A Mutual Information Lower Bound for Multimodal Regression Active Learning
Pith reviewed 2026-06-30 21:07 UTC · model grok-4.3
The pith
Mutual information between the output and the epistemic index supplies a vanishing acquisition objective for multimodal regression active learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the mutual information between the regression output and the stochastic index selecting among model hypotheses is a principled acquisition function. This quantity is proven to vanish with growing datasets, confirming that it captures precisely the uncertainty additional data can resolve. A tractable lower bound MI-LB is derived for mixture density network ensembles that inherits the vanishing property and serves as a reliable proxy for epistemic uncertainty even when the input space does not encode the multimodality.
What carries the argument
The Two-Index framework, consisting of one stochastic index for model hypotheses (epistemic) and a second for within-hypothesis randomness (aleatoric), together with the entropy decomposition that isolates their mutual information with the output.
If this is right
- MI-LB is the only evaluated acquisition function that matches or beats every baseline consistently across multimodal benchmarks.
- Geometric and Fisher-based baselines succeed only when the input space already encodes the multimodality and collapse otherwise.
- The mutual information objective captures exactly the uncertainty that data can resolve because the quantity vanishes with additional training data.
- The closed-form lower bound for MDN ensembles remains a reliable proxy for epistemic uncertainty without requiring the input to encode multimodality.
Where Pith is reading between the lines
- The Two-Index separation could be applied to other ensemble or Bayesian models beyond mixture density networks to derive similar acquisition functions.
- Analogous entropy decompositions might extend the approach to active learning for structured outputs or time-series regression.
- Empirical tests on high-dimensional inputs or physical systems with latent multimodality would clarify whether the lower-bound approximation remains tight in practice.
Load-bearing premise
The closed-form lower bound derived for Mixture Density Network ensembles preserves the key vanishing property of the true mutual information and remains a reliable proxy for epistemic uncertainty even when the input space does not already encode the multimodality.
What would settle it
An experiment on a multimodal regression benchmark in which the MI-LB acquisition scores fail to approach zero as the training set size increases, or in which MI-LB is outperformed by variance-based acquisition when the input space does not encode modes.
Figures

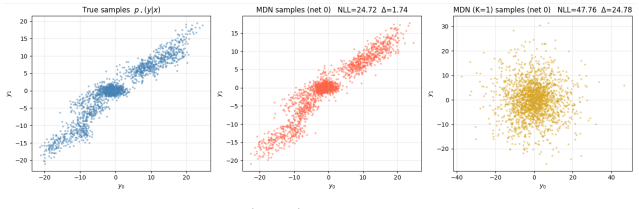
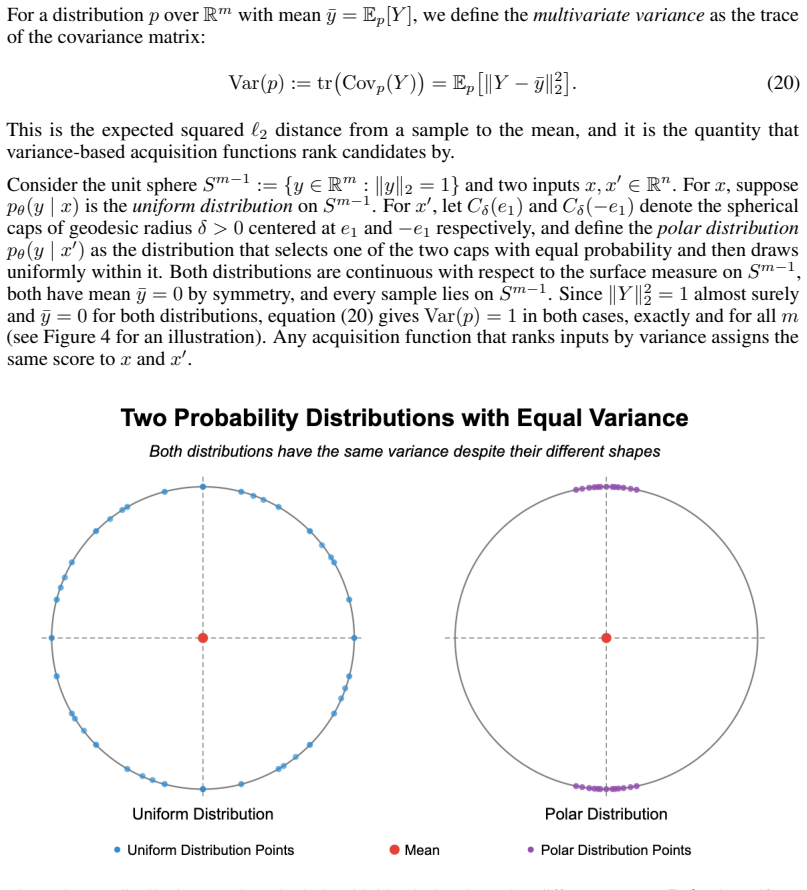

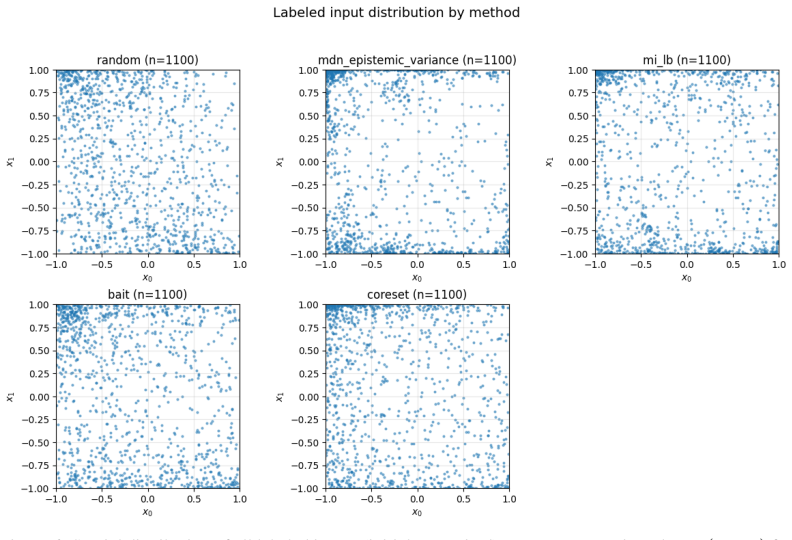
read the original abstract
