VISOR: A Vision-Language Model-based Test Oracle for Testing Robots
Pith reviewed 2026-05-20 22:20 UTC · model grok-4.3
The pith
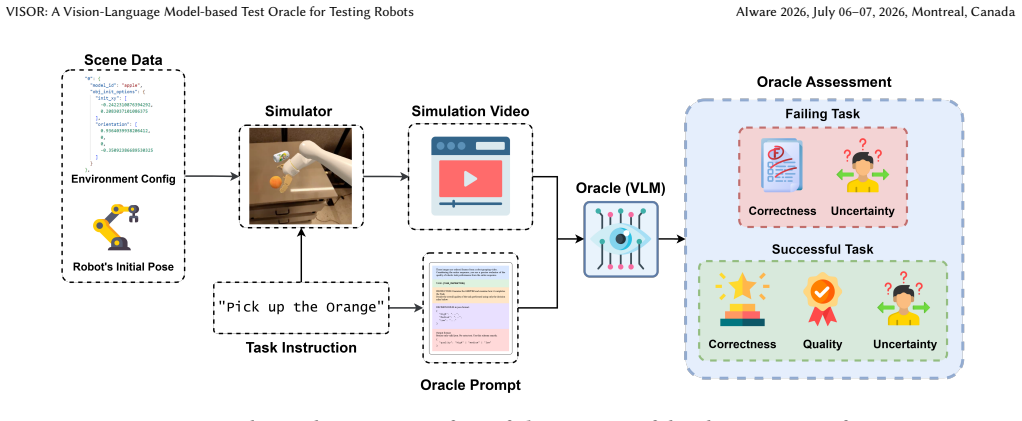
VISOR uses vision-language models to automatically judge robot task success and quality from videos without task-specific rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VISOR is an approach that applies vision-language models to robot testing videos to produce automated assessments of task correctness, task quality, and the model's own uncertainty, evaluated using GPT and Gemini on four robotic tasks with over 1,000 videos where Gemini shows higher recall and GPT higher precision but with low correlation between uncertainty and correctness.
What carries the argument
VISOR, a VLM-based test oracle that processes video footage of robot tasks to generate correctness, quality, and uncertainty scores without requiring task-specific symbolic rules or fine-tuning.
Load-bearing premise
Vision-language models can reliably interpret robot video footage to judge both binary task success and continuous quality without task-specific fine-tuning or symbolic rules.
What would settle it
Running VISOR on a new collection of robot videos where human experts disagree with the VLM judgments on a large fraction of cases for either success or quality would falsify the claim that it provides reliable automated assessment.
Figures

read the original abstract
Testing robots requires assessing whether they perform their intended tasks correctly, dependably, and with high quality, a challenge known as the test oracle problem in software testing. Traditionally, this assessment relies on task-specific symbolic oracles for task correctness and on human manual evaluation of robot behavior, which is time-consuming, subjective, and error-prone. To address this, we propose VISOR, a Vision-Language Model (VLM)-based approach for automated test oracle assessment that eliminates the need of expensive human evaluations. VISOR performs automated evaluation of task correctness and quality, addressing the limitations of existing symbolic test oracles, which are task-specific and provide pass/fail judgments without explicitly quantifying task quality. Given the inherent uncertainty in VLMs, VISOR also explicitly quantifies its own uncertainty during test assessments. We evaluated VISOR using two VLMs, i.e., GPT and Gemini, across four robotic tasks on over 1,000 videos. Results show that Gemini achieves higher recall while GPT achieves higher precision. However, both models show low correlation between uncertainty and correctness, which prevents using uncertainty as a correctness predictor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VISOR, a vision-language model (VLM)-based test oracle for evaluating robot task performance from videos. It claims to automate assessment of both binary task correctness and continuous task quality using off-the-shelf VLMs like GPT and Gemini, while quantifying uncertainty, thereby eliminating the need for task-specific symbolic oracles and human evaluations. Evaluation on over 1,000 videos from four robotic tasks shows Gemini with higher recall and GPT with higher precision for correctness, but low correlation between uncertainty and correctness.
