Recognition: no theorem link
HCRE: LLM-based Hierarchical Classification for Cross-Document Relation Extraction with a Prediction-then-Verification Strategy
Pith reviewed 2026-05-10 18:30 UTC · model grok-4.3
The pith
A hierarchical relation tree plus prediction verification lets large language models beat baselines on cross-document relation extraction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that deriving a hierarchical relation tree from the predefined set lets an LLM classify cross-document relations level by level with far fewer choices per step, and that inserting a prediction-then-verification procedure at each level prevents error propagation, producing higher accuracy than flat LLM prompting or SLM-plus-classifier pipelines.
What carries the argument
The hierarchical relation tree, which decomposes the full relation set into levels of limited children, together with the prediction-then-verification inference routine that performs multi-view checks before descending.
If this is right
- LLMs become competitive for relation extraction once the label space is decomposed hierarchically.
- Error accumulation across classification levels can be controlled by adding verification at each step.
- The same tree structure could reduce the effective label space in other multi-relation tasks.
- Performance gains appear without any change in model size or training data.
Where Pith is reading between the lines
- The same narrowing-plus-check pattern may help LLMs on other wide-label problems such as event argument extraction.
- If hierarchies can be learned automatically rather than hand-derived, the method could scale to open relation sets.
- Verification at each level resembles a lightweight form of self-consistency that might transfer to other multi-step LLM pipelines.
Load-bearing premise
The predefined relations can be grouped into a hierarchy that actually shrinks the decision space enough to help, and the verification step catches most mistakes before they reach the next level.
What would settle it
On a standard cross-document RE benchmark, if the hierarchical-plus-verification method produces accuracy no higher than direct LLM prompting or existing SLM baselines, the central claim would be falsified.
Figures






read the original abstract
Cross-document relation extraction (RE) aims to identify relations between the head and tail entities located in different documents. Existing approaches typically adopt the paradigm of ``\textit{Small Language Model (SLM) + Classifier}''. However, the limited language understanding ability of SLMs hinders further improvement of their performance. In this paper, we conduct a preliminary study to explore the performance of Large Language Models (LLMs) in cross-document RE. Despite their extensive parameters, our findings indicate that LLMs do not consistently surpass existing SLMs. Further analysis suggests that the underperformance is largely attributed to the challenges posed by the numerous predefined relations. To overcome this issue, we propose an LLM-based \underline{H}ierarchical \underline{C}lassification model for cross-document \underline{RE} (HCRE), which consists of two core components: 1) an LLM for relation prediction and 2) a \textit{hierarchical relation tree} derived from the predefined relation set. This tree enables the LLM to perform hierarchical classification, where the target relation is inferred level by level. Since the number of child nodes is much smaller than the size of the entire predefined relation set, the hierarchical relation tree significantly reduces the number of relation options that LLM needs to consider during inference. However, hierarchical classification introduces the risk of error propagation across levels. To mitigate this, we propose a \textit{prediction-then-verification} inference strategy that improves prediction reliability through multi-view verification at each level. Extensive experiments show that HCRE outperforms existing baselines, validating its effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HCRE, an LLM-based model for cross-document relation extraction that constructs a hierarchical relation tree from the predefined relation set to enable level-by-level classification, thereby reducing the number of candidate relations the LLM must consider at each step. A prediction-then-verification inference strategy is introduced to mitigate error propagation across hierarchy levels. A preliminary study shows that direct LLM use does not consistently outperform SLM+classifier baselines due to large relation sets, and the authors claim that extensive experiments validate HCRE's superiority over existing methods.
