AttenA+: Rectifying Action Inequality in Robotic Foundation Models
Pith reviewed 2026-05-14 18:39 UTC · model grok-4.3
The pith
Reweighting robotic action losses by inverse velocity improves foundation model performance on manipulation tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Robotic foundation models are limited by an implicit assumption of temporal homogeneity that assigns uniform importance to all actions during optimization. AttenA+ introduces velocity-driven action attention that reweights the loss function by the inverse velocity field, thereby aligning model capacity with the physical hierarchy of manipulation where slow segments demand greater precision. This architecture-agnostic enhancement integrates directly into existing backbones and produces measurable gains on long-horizon benchmarks while preserving the original model structure.
What carries the argument
velocity-driven action attention, a reweighting of the training loss by the inverse of the action velocity field that prioritizes low-speed, precision-critical segments
If this is right
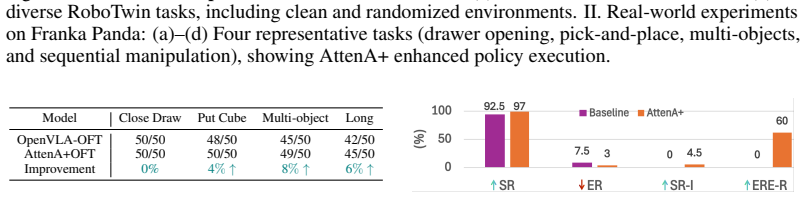
- OpenVLA-OFT reaches 98.6 percent success on the Libero benchmark, a 1.5 percent gain over the prior baseline
- FastWAM reaches 92.4 percent on RoboTwin 2.0, a 0.6 percent gain
- The method attaches to any existing backbone without structural modifications or added parameters
- Real-world deployment on a Franka manipulator demonstrates robustness and cross-task generalization
Where Pith is reading between the lines
- The same inverse-rate reweighting could be tested on other sequential control domains where speed varies, such as autonomous navigation or animation synthesis
- Alternative proxies for criticality, such as contact force or acceleration, could be substituted for velocity to check whether the gains persist
- The result implies that future scaling efforts in robotics may benefit more from embedding physical sequence structure than from data volume alone
Load-bearing premise
That velocity is the right proxy for kinematic criticality and that inverse-velocity reweighting will automatically focus learning on the segments that most affect task success.
What would settle it
Training with the AttenA+ reweighting on a manipulation task where success depends mainly on high-velocity actions would produce equal or lower performance than uniform weighting.
Figures












read the original abstract
Existing robotic foundation models, while powerful, are predicated on an implicit assumption of temporal homogeneity: treating all actions as equally informative during optimization. This "flat" training paradigm, inherited from language modeling, remains indifferent to the underlying physical hierarchy of manipulation. In reality, robot trajectories are fundamentally heterogeneous, where low-velocity segments often dictate task success through precision-demanding interactions, while high-velocity motions serve as error-tolerant transitions. Such a misalignment between uniform loss weighting and physical criticality fundamentally limits the performance of current Vision-Language-Action (VLA) models and World-Action Models (WAM) in complex, long-horizon tasks. To rectify this, we introduce AttenA+, an architecture-agnostic framework that prioritizes kinematically critical segments via velocity-driven action attention. By reweighting the training objective based on the inverse velocity field, AttenA+ naturally aligns the model's learning capacity with the physical demands of manipulation. As a plug-and-play enhancement, AttenA+ can be integrated into existing backbones without structural modifications or additional parameters. Extensive experiments demonstrate that AttenA+ significantly elevates the ceilings of current state-of-the-art models. Specifically, it improves OpenVLA-OFT to 98.6% (+1.5%) on the Libero benchmark and pushes FastWAM to 92.4% (+0.6%) on RoboTwin 2.0. Real-world validation on a Franka manipulator further showcases its robustness and cross-task generalization. Our work suggests that mining the intrinsic structural priors of action sequences offers a highly efficient, physics-aware complement to standard scaling laws, paving a new path for general-purpose robotic control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AttenA+, an architecture-agnostic, parameter-free framework that reweights the training objective of Vision-Language-Action (VLA) and World-Action Models (WAM) using the inverse velocity field. This prioritizes low-velocity segments presumed to be kinematically critical for manipulation success, addressing the assumed temporal homogeneity of standard uniform-loss training. The manuscript reports concrete gains when applied to existing backbones: OpenVLA-OFT reaches 98.6% (+1.5%) on Libero and FastWAM reaches 92.4% (+0.6%) on RoboTwin 2.0, with additional real-world validation on a Franka manipulator.