Active learning for continuous regression has lacked an acquisition function that targets epistemic uncertainty when the predictive distribution is multimodal: variance misses modal disagreement, and information-theoretic targets like BALD are designed for discrete outputs. We introduce a Two-Index framework that makes this separation explicit: one stochastic index selects among competing model hypotheses (epistemic source), while a second governs within-hypothesis randomness (aleatoric source). An entropy decomposition within the framework identifies the mutual information between the output and the epistemic index as a principled acquisition objective, and we prove this quantity vanishes as the model is trained on growing datasets, confirming that it captures exactly the uncertainty data can resolve. Because this mutual information is intractable for continuous outputs, we derive the Mutual Information Lower Bound (MI-LB) acquisition function, a closed-form approximation for Mixture Density Network ensembles. On benchmarks featuring multimodal systems, MI-LB matches or beats every baseline evaluated and is the only method to do so consistently -- geometric and Fisher-based baselines compete only when the input space already encodes the multimodality, and collapse otherwise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Two-Index framework that decomposes entropy into epistemic and aleatoric sources for multimodal regression active learning. It identifies the mutual information between the output Y and the epistemic index as a principled acquisition objective, proves that this MI vanishes as the dataset grows (confirming it isolates resolvable uncertainty), and derives a closed-form Mutual Information Lower Bound (MI-LB) acquisition function for Mixture Density Network ensembles. Experiments on multimodal benchmarks show MI-LB matches or beats all baselines and is the only method that does so consistently.
Significance. If the vanishing property and the fidelity of the lower bound hold, the work supplies a theoretically motivated acquisition function for epistemic uncertainty in continuous multimodal regression, where variance-based and discrete-output methods like BALD are inadequate. The explicit proof of vanishing MI and the consistent empirical superiority are notable strengths; the result could influence acquisition design in settings with inherent multimodality.
major comments (2)
- [Derivation of MI-LB (following the Two-Index entropy decomposition)] The manuscript proves that the true mutual information I(Y; epistemic index) vanishes with growing data, but the deployed acquisition function is the closed-form MI-LB derived for MDN ensembles. No argument is given that this specific lower-bound expression also tends to zero under ensemble convergence or dataset growth, nor that the approximation gap remains controlled when the input does not already encode multimodality. This is load-bearing for the claim that MI-LB is a principled proxy for epistemic uncertainty.
- [Proof of vanishing MI and subsequent MI-LB section] The abstract and framework claim the lower bound preserves the key vanishing property, yet the provided text supplies no limiting argument or numerical verification that MI-LB o 0 as N o o. If the bound fails to vanish or becomes loose, the acquisition function loses its claimed grounding.
minor comments (2)
- [Two-Index framework definition] Notation for the two indices (epistemic and aleatoric) should be introduced with explicit random-variable symbols in the framework section to avoid ambiguity when the indices are later marginalized.