Significance. If the empirical results hold, the hierarchical reduction of option space combined with multi-view verification offers a practical mechanism for improving LLM reliability on classification tasks with large label sets, which is relevant beyond RE to other structured prediction problems. The approach is grounded in an empirical diagnosis of LLM limitations rather than purely theoretical assumptions, and the absence of free parameters or circular definitions in the core construction is a positive feature.
major comments (2)
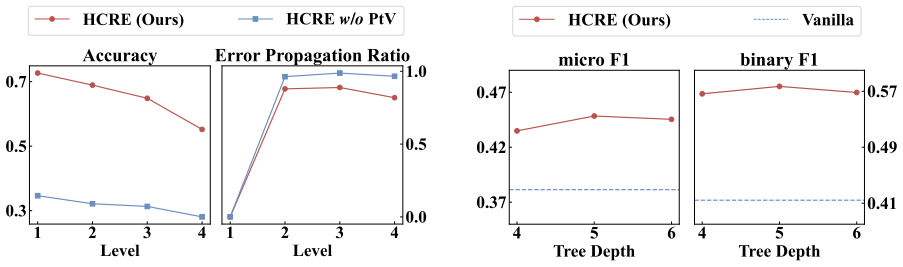
- [§4 and abstract] §4 (Experiments) and the abstract: the central claim that HCRE 'outperforms existing baselines' is load-bearing, yet the provided description supplies no concrete metrics (F1, accuracy), dataset names, baseline implementations, or ablation results on the verification component. Without per-level error rates or a controlled comparison of hierarchical classification with vs. without verification, it is impossible to confirm that the tree reduces options sufficiently or that verification prevents propagation as assumed.
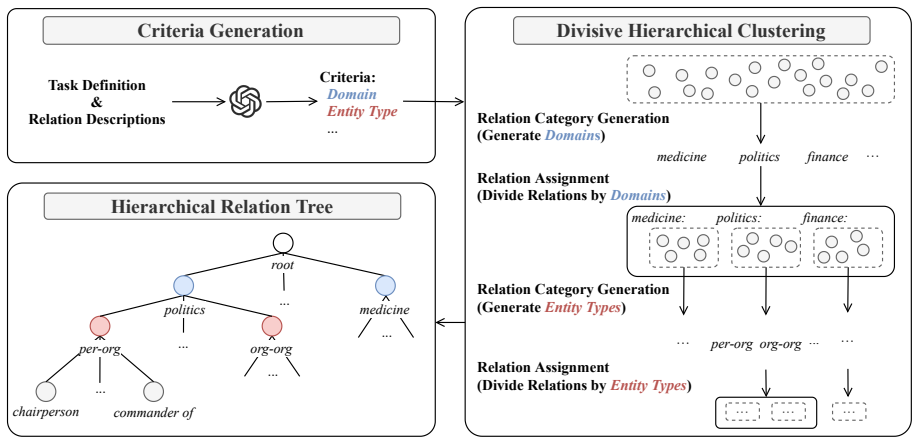
- [§3.2] §3.2 (hierarchical relation tree construction): the method for deriving the tree from the predefined relation set is described at a high level but lacks an explicit algorithm, example, or pseudocode. This is critical because the claim that 'the number of child nodes is much smaller' depends on the specific hierarchy; without it, reproducibility and the generality of the reduction effect cannot be assessed.
minor comments (2)
- [abstract] Abstract: the claim of 'extensive experiments' is stated without any supporting numbers or dataset references, which is a presentation issue that should be addressed by adding at least one quantitative highlight.
- [§3.3] Notation: the distinction between the LLM prediction step and the verification step could be clarified with a small diagram or pseudocode in §3.3 to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to improve clarity and empirical detail.
read point-by-point responses
-
Referee: [§4 and abstract] §4 (Experiments) and the abstract: the central claim that HCRE 'outperforms existing baselines' is load-bearing, yet the provided description supplies no concrete metrics (F1, accuracy), dataset names, baseline implementations, or ablation results on the verification component. Without per-level error rates or a controlled comparison of hierarchical classification with vs. without verification, it is impossible to confirm that the tree reduces options sufficiently or that verification prevents propagation as assumed.
Authors: We appreciate the referee pointing out the need for more explicit empirical support. Section 4 of the manuscript already reports F1 scores, dataset names, and baseline comparisons, but we agree the abstract should highlight key numbers and that additional controlled analysis would strengthen the claims. In the revision we will (1) update the abstract with specific F1 improvements over baselines, (2) add per-level error rates, and (3) include a new ablation table comparing the full prediction-then-verification strategy against hierarchical classification without verification. These changes will make the contribution of each component directly verifiable. revision: yes
-
Referee: [§3.2] §3.2 (hierarchical relation tree construction): the method for deriving the tree from the predefined relation set is described at a high level but lacks an explicit algorithm, example, or pseudocode. This is critical because the claim that 'the number of child nodes is much smaller' depends on the specific hierarchy; without it, reproducibility and the generality of the reduction effect cannot be assessed.
