Why We Need World Models for AGI: Where LLMs Fail and How World Models May Outperform
Pith reviewed 2026-06-30 21:34 UTC · model grok-4.3
The pith
Agents with explicit access to latent states win 79 percent in long-horizon tasks where LLMs reach only 11 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
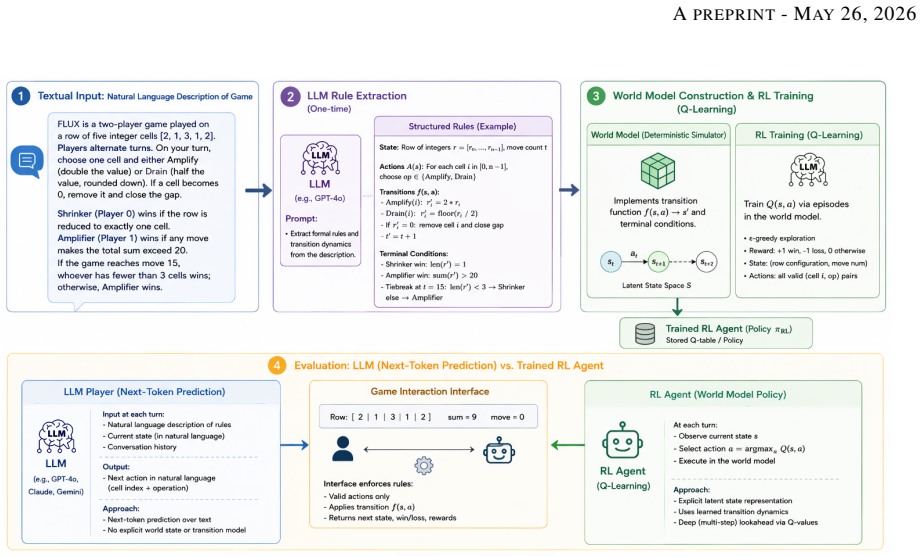
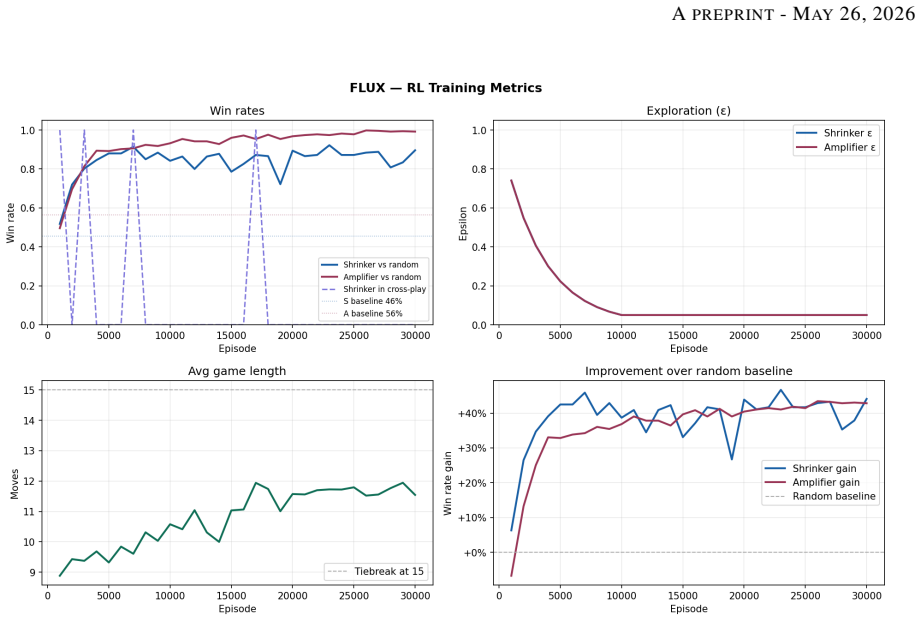
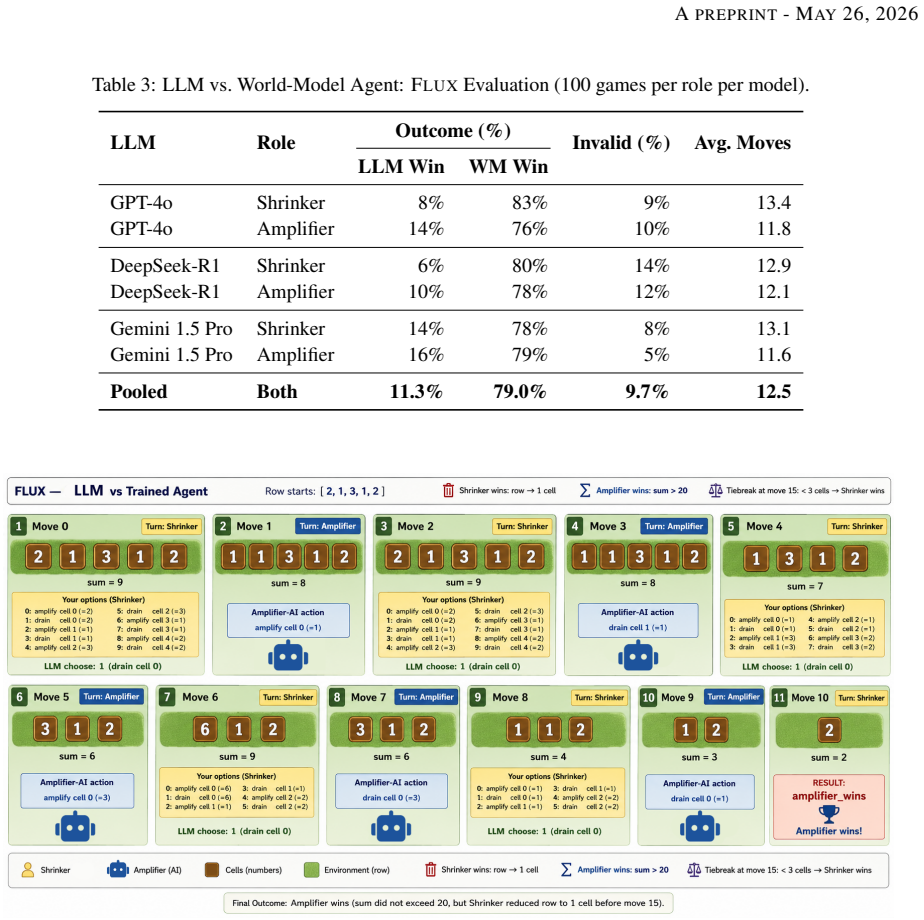
In the Flux case study, agents given explicit access to the latent state space exhibit substantially more stable behavior in long-horizon gameplay, achieving an aggregate win rate of approximately 79 percent versus 11 percent for LLMs. Qualitative analysis shows LLMs producing invalid actions, state-tracking errors, and short-horizon reasoning failures. The results indicate that strong sequence prediction alone may struggle to support robust long-horizon dynamic reasoning without mechanisms for persistent state tracking and transition modeling.