Significance. If validated, this approach could meaningfully reduce dependence on manual human evaluation in robot testing by offering a generalizable oracle that quantifies quality alongside correctness. The scale of the empirical evaluation (1000+ videos) and transparent reporting of the low uncertainty-correctness correlation are positive elements that support reproducibility and honest assessment of limitations.
major comments (1)
- [Evaluation / Results] Evaluation section and abstract: while precision and recall results address binary task correctness against ground truth, the manuscript provides no correlation, agreement, or error metrics (e.g., Pearson r, Cohen's kappa, or mean absolute error) comparing the continuous VLM quality scores to independent human expert ratings on the same videos. This directly undermines the central claim that VISOR eliminates human evaluation for quality assessment, as the quality component lacks the direct validation reported for correctness.
minor comments (2)
- [Abstract] Abstract: the results summary mentions only correctness metrics and uncertainty correlation but omits any description of quality-score findings, which should be added for completeness given that quality assessment is part of the stated contribution.
- [Methods] Methods: additional details on video data splits, how ground-truth labels were obtained (including inter-rater reliability), exact VLM prompts or rubrics for quality scoring, and the precise definition of the quality metric (e.g., numeric scale) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and recommendation for major revision. We address the single major comment point-by-point below, acknowledging where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation section and abstract: while precision and recall results address binary task correctness against ground truth, the manuscript provides no correlation, agreement, or error metrics (e.g., Pearson r, Cohen's kappa, or mean absolute error) comparing the continuous VLM quality scores to independent human expert ratings on the same videos. This directly undermines the central claim that VISOR eliminates human evaluation for quality assessment, as the quality component lacks the direct validation reported for correctness.
Authors: We agree that the current evaluation validates binary correctness against ground-truth labels but does not report quantitative agreement metrics (Pearson r, MAE, etc.) between the continuous VLM quality scores and independent human expert ratings on the same videos. This is a genuine gap: while the manuscript positions VISOR as removing the need for human evaluation of both correctness and quality, only the former receives direct empirical validation. In the revised version we will add a targeted human study on a representative subset of the 1,000+ videos. Expert raters will provide continuous quality scores; we will then compute and report Pearson correlation, Cohen’s kappa (after discretization), and mean absolute error between VLM and human scores, together with inter-rater reliability. These results will be inserted into the Evaluation section and referenced in the abstract. revision: yes
Circularity Check
No circularity: empirical application of off-the-shelf VLMs with direct ground-truth comparison
full rationale
The paper is an empirical evaluation applying existing VLMs (GPT-4 and Gemini) to over 1,000 robot videos across four tasks. It reports precision/recall for binary correctness and notes low uncertainty-correctness correlation, without any equations, fitted parameters, or internal derivations. Claims rest on direct measurement against ground truth rather than any self-referential modeling or prediction that reduces to inputs by construction. No load-bearing self-citations or ansatzes are invoked in the provided abstract and evaluation summary; the central results are externally falsifiable via the video dataset and human ground truth.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can extract task correctness and quality signals from raw robot videos without additional training or symbolic scaffolding.