Authors: We agree that an explicit algorithm and example are necessary for reproducibility. We will add pseudocode describing the tree-construction procedure to Section 3.2 and include a worked example that shows how a sample relation set is partitioned into levels, confirming the reduction in child-node cardinality at each step. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives its HCRE model from an empirical preliminary study showing LLM underperformance on large relation sets, then constructs a hierarchical relation tree directly from the standard predefined relation set and adds a prediction-then-verification strategy as a mitigation. These components are presented as engineering solutions rather than self-referential definitions or fitted parameters renamed as predictions. Central claims rest on external experimental comparisons against baselines, with no load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. The derivation chain remains self-contained against the reported empirical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs do not consistently surpass SLMs in cross-document RE primarily due to the large number of predefined relations
invented entities (2)
-
hierarchical relation tree
no independent evidence
-
prediction-then-verification inference strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SWE-AGILE: A Software Agent Framework for Efficiently Managing Dynamic Reasoning Context
Exploring label hierarchy in a generative way for hierarchical text classification. InCOLING 2022. Monika Jain, Raghava Mutharaju, Kuldeep Singh, and Ramakanth Kavuluru. 2024a. Knowledge-driven cross-document relation extraction. InFindings of ACL 2024. Vidit Jain, Mukund Rungta, Yuchen Zhuang, Yue Yu, Zeyu Wang, Mu Gao, Jeffrey Skolnick, and Chao Zhang. ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Label augmentation for zero-shot hierarchical text classification. InACL 2024. Liangying Shao, Liang Zhang, Minlong Peng, Guoqi Ma, Hao Yue, Mingming Sun, and Jinsong Su. 2024. One2Set + large language model: Best partners for keyphrase generation. InEMNLP 2024. Junyoung Son, Jinsung Kim, Jungwoo Lim, Yoonna Jang, and Heuiseok Lim. 2023. Explore the way: ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
AutoRE: Document-level relation extraction with large language models. InACL 2024. An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Hao- ran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, and 40 others. 2024. Qwen2 technical...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Towards better document-level relation extrac- tion via iterative inference. InEMNLP 2022. Liang Zhang, Jinsong Su, Zijun Min, Zhongjian Miao, Qingguo Hu, Biao Fu, Xiaodong Shi, and Yidong Chen. 2023b. Exploring self-distillation based rela- tional reasoning training for document-level relation extraction. InAAAI 2023. Liang Zhang, Zhen Yang, Biao Fu, Ziy...
-
[5]
In EMNLP 2024
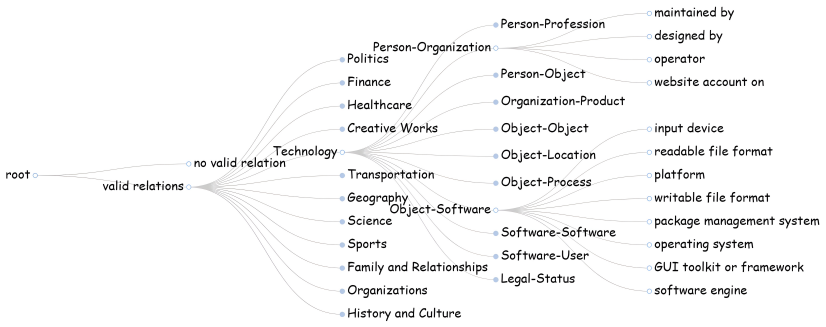
Grasping the essentials: Tailoring large lan- guage models for zero-shot relation extraction. In EMNLP 2024. A Details of Hierarchical Relation Tree A.1 Prompt Templates for Tree Construction As illustrated in Figure 8, our tree construction pipeline begins by deriving a set of partitioning cri- teria to progressively partition the relations. Using these ...
