ReCoVer: Resilient LLM Pre-Training System via Fault-Tolerant Collective and Versatile Workload
Pith reviewed 2026-05-25 05:50 UTC · model grok-4.3
The pith
ReCoVer keeps the number of microbatches per iteration constant to preserve LLM training trajectory after hardware failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
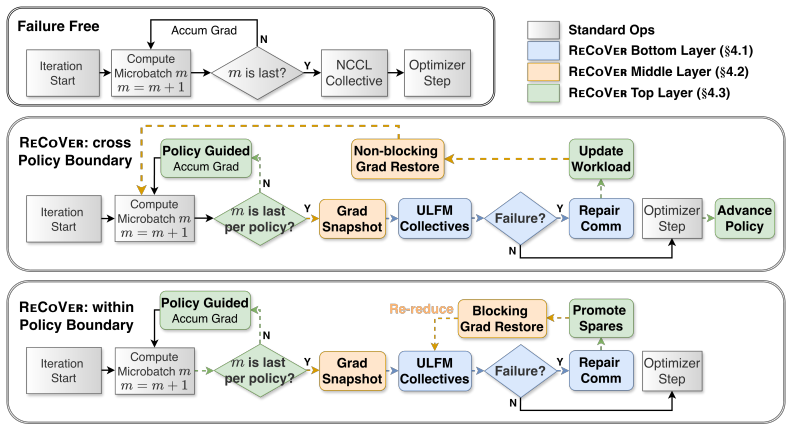
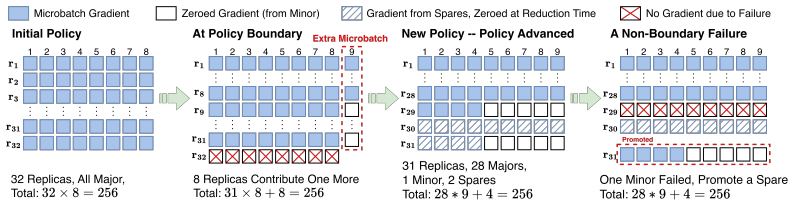
ReCoVer upholds the single invariant that each iteration keeps the number of microbatches constant, ensuring per-iteration gradients remain stochastically equivalent to a failure-free run. The framework is organized as three decoupled protocol layers: fault-tolerant collectives that isolate faults, in-step fine-grained recovery that preserves intra-iteration progress, and versatile-workload policy that redistributes microbatch quotas across survivors. It integrates directly with 3D parallelism and Hybrid Sharded Data Parallel as a drop-in substrate.
What carries the argument
The constant-microbatch invariant per iteration, enforced by fault-tolerant collectives, in-step recovery, and versatile-workload redistribution to keep gradients equivalent despite lost GPUs.
If this is right
- The training trajectory matches a failure-free reference even after 256 GPUs are lost across the run.
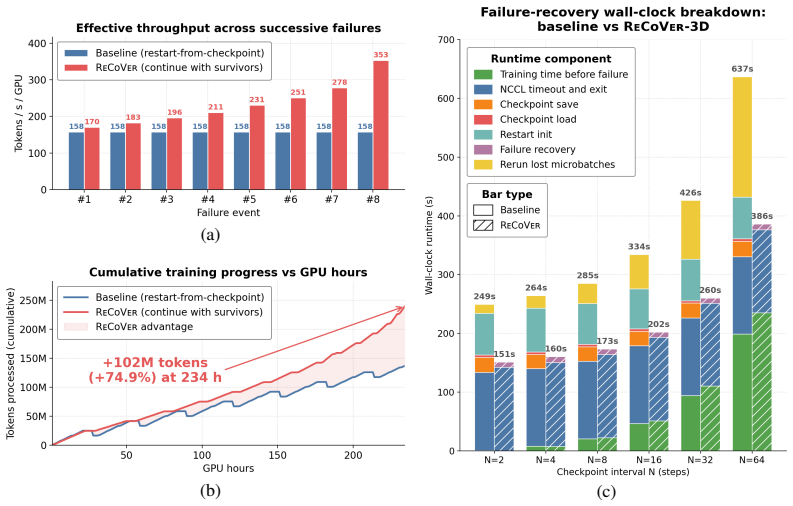
- Effective throughput reaches 2.23 times that of checkpoint-and-restart baselines after successive failures.
- 74.9 percent more tokens are processed in 234 GPU-hours, with the gap increasing as training length grows.
- The design remains compatible with standard 3D parallelism and Hybrid Sharded Data Parallel without code changes.