What carries the argument
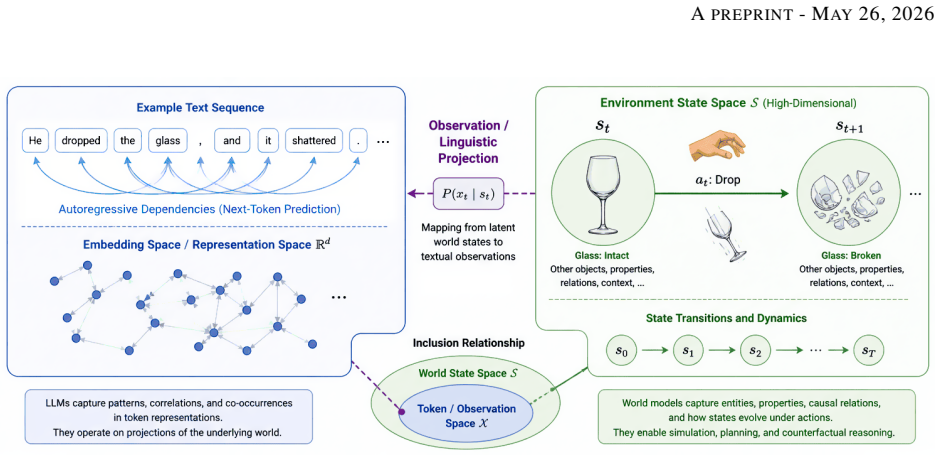
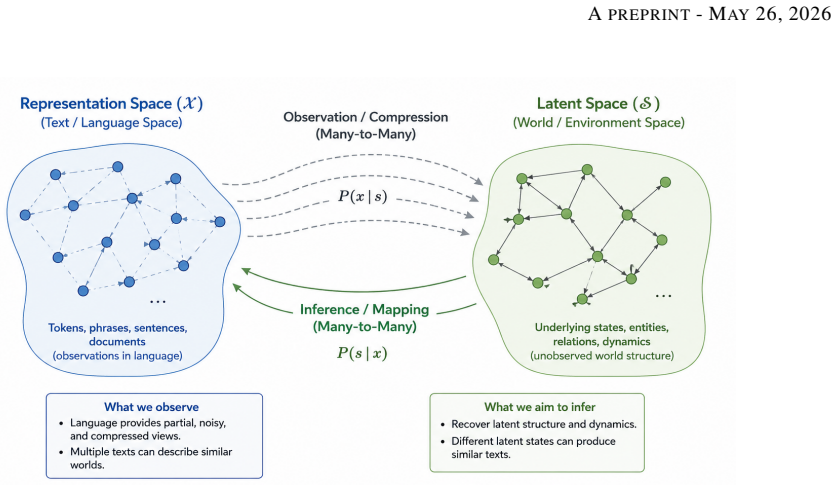
Latent Dynamics Inference, the view that language and multimodal observations supply partial evidence of underlying transition dynamics, operationalized through the Flux simulator that converts natural-language rules into an explicit state-transition model.
If this is right
- LLMs may need added components for persistent state tracking to handle tasks with extended dependencies.
- Transition dynamics extracted from textual rules can serve as a ground-truth baseline for measuring model limitations in sequential settings.
- Agents that maintain explicit representations of environment changes can sustain planning across many steps where pure sequence models lose coherence.
- The distinction between sequence prediction and latent dynamics modeling may explain why current LLMs show instability on long-horizon decision problems.
Where Pith is reading between the lines
- Hybrid architectures that pair language models with separate world-model modules could address the observed planning deficits without discarding sequence capabilities.
- If the pattern generalizes, continued scaling of next-token prediction alone may reach limits on tasks that require causal simulation of changing states.
- Comparable rule-to-simulator extractions could be applied to other structured domains such as simple physics or board-game rule sets to test the same distinction.
Load-bearing premise
The natural-language rules of Flux can be compiled into an explicit state-transition simulator that faithfully represents the latent dynamics and supplies a fair comparison baseline for text-only models.
What would settle it
A controlled run in which LLMs supplied with external memory or explicit state vectors reach win rates near 79 percent in Flux would indicate that the performance gap does not require separate transition modeling.
Figures
read the original abstract
Large language models achieve strong performance in language generation and knowledge-intensive tasks, yet remain limited in settings requiring causal reasoning, persistent state tracking, and long-horizon planning. We argue that these limitations may arise from an objective-level mismatch between sequence prediction and reasoning over latent environment dynamics. To formalize this distinction, we introduce Latent Dynamics Inference (LDI), a conceptual perspective that interprets language and multimodal observations as partial evidence of underlying transition dynamics. To empirically investigate this perspective, we introduce Flux, a sequential reasoning environment specified entirely through natural-language rules. As a proof-of-concept case study, the rules are first compiled into an explicit state-transition simulator, illustrating that structured latent transition dynamics can, in some cases, be operationally extracted from textual rule descriptions. This enables a controlled comparison between the LLMs operating purely over textual observations and reinforcement-learning agents trained directly within the extracted latent state space. Within this case study, agents operating with explicit access to the latent state space exhibit substantially more stable behavior in long-horizon gameplay, achieving an aggregate win rate of approximately 79% versus 11% for LLMs. Qualitative analysis further reveals failure modes consistent with unstable persistent state tracking, including invalid actions, state-tracking errors, and short-horizon reasoning failures. The complete implementation of the Flux environment available at https://github.com/FeisalAlaswad/FLUX-RL-Agent Within the evaluated setting, these results suggest that strong sequence prediction alone may struggle to support robust long-horizon dynamic reasoning without mechanisms for persistent state tracking and transition modeling
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs are limited in causal reasoning, persistent state tracking, and long-horizon planning due to an objective mismatch with sequence prediction. It introduces Latent Dynamics Inference (LDI) as a perspective on observations as partial evidence of latent transitions, presents the Flux environment defined entirely by natural-language rules, compiles those rules into an explicit state-transition simulator, and reports a controlled comparison in which RL agents with direct access to the latent state space achieve an aggregate win rate of approximately 79% versus 11% for LLMs operating on textual observations. Qualitative analysis identifies LLM failure modes such as invalid actions and state-tracking errors. The Flux implementation is released on GitHub.
Significance. If the simulator is shown to be a faithful extraction of the latent dynamics, the result would provide concrete evidence that explicit world models can support more stable long-horizon behavior than pure sequence prediction in rule-specified environments. The open-source release and the introduction of a fully textual-rule environment are positive contributions to reproducibility and to the study of world-model advantages. The work remains a single proof-of-concept case study whose generality is not yet established.
major comments (2)
- [Abstract / Flux environment] Abstract and Flux environment description: the headline 79% versus 11% win-rate comparison is load-bearing for the central claim, yet the manuscript provides no validation metrics, coverage checks, equivalence proofs, or inter-rater agreement scores confirming that the compiled state-transition simulator faithfully reproduces all preconditions, transition probabilities, and state variables implicit in the natural-language rules. Without such evidence the performance gap could arise from systematic information asymmetry rather than from the absence of world-model mechanisms.
- [Empirical evaluation] Experimental comparison section: the reported win rates are stated without trial count, variance, statistical tests, action-space equivalence controls, prompt-engineering details, or handling of invalid actions and length biases. These omissions make it impossible to assess whether the 79%–11% difference is robust or diagnostic of the LDI distinction.
minor comments (2)
- [Latent Dynamics Inference] The definition of LDI is presented conceptually but lacks a formal mathematical statement (e.g., an equation relating observations, latent states, and transition functions) that would allow readers to distinguish it from standard POMDP or latent-variable formulations.
- [Implementation] The GitHub link is given, but the manuscript does not include a reproducibility checklist or explicit mapping between the released code and the exact rule-to-simulator compilation procedure used for the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional rigor would strengthen the presentation. Flux is offered as a controlled proof-of-concept case study rather than a general claim; we address each major point below and commit to revisions that improve transparency without altering the core argument.
read point-by-point responses
-
Referee: [Abstract / Flux environment] Abstract and Flux environment description: the headline 79% versus 11% win-rate comparison is load-bearing for the central claim, yet the manuscript provides no validation metrics, coverage checks, equivalence proofs, or inter-rater agreement scores confirming that the compiled state-transition simulator faithfully reproduces all preconditions, transition probabilities, and state variables implicit in the natural-language rules. Without such evidence the performance gap could arise from systematic information asymmetry rather than from the absence of world-model mechanisms.
