Shepherd: A Runtime Substrate Empowering Meta-Agents with a Formalized Execution Trace
Pith reviewed 2026-05-12 03:21 UTC · model grok-4.3
The pith
Shepherd formalizes meta-agent operations as functions on a Git-like execution trace that records every interaction for fast forking and replay.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
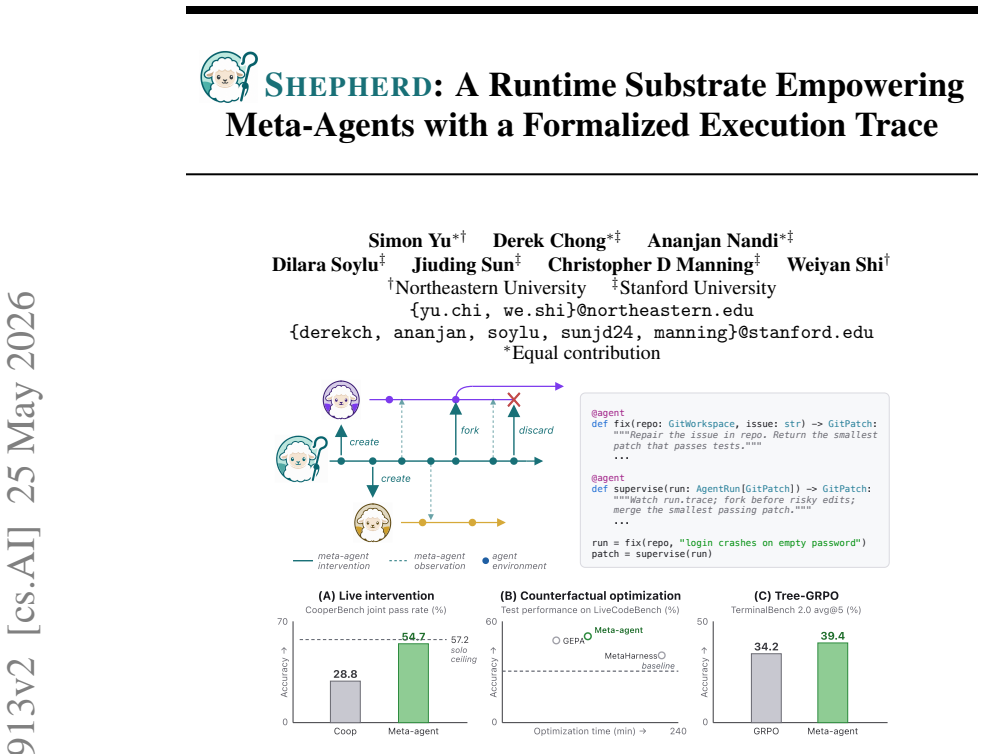
Shepherd records every agent-environment interaction as a typed event in a Git-like execution trace, enabling any past state to be forked and replayed. The substrate forks the agent process and its filesystem five times faster than Docker and reuses more than 95 percent of prompt cache on replay. When applied to runtime intervention, counterfactual meta-optimization, and Tree-RL training, the trace produces measurable gains in pass rates, benchmark scores, and training efficiency across the reported tasks.
What carries the argument
The typed execution trace that stores every agent-environment interaction as an event and supports forking of both the agent process and its filesystem.
If this is right
- A live supervisor using the trace can raise pair-coding pass rates from 28.8 percent to 54.7 percent on CooperBench.
