VISTA: An End-to-End Benchmark for Visual Spec-to-Web-App Coding Agents
Pith reviewed 2026-06-30 14:42 UTC · model grok-4.3
The pith
VISTA benchmark shows visual fidelity and functional correctness are only partially coupled in web-app coding agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
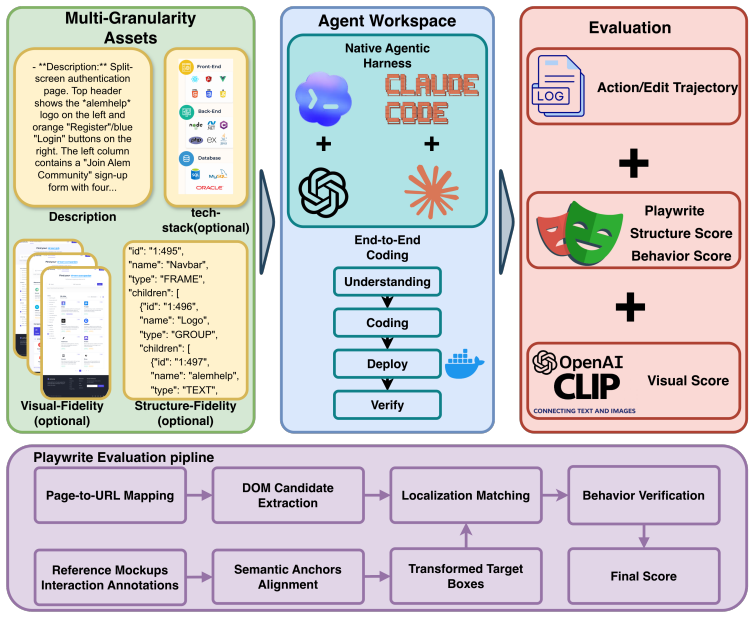
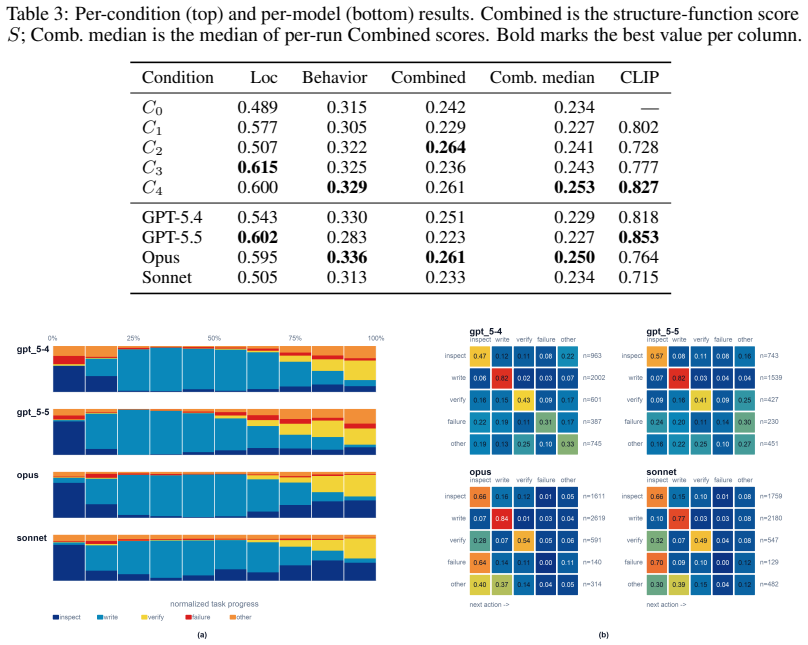
VISTA defines five prompt-information conditions varying visual/structural fidelity and stack constraints, annotates pages with interactive UI components and visual anchors to support robust testing, and combines DOM-grounded matching, behavior-specific browser tests, and CLIP visual similarity to measure structural alignment, behavioral completeness, and visual fidelity, finding that visual fidelity and functional correctness are partially decoupled across input conditions and agents.