Authors: We agree that explicit validation evidence is currently absent and that this leaves open the possibility of information asymmetry. In revision we will add a new subsection detailing the compilation procedure, including (i) manual spot-checks of 50 randomly sampled state transitions against the source rules, (ii) enumeration of all state variables and preconditions with coverage statistics, and (iii) equivalence tests on a held-out set of rule-derived scenarios. Because the simulator is produced by direct, deterministic compilation rather than learned approximation, inter-rater agreement metrics are not applicable; the added checks will nevertheless demonstrate fidelity and rule out systematic mismatch as the source of the observed gap. revision: yes
-
Referee: [Empirical evaluation] Experimental comparison section: the reported win rates are stated without trial count, variance, statistical tests, action-space equivalence controls, prompt-engineering details, or handling of invalid actions and length biases. These omissions make it impossible to assess whether the 79%–11% difference is robust or diagnostic of the LDI distinction.
Authors: We accept that these reporting omissions prevent proper evaluation. The revised experimental section will report: 100 independent episodes per condition, mean win rates accompanied by standard deviations, two-sided t-tests with p-values, explicit confirmation that both agents operate over identical action vocabularies, the exact prompt templates and decoding parameters used for each LLM, and the precise mechanisms for invalid actions (rejection sampling plus length penalty for LLMs; action masking for the RL agent). Episode length will be fixed across conditions to eliminate horizon bias. These additions will allow readers to judge robustness directly. revision: yes
Circularity Check
No circularity: empirical comparison in novel environment
full rationale
The paper's central claim is an empirical result from a new environment (Flux) where natural-language rules are compiled into a simulator for comparing LLMs (text observations) against RL agents (explicit state). No equations, fitted parameters, or self-citations appear in the derivation chain; the 79% vs 11% win-rate difference is a direct experimental outcome rather than a quantity defined by construction from inputs. The perspective (LDI) is conceptual framing, not a mathematical reduction. This is a self-contained case study against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural-language rules in Flux can be compiled into an explicit state-transition simulator that captures the underlying latent dynamics
- domain assumption LLMs in the comparison receive only textual observations and have no access to the latent state representation
invented entities (2)
-
Latent Dynamics Inference (LDI)
no independent evidence
-
Flux environment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Better autoregressive regression with llms via regression-aware fine-tuning
Michal Lukasik, Zhao Meng, Harikrishna Narasimhan, Yin-Wen Chang, Aditya Krishna Menon, Felix Yu, and Sanjiv Kumar. Better autoregressive regression with llms via regression-aware fine-tuning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[2]
Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
2025
-
[3]
Xingxuan Zhang, Jiansheng Li, Wenjing Chu, Junjia Hai, Renzhe Xu, Yuqing Yang, Shikai Guan, Jiazheng Xu, and Peng Cui. On the out-of-distribution generalization of multimodal large language models.arXiv preprint arXiv:2402.06599, 2024
-
[4]
Large language models (llms): survey, technical frameworks, and future challenges.Artificial Intelligence Review, 57(10):260, 2024
Pranjal Kumar. Large language models (llms): survey, technical frameworks, and future challenges.Artificial Intelligence Review, 57(10):260, 2024
2024
-
[5]
Multimodal vision-language models in chest x-ray analysis: a study of generalization, supervision, and robustness.Biomedical Engineering Letters, 16(2):517–537, 2026
Batoul Aljaddouh, D Malathi, and Feisal Alaswad. Multimodal vision-language models in chest x-ray analysis: a study of generalization, supervision, and robustness.Biomedical Engineering Letters, 16(2):517–537, 2026
