A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
Pith reviewed 2026-05-20 23:12 UTC · model grok-4.3
The pith
Agent skills serve as reusable procedural artifacts that let LLM agents execute tasks reliably without repeated low-level reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
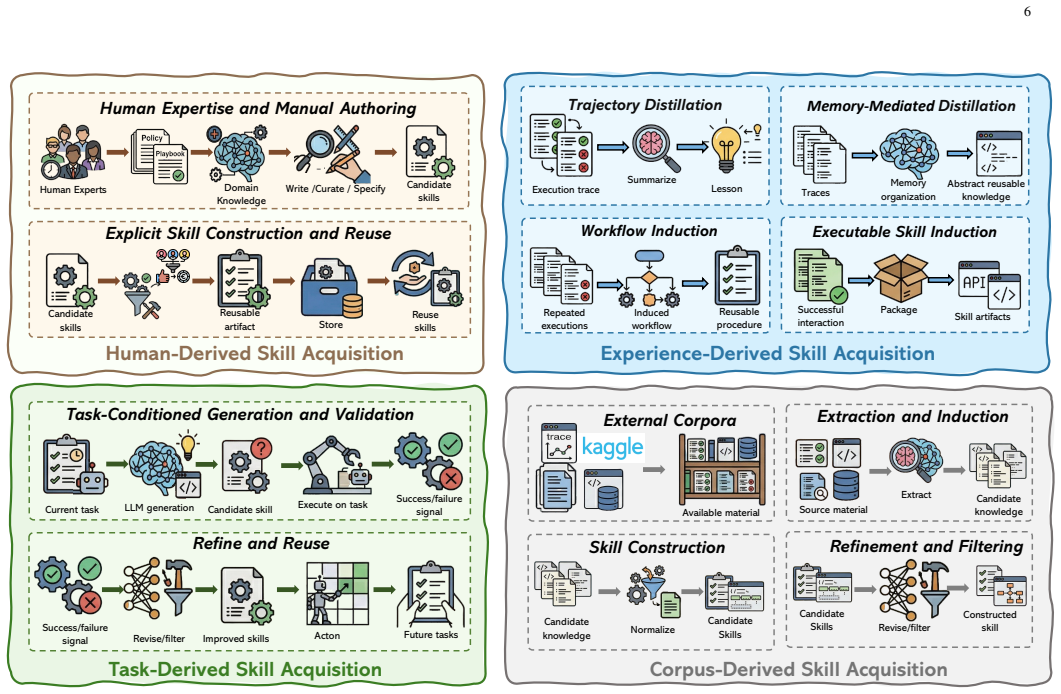
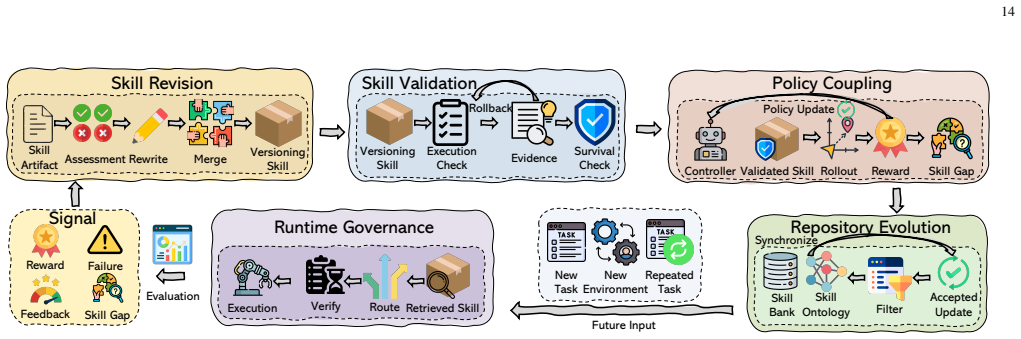
The paper establishes that skills, as reusable procedural artifacts coordinating tools, memory, and runtime context, form the key operational layer complementing agents' high-level reasoning, and organizes the literature around the four stages of representation, acquisition, retrieval, and evolution to advance scalability in LLM agent systems.
What carries the argument
The four-stage agent skill lifecycle consisting of representation, acquisition, retrieval, and evolution, which structures the review of techniques for creating and maintaining reusable skills.
If this is right
- Skills enable reliable execution across similar tasks by reusing proven procedures.
- Systems become more scalable as new tasks leverage existing skill libraries rather than building from scratch.
- Maintainability improves through structured updates and evolution of skills over time.
- Interoperability between different agent frameworks increases with standardized skill representations.
- Applications in complex workflows gain robustness from composable skill combinations.
Where Pith is reading between the lines
- Developers could build shared skill repositories that accelerate agent development across organizations.
- The lifecycle model might extend to non-LLM agents, such as those using traditional planning algorithms.
- Future research could explore automated verification methods for skill quality within this framework.
- Integration with memory systems could create self-improving skill collections.
Load-bearing premise
The diverse literature on LLM-based agents fits into the proposed four stages of the skill lifecycle without forcing unnatural categorizations or leaving out important work.
What would settle it
Identification of a substantial set of agent skill techniques or papers that cannot be classified into any of the four stages: representation, acquisition, retrieval, or evolution.
Figures








read the original abstract
Large language model (LLM)-based agents that reason, plan, and act through tools, memory, and structured interaction are emerging as a promising paradigm for automating complex workflows. Recent systems such as OpenClaw and Claude Code exemplify a broader shift from passive response generation to action-oriented task execution. Yet as agents move toward open-ended, real-world deployment, relying on from-scratch reasoning and low-level tool calls for every task become increasingly inefficient, error-prone, and hard to maintain. This survey examines this challenge through the lens of \emph{agent skills}, which we define as reusable procedural artifacts that coordinate tools, memory, and runtime context under task-specific constraints. Under this view, agents and skills play complementary roles: agents handle high-level reasoning and planning, while skills form the operational layer that enables reliable, reusable, and composable execution. Skills are therefore central to the scalability, robustness, and maintainability of modern agent systems. We organize the literature around four stages of the agent skill lifecycle -- representation, acquisition, retrieval, and evolution -- and review representative methods, ecosystem resources, and application settings across each stage. We conclude by discussing open challenges in quality control, interoperability, safe updating, and long-term capability management. All related resources, including research papers, open-source data, and projects, are collected for the community in \textcolor{blue}{https://github.com/JayLZhou/Awesome-Agent-Skills}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys LLM-based agent skills, defining them as reusable procedural artifacts that coordinate tools, memory, and runtime context under task-specific constraints. It argues that agents and skills play complementary roles, with skills forming the operational layer for reliable, reusable, and composable execution, thereby central to scalability, robustness, and maintainability. The literature is organized around four stages of the agent skill lifecycle—representation, acquisition, retrieval, and evolution—with reviews of representative methods, ecosystem resources, and applications in each stage. Open challenges in quality control, interoperability, safe updating, and long-term capability management are discussed, and all resources are collected in a GitHub repository.
Significance. If the four-stage taxonomy provides a non-forced and reasonably complete partition of the literature, the survey would offer a useful organizing framework for researchers building scalable agent systems. The explicit collection of papers, data, and projects in the linked GitHub repository is a concrete strength that enhances reproducibility and community utility beyond the textual review.
major comments (1)
- [Abstract and lifecycle organization section] The central organizational claim—that the existing literature partitions cleanly into the four stages of representation, acquisition, retrieval, and evolution without major omissions or forced categorizations—is load-bearing for the survey's practical value (see Abstract and the opening of the lifecycle section). The manuscript does not supply explicit selection criteria, coverage statistics, or a dedicated discussion of cross-stage methods (e.g., online skill refinement that interleaves acquisition and retrieval), leaving open the risk that the taxonomy imposes artificial boundaries as noted in the stress-test concern.
minor comments (2)
- [Review sections for each lifecycle stage] A summary table or figure listing representative methods per stage with key references would improve readability and allow readers to quickly assess coverage.
- [Conclusion] The GitHub repository link is mentioned but could be accompanied by a brief description of its structure and update policy in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential utility of the four-stage taxonomy and the GitHub repository. We address the major comment below and will revise the manuscript accordingly to strengthen the presentation of the taxonomy.
read point-by-point responses
-
Referee: [Abstract and lifecycle organization section] The central organizational claim—that the existing literature partitions cleanly into the four stages of representation, acquisition, retrieval, and evolution without major omissions or forced categorizations—is load-bearing for the survey's practical value (see Abstract and the opening of the lifecycle section). The manuscript does not supply explicit selection criteria, coverage statistics, or a dedicated discussion of cross-stage methods (e.g., online skill refinement that interleaves acquisition and retrieval), leaving open the risk that the taxonomy imposes artificial boundaries as noted in the stress-test concern.
Authors: We agree that the manuscript would benefit from greater transparency regarding how the taxonomy was constructed. The four stages reflect a natural lifecycle progression observed across the surveyed literature, rather than an imposed partition, but we acknowledge that explicit documentation of selection criteria and coverage would help readers evaluate completeness and potential boundary issues. In the revised version, we will add a dedicated subsection (likely in the introduction or at the start of the lifecycle organization section) that outlines the literature search methodology, inclusion criteria, time frame, and approximate coverage statistics (e.g., number of papers reviewed per stage). We will also include a new discussion paragraph or subsection addressing cross-stage methods, with concrete examples such as online skill refinement that interleaves acquisition and retrieval, and how such hybrid approaches are handled or noted within the taxonomy. This addition will explicitly discuss overlaps and mitigate concerns about artificial boundaries. revision: yes
Circularity Check
Survey organizes external literature without self-referential derivation
full rationale
This paper is a literature survey that defines agent skills and organizes existing external work into four lifecycle stages (representation, acquisition, retrieval, evolution) as an organizational framework. It reviews representative methods and resources from the broader literature rather than deriving new quantities, predictions, or results from fitted parameters, self-citations, or internal equations. The complementary roles of agents and skills are presented as a definitional viewpoint to motivate the survey structure, with no load-bearing steps that reduce claims to inputs by construction. No uniqueness theorems, ansatzes, or renamings of known results are invoked in a self-referential manner. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We organize the literature around four stages of the agent skill lifecycle — representation, acquisition, retrieval, and evolution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Adaptive Multi-Resolution Procedural Knowledge Compression for Large Language Models
SKIM is an adaptive multi-resolution soft-token framework that compresses procedural skills while aiming to preserve logical dependencies and task performance better than prior compression methods.
-
Skill Coverage: A Test Adequacy Metric for Agent Skills
Skill coverage is a binary test adequacy metric that extracts observable behavior constraints from skill documents and judges whether trajectories provide sufficient evidence to cover each constraint, revealing 39.90-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.