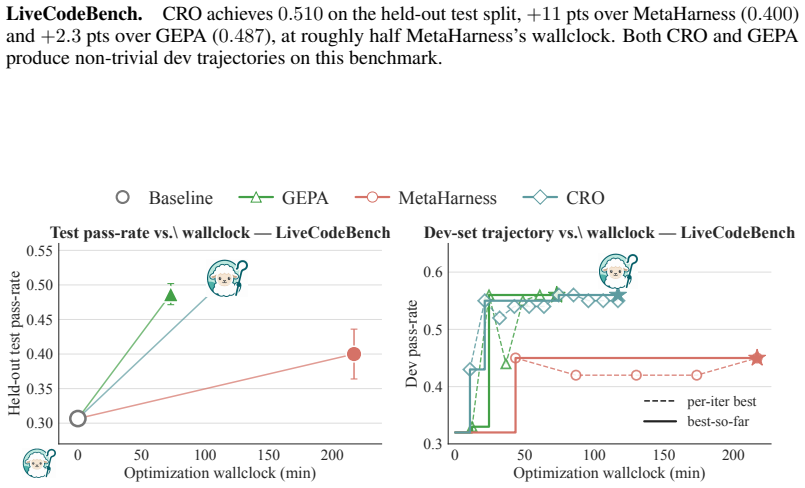
- Branching exploration inside the trace outperforms baselines on four benchmarks by as much as 11 points and reduces wall-clock time by as much as 58 percent.
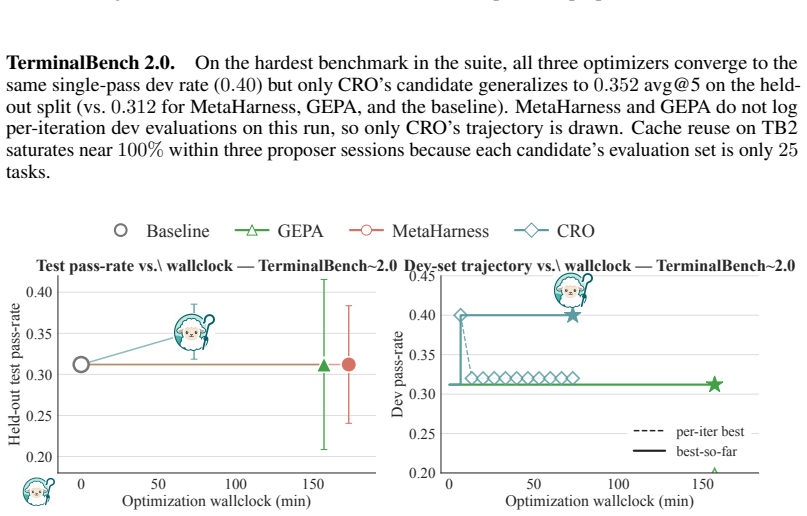
- Forking rollouts at selected turns inside the trace raises TerminalBench-2 performance from 34.2 percent to 39.4 percent.
- Any past agent state captured in the trace can be replayed or branched without restarting the full environment.
Where Pith is reading between the lines
- The same trace structure could let developers version and debug ordinary single-agent systems the way git versions code.
- High cache reuse on replay suggests the mechanism may scale to longer-horizon agent runs where repeated prompt computation would otherwise dominate cost.
- If the Lean mechanization of core operations is extended, it could support machine-checked proofs that certain meta-agent interventions preserve safety properties.
Load-bearing premise
The reported gains in intervention success, optimization scores, and RL performance arise from the trace and forking features rather than from unmeasured differences in experimental setup or implementation.
What would settle it
Run the same three applications with the forking and trace recording disabled while keeping every other component fixed; if the pass-rate, benchmark, and training improvements disappear, the central claim is supported.