2026
-
[6]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv preprint arXiv:2506.06941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Annie Wong, Thomas Bäck, Aske Plaat, Niki van Stein, and Anna V Kononova. Reasoning capabilities of large language models on dynamic tasks.arXiv preprint arXiv:2505.10543, 2025
-
[8]
Evaluating cognitive maps and planning in large language models with cogeval
Ida Momennejad, Hosein Hasanbeig, Felipe Vieira Frujeri, Hiteshi Sharma, Nebojsa Jojic, Hamid Palangi, Robert Ness, and Jonathan Larson. Evaluating cognitive maps and planning in large language models with cogeval. Advances in Neural Information Processing Systems, 36:69736–69751, 2023
2023
-
[9]
From cocomo to gpt: A comprehensive evaluation of llm-based software effort estimation.IEEE Access, 2026
Feisal Alaswad, E Poovammal, and Batoul Aljaddouh. From cocomo to gpt: A comprehensive evaluation of llm-based software effort estimation.IEEE Access, 2026
2026
-
[10]
Large language models are not strong abstract reasoners.arXiv preprint arXiv:2305.19555, 2023
Gaël Gendron, Qiming Bao, Michael Witbrock, and Gillian Dobbie. Large language models are not strong abstract reasoners.arXiv preprint arXiv:2305.19555, 2023
-
[11]
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, and Dhanya Sridhar. Evaluating interventional reasoning capabilities of large language models.arXiv preprint arXiv:2404.05545, 2024
-
[12]
Evaluation of causal reasoning for large language models in contextualized clinical scenarios of laboratory test interpretation
Balu Bhasuran, Mattia Prosperi, Karim Hanna, John Petrilli, Caretia JeLayne Washington, and Zhe He. Evaluation of causal reasoning for large language models in contextualized clinical scenarios of laboratory test interpretation. npj Digital Medicine, 2026. 17 APREPRINT- MAY26, 2026
2026
-
[13]
CounterBench: Evaluating and Improving Counterfactual Reasoning in Large Language Models
Yuefei Chen, Vivek K Singh, Jing Ma, and Ruxiang Tang. Counterbench: A benchmark for counterfactuals reasoning in large language models.arXiv preprint arXiv:2502.11008, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Cause and effect: Can large language models truly understand causality? InProceedings of the AAAI Symposium Series, volume 4, pages 2–9, 2024
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Dushyant Singh Sengar, Mayank Jindal, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, and Aman Chadha. Cause and effect: Can large language models truly understand causality? InProceedings of the AAAI Symposium Series, volume 4, pages 2–9, 2024
2024
-
[15]
Akshit Sinha, Arvindh Arun, Shashwat Goel, Steffen Staab, and Jonas Geiping. The illusion of diminishing returns: Measuring long horizon execution in llms.arXiv preprint arXiv:2509.09677, 2025
-
[16]
Failure modes in LLM systems: A system-level taxonomy for reliable AI applications
Vaishali Vinay. Failure modes in llm systems: A system-level taxonomy for reliable ai applications.arXiv preprint arXiv:2511.19933, 2025
-
[17]
Mldt: Multi-level decomposition for complex long-horizon robotic task planning with open-source large language model
Yike Wu, Jiatao Zhang, Nan Hu, Lanling Tang, Guilin Qi, Jun Shao, Jie Ren, and Wei Song. Mldt: Multi-level decomposition for complex long-horizon robotic task planning with open-source large language model. In International Conference on Database Systems for Advanced Applications, pages 251–267. Springer, 2024
2024
-
[18]
Grounding large language models in interactive environments with online reinforcement learning
Thomas Carta, Clément Romac, Thomas Wolf, Sylvain Lamprier, Olivier Sigaud, and Pierre-Yves Oudeyer. Grounding large language models in interactive environments with online reinforcement learning. InInternational conference on machine learning, pages 3676–3713. PMLR, 2023
2023
-
[19]
Language models meet world models: Embodied experiences enhance language models.Advances in neural information processing systems, 36:75392–75412, 2023