invented entities (1)
-
VISOR system
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VISOR performs automated evaluation of task correctness and quality... using zero-shot prompts... uncertainty quantified via Entropy, MSP, DeepGini
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Results show that Gemini achieves higher recall while GPT achieves higher precision... low correlation between uncertainty and correctness
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, Daniel Dworakowski, Jiaojiao Fan, Michele Fenzi, Francesco Ferroni, Sanja Fidler, Dieter Fox, Songwei Ge, Yunhao Ge, Jinwei Gu, Siddharth Gururani, Ethan He, Jiahui Huang, Jacob Samuel Huffman, Pooya Jannaty, Jingyi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.03575 2025
-
[2]
Andrea Arcuri and Lionel Briand. 2011. A Practical Guide for Using Statistical Tests to Assess Randomized Algorithms in Software Engineering. InProceedings of the 33rd International Conference on Software Engineering(Waikiki, Honolulu, HI, USA)(ICSE ’11). Association for Computing Machinery, New York, NY, USA, 1–10. doi:10.1145/1985793.1985795
-
[3]
Seemal Asif, Mikel Bueno, Pedro Ferreira, Paul Anandan, Ze Zhang, Yue Yao, Gautham Ragunathan, Lloyd Tinkler, Masoud Sotoodeh-Bahraini, Niels Lohse, Phil Webb, Windo Hutabarat, and Ashutosh Tiwari. 2025. Rapid and automated configuration of robot manufacturing cells.Robotics and Computer-Integrated Manufacturing92 (2025), 102862. doi:10.1016/j.rcim.2024.102862
-
[4]
Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor Cărbune, Jason Lin, Jindong Chen, and Abhanshu Sharma
-
[5]
ScreenAI: a vision-language model for UI and infographics understanding. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence(Jeju, Korea)(IJCAI ’24). Article 339, 11 pages. doi:10.24963/ijcai. 2024/339
-
[6]
Radhakisan Baheti and Helen Gill. 2011. Cyber-physical systems.The impact of control technology12, 1 (2011), 161–166
work page 2011
-
[7]
Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo
Earl T. Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo
-
[8]
The Oracle Problem in Software Testing: A Survey.IEEE Trans. Softw. Eng. 41, 5 (May 2015), 507–525. doi:10.1109/TSE.2014.2372785
-
[9]
Christopher M. Bishop. 2006.Pattern Recognition and Machine Learning. Springer
work page 2006
-
[10]
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith LLontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang Tan, Gua...
-
[11]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots. CoRRabs/2503.14734 (2025). arXiv:2503.14734 doi:10.48550/ARXIV.2503.14734
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14734 2025
-
[12]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. 2024. 𝜋0: ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164 2024
-
[13]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14455–14465. doi:10.1109/CVPR52733.2024.01370
-
[14]
Yongchao Chen, Jacob Arkin, Charles Dawson, Yang Zhang, Nicholas Roy, and Chuchu Fan. 2024. AutoTAMP: Autoregressive Task and Motion Planning with LLMs as Translators and Checkers. In2024 IEEE International Conference on Ro- botics and Automation (ICRA). 6695–6702. doi:10.1109/ICRA57147.2024.10611163 AIware 2026, July 06–07, 2026, Montreal, Canada Prasun ...
-
[15]
Patricia Derler, Edward A Lee, and Alberto Sangiovanni Vincentelli. 2011. Mod- eling cyber–physical systems.Proc. IEEE100, 1 (2011), 13–28
work page 2011
-
[16]
Ashour, Fuqian Shi, Simon James Fong, and João Manuel R
Nilanjan Dey, Amira S. Ashour, Fuqian Shi, Simon James Fong, and João Manuel R. S. Tavares. 2018. Medical cyber-physical systems: A survey.J. Med. Syst.42, 4 (March 2018), 13 pages. doi:10.1007/s10916-018-0921-x
-
[17]
Yuqing Du, Ksenia Konyushkova, Misha Denil, Akhil Raju, Jessica Landon, Felix Hill, Nando de Freitas, and Serkan Cabi. 2023. Vision-Language Models as Success Detectors. InProceedings of The 2nd Conference on Lifelong Learning Agents (Proceedings of Machine Learning Research, Vol. 232), Sarath Chandar, Razvan Pascanu, Hanie Sedghi, and Doina Precup (Eds.)...
work page 2023
-
[18]
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wen- tao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. 2025. AHA: A Vision-Language-Model for Detecting and Reasoning Over Failures in Robotic Manipulation. InThe Thirteenth International Conference on Learn- ing Representations, ICLR 2025, Singapore, April 24-28, 20...
work page 2025
-
[19]
Yang Feng, Qingkai Shi, Xinyu Gao, Jun Wan, Chunrong Fang, and Zhenyu Chen. 2020. DeepGini: prioritizing massive tests to enhance the robustness of deep neural networks. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis(Virtual Event, USA)(ISSTA 2020). Association for Computing Machinery, New York, NY, USA, 177...
-
[20]
Gemini Team. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.CoRR abs/2507.06261 (2025). arXiv:2507.06261 doi:10.48550/ARXIV.2507.06261
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[21]
Yanjiang Guo, Yen-Jen Wang, Lihan Zha, and Jianyu Chen. 2024. DoReMi: Ground- ing Language Model by Detecting and Recovering from Plan-Execution Misalign- ment. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 12124–12131. doi:10.1109/IROS58592.2024.10802284
-
[22]
Iryna Hartsock and Ghulam Rasool. 2024. Vision-language models for medical report generation and visual questionanswering: a review.Frontiers Artif. Intell. 7 (2024). doi:10.3389/FRAI.2024.1430984
-
[23]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. 2020. RLBench: The Robot Learning Benchmark & Learning Environment.IEEE Robotics and Automation Letters5, 2 (2020), 3019–3026. doi:10.1109/LRA.2020.2974707
-
[24]
Shinpei Kato, Shota Tokunaga, Yuya Maruyama, Seiya Maeda, Manato Hirabayashi, Yuki Kitsukawa, Abraham Monrroy, Tomohito Ando, Yusuke Fujii, and Takuya Azumi. 2018. Autoware on board: enabling autonomous vehicles with embedded systems. InProceedings of the 9th ACM/IEEE International Confer- ence on Cyber-Physical Systems(Porto, Portugal)(ICCPS ’18). IEEE P...
-
[25]
Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Posner, and Yuke Zhu
-
[26]
IEEE Access8, 199523–199538 (2020) https://doi.org/10.1109/ACCESS
Vision-Language-Action Models for Robotics: A Review Towards Real- World Applications.IEEE Access13 (2025), 162467–162504. doi:10.1109/ACCESS. 2025.3609980
-
[27]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakr- ishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2025. OpenVLA: An Open-Source Vision- Language-Action Model. InProceedings of The 8th Confer...
work page 2025
-
[28]
Chenxuan Li, Jiaming Liu, Guanqun Wang, Xiaoqi Li, Sixiang Chen, Liang Heng, Chuyan Xiong, Jiaxin Ge, Renrui Zhang, Kaichen Zhou, and Shanghang Zhang
-
[29]
arXiv:2405.17418 [cs.CV] doi:10
A Self-Correcting Vision-Language-Action Model for Fast and Slow System Manipulation.CoRRabs/2405.17418 (2025). arXiv:2405.17418 [cs.CV] doi:10. 48550/ARXIV.2405.17418
-
[30]
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. 2024. LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models.CoRRabs/2407.07895 (2024). arXiv:2407.07895 doi:10.48550/ARXIV.2407.07895
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.07895 2024
-
[31]
Shunlei Li, Jin Wang, Rui Dai, Wanyu Ma, Wing Yin Ng, Yingbai Hu, and Zheng Li
-
[32]
https://doi.org/10.1109/iros60139.2025.11247690
RoboNurse-VLA: Robotic Scrub Nurse System based on Vision-Language- Action Model. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 3986–3993. doi:10.1109/IROS60139.2025.11246030
-
[33]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Oier Mees, Karl Pertsch, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jia- jun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. 2025. Evaluating Real-World Robot Manipulation Policies in Simulation. InProceedings of The 8th Conference on Robot Learning (Proceedings of Machine...
