Self-Supervised Laplace Approximation for Bayesian Uncertainty Quantification
Pith reviewed 2026-05-13 04:44 UTC · model grok-4.3
The pith
Refitting models on their own predictions approximates the posterior predictive distribution directly and improves calibration over classical Laplace methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
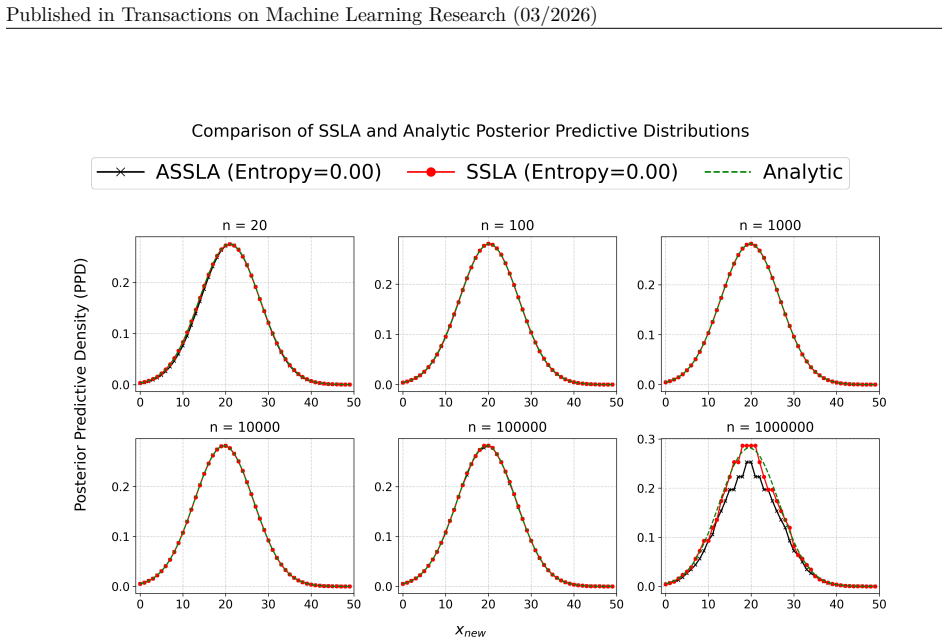
We propose to bypass the parameter posterior and focus directly on approximating the posterior predictive distribution by drawing inspiration from self-training. Essentially, we quantify a Bayesian model's predictive uncertainty by refitting on self-predicted data. If a model assigns high likelihood to self-predicted data, these predictions are of low uncertainty, and vice versa. This yields a deterministic, sampling-free approximation of the posterior predictive called Self-Supervised Laplace Approximation (SSLA). An approximate version (ASSLA) avoids expensive refitting. The method supports classical Bayesian sensitivity analysis via different priors and is studied in regression settings.
What carries the argument
Self-Supervised Laplace Approximation (SSLA), a procedure that refits the model on its own predictions treated as pseudo-data to quantify uncertainty in the posterior predictive distribution.
If this is right
- SSLA enables direct sensitivity analysis to prior choice without additional sampling.
- The method applies to both Bayesian linear models and Bayesian neural networks for regression.
- ASSLA provides a computationally cheaper alternative that still improves calibration over standard Laplace approximations.
- The approach remains deterministic and sampling-free across the studied tasks.
Where Pith is reading between the lines
- The self-supervised refitting idea could be tested for extending calibration gains to classification problems.
- If the initial model predictions are poor, the method may amplify errors rather than quantify uncertainty faithfully.
- Combining SSLA with other approximate inference techniques might further reduce computational cost in large-scale settings.
Load-bearing premise
That the model's initial predictions are reliable enough to serve as pseudo-labels whose likelihood under refitting accurately reflects true predictive uncertainty.
What would settle it
A dataset where SSLA or ASSLA predictive intervals show substantially worse calibration metrics (such as coverage or expected calibration error) than classical Laplace approximations on the same models.
Figures


read the original abstract
Approximate Bayesian inference typically revolves around computing the posterior parameter distribution. In practice, however, the main object of interest is often a model's predictions rather than its parameters. In this work, we propose to bypass the parameter posterior and focus directly on approximating the posterior predictive distribution. We achieve this by drawing inspiration from self-training within self-supervised and semi-supervised learning. Essentially, we quantify a Bayesian model's predictive uncertainty by refitting on self-predicted data. The idea is strikingly simple: If a model assigns high likelihood to self-predicted data, these predictions are of low uncertainty, and vice versa. This yields a deterministic, sampling-free approximation of the posterior predictive. The modular structure of our Self-Supervised Laplace Approximation (SSLA) further allows us to plug in different prior specifications, enabling classical Bayesian sensitivity (w.r.t. prior choice) analysis. In order to bypass expensive refitting, we further introduce an approximate version of SSLA, called ASSLA. We study (A)SSLA both theoretically and empirically in regression models ranging from Bayesian linear models to Bayesian neural networks. Across a wide array of regression tasks with simulated and real-world datasets, our methods outperform classical Laplace approximations in predictive calibration while remaining computationally efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Self-Supervised Laplace Approximation (SSLA) to directly approximate the posterior predictive distribution p(y*|x*,D) in Bayesian regression models by refitting on self-generated pseudo-labels from the initial model predictions, inspired by self-training. An approximate variant ASSLA is introduced to avoid full refitting. The approach is analyzed theoretically and evaluated empirically on regression tasks ranging from Bayesian linear models to neural networks, with claims of improved predictive calibration over classical Laplace approximations while remaining computationally efficient and modular for prior sensitivity analysis.
