ZeroUnlearn: Few-Shot Knowledge Unlearning in Large Language Models
Pith reviewed 2026-06-30 19:27 UTC · model grok-4.3
The pith
ZeroUnlearn removes sensitive information from large language models by enforcing representational orthogonality with a closed-form multiplicative update.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ZeroUnlearn reformulates machine unlearning as a precise knowledge re-mapping problem via model editing. It overwrites sensitive inputs by mapping them to a neutral target state and removing their original representations. ZeroUnlearn enforces representational orthogonality through a multiplicative parameter update with a closed-form solution, enabling efficient and targeted unlearning. We further extend ZeroUnlearn to a gradient-based variant for multi-sample unlearning. Experiments demonstrate that our approach outperforms existing baselines while preserving general model utility.
What carries the argument
Multiplicative parameter update that enforces representational orthogonality with a closed-form solution, overwriting sensitive inputs to neutral states by removing original representations.
If this is right
- Enables few-shot unlearning without expensive retraining.
- Preserves overall model utility better than aggressive fine-tuning methods.
- Supports targeted removal of specific sensitive knowledge.
- The gradient-based variant handles multiple samples effectively.
- Experiments show superior performance over baselines.
Where Pith is reading between the lines
- If orthogonality isolates representations, the update rule could apply to factual corrections or other model edits beyond unlearning.
- Testing the closed-form solution across model scales would reveal whether efficiency holds for very large architectures.
- Choosing different neutral target states might improve results for specific unlearning goals not explored here.
- Combining this with existing alignment techniques could strengthen privacy protections in deployed models.
Load-bearing premise
That mapping sensitive inputs to a neutral state through orthogonality fully removes their original representations without affecting related knowledge or model performance.
What would settle it
If the model still generates the original sensitive outputs from the unlearned inputs or shows reduced accuracy on related non-sensitive tasks after the update, the central claim fails.
Figures







read the original abstract
Large language models inevitably retain sensitive information, defined as inputs that may induce harmful generations, due to training on massive web corpora, raising concerns for privacy and safety. Existing machine unlearning methods primarily rely on retraining or aggressive fine-tuning, which are either computationally expensive or prone to degrading related knowledge and overall model utility. In this work, we reformulate machine unlearning as a precise knowledge re-mapping problem via model editing. We propose ZeroUnlearn, a few-shot unlearning framework. It overwrites sensitive inputs by mapping them to a neutral target state and removing their original representations. ZeroUnlearn enforces representational orthogonality through a multiplicative parameter update with a closed-form solution, enabling efficient and targeted unlearning. We further extend ZeroUnlearn to a gradient-based variant for multi-sample unlearning. Experiments demonstrate that our approach outperforms existing baselines while preserving general model utility. Our code is available at the github: https://github.com/XMUDeepLIT/ZeroUnlearn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ZeroUnlearn, a few-shot knowledge unlearning framework for LLMs that reformulates unlearning as a model-editing task. It overwrites sensitive inputs by mapping them to a neutral target state and removes their original representations via a multiplicative parameter update with a closed-form solution that enforces representational orthogonality; a gradient-based extension handles multi-sample cases. Experiments are stated to show outperformance over baselines while preserving general model utility, with code released.
Significance. If the closed-form multiplicative update demonstrably isolates sensitive directions without collateral damage to shared representations, the approach would provide an efficient, low-shot alternative to retraining-based unlearning methods. This would be significant for privacy and safety applications in deployed LLMs. The explicit code release supports reproducibility.