work page 2025
-
[34]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Pe- ter Stone. 2023. LIBERO: benchmarking knowledge transfer for lifelong robot learning. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 1939, 16 pages
work page 2023
-
[35]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Asso- ciates Inc., Red Hook, NY, USA, Article 1516, 25 pages
work page 2023
-
[36]
Zeyi Liu, Arpit Bahety, and Shuran Song. 2023. REFLECT: Summarizing Robot Experiences for Failure Explanation and Correction. InProceedings of The 7th Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 229), Jie Tan, Marc Toussaint, and Kourosh Darvish (Eds.). PMLR, 3468–3484. https: //proceedings.mlr.press/v229/liu23g.html
work page 2023
-
[37]
Weifeng Lu, Minghao Ye, Zewei Ye, Ruihan Tao, Shuo Yang, and Bo Zhao. 2025. RoboFAC: A Comprehensive Framework for Robotic Failure Analysis and Cor- rection.CoRRabs/2505.12224 (2025). arXiv:2505.12224 doi:10.48550/ARXIV.2505. 12224
-
[38]
Zhen Luo, Yixuan Yang, Yanfu Zhang, and Feng Zheng. 2025. RoboReflect: A Robotic Reflective Reasoning Framework for Grasping Ambiguous-Condition Objects.CoRRabs/2501.09307 (2025). arXiv:2501.09307 doi:10.48550/ARXIV.2501. 09307
-
[39]
Salvatore S Mangiafico. 2016. Summary and analysis of extension program evaluation in R.Rutgers Cooperative Extension: New Brunswick, NJ, USA125 (2016), 16–22
work page 2016
-
[40]
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaib- hav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. 2025. SmolVLM: Redefining small and efficient multimodal models.CoRRabs/2504.05299 (2025). ar...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.05299 2025
-
[41]
László Monostori, Botond Kádár, Thomas Bauernhansl, Shinsuke Kondoh, Soundar Kumara, Gunther Reinhart, Olaf Sauer, Gunther Schuh, Wilfried Sihn, and Kenichi Ueda. 2016. Cyber-physical systems in manufacturing.CIRP Annals 65, 2 (2016), 621–641. doi:10.1016/j.cirp.2016.06.005
-
[42]
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. 2024. RoboCasa: Large-Scale Simulation of Household Tasks for GeneralistRobots. InRobotics: Science and Systems XX, Delft, The Netherlands, July 15-19, 2024, Dana Kulic, Gentiane Venture, Kostas E. Bekris, and Enrique Coronado (Eds.). d...
-
[43]
OpenAI. 2023. GPT-4 Technical Report.CoRRabs/2303.08774 (2023). arXiv:2303.08774 doi:10.48550/ARXIV.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[44]
Desirè Pantalone, Giulia Satu Faini, Francesca Cialdai, Elettra Sereni, Stefano Bacci, Daniele Bani, Marco Bernini, Carlo Pratesi, PierLuigi Stefàno, Lorenzo Orzalesi, Michele Balsamo, Valfredo Zolesi, and Monica Monici. 2021. Robot- assisted surgery in space: pros and cons. A review from the surgeon’s point of view.npj Microgravity7, 1 (Dec. 2021), 56. d...
-
[45]
Jierui Peng, Yanyan Zhang, Yicheng Duan, Tuo Liang, Vipin Chaudhary, and Yu Yin. 2025. NEBULA: Do We Evaluate Vision-Language-Action Agents Correctly? CoRRabs/2510.16263 (2025). arXiv:2510.16263 doi:10.48550/ARXIV.2510.16263
-
[46]
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. 2025. SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model.CoRR abs/2501.15830 (2025). arXiv:2501.15830 doi:10.48550/ARXIV.2501.15830
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.15830 2025
-
[47]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th Inter- national Conference on Machine Learning (Proceedings of Machi...
