Recognition: 1 theorem link
· Lean TheoremImplicit Preference Alignment for Human Image Animation
Pith reviewed 2026-05-11 02:35 UTC · model grok-4.3
The pith
Implicit Preference Alignment improves hand motion quality in human image animation by maximizing likelihood of self-generated high-quality samples without requiring paired preference data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
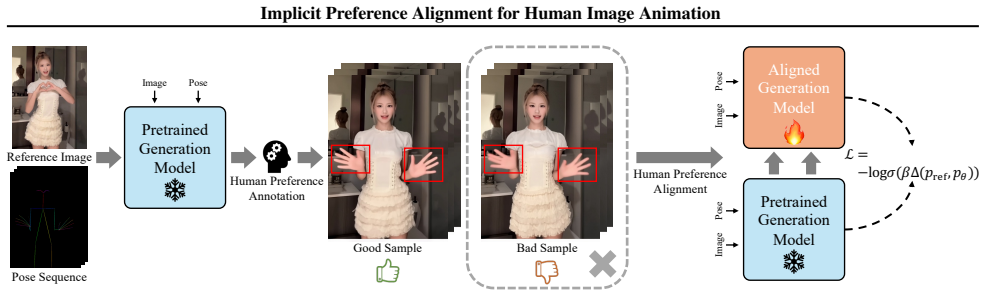
The paper shows that a model can be aligned to human preferences for hand quality by maximizing the probability of its own self-generated high-quality samples under an implicit reward formulation while adding a KL-style penalty against the pretrained prior, and that this process, when localized to hand regions, yields measurable gains in animation quality without any explicit preference pairs.
What carries the argument
Implicit Preference Alignment, an implicit-reward-maximization objective that boosts likelihood of high-quality self-samples while penalizing deviation from the pretrained prior, together with Hand-Aware Local Optimization that restricts the alignment gradient to hand pixels.
If this is right
- Hand generation quality rises in the final animated videos.
- Preference-style post-training becomes practical for any dynamic region where paired data is hard to collect.
- The same implicit-reward loop can be applied as a lightweight fine-tuning stage after initial training of animation models.
- The barrier to constructing preference datasets for video tasks drops sharply because only self-generated outputs are needed.
Where Pith is reading between the lines
- The approach may transfer to other high-complexity motion problems such as facial animation or cloth dynamics where paired comparisons are equally costly.
- Repeated self-generation and re-alignment cycles could create a form of iterative self-improvement for generative video models.
- The method suggests that explicit human feedback can sometimes be replaced by careful filtering of a model's own outputs when the base model already produces a useful distribution of candidates.
Load-bearing premise
That samples the model itself generates can be trusted as high-quality proxies for human preference and that increasing their likelihood will produce outputs humans actually prefer in the hand regions.
What would settle it
A controlled experiment in which applying IPA produces no improvement (or a decline) in hand quality scores or in side-by-side human preference ratings compared with the unmodified base model on the same test animations.
Figures








read the original abstract
Human image animation has witnessed significant advancements, yet generating high-fidelity hand motions remains a persistent challenge due to their high degrees of freedom and motion complexity. While reinforcement learning from human feedback, particularly direct preference optimization, offers a potential solution, it necessitates the construction of strict preference pairs. However, curating such pairs for dynamic hand regions is prohibitively expensive and often impractical due to frame-wise inconsistencies. In this paper, we propose Implicit Preference Alignment (IPA), a data-efficient post-training framework that eliminates the need for paired preference data. Theoretically grounded in implicit reward maximization, IPA aligns the model by maximizing the likelihood of self-generated high-quality samples while penalizing deviations from the pretrained prior. Furthermore, we introduce a Hand-Aware Local Optimization mechanism to explicitly steer the alignment process toward hand regions. Experiments demonstrate that our method achieves effective preference optimization to enhance hand generation quality, while significantly lowering the barrier for constructing preference data. Codes are released at https://github.com/mdswyz/IPA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Implicit Preference Alignment (IPA), a post-training framework for human image animation that performs preference optimization without constructing paired preference data. It aligns the model by maximizing the likelihood of self-generated high-quality samples while penalizing deviations from the pretrained prior (implicit reward maximization), and introduces Hand-Aware Local Optimization to focus the process on hand regions. The abstract claims this yields effective improvements in hand generation quality with lower data construction costs.