major comments (3)
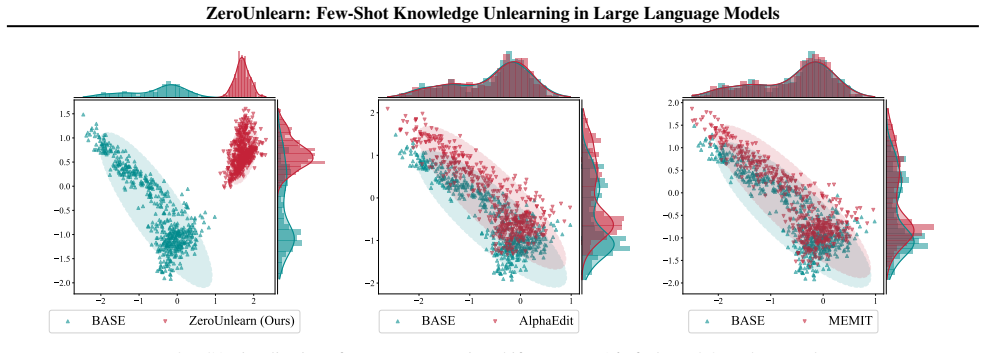
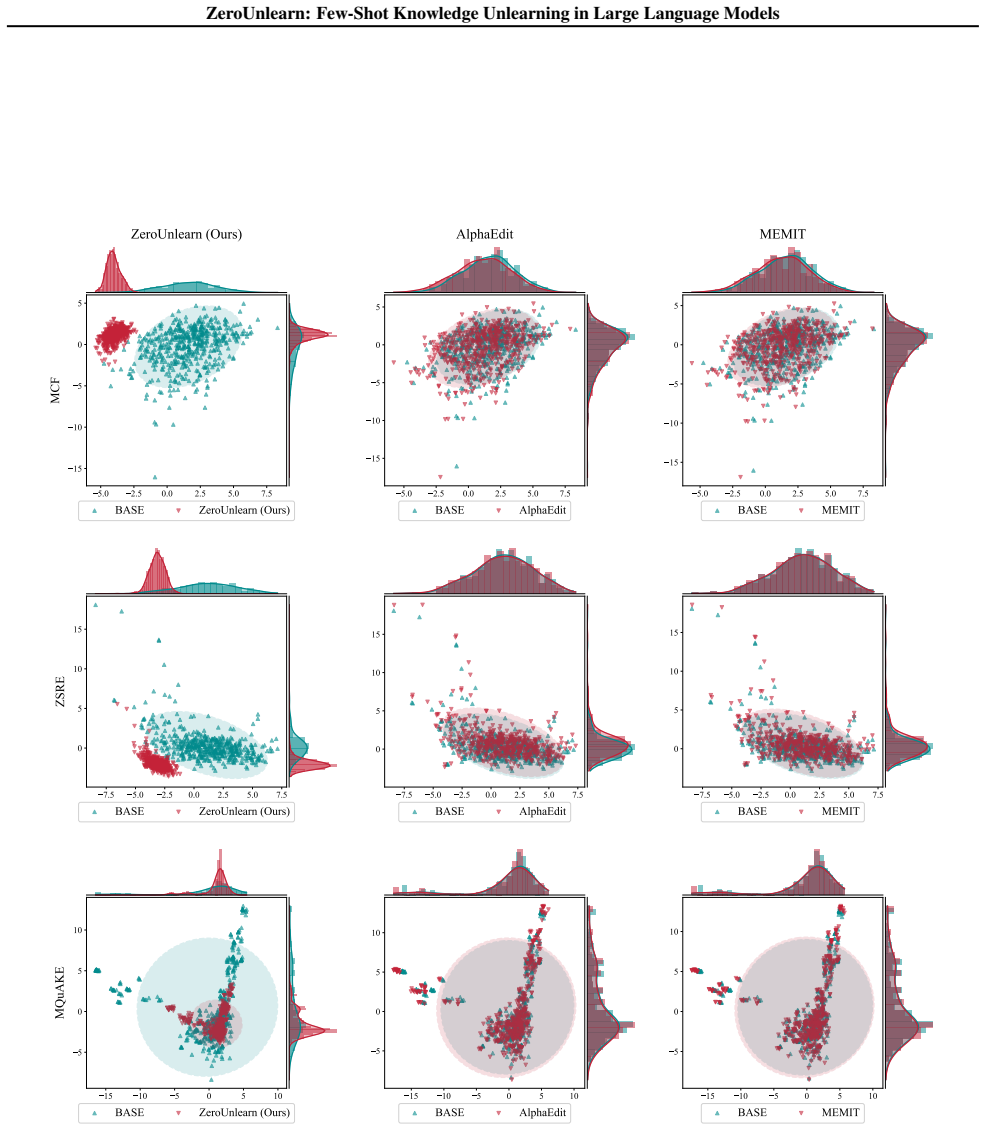
- [§3] §3 (Method), closed-form multiplicative update: the central claim requires that this update produces exact representational orthogonality between sensitive inputs and their original directions. However, when sensitive and retained knowledge share latent directions (as is common in distributed LLM representations), the low-rank correction may perturb shared singular vectors. The manuscript must supply either a formal isolation guarantee or targeted experiments measuring collateral effects on semantically related but non-sensitive inputs.
- [§3.2] §3.2 (closed-form derivation): the update is presented as a new derivation enabling precise orthogonality. It is unclear whether the solution is genuinely novel or reduces to a standard orthogonal projection onto the complement of the sensitive direction (as in prior model-editing work). Explicit comparison to the update rules in ROME/MEMIT and a statement of what is newly derived versus previously known is required.
- [Abstract, §4] Abstract and §4 (Experiments): outperformance over baselines is asserted, yet the abstract supplies no quantitative metrics, specific baselines, or ablation results. The experimental section must report concrete numbers (e.g., unlearning efficacy, utility retention, comparison tables) with statistical detail to substantiate the central empirical claim.
minor comments (3)
- [§3] The definition of the neutral target state and the precise choice of orthogonality metric should be stated explicitly with equation references.
- Add citations to recent LLM unlearning surveys and to the original ROME/MEMIT papers for context on the model-editing framing.
- [Abstract] Verify that the GitHub link is functional and contains the exact code used for the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), closed-form multiplicative update: the central claim requires that this update produces exact representational orthogonality between sensitive inputs and their original directions. However, when sensitive and retained knowledge share latent directions (as is common in distributed LLM representations), the low-rank correction may perturb shared singular vectors. The manuscript must supply either a formal isolation guarantee or targeted experiments measuring collateral effects on semantically related but non-sensitive inputs.
Authors: We agree that shared latent directions between sensitive and retained knowledge represent a potential source of collateral effects in any low-rank editing approach. Our multiplicative update is constructed to enforce orthogonality specifically on the sensitive directions identified in the few-shot regime, but we acknowledge that a formal isolation guarantee under arbitrary distribution overlap is not provided in the current draft. To address this, we will add targeted experiments that measure performance on semantically related but explicitly non-sensitive inputs (e.g., paraphrases and neighboring concepts) and report the resulting utility degradation. These results will be included in a new subsection of §4. revision: yes
-
Referee: [§3.2] §3.2 (closed-form derivation): the update is presented as a new derivation enabling precise orthogonality. It is unclear whether the solution is genuinely novel or reduces to a standard orthogonal projection onto the complement of the sensitive direction (as in prior model-editing work). Explicit comparison to the update rules in ROME/MEMIT and a statement of what is newly derived versus previously known is required.
Authors: The closed-form multiplicative update is derived from the requirement of exact orthogonality under a multiplicative (rather than additive) parameter change, which yields a different algebraic solution than the additive rank-one updates in ROME or the multi-layer MEMIT formulation. While the geometric goal of removing a direction is related, the multiplicative structure and the closed-form expression that avoids iterative optimization are specific to our unlearning objective. We will insert a dedicated paragraph in §3.2 that explicitly contrasts the update rule with the ROME and MEMIT formulations, highlighting the differences in the derivation and the resulting parameter update. revision: yes
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): outperformance over baselines is asserted, yet the abstract supplies no quantitative metrics, specific baselines, or ablation results. The experimental section must report concrete numbers (e.g., unlearning efficacy, utility retention, comparison tables) with statistical detail to substantiate the central empirical claim.
Authors: We accept that the abstract should contain the key quantitative findings. In the revised manuscript we will expand the abstract to include the main metrics (unlearning efficacy, utility retention on standard benchmarks, and direct comparison to the strongest baselines) together with the number of shots used. The experimental section already contains comparison tables; we will add statistical significance markers (standard deviations over multiple runs) and an explicit ablation table to make the empirical support fully transparent. revision: yes
Circularity Check
No significant circularity in derivation of closed-form update
full rationale
The paper reformulates unlearning as knowledge re-mapping and derives a multiplicative parameter update with closed-form solution to enforce representational orthogonality between sensitive inputs and their original directions. This derivation is presented as a direct mathematical construction from the orthogonality objective rather than a reduction to previously fitted quantities, self-citations, or ansatzes imported from the authors' prior work. No load-bearing step reduces by construction to its own inputs, and the method is self-contained against the stated assumptions without invoking uniqueness theorems or renaming known results. The central claim therefore stands as an independent proposal.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MemGraphRAG: Memory-based Multi-Agent System for Graph Retrieval-Augmented Generation
MemGraphRAG uses a memory-based multi-agent system for globally consistent graph construction from fragmented corpora plus a memory-aware hierarchical retriever, claiming better benchmark performance than prior GraphR...
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Soft prompting for unlearning in large language models
Bhaila, K., Van, M.-H., and Wu, X. Soft prompting for unlearning in large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 4046–4056,
2025
-
[3]
arXiv preprint arXiv:2310.02238 , year=
URL https: //arxiv.org/abs/2310.02238. Fang, J., Jiang, H., Wang, K., Ma, Y ., Jie, S., Wang, X., He, X., and Chua, T.-S. Alphaedit: Null-space constrained knowledge editing for language models.arXiv preprint arXiv:2410.02355,
-
[4]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:1911.03030 , year=
Guo, C., Goldstein, T., Hannun, A., and Van Der Maaten, L. Certified data removal from machine learning models. arXiv preprint arXiv:1911.03030,
-
[7]
Measuring Massive Multitask Language Understanding
URL https: //arxiv.org/abs/2009.03300. Huang, Z., Shen, Y ., Zhang, X., Zhou, J., Rong, W., and Xiong, Z. Transformer-patcher: One mistake worth one neuron.arXiv preprint arXiv:2301.09785,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
Soul: Unlocking the power of second-order optimization for llm unlearning
Jia, J., Zhang, Y ., Zhang, Y ., Liu, J., Runwal, B., Diffend- erfer, J., Kailkhura, B., and Liu, S. Soul: Unlocking the power of second-order optimization for llm unlearning. arXiv preprint arXiv:2404.18239,
-
[9]
Object Hallucination-Free Reinforcement Unlearning for Vision-Language Models
URL https://arxiv.org/ abs/2605.08031. Levy, O., Seo, M., Choi, E., and Zettlemoyer, L. Zero- shot relation extraction via reading comprehension,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Zero-Shot Relation Extraction via Reading Comprehension
URLhttps://arxiv.org/abs/1706.04115. Lin, Y ., Zhao, C., Shao, M., Meng, B., Zhao, X., and Chen, H. Towards counterfactual fairness-aware domain gen- eralization in changing environments.arXiv preprint arXiv:2309.13005,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Lin, Y ., Li, D., Shao, M., Wan, G., and Zhao, C. Fade: Towards fairness-aware generation for domain general- ization via classifier-guided score-based diffusion models. arXiv preprint arXiv:2406.09495,
-
[12]
URL https://openreview.net/forum? id=mUTN9VIaSy. Ma, G., Zhang, L., Tu, H., Fu, H., Li, H., Lin, Y ., Wang, L., Luo, W., and Su, J. Hcre: Llm-based hierarchical classification for cross-document relation extraction with a prediction-then-verification strategy.arXiv preprint arXiv:2604.07937,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
TOFU: A Task of Fictitious Unlearning for LLMs
Maini, P., Feng, Z., Schwarzschild, A., Lipton, Z. C., and Kolter, J. Z. Tofu: A task of fictitious unlearning for llms. arXiv preprint arXiv:2401.06121,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Mass-Editing Memory in a Transformer
Meng, K., Bau, D., Andonian, A., and Belinkov, Y . Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022a. Meng, K., Sharma, A. S., Andonian, A., Belinkov, Y ., and Bau, D. Mass-editing memory in a transformer.arXiv preprint arXiv:2210.07229, 2022b. Mitchell, E., Lin, C., Bosselut, A., Fin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Scalable Extraction of Training Data from (Production) Language Models
Nasr, M., Carlini, N., Hayase, J., Jagielski, M., Cooper, A. F., Ippolito, D., Choquette-Choo, C. A., Wallace, E., Tram`er, F., and Lee, K. Scalable extraction of training data from (production) language models.arXiv preprint arXiv:2311.17035,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Supervised algorithmic fairness in distribution shifts: A survey.arXiv preprint arXiv:2402.01327,
Shao, M., Li, D., Zhao, C., Wu, X., Lin, Y ., and Tian, Q. Supervised algorithmic fairness in distribution shifts: A survey.arXiv preprint arXiv:2402.01327,
-
[17]
D., Ng, A., and Potts, C
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A., and Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Yarowsky, D., Baldwin, T., Korhonen, A., Livescu, K., and Bethard, S. (eds.),Proceedings of the 2013 Confer- ence on Empirical Methods in Natural Language Process- ing, pp. 1631–1642, Seattl...