work page 2021
-
[48]
Diego Rodríguez-Guerra, Gorka Sorrosal, Itziar Cabanes, and Carlos Calleja
-
[49]
doi:10.1109/ ACCESS.2021.3099287
Human-Robot Interaction Review: Challenges and Solutions for Modern Industrial Environments.IEEE Access9 (2021), 108557–108578. doi:10.1109/ ACCESS.2021.3099287
-
[50]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications.CoRRabs/2402.07927 (2024). arXiv:2402.07927 doi:10.48550/ARXIV.2402.07927
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.07927 2024
-
[51]
VISOR: A Vision-Language Model-based Test Oracle for Testing Robots
Prasun Saurabh, Pablo Valle, Aitor Arrieta, Shaukat Ali, and Paolo Arcaini. 2026. Supplementary material for the paper “VISOR: A Vision-Language Model-based Test Oracle for Testing Robots”. https://doi.org/10.5281/zenodo.19680486
-
[52]
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, Yilin Zhao, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catanzaro, Andrew Tao, Jan Kautz, Zhiding Yu, and Guilin Liu. 2025. Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders. In The Thirteenth International Conference on Learni...
work page 2025
-
[53]
Daeun Song, Jing Liang, Amirreza Payandeh, Amir Hossain Raj, Xuesu Xiao, and Dinesh Manocha. 2025. VLM-Social-Nav: Socially Aware Robot Navigation Through Scoring Using Vision-Language Models.IEEE Robotics and Automation VISOR: A Vision-Language Model-based Test Oracle for Testing Robots AIware 2026, July 06–07, 2026, Montreal, Canada Letters10, 1 (2025),...
-
[54]
Michael Tschannen, Alexey A. Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier J. Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. 2025. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.14786 2025
-
[55]
Pablo Valle, Chengjie Lu, Shaukat Ali, and Aitor Arrieta. 2025. Evaluating Uncertainty and Quality of Visual Language Action-enabled Robots.CoRR abs/2507.17049 (2025). arXiv:2507.17049 doi:10.48550/ARXIV.2507.17049
-
[56]
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. 2022. GIT: A Generative Image- to-text Transformer for Vision and Language.CoRRabs/2205.14100 (2022). arXiv:2205.14100 doi:10.48550/ARXIV.2205.14100
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.14100 2022
-
[57]
Zhijie Wang, Zhehua Zhou, Jiayang Song, Yuheng Huang, Zhan Shu, and Lei Ma. 2025. VLATest: Testing and Evaluating Vision-Language-Action Models for Robotic Manipulation.Proc. ACM Softw. Eng.2, FSE, Article FSE073 (June 2025), 24 pages. doi:10.1145/3729343
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[59]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. 2024. Vision-Language Models for Vision Tasks: A Survey.IEEE Trans. Pattern Anal. Mach. Intell.46, 8 (Aug. 2024), 5625–5644. doi:10.1109/TPAMI.2024.3369699
-
[60]
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. 2024. VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks.CoRRabs/2412.18194 (2024). arXiv:2412.18194 doi:10.48550/ARXIV.2412.18194
-
[61]
Enshen Zhou, Qi Su, Cheng Chi, Zhizheng Zhang, Zhongyuan Wang, Tiejun Huang, Lu Sheng, and He Wang. 2025. Code-as-monitor: Constraint-aware visual programming for reactive and proactive robotic failure detection. InProceedings of the Computer Vision and Pattern Recognition Conference. 6919–6929
work page 2025
-
[62]
Sanketi, Grecia Salazar, Michael S
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, Quan Vuong, Vincent Van- houcke, Huong Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Ser- manet, Pannag R. Sanketi, Grecia Salazar, Michael S. Ryoo, Krista Reymann, Kanishka Rao, Karl Pertsch, Igor Mordatch, Henryk Michale...
-
[63]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. InProceedings of The 7th Conference on Robot Learning (Proceedings of Ma- chine Learning Research, Vol. 229), Jie Tan, Marc Toussaint, and Kourosh Darvish (Eds.). PMLR, 2165–2183. https://proceedings.mlr.press/v229/zitkovich23a.html
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.