What carries the argument
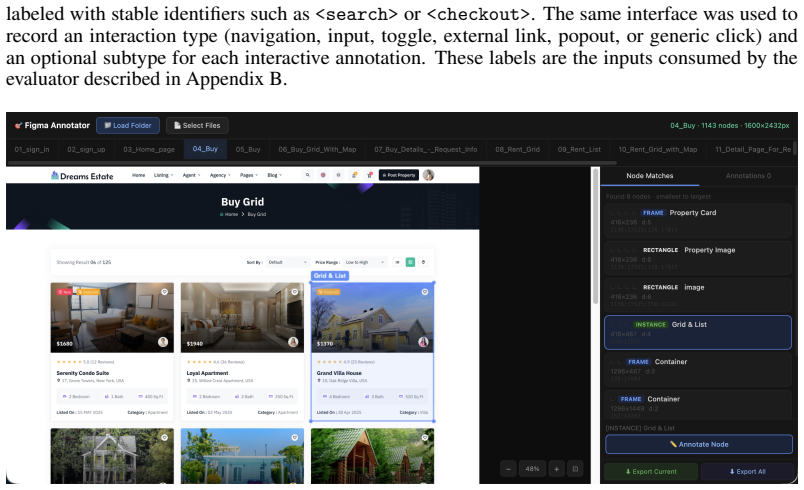
The VISTA benchmark, which annotates each page with interactive UI components and around three visual anchor points to enable combined DOM, browser-test, and CLIP evaluation beyond the limits of script-based tools like Playwright.
Load-bearing premise
Manual annotation of each page with interactive UI components and around three visual anchor points is sufficient to address the limitations of script-based testing tools in open-ended code generation settings.
What would settle it
An experiment that applies an alternative evaluation protocol to the same agent outputs and finds strong correlation between visual fidelity scores and functional correctness scores would undermine the partial-decoupling result.
Figures
read the original abstract
We present VISTA (VIsual Spec-To-App Benchmark), a benchmark for evaluating the end-to-end web-app generation capabilities of LLM-based agents. Unlike prior code generation benchmarks that focus on algorithmic tasks, VISTA targets realistic UI-centric development, where agents must produce functional, visually coherent applications from underspecified inputs. We define five prompt-information conditions that vary along two axes, visual/structural fidelity and stack constraint: (1) text only with free stack choice, (2) text with reference screenshots under three specified stacks, (3) text with reference screenshots under free stack choice, (4) text with screenshots and pruned Figma structure under a single specified stack, and (5) text with screenshots and pruned Figma structure under free stack choice. To enable robust evaluation, each page in the benchmark is manually annotated with interactive UI components and around three visual anchor points, addressing the well-known limitations of script-based testing tools such as Playwright in open-ended code generation settings. Evaluation combines DOM-grounded reference matching, behavior-specific browser tests, and CLIP-based visual similarity, jointly measuring structural alignment, behavioral completeness, and overall visual fidelity. We use VISTA to assess four agent systems drawn from two model families and two harnesses, finding that visual fidelity and functional correctness are partially decoupled across both input conditions and agents, and that agent editing style varies sharply but is largely orthogonal to task quality. VISTA establishes a rigorous and reproducible foundation for advancing agent-based software engineering research. Code is available at https://github.com/kaboider/VISTA_Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