- [Experiments and benchmarks] The experimental section should clarify how post-hoc benchmark selection was performed and whether any multimodal systems were excluded; this affects the strength of the 'only method to do so consistently' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that identify opportunities to strengthen the theoretical claims around MI-LB. We respond to each major comment below.
read point-by-point responses
-
Referee: The manuscript proves that the true mutual information I(Y; epistemic index) vanishes with growing data, but the deployed acquisition function is the closed-form MI-LB derived for MDN ensembles. No argument is given that this specific lower-bound expression also tends to zero under ensemble convergence or dataset growth, nor that the approximation gap remains controlled when the input does not already encode multimodality. This is load-bearing for the claim that MI-LB is a principled proxy for epistemic uncertainty.
Authors: We agree that an explicit argument linking the vanishing property to the specific MI-LB expression is needed. In revision we will add a subsection showing that, under the MDN ensemble convergence to the true posterior, the Jensen gap in the lower bound vanishes simultaneously with the epistemic entropy terms, so MI-LB tends to zero. We will also clarify that the bound is derived for output multimodality captured by the mixture components and remains a valid epistemic proxy even when the input alone does not encode it. revision: yes
-
Referee: The abstract and framework claim the lower bound preserves the key vanishing property, yet the provided text supplies no limiting argument or numerical verification that MI-LB → 0 as N → ∞. If the bound fails to vanish or becomes loose, the acquisition function loses its claimed grounding.
Authors: The abstract and proof target the true mutual information; the lower-bound preservation was implicit. We will insert both a formal limiting argument (MI-LB → 0 follows from tightness of the bound as epistemic variance collapses) and a numerical verification experiment plotting MI-LB versus training set size on a controlled multimodal regression task. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The abstract and provided text describe a Two-Index entropy decomposition that isolates mutual information I(Y; epistemic index) as the acquisition objective, with an explicit proof that this quantity vanishes under dataset growth. A closed-form lower bound MI-LB is then derived for MDN ensembles as an approximation. No quoted step reduces the objective to a fitted parameter, self-citation chain, or input by construction; the vanishing property is stated as proven for the true MI rather than assumed for the bound. The central claim therefore retains independent content and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard entropy decomposition and mutual information properties hold for the two-index joint distribution
invented entities (1)
-
Two-Index framework (epistemic index and aleatoric index)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bayesian active learning for classification and preference learning, 2011
Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel. Bayesian active learning for classification and preference learning, 2011
2011
-
[2]
What uncertainties do we need in bayesian deep learning for computer vision?Advances in neural information processing systems, 30, 2017
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision?Advances in neural information processing systems, 30, 2017. 10
2017
-
[3]
Epistemic neural networks.CoRR, abs/2107.08924, 2021
Ian Osband, Zheng Wen, Mohammad Asghari, Morteza Ibrahimi, Xiyuan Lu, and Benjamin Van Roy. Epistemic neural networks.CoRR, abs/2107.08924, 2021
-
[4]
Huber, Tim Bailey, Hugh Durrant-Whyte, and Uwe D
Marco F. Huber, Tim Bailey, Hugh Durrant-Whyte, and Uwe D. Hanebeck. On entropy approximation for gaussian mixture random vectors. In2008 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, pages 181–188, 2008
2008
-
[5]
A deeper look into aleatoric and epistemic uncertainty disentanglement
Matias Valdenegro-Toro and Daniel Saromo Mori. A deeper look into aleatoric and epistemic uncertainty disentanglement. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1508–1516. IEEE, 2022
2022
-
[6]
What are bayesian neural network posteriors really like? InInternational conference on machine learning, pages 4629–4640
Pavel Izmailov, Sharad Vikram, Matthew D Hoffman, and Andrew Gordon Gordon Wilson. What are bayesian neural network posteriors really like? InInternational conference on machine learning, pages 4629–4640. PMLR, 2021
2021
-
[7]
Deep ensembles as approximate bayesian inference
Andrew Gordon Wilson and Pavel Izmailov. Deep ensembles as approximate bayesian inference. https://cims.nyu.edu/~andrewgw/deepensembles/, 2021
2021
-
[8]
Benchmarking uncertainty disen- tanglement: Specialized uncertainties for specialized tasks.Advances in neural information processing systems, 37:50972–51038, 2024
Bálint Mucsányi, Michael Kirchhof, and Seong Joon Oh. Benchmarking uncertainty disen- tanglement: Specialized uncertainties for specialized tasks.Advances in neural information processing systems, 37:50972–51038, 2024
2024
-
[9]
Mixture density networks.Neural Computing Research Group Report, 1994
Christopher M Bishop. Mixture density networks.Neural Computing Research Group Report, 1994
1994
-