2024
-
[6]
Provide 10-12 distinct classification cri- teria with concise names (1-2 words)
-
[7]
Choose the top 2 criteria that might yield the most effective classification results
-
[8]
classification criteria
Return the result in a valid JSON format as shown below. JSON Output Format: ```json { “classification criteria”: { “criterion name 1”: { “explanation”: “explanation of criterion 1”, “possible category names”: [ “category name 1”, “category name 2” ] }, “criterion name 2”: { “explanation”: “explanation of criterion 1”, “possible category names”: [ “catego...
-
[9]
Each [CRITERION_NAME] should have aCONCISE, CLEAR and STRUC- TUREDname (1-2 words) reflecting its theme (e.g., [CRITERION_EXAMPLES])
-
[10]
Ensure that [CRITERION_NAME]s do not overlap in meaning, with each covering a single [CRITERION_NAME]
-
[11]
Ensure that [CRITERION_NAME]s coverALLprovided relation types
-
[12]
Provide a brief yet precise de- scription (~15 words) for each [CRITE- RION_NAME]
-
[13]
name of [CRITERION_NAME] 1
Return the result in a valid JSON format as shown below. JSON Output Format: ```json { “name of [CRITERION_NAME] 1”: “de- scription of [CRITERION_NAME] 1”, “name of [CRITERION_NAME] 2”: “de- scription of [CRITERION_NAME] 2”, ... } ``` Relation Types and Descriptions: Criteria Generation Divisive Hierarchical Clustering Relation Category Generation (Genera...
-
[14]
domain”, “entity types
among trees generated with different random Tree Construction Parameters Value micro F1 binary F1 Random Seed 42 45.35 58.19 666 44.50 57.42 1024 44.55 57.98 Criterion Set (Domain, Entity Type) 45.35 58.19 (Domain, Polarity) 45.10 57.08 (Entity Type, Polarity) 44.14 57.36 Table 5: Experiment results with varying tree construction parameters. #Input Tokens...
2023
-
[15]
": "<description of >
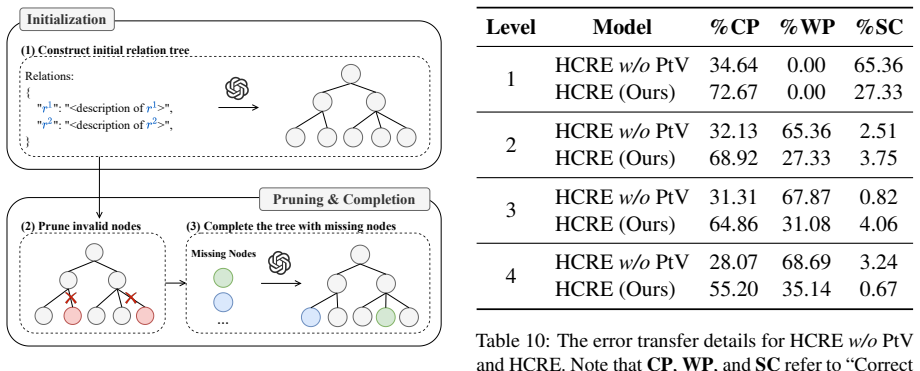
to preprocess all text paths. D Thew/oLTC Variant Different from the level-wise pipeline of tree con- struction, in this variant, we first prompt the LLM M2 with predefined relations to directly generate Relations: { " ": "<description of >", " ": "<description of >", } (1) Construct initial relation tree Initialization Pruning & Completion ... (2) Prune ...
-
[16]
The confidence scores of predicted relations are also recorded for tie-breaking
The LLM independently generates a relation prediction for every text path within a bag. The confidence scores of predicted relations are also recorded for tie-breaking
-
[17]
For each bag, the most frequent positive rela- tion is selected as the bag-level prediction
-
[18]
If multiple relations are tied for the highest frequency, we choose the relation with the highest confidence as the bag-level prediction
-
[19]
If all paths within the bag are predicted as NA, the bag-level prediction is NA. Notably, the bag-level evaluation is essentially an- other form of path-level evaluation, requiring no additional model training or inference. Therefore, the two evaluation protocols are fundamentally con- sistent. As shown in Table 11, HCRE still signif- icantly outperforms ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.