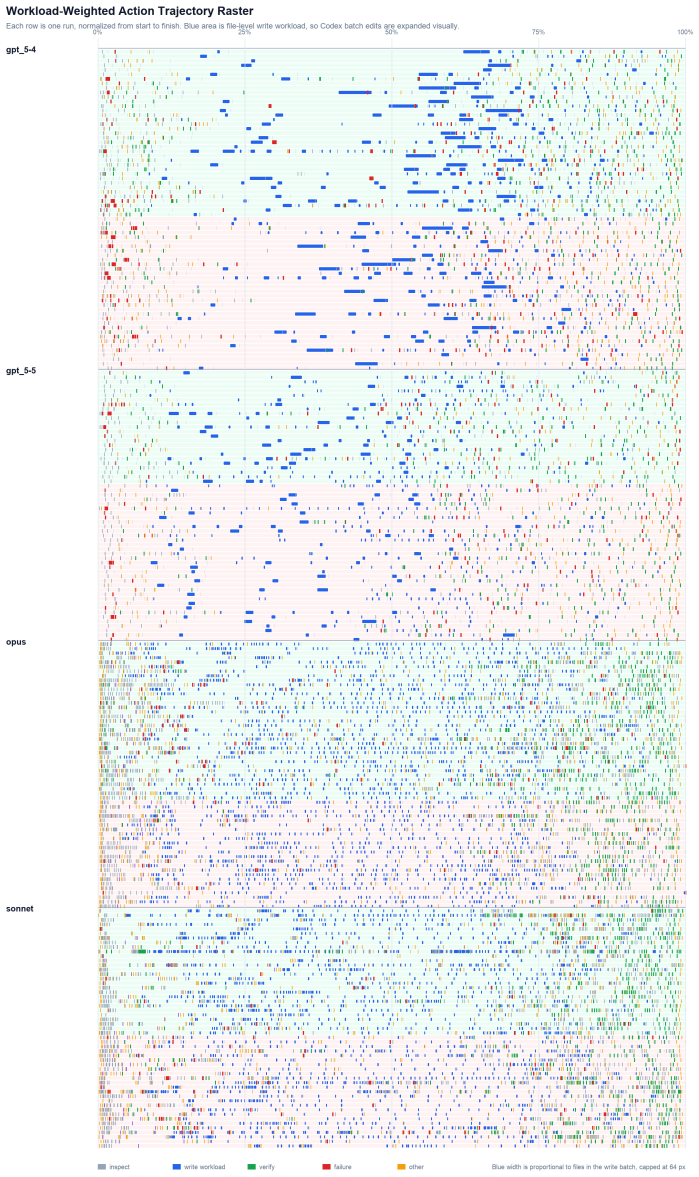
Summary. The manuscript presents VISTA, a benchmark for end-to-end evaluation of LLM-based agents generating functional web apps from underspecified visual/textual specs. It defines five prompt conditions varying along visual/structural fidelity and stack constraint axes, manually annotates each page with interactive UI components and ~3 visual anchor points to support evaluation, and combines DOM-grounded matching, behavior-specific browser tests, and CLIP visual similarity. Experiments on four agents from two model families show that visual fidelity and functional correctness are partially decoupled across conditions and agents, with editing styles varying but largely orthogonal to quality; the work claims to establish a rigorous, reproducible foundation for agent-based SE research, with code released.
Significance. If the evaluation pipeline proves robust, VISTA would offer a useful standardized resource for UI-centric agent research by highlighting metric decoupling and providing reproducible test harnesses. The public code release is a clear strength for reproducibility. However, the significance is tempered by the load-bearing nature of the annotation and testing assumptions for claims of rigor.
major comments (2)
- [Abstract / Evaluation pipeline] Abstract and evaluation description: the assertion that manual annotation of interactive components plus ~3 visual anchor points per page 'addresses the well-known limitations of script-based testing tools such as Playwright in open-ended code generation settings' lacks supporting validation (e.g., inter-annotator agreement, coverage statistics against full interaction graphs, or comparison to exhaustive Playwright scripts). This directly affects the behavioral-completeness metric and the reported partial decoupling between visual fidelity and functional correctness.
- [Abstract] Abstract: the central claim that VISTA 'establishes a rigorous and reproducible foundation' rests on the joint DOM + browser-test + CLIP pipeline, yet no quantitative evidence is provided on how the limited anchor points ensure behavioral completeness for realistic apps containing forms, modals, or dynamic lists. Without such evidence the decoupling result risks being an artifact of incomplete measurement.
minor comments (2)
- The five prompt conditions are clearly motivated but would benefit from an explicit table mapping each condition to its visual/structural and stack dimensions for quick reference.
- Clarify whether the ~3 anchor points are chosen per page or per interactive component, and how they are selected to maximize behavioral coverage.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on the VISTA benchmark. The comments highlight important aspects of validating the evaluation pipeline, and we address each point below with plans for revision.
read point-by-point responses
-
Referee: [Abstract / Evaluation pipeline] Abstract and evaluation description: the assertion that manual annotation of interactive components plus ~3 visual anchor points per page 'addresses the well-known limitations of script-based testing tools such as Playwright in open-ended code generation settings' lacks supporting validation (e.g., inter-annotator agreement, coverage statistics against full interaction graphs, or comparison to exhaustive Playwright scripts). This directly affects the behavioral-completeness metric and the reported partial decoupling between visual fidelity and functional correctness.
Authors: We agree that the manuscript currently lacks explicit quantitative validation (such as inter-annotator agreement or coverage statistics) for the annotation process. The annotations were designed to capture primary interactive components and visual anchors to support behavior-specific browser tests in open-ended generation settings. In the revised manuscript, we will expand the evaluation section to include a description of the annotation protocol, inter-annotator agreement metrics (where multiple annotators were involved), and basic coverage statistics relative to the interaction graphs of the benchmark apps. This will provide stronger grounding for the behavioral-completeness claims. revision: yes
-
Referee: [Abstract] Abstract: the central claim that VISTA 'establishes a rigorous and reproducible foundation' rests on the joint DOM + browser-test + CLIP pipeline, yet no quantitative evidence is provided on how the limited anchor points ensure behavioral completeness for realistic apps containing forms, modals, or dynamic lists. Without such evidence the decoupling result risks being an artifact of incomplete measurement.
Authors: The pipeline relies on DOM-grounded matching for structure, targeted browser tests derived from the annotated interactive components for behavior, and CLIP for visual similarity. The limited anchors (~3 per page) serve primarily as visual references rather than exhaustive behavioral coverage. We acknowledge the absence of quantitative evidence on completeness for complex elements like forms or modals. In revision, we will add an analysis subsection discussing test coverage across app types (including forms, modals, and lists) and explicitly note the scope and limitations of the anchor-based approach to avoid overclaiming rigor. revision: yes
Circularity Check
No circularity; benchmark is self-contained with no derivations or self-defined quantities
full rationale
The paper is a benchmark presentation with no equations, fitted parameters, or mathematical derivations. Central claims rest on standard evaluation components (DOM matching, browser tests, CLIP similarity) and manual annotation described as addressing external tool limitations, without any reduction of outputs to inputs by construction or load-bearing self-citations. The work provides an external code link and is independent of its own results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Ac- cessed: 2026-05-07. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Accessed: 2026-05-07. Google. Gemini CLI. https://google-gemini.github.io/gemini-cli/,
2026
-
[4]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Accessed: 2026-05-07. Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. CodeSearchNet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues?arXiv preprint arXiv:2310.06770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
The stack: 3 TB of permissively licensed source code.arXiv preprint arXiv:2211.15533,
9 Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, and Harm de Vries. The stack: 3 TB of permissively licensed source code.arXiv preprint arXiv:2211.15533,
-
[7]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks.arXiv preprint arXiv:2401.13649,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Accessed: 2026-05-07. OpenAI. Codex: Ai coding partner from OpenAI. https://openai.com/codex/,
2026
-
[9]
Accessed: 2026-05-07. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages ...
2026
-
[10]
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2Code: Benchmarking multimodal code generation for automated front-end engineering.arXiv preprint arXiv:2403.03163,
-
[11]
Large Language Models are not Fair Evaluators
Accessed: 2026-05-07. Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators.arXiv preprint arXiv:2305.17926,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenHands: An open platform for AI soft...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.