Significance. If the quality selection for self-generated samples can be shown to be independent and correlated with human preferences, and if the local optimization demonstrably improves hand fidelity without introducing artifacts, the approach would offer a practical reduction in the cost of preference alignment for generative video models, especially for high-DoF regions like hands.
major comments (2)
- [Abstract] Abstract: The central claim rests on implicit reward maximization over 'self-generated high-quality samples.' No independent quality criterion, external scorer, human validation step, or proxy metric with established correlation to human hand-preference judgments is described. Without such a mechanism, the selection process risks circularity, where the model reinforces its own failure modes rather than aligning to external preferences.
- [Abstract] Abstract (Hand-Aware Local Optimization): The localization of the loss to hand regions is presented as steering the alignment, but the description provides no derivation, loss formulation, or ablation showing that this localization is necessary for the claimed gains versus a global implicit alignment. This leaves open whether the hand-specific improvements are attributable to the core IPA mechanism or to the added localization heuristic.
minor comments (2)
- The abstract states that codes are released at a GitHub link; confirming that the released code includes the exact quality-selection procedure and training details would strengthen reproducibility.
- Consider expanding the related-work discussion to include recent implicit-reward or self-play alignment methods outside the animation domain for clearer positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications from the manuscript and indicate planned revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim rests on implicit reward maximization over 'self-generated high-quality samples.' No independent quality criterion, external scorer, human validation step, or proxy metric with established correlation to human hand-preference judgments is described. Without such a mechanism, the selection process risks circularity, where the model reinforces its own failure modes rather than aligning to external preferences.
Authors: We agree the abstract is brief and does not explicitly detail the quality selection mechanism. The full manuscript (Section 3.2) grounds the implicit reward in the difference between the aligned model likelihood and the pretrained prior, with high-quality samples defined as those for which the aligned model assigns higher probability than the prior while remaining close to it. This formulation is intended to avoid pure self-reinforcement by anchoring to the prior. However, we acknowledge the referee's point on the need for an independent check. In the revision we will expand the abstract to note that sample selection is further filtered by an off-the-shelf hand-pose confidence score (independent of the animation model) and will add a short human-preference correlation study in the experiments to quantify alignment with human judgments. revision: yes
-
Referee: [Abstract] Abstract (Hand-Aware Local Optimization): The localization of the loss to hand regions is presented as steering the alignment, but the description provides no derivation, loss formulation, or ablation showing that this localization is necessary for the claimed gains versus a global implicit alignment. This leaves open whether the hand-specific improvements are attributable to the core IPA mechanism or to the added localization heuristic.
Authors: The full manuscript (Section 3.3) derives the Hand-Aware Local Optimization as a spatially masked variant of the IPA objective, where the mask is obtained from an external pose estimator and the loss is applied only inside hand bounding boxes. The derivation follows from the observation that hand regions exhibit higher motion complexity and thus require focused gradient updates to prevent the global loss from being dominated by easier body regions. Section 5.3 already contains an ablation comparing global IPA versus the localized version, showing that localization yields the reported hand-quality gains while global IPA alone produces smaller improvements and occasional artifacts in non-hand areas. We will revise the abstract to briefly reference this formulation and ablation so the contribution is clearer. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents IPA as a post-training framework grounded in implicit reward maximization, where the model maximizes likelihood on self-generated high-quality samples while penalizing deviation from the prior, augmented by a Hand-Aware Local Optimization step. No equations or sections reduce the central alignment claim to a self-definition, fitted input renamed as prediction, or load-bearing self-citation chain. The method introduces an explicit localization mechanism and claims data efficiency by avoiding paired data, with the derivation remaining self-contained against external benchmarks rather than tautological. The quality designation for samples is part of the proposed framework but does not exhibit a quoted reduction to the model's own outputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theoretically grounded in implicit reward maximization, IPA aligns the model by maximizing the likelihood of self-generated high-quality samples while penalizing deviations from the pretrained prior.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R., Bai, B., Chellappa, R., and Graf, H
Balaji, Y ., Min, M. R., Bai, B., Chellappa, R., and Graf, H. P. Conditional gan with discriminative filter genera- tion for text-to-video synthesis. InProceedings of the Twenty-Eighth International Joint Conference on Artifi- cial Intelligence, pp. 1995–2001,
work page 1995
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., Jampani, V ., and Rombach, R. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Cheng, G., Gao, X., Hu, L., Hu, S., Huang, M., Ji, C., Li, J., Meng, D., Qi, J., Qiao, P., et al. Wan-animate: Unified character animation and replacement with holistic replication.arXiv preprint arXiv:2509.14055,
-
[4]
arXiv preprint arXiv:2302.08215 , year=
Go, D., Korbak, T., Kruszewski, G., Rozen, J., Ryu, N., and Dymetman, M. Aligning language models with prefer- ences through f-divergence minimization.arXiv preprint arXiv:2302.08215,
-
[5]
H., Ghandeharioun, A., Ferguson, C., Lapedriza, A., Jones, N., Gu, S., and Picard, R
Jaques, N., Shen, J. H., Ghandeharioun, A., Ferguson, C., Lapedriza, A., Jones, N., Gu, S., and Picard, R. Human- centric dialog training via offline reinforcement learn- ing. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pp. 3985–4003,
work page 2020
-
[6]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al. Hunyuan- video: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
URLhttps://arxiv.org/abs/2506.15742. 10 Implicit Preference Alignment for Human Image Animation Li, S., Kallidromitis, K., Gokul, A., Kato, Y ., and Kozuka, K. Aligning diffusion models by optimizing human utility. Advances in Neural Information Processing Systems, 37: 24897–24925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Peng, X. B., Kumar, A., Zhang, G., and Levine, S. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177,
work page internal anchor Pith review arXiv 1910
-
[9]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., and Gelly, S. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717,
work page internal anchor Pith review arXiv
-
[10]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W....
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Motion inversion for video customization
Wang, X., Zhang, S., Gao, C., Wang, J., Zhou, X., Zhang, Y ., Yan, L., and Sang, N. Unianimate: Taming unified video diffusion models for consistent human image animation. Science China Information Sciences, 68(10):1–14, 2025a. Wang, X., Zhang, S., Tang, L., Zhang, Y ., Gao, C., Wang, Y ., and Sang, N. Unianimate-dit: Human image anima- tion with large-sc...
-
[12]
Fine-Tuning Language Models from Human Preferences
Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[13]
more anatomically correct, stable, and artifact-free hand structures,
Tab. 9 lists the performance metrics across a wide range ofβ values from 200 to 2000 on both the TikTok benchmark and our proposed benchmark. The numerical data corroborates our analysis in Sec. 5.3. A.6. Qualitative Analysis of Ablation Study for Differentβ We now visually analyze the results generated by models trained with varying β to further investig...
work page 2000
-
[14]
For β= 200 , the model produces anatomically impossible artifacts (i.e., an extraneous third hand)
15 Implicit Preference Alignment for Human Image Animation 𝛽=2000 𝛽=600 𝛽=200 Figure 6.Visual results for different β. For β= 200 , the model produces anatomically impossible artifacts (i.e., an extraneous third hand). When β= 2000 , the generated hands suffer from blurry artifacts and distortions. For β= 600 , the generated hands exhibit clear structures...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.