[10]
Multimodal scientific learning beyond diffusions and flows, 2026
Leonardo Ferreira Guilhoto, Akshat Kaushal, and Paris Perdikaris. Multimodal scientific learning beyond diffusions and flows, 2026
2026
-
[11]
A framework and benchmark for deep batch active learning for regression.Journal of Machine Learning Research, 24(164):1–81, 2023
David Holzmüller, Viktor Zaverkin, Johannes Kästner, and Ingo Steinwart. A framework and benchmark for deep batch active learning for regression.Journal of Machine Learning Research, 24(164):1–81, 2023
2023
-
[12]
Active learning for convolutional neural networks: A core-set approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[13]
Ash, Surbhi Goel, Akshay Krishnamurthy, and Sham Kakade
Jordan T. Ash, Surbhi Goel, Akshay Krishnamurthy, and Sham Kakade. Gone fishing: Neural active learning with fisher embeddings. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[14]
Andreas Kirsch, Sebastian Farquhar, and Yarin Gal. A simple baseline for batch active learning with stochastic acquisition functions.CoRR, abs/2106.12059, 2021
-
[15]
Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning.Advances in neural information processing systems, 32, 2019
Andreas Kirsch, Joost Van Amersfoort, and Yarin Gal. Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning.Advances in neural information processing systems, 32, 2019
2019
-
[16]
Bayesian model averaging: a tutorial (with comments by m
Jennifer A Hoeting, David Madigan, Adrian E Raftery, and Chris T V olinsky. Bayesian model averaging: a tutorial (with comments by m. clyde, david draper and ei george, and a rejoinder by the authors.Statistical science, 14(4):382–417, 1999
1999
-
[17]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[18]
Algorithms for manifold learning.Univ
Lawrence Cayton et al. Algorithms for manifold learning.Univ. of California at San Diego Tech. Rep, 12(1-17):1, 2005
2005
-
[19]
H. A. Kramers. Brownian motion in a field of force and the diffusion model of chemical reactions.Physica, 7(4):284–304, 1940
1940
-
[20]
Balachandran, Dezhen Xue, and Ruihao Yuan
Turab Lookman, Prasanna V . Balachandran, Dezhen Xue, and Ruihao Yuan. Active learning in materials science with emphasis on adaptive sampling using uncertainties for targeted design. npj Computational Materials, 5(1):21, 2019. 11
2019
-
[21]
Balachandran, John Hogden, James Theiler, Deqing Xue, and Turab Lookman
Dezhen Xue, Prasanna V . Balachandran, John Hogden, James Theiler, Deqing Xue, and Turab Lookman. Accelerated search for materials with targeted properties by adaptive design.Nature Communications, 7(1):11241, 2016
2016
-
[22]
Gilad Kusne, Jason Hattrick-Simpers, Keith A
Eric Stach, Brian DeCost, A. Gilad Kusne, Jason Hattrick-Simpers, Keith A. Brown, Kristofer G. Reyes, Joshua Schrier, Simon Billinge, Tonio Buonassisi, Ian Foster, Carla P. Gomes, John M. Gregoire, Apurva Mehta, Joseph Montoya, Elsa Olivetti, Chiwoo Park, Eli Rotenberg, Semion K. Saikin, Sylvia Smullin, Valentin Stanev, and Benji Maruyama. Autonomous expe...
2021
-
[23]
Fries, and Bo Sundman.Computational Thermodynamics: The CALPHAD Method
Hans Lukas, Suzana G. Fries, and Bo Sundman.Computational Thermodynamics: The CALPHAD Method. Cambridge University Press, USA, 1st edition, 2007
2007
-
[24]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018
2018
-
[25]
Flax: A neural network library and ecosystem for JAX, 2023
Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Zee. Flax: A neural network library and ecosystem for JAX, 2023
2023
-
[26]
J. D. Hunter. Matplotlib: A 2d graphics environment.Computing in Science & Engineering, 9(3):90–95, 2007
2007
-
[27]
Harris, K
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fer- nández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin She...
2020
-
[28]
Learning structured output representation using deep conditional generative models.Advances in neural information processing systems, 28, 2015
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models.Advances in neural information processing systems, 28, 2015
2015
-
[29]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Composite bayesian optimization in function spaces using neon—neural epistemic operator networks.Scientific Reports, 14(1):29199, 2024
Leonardo Ferreira Guilhoto and Paris Perdikaris. Composite bayesian optimization in function spaces using neon—neural epistemic operator networks.Scientific Reports, 14(1):29199, 2024
2024
-
[31]
Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
George Cybenko. Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
1989
-
[32]
A universal approximation theorem of deep neural networks for expressing probability distributions.Advances in neural information processing systems, 33:3094–3105, 2020
Yulong Lu and Jianfeng Lu. A universal approximation theorem of deep neural networks for expressing probability distributions.Advances in neural information processing systems, 33:3094–3105, 2020
2020
-
[33]
The DeepMind JAX Ecosystem, 2020
DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena ...
2020
-
[34]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016. 12 A Mathematical Notation Table 2 summarizes the symbols and notation used in this work. For operands that involve expectations, such as expectationE, variance Var and entropy H, a sub- index indicates what is the random variable for which the expec...
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.