Personalized Generative Models for Contextual Debiasing
Pith reviewed 2026-06-29 22:09 UTC · model grok-4.3
The pith
Personalized text-to-image models generate rare-context images to debias vision training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DecoupleGen personalizes text-to-image diffusion models to enable coherent synthesis of images with rare contexts while preserving original visual details; the generated images stay semantically meaningful, remain visually aligned with source datasets, and, when added under verification constraints, produce consistent improvements on object classification and recognition tasks.
What carries the argument
DecoupleGen, a personalization procedure on text-to-image diffusion models that decouples contextual patterns to produce rare-context images while keeping original visual details intact.
Load-bearing premise
The generated images must remain semantically meaningful, visually aligned with the original dataset, and free of new biases that could harm performance.
What would settle it
Train a classifier on the original dataset plus the generated augmentations and measure accