li, Ziyue Li, and Tianyi Zhou
R2-t2: Re-routing in test-time for multimodal mixture-of-experts , author=. arXiv preprint arXiv:2502.20395 , year=
-
[30]
Awakening Dormant Experts:Counterfactual Routing to Mitigate MoE Hallucinations
Awakening Dormant Experts: Counterfactual Routing to Mitigate MoE Hallucinations , author=. arXiv preprint arXiv:2604.14246 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model , author=. arXiv preprint arXiv:2405.04434 , year=
work page internal anchor Pith review arXiv
-
[32]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[34]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Direct preference optimization with an offset , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
work page 2024
-
[36]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Wpo: Enhancing rlhf with weighted preference optimization , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[37]
Phi-4 technical report , author=. arXiv preprint arXiv:2412.08905 , year=
work page internal anchor Pith review arXiv
-
[38]
Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability , author=. arXiv preprint arXiv:2411.19943 , year=
-
[39]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. arXiv preprint arXiv:2506.01939 , year=
work page internal anchor Pith review arXiv
-
[40]
Stablemoe: Stable routing strategy for mixture of experts.arXiv preprint arXiv:2204.08396,
Stablemoe: Stable routing strategy for mixture of experts , author=. arXiv preprint arXiv:2204.08396 , year=
-
[41]
Advances in Neural Information Processing Systems , volume=
On the representation collapse of sparse mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.