Where Pith is reading between the lines
- The constant-microbatch rule may allow training runs to skip most full checkpoints once the system is in steady state.
- The same invariant could be tested on other large-scale distributed workloads if their loss surfaces tolerate the same redistribution.
- Because the layers are decoupled, the approach might combine with future collective libraries that already tolerate partial failures.
Load-bearing premise
That keeping the number of microbatches constant per iteration ensures the gradients stay stochastically equivalent to a failure-free run without the recovery mechanisms introducing systematic bias.
What would settle it
A controlled experiment that injects the same sequence of GPU losses into two otherwise identical pre-training runs and checks whether the loss trajectory and final model quality remain statistically indistinguishable from the failure-free reference.
Figures







read the original abstract
Pre-training large language models on massive GPU clusters has made hardware faults routine rather than rare, driving the need for resilient training systems. Yet existing frameworks either focus on specific parallelism schemes or risk drifting away from a failure-free training trajectory. We propose ReCoVer, a resilient LLM pre-training system that upholds a single invariant: each iteration keeps the number of microbatches constant, ensuring per-iteration gradients remain stochastically equivalent to a failure-free run. The framework is organized as three decoupled protocol layers: (1) Fault-tolerant collectives that isolate faults from propagating across replicas; (2) in-step fine-grained recovery that preserves intra-iteration progress and prevents gradient corruption; (3) versatile-workload policy that dynamically redistributes microbatch quotas across the survivors. The design is parallelism-agnostic, integrating directly with both 3D parallelism and Hybrid Sharded Data Parallel (HSDP) as a drop-in substrate. We evaluate our implementation on end-to-end pre-training tasks for up to 512 GPUs, ReCoVer successfully preserves the training trajectory from a failure-free reference despite of 256 GPUs lost spread across the run. For comparison with checkpoint-and-restart baselines, ReCoVer demonstrates $2.23\times$ higher effective throughput after successive failures. This advantage results in ReCoVer processing 74.9% more tokens at 234 GPU-hours, with the gap widening as the training prolongs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ReCoVer, a resilient LLM pre-training system for large GPU clusters that upholds the invariant of constant microbatches per iteration to keep per-iteration gradients stochastically equivalent to a failure-free run. It comprises three decoupled layers—fault-tolerant collectives, in-step fine-grained recovery, and a versatile-workload policy for dynamic microbatch redistribution—and is designed as a parallelism-agnostic drop-in substrate for 3D parallelism and HSDP. End-to-end evaluation on up to 512 GPUs claims successful preservation of the training trajectory despite losing 256 GPUs across the run, with 2.23× higher effective throughput than checkpoint-and-restart baselines, enabling 74.9% more tokens processed at 234 GPU-hours.
Significance. If the trajectory-preservation claim holds, the work addresses a practical bottleneck in large-scale training where hardware faults are routine, potentially improving utilization without sacrificing convergence properties. The end-to-end scale (512 GPUs), integration with existing parallelism schemes, and direct throughput comparison to a standard baseline are concrete strengths. The absence of fitted parameters or self-referential normalizations avoids circularity risks.
major comments (2)
- [Abstract] Abstract: the central claim that ReCoVer 'successfully preserves the training trajectory from a failure-free reference despite of 256 GPUs lost' is load-bearing for all reported advantages, yet the manuscript provides no details on the measurement of trajectory equivalence (e.g., loss curves, gradient statistics, or token-level sampling), error bars, baseline implementation specifics, or verification that the versatile-workload policy and fault-tolerant collectives introduce no systematic bias into data order or randomness.
- [Abstract] Abstract (versatile-workload policy description): the assumption that keeping microbatch count constant per iteration ensures stochastic gradient equivalence rests on the policy correctly redistributing quotas without altering sampling statistics or computation order; however, no mechanism details are supplied on post-failure data assignment or randomness preservation, leaving the equivalence unverified in the reported experiments.
minor comments (2)
- [Abstract] Abstract: 'despite of 256 GPUs lost' is grammatically incorrect and should read 'despite 256 GPUs being lost'.
- [Abstract] Abstract: the phrase 'with the gap widening as the training prolongs' is vague; a specific scaling trend or additional data point would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the trajectory-preservation claim. We will revise the abstract to incorporate additional details on verification methods and policy mechanisms while preserving its conciseness. The full manuscript already contains supporting evaluation data, but we agree the abstract can be strengthened for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ReCoVer 'successfully preserves the training trajectory from a failure-free reference despite of 256 GPUs lost' is load-bearing for all reported advantages, yet the manuscript provides no details on the measurement of trajectory equivalence (e.g., loss curves, gradient statistics, or token-level sampling), error bars, baseline implementation specifics, or verification that the versatile-workload policy and fault-tolerant collectives introduce no systematic bias into data order or randomness.