Significance. If the velocity-specific mechanism can be isolated and the gains replicated with proper controls, the work supplies a lightweight, physics-motivated complement to scaling that exploits intrinsic structure in action sequences. The absence of added parameters and the plug-and-play nature make the approach attractive for existing robotic foundation models, provided the central causal claim holds.
major comments (2)
- [§4 (Experimental Evaluation)] The experimental results (abstract and §4) report specific percentage improvements (+1.5% on Libero, +0.6% on RoboTwin) but supply no information on baseline implementations, number of random seeds, statistical tests, data splits, or variance. This renders the quantitative claims unverifiable and prevents assessment of whether the reported ceilings are robust.
- [§3 (Method) and §4] The central claim that gains arise specifically because inverse-velocity reweighting aligns learning capacity with kinematic criticality is not isolated from generic non-uniform weighting. No ablation compares the proposed scheme against controls such as random weights with matched statistics or reweighting by action norm (or other proxies). Without these, the physics-aware interpretation and the 'rectifying action inequality' framing remain unsupported.
minor comments (2)
- [§3] Notation for the reweighting factor (inverse velocity field) is introduced without an explicit equation number or derivation showing how it is computed from raw trajectories; a short formal definition would improve clarity.
- [Abstract and §4] The abstract states 'extensive experiments' yet provides no table or figure summarizing all evaluated backbones, tasks, and metrics in one place; a consolidated results table would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of experimental rigor and causal isolation. We address each major point below and will revise the manuscript to strengthen the presentation of results and supporting evidence.
read point-by-point responses
-
Referee: [§4 (Experimental Evaluation)] The experimental results (abstract and §4) report specific percentage improvements (+1.5% on Libero, +0.6% on RoboTwin) but supply no information on baseline implementations, number of random seeds, statistical tests, data splits, or variance. This renders the quantitative claims unverifiable and prevents assessment of whether the reported ceilings are robust.
Authors: We agree that the current version lacks sufficient detail on the experimental protocol. In the revised manuscript we will add a dedicated subsection under §4 that specifies: (i) exact baseline implementations and training hyperparameters, (ii) number of random seeds (we will report results over at least three seeds), (iii) data splits used for Libero and RoboTwin, (iv) statistical tests performed, and (v) mean and standard deviation of success rates. This will allow readers to assess robustness directly. revision: yes
-
Referee: [§3 (Method) and §4] The central claim that gains arise specifically because inverse-velocity reweighting aligns learning capacity with kinematic criticality is not isolated from generic non-uniform weighting. No ablation compares the proposed scheme against controls such as random weights with matched statistics or reweighting by action norm (or other proxies). Without these, the physics-aware interpretation and the 'rectifying action inequality' framing remain unsupported.
Authors: We acknowledge that the present experiments do not yet isolate the velocity-specific mechanism from generic non-uniform weighting. To address this, the revised §4 will include two new ablations: (1) random reweighting drawn from the same distribution as the inverse-velocity weights, and (2) reweighting proportional to action-norm magnitude. These controls will be run on the same backbones and benchmarks, allowing direct comparison of success rates and thereby testing whether the kinematic motivation is necessary for the observed gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines AttenA+ explicitly as reweighting the training objective by the inverse velocity field drawn from physical trajectory measurements, independent of the final benchmark numbers. The reported gains on Libero (98.6%) and RoboTwin (92.4%) are presented as empirical outcomes of applying this externally motivated rule rather than as predictions that reduce to a fit or self-definition. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core mechanism, and the architecture-agnostic plug-and-play framing does not rely on any load-bearing reduction to prior author work or fitted parameters. The derivation therefore remains self-contained against external physical priors.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Robot trajectories are fundamentally heterogeneous, with low-velocity segments dictating task success through precision-demanding interactions.
invented entities (1)
-
AttenA+ framework
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.