2013
-
[18]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
URLhttps://arxiv.org/abs/1804.07461. Wang, X., Liu, X., Wang, L., Wu, S., Su, J., and Wu, H. A simple yet effective self-debiasing framework for transformer models.Artificial In- telligence, 339:104258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
doi: https://doi.org/10.1016/j.artint.2024.104258
ISSN 0004-3702. doi: https://doi.org/10.1016/j.artint.2024.104258. URL https://www.sciencedirect.com/ science/article/pii/S0004370224001942. 10 ZeroUnlearn: Few-Shot Knowledge Unlearning in Large Language Models Warstadt, A., Singh, A., and Bowman, S. R. Neural network acceptability judgments.Transactions of the Association for Computational Linguistics, ...
-
[20]
Unveiling the Implicit Toxicity in Large Language Models, November 2023
Wen, J., Ke, P., Sun, H., Zhang, Z., Li, C., Bai, J., and Huang, M. Unveiling the implicit toxicity in large lan- guage models.arXiv preprint arXiv:2311.17391,
-
[21]
A broad- coverage challenge corpus for sentence understanding through inference
Williams, A., Nangia, N., and Bowman, S. A broad- coverage challenge corpus for sentence understanding through inference. InProceedings of the 2018 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long papers), pp. 1112–1122,
2018
-
[22]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Machine unlearning of pre-trained large language models.arXiv preprint arXiv:2402.15159, 2024a
Yao, J., Chien, E., Du, M., Niu, X., Wang, T., Cheng, Z., and Yue, X. Machine unlearning of pre-trained large language models.arXiv preprint arXiv:2402.15159, 2024a. Yao, Y ., Xu, X., and Liu, Y . Large language model unlearn- ing.Advances in Neural Information Processing Systems, 37:105425–105475, 2024b. Zhang, R., Lin, L., Bai, Y ., and Mei, S. Negative...
-
[24]
URL https: //arxiv.org/abs/2305.14795. Zhu, C., Rawat, A. S., Zaheer, M., Bhojanapalli, S., Li, D., Yu, F., and Kumar, S. Modifying memories in transformer models.arXiv preprint arXiv:2012.00363,
-
[25]
over-correction
11 ZeroUnlearn: Few-Shot Knowledge Unlearning in Large Language Models A. Notation Table 3.Summary of symbols used throughout the paper. Vectors and matrices are in bold. Symbol Meaning Df ={(x i, yi)}n i=1 Forget set (samples whose influence should be removed). fθ,θ∈ΘPre-trained language model parameterized byθ. U(·)Unlearning operator;θ ′ =U(θ,D f). θ′,...
2023
-
[26]
I don’t know
Impact of the Neutral Target State (Mn).As shown in Table 4, incorporating Mn yields a consistent improvement in unlearning performance across all model architectures. The inclusion of the target state significantly reduces the Efficacy (Eff.) and Generalization (Gen.) scores (where lower values indicate better unlearning). For instance, on Llama-3.1, the...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.