Authors: We acknowledge the abstract's brevity omits explicit verification details. The evaluation section of the manuscript reports loss-curve overlays, gradient-norm statistics, and per-iteration token counts across failure-free and failure-injected runs (with standard error bars from repeated trials) to substantiate equivalence. The checkpoint-restart baseline follows the standard Megatron-DeepSpeed implementation with identical data loaders and random seeds. To address the concern directly in the abstract, we will add a concise clause noting these verification approaches and confirming no systematic bias in data order, as the collectives and policy preserve iteration-level sampling statistics. revision: yes
-
Referee: [Abstract] Abstract (versatile-workload policy description): the assumption that keeping microbatch count constant per iteration ensures stochastic gradient equivalence rests on the policy correctly redistributing quotas without altering sampling statistics or computation order; however, no mechanism details are supplied on post-failure data assignment or randomness preservation, leaving the equivalence unverified in the reported experiments.
Authors: The versatile-workload policy (detailed in Section 4) redistributes microbatch quotas proportionally to surviving GPU memory and compute capacity while enforcing a fixed global iteration seed and deterministic sharding of the data stream; this ensures the exact sequence of samples processed per iteration remains identical to the failure-free case. Post-failure reassignment occurs before the iteration begins, with no reordering of the data loader. We will revise the abstract to include a brief parenthetical on this mechanism (e.g., 'via deterministic quota redistribution under a shared random seed') to make the equivalence argument self-contained. revision: yes
Circularity Check
No circularity: empirical system evaluation with no derivations or self-referential fits
full rationale
The paper describes a fault-tolerant training system and reports empirical throughput and token-processing gains versus checkpoint-restart baselines. No equations, parameter fits, or derivations appear in the provided text. The stated invariant (constant microbatch count per iteration) is presented as a design choice whose correctness is evaluated experimentally rather than derived from prior results by the same authors. Claims rest on direct comparison to external baselines and do not reduce to self-definition or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hardware faults are routine rather than rare in massive GPU clusters used for LLM pre-training
- domain assumption Maintaining constant microbatch count per iteration preserves stochastic equivalence of gradients
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
A. Bouteiller, G. Bosilca, and J. J. Dongarra. Plan b: Interruption of ongoing mpi operations to support failure recovery. InProceedings of the 22nd European MPI Users’ Group Meeting, pages 1–9, 2015
work page 2015
-
[4]
S. Dash, I. R. Lyngaas, J. Yin, X. Wang, R. Egele, J. A. Ellis, M. Maiterth, G. Cong, F. Wang, and P. Balaprakash. Optimizing distributed training on frontier for large language models. In ISC High Performance 2024 Research Paper Proceedings (39th International Conference), pages 1–11. Prometeus GmbH, 2024
work page 2024
-
[5]
A. Eisenman, K. K. Matam, S. Ingram, D. Mudigere, R. Krishnamoorthi, K. Nair, M. Smelyan- skiy, and M. Annavaram. {Check-N-Run}: A checkpointing system for training deep learning recommendation models. In19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), pages 929–943, 2022
work page 2022
- [6]
-
[7]
M. Gooding. xai targets one million gpus for colossus supercomputer in memphis, 2024
work page 2024
-
[8]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
S. Hasan. Scaling llama4 training to 100k, 2026
work page 2026
-
[10]
Q. Hu, Z. Ye, Z. Wang, G. Wang, M. Zhang, Q. Chen, P. Sun, D. Lin, X. Wang, Y . Luo, et al. Characterization of large language model development in the datacenter. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 709–729, 2024
work page 2024
- [11]
-
[12]
I. Jang, Z. Yang, Z. Zhang, X. Jin, and M. Chowdhury. Oobleck: Resilient distributed training of large models using pipeline templates. InProceedings of the 29th Symposium on Operating Systems Principles, pages 382–395, 2023
work page 2023
-
[13]