Jiannan Xiang, Tianhua Tao, Yi Gu, Tianmin Shu, Zirui Wang, Zichao Yang, and Zhiting Hu. Language models meet world models: Embodied experiences enhance language models.Advances in neural information processing systems, 36:75392–75412, 2023
2023
-
[20]
Will multimodal large language models ever achieve deep understanding of the world?Frontiers in Systems Neuroscience, 19:1683133, 2025
Igor Farkaš, Michal Vavreˇcka, and Stefan Wermter. Will multimodal large language models ever achieve deep understanding of the world?Frontiers in Systems Neuroscience, 19:1683133, 2025
2025
-
[21]
Feedback-induced performance decline in llm-based decision-making
Xiao Yang, Juxi Leitner, and Michael Burke. Feedback-induced performance decline in llm-based decision-making. arXiv preprint arXiv:2507.14906, 2025
-
[22]
A review of causal decision making.Journal of Artificial Intelligence Research, 85, 2026
Lin Ge, Hengrui Cai, Runzhe Wan, Yang Xu, and Rui Song. A review of causal decision making.Journal of Artificial Intelligence Research, 85, 2026
2026
-
[23]
Francesco Petri, Luigi Asprino, and Aldo Gangemi. Learning local causal world models with state space models and attention.arXiv preprint arXiv:2505.02074, 2025
-
[24]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Industrial applications of large language models.Scientific Reports, 15(1):13755, 2025
Mubashar Raza, Zarmina Jahangir, Muhammad Bilal Riaz, Muhammad Jasim Saeed, and Muhammad Awais Sattar. Industrial applications of large language models.Scientific Reports, 15(1):13755, 2025
2025
-
[26]
Ai-powered traffic manage- ment: Improving congestion detection and signal regulation
D Malathi, Feisal Alaswad, Batoul Aljaddouh, Leela Ranganayagi, and R Sangeetha. Ai-powered traffic manage- ment: Improving congestion detection and signal regulation. In2025 International Conference on Multi-Agent Systems for Collaborative Intelligence (ICMSCI), pages 899–904. IEEE, 2025
2025
-
[27]
Dreamingv2: Reinforcement learning with discrete world models without reconstruction
Masashi Okada and Tadahiro Taniguchi. Dreamingv2: Reinforcement learning with discrete world models without reconstruction. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 985–991. IEEE, 2022
2022
-
[28]
Dreamerv3 for traffic signal control: hyperparameter tuning and performance
Qiang Li, Yinhan Lin, Qin Luo, and Lina Yu. Dreamerv3 for traffic signal control: hyperparameter tuning and performance. InManagement Science and Industrial Engineering: Proceedings of the 7th International Conference (MSIE 2025), Bali Island, Indonesia, 24-26 April 2025, pages 401–415. SAGE Publications 1 Oliver’s Yard, 55 City Road, London, EC1Y 1SP, 2025
2025
-
[29]
Anurag Koul, Varun V Kumar, Alan Fern, and Somdeb Majumdar. Dream and search to control: Latent space planning for continuous control.arXiv preprint arXiv:2010.09832, 2020
-
[30]
Demystifying muzero planning: Interpreting the learned model.IEEE Transactions on Artificial Intelligence, 2025
Hung Guei, Yan-Ru Ju, Wei-Yu Chen, and Ti-Rong Wu. Demystifying muzero planning: Interpreting the learned model.IEEE Transactions on Artificial Intelligence, 2025
2025
-
[31]
Large language model guided tree-of-thought.arXiv preprint arXiv:2305.08291, 2023
Jieyi Long. Large language model guided tree-of-thought.arXiv preprint arXiv:2305.08291, 2023
-
[32]
Tree of uncertain thoughts reasoning for large language models
Shentong Mo and Miao Xin. Tree of uncertain thoughts reasoning for large language models. InICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12742–12746. IEEE, 2024
2024
-
[33]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning acting and planning in language models.arXiv preprint arXiv:2310.04406, 2023. 18 APREPRINT- MAY26, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Kenneth Li, Aspen K Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Emergent world representations: Exploring a sequence model trained on a synthetic task.arXiv preprint arXiv:2210.13382, 2022
-
[36]
Emergent world models and latent variable estimation in chess-playing language models
Adam Karvonen. Emergent world models and latent variable estimation in chess-playing language models.arXiv preprint arXiv:2403.15498, 2024. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.