Figures
















read the original abstract
As LLM agent systems take on more complex tasks, they increasingly rely on meta-agents: higher-order agents that operate on other agents, much as managers supervise employees. Whatever a meta-agent does: coordinating agents, halting risky actions before execution, or repairing failed runs, requires manipulation of agentic execution at runtime. Existing agentic substrates make this hard: they give meta-agents only plain transcripts and environment snapshots, requiring it to build it's own tooling to reconstruct and orchestrate execution state. Therefore, we introduce Shepherd, a Python substrate grounded in functional programming principles, where an agent's execution is itself a first-class object that a meta-agent can inspect and transform. Every model call, tool call, and environment change becomes a structured event in a Git-like execution trace, where any past state can be forked 5x faster than docker commit and replayed. Three example use cases show Shepherd's versatility: (1) a supervisor agent prevents conflicts among parallel coding agents, lifting CooperBench performance from 28.8% to 54.7%; (2) a counterfactual optimizer repairs agent workflows by proposing edits and replaying runs from the point of changed behavior, outperforming MetaHarness on TerminalBench-2 with 58% lower wall-clock; (3) a meta-agent picks fork points during rollouts to improve credit assignment in long-horizon agentic RL, doubling GRPO's gains on TerminalBench-2. We open-source Shepherd to empower future meta-agents with principled and efficient operations over agentic execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Shepherd, a functional programming model that formalizes meta-agent operations on target agents as functions, with core operations mechanized in Lean. It records every agent-environment interaction as a typed event in a Git-like execution trace, enabling forking and replay of past states. The system forks agent processes and filesystems 5× faster than Docker with >95% prompt-cache reuse on replay. It demonstrates the model in three applications: runtime intervention raising pair-coding pass rates from 28.8% to 54.7% on CooperBench; counterfactual meta-optimization outperforming baselines by up to 11 points with up to 58% wall-clock reduction across four benchmarks; and Tree-RL training improving TerminalBench-2 from 34.2% to 39.4%. These results are presented as establishing Shepherd as efficient infrastructure for programming meta-agents, with the system open-sourced.
Significance. If the empirical claims hold under proper controls, Shepherd could provide a useful formalized runtime substrate for meta-agent development, leveraging execution traces for intervention, optimization, and training. The mechanization of core operations in Lean is a clear strength, supplying machine-checked proofs for the model. Open-sourcing the system is also a positive step that supports reproducibility and community follow-on work.
major comments (1)
- [Abstract] Abstract: the abstract reports specific performance improvements (pair-coding pass rate 28.8%→54.7% on CooperBench, up to 11-point gains with 58% wall-clock reduction, TerminalBench-2 34.2%→39.4%) but supplies no experimental details, baselines, statistical tests, error bars, or methodology. This prevents verification that the gains are attributable to the typed execution trace and forking features rather than unstated factors, which is load-bearing for the central claim that 'these results establish Shepherd as an efficient infrastructure for programming meta-agents.'
Simulated Author's Rebuttal
We thank the referee for their positive assessment of Shepherd's contributions, including the Lean mechanization and open-sourcing, and for the constructive feedback on the abstract. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract reports specific performance improvements (pair-coding pass rate 28.8%→54.7% on CooperBench, up to 11-point gains with 58% wall-clock reduction, TerminalBench-2 34.2%→39.4%) but supplies no experimental details, baselines, statistical tests, error bars, or methodology. This prevents verification that the gains are attributable to the typed execution trace and forking features rather than unstated factors, which is load-bearing for the central claim that 'these results establish Shepherd as an efficient infrastructure for programming meta-agents.'
Authors: The abstract is intentionally concise to highlight key outcomes, following standard academic practice. The full manuscript provides the requested experimental details, including baselines, statistical tests, error bars, and methodology, in the dedicated evaluation sections for each application (runtime intervention, counterfactual meta-optimization, and Tree-RL training). These sections describe controlled experiments that isolate the contributions of the typed execution traces and forking mechanisms, supporting the attribution of the reported gains. The abstract's central claim is thus grounded in the body of the paper rather than standing alone. revision: no
Circularity Check
No circularity: empirical claims rest on reported results without derivations or self-referential reductions
full rationale
The provided abstract contains no equations, derivations, fitted parameters, or self-citations. It introduces Shepherd as a functional model with execution traces and forking, then reports three separate empirical applications (runtime intervention on CooperBench, counterfactual optimization on four benchmarks, Tree-RL on TerminalBench-2) with performance deltas. These results are presented as demonstrations rather than as outputs derived from the system's definition by construction. No load-bearing step reduces a prediction or uniqueness claim to an input fit or prior self-citation; the central infrastructure claim is supported by the listed experimental outcomes, which remain externally verifiable in principle.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean, AlexanderDuality.lean, ArithmeticFromLogic.leanreality_from_one_distinction echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
core operations mechanized in Lean... small algebraic-effects calculus... proof envelopes... typed event in a Git-like execution trace... fork... replay
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.