M. Jeon, S. Venkataraman, A. Phanishayee, J. Qian, W. Xiao, and F. Yang. Analysis of{Large- Scale}{Multi-Tenant}{GPU} clusters for {DNN} training workloads. In2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 947–960, 2019. 10
work page 2019
-
[14]
Z. Jiang, H. Lin, Y . Zhong, Q. Huang, Y . Chen, Z. Zhang, Y . Peng, X. Li, C. Xie, S. Nong, et al. {MegaScale}: Scaling large language model training to more than 10,000 {GPUs}. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 745–760, 2024
work page 2024
-
[15]
A. Kokolis, M. Kuchnik, J. Hoffman, A. Kumar, P. Malani, F. Ma, Z. DeVito, S. Sengupta, K. Saladi, and C.-J. Wu. Revisiting reliability in large-scale machine learning research clusters. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1259–1274. IEEE, 2025
work page 2025
- [16]
-
[17]
J. Lee, Z. Chen, X. He, R. Underwood, B. Nicolae, F. Cappello, X. Lu, S. Di, and Z. Zhang. Spare: Stacked parallelism with adaptive reordering for fault-tolerant llm pretraining systems with 100k+ gpus.arXiv preprint arXiv:2603.00357, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
J. Li, G. Bosilca, A. Bouteiller, and B. Nicolae. Elastic deep learning through resilient collective operations. InProceedings of the SC’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, pages 44–50, 2023
work page 2023
- [19]
- [20]
- [21]
- [22]
-
[23]
D. Narayanan, A. Harlap, A. Phanishayee, V . Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia. Pipedream: Generalized pipeline parallelism for dnn training. In Proceedings of the 27th ACM symposium on operating systems principles, pages 1–15, 2019
work page 2019
-
[24]
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, et al. Efficient large-scale language model training on gpu clusters using megatron-lm. InProceedings of the international conference for high performance computing, networking, storage and analysis, pages 1–15, 2021
work page 2021
-
[25]
B. Nicolae, A. Moody, E. Gonsiorowski, K. Mohror, and F. Cappello. Veloc: Towards high performance adaptive asynchronous checkpointing at large scale. In2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 911–920. IEEE, 2019
work page 2019
- [26]
- [27]
-
[28]
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020. 11
work page 2020
-
[29]
O. Salpekar, R. Varma, K. Yu, V . Ivanov, Y . Wang, A. Sharif, M. Si, S. Xu, F. Tian, S. Zheng, et al. Training llms with fault tolerant hsdp on 100,000 gpus.arXiv preprint arXiv:2602.00277, 2026
-
[30]
Horovod: fast and easy distributed deep learning in TensorFlow
A. Sergeev and M. Del Balso. Horovod: fast and easy distributed deep learning in tensorflow. arXiv preprint arXiv:1802.05799, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[32]
N. Tazi, F. Mom, H. Zhao, P. Nguyen, M. Mekkouri, L. Werra, and T. Wolf. The ultra-scale playbook: Training llms on gpu clusters. 2025.URl: https://huggingface. co/spaces/nanotron/ultrascaleplaybook, 2025
work page 2025
-
[33]
J. Thorpe, P. Zhao, J. Eyolfson, Y . Qiao, Z. Jia, M. Zhang, R. Netravali, and G. H. Xu. Bamboo: Making preemptible instances resilient for affordable training of large{DNNs}. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 497–513, 2023
work page 2023
-
[34]
B. Wan, M. Han, Y . Sheng, Y . Peng, H. Lin, M. Zhang, Z. Lai, M. Yu, J. Zhang, Z. Song, et al. {ByteCheckpoint}: A unified checkpointing system for large foundation model development. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25), pages 559–578, 2025
work page 2025
-
[35]
B. Wan, G. Liu, Z. Song, J. Wang, Y . Zhang, G. Sheng, S. Wang, H. Wei, C. Wang, W. Lou, et al. Robust llm training infrastructure at bytedance. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, pages 186–203, 2025
work page 2025
- [36]
-
[37]
Z. Wang, Z. Jia, S. Zheng, Z. Zhang, X. Fu, T. E. Ng, and Y . Wang. Gemini: Fast failure recovery in distributed training with in-memory checkpoints. InProceedings of the 29th Symposium on Operating Systems Principles, pages 364–381, 2023
work page 2023
-
[38]
Z. Wang, Z. Liu, R. Zhang, A. Maurya, P. Hovland, B. Nicolae, F. Cappello, and Z. Zhang. Boost: Bottleneck-optimized scalable training framework for low-rank large language models. arXiv preprint arXiv:2512.12131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
- [40]
-
[41]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Y . Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023. A Additional Evaluations and Details This appendix provides additional evaluation details and the results for RECOVER-HSDP that cannot be inclu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.