Significance. If the central approximation holds with controlled bias, SSLA provides a simple, deterministic, sampling-free method for predictive uncertainty quantification that shifts focus from parameter posteriors to predictions. This could be useful for scalable Bayesian deep learning applications, and the modular prior plug-in enables straightforward sensitivity checks not always available in other approximations.
major comments (2)
- [§3] §3 (Method): The core construction refits the model (or its Laplace approximation) using the initial MAP predictions as targets to obtain a curvature or likelihood-based uncertainty measure. This step is load-bearing for the claim of approximating the posterior predictive, yet the paper provides no quantitative bound on the approximation error when the initial predictions deviate from the true conditional (e.g., under misspecification or high noise). A concrete error analysis or counterexample regime is required.
- [§5] §5 (Experiments): The abstract states outperformance in predictive calibration across simulated and real-world regression datasets, but the experimental design details (baselines, number of runs, error bars, statistical tests, and handling of self-prediction bias) are not summarized here; without these, the empirical support for the central claim cannot be fully assessed.
minor comments (2)
- [§3] Notation for the self-supervised loss and the resulting approximate predictive variance should be introduced with explicit equations early in §3 to improve readability.
- [Abstract] Clarify in the abstract and introduction whether ASSLA is a first-order approximation to SSLA or an independent method; the current wording leaves this ambiguous.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method): The core construction refits the model (or its Laplace approximation) using the initial MAP predictions as targets to obtain a curvature or likelihood-based uncertainty measure. This step is load-bearing for the claim of approximating the posterior predictive, yet the paper provides no quantitative bound on the approximation error when the initial predictions deviate from the true conditional (e.g., under misspecification or high noise). A concrete error analysis or counterexample regime is required.
Authors: We acknowledge that the current manuscript does not provide a general quantitative bound on the approximation error for arbitrary misspecification or high noise. The theoretical analysis in §3 characterizes SSLA for the linear Gaussian case, where it recovers the exact posterior predictive distribution, and motivates the approach more generally via the self-supervised refitting construction. In the revised version we will add a new paragraph to §3 that derives a simple error bound in terms of the L2 deviation between the initial MAP predictions and the true conditional mean (under standard Lipschitz assumptions on the model), together with a concrete counterexample in a high-noise linear regression regime that illustrates when the bias becomes noticeable. This directly supplies the requested error analysis while preserving the modular and sampling-free nature of the method. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract states outperformance in predictive calibration across simulated and real-world regression datasets, but the experimental design details (baselines, number of runs, error bars, statistical tests, and handling of self-prediction bias) are not summarized here; without these, the empirical support for the central claim cannot be fully assessed.
Authors: The abstract is necessarily brief and therefore omits experimental protocol details, but §5 of the manuscript fully specifies the baselines (classical Laplace, variational inference, and ensembles), the number of independent runs with reported variability, the calibration metrics and statistical tests employed, and the handling of self-prediction bias via training-only pseudo-label generation and strict held-out evaluation. To make these elements immediately accessible, we will insert a short “Experimental Protocol” paragraph at the beginning of §5 and add a one-sentence summary of the evaluation setup to the abstract. We believe this change will allow the empirical claims to be assessed without altering the reported results. revision: yes
Circularity Check
No significant circularity in the proposed approximation
full rationale
The paper proposes SSLA as a heuristic approximation to the posterior predictive distribution by refitting a Laplace approximation on self-generated pseudo-labels drawn from the initial model's point predictions. This construction is explicitly presented as an approximation technique inspired by self-training, not as a first-principles derivation whose output is definitionally identical to its input. The central claim (improved predictive calibration over classical Laplace) is evaluated empirically across simulated and real regression datasets and is therefore falsifiable against external benchmarks. No equations or steps in the provided abstract reduce the uncertainty measure to a tautological fit on the same quantities by construction, nor does the argument rest on load-bearing self-citations or imported uniqueness theorems. The acknowledged modeling assumption (initial predictions are sufficiently reliable pseudo-labels) is stated as such rather than smuggled in as a proven result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Laplace approximation provides a valid local Gaussian fit to the posterior
- ad hoc to paper Self-predicted data likelihood reliably indicates predictive uncertainty
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
logp(ˆyn+1|xn+1,D)≈˜ℓ(˜θ)−ℓ(ˆθ)+logπ(˜θ)−logπ(ˆθ)−½log|˜J(˜θ)|+½log|J(ˆθ)| (eq. 12); ASSLA drops prior term via O(n⁻¹) expansion
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
refitting on self-predicted data to quantify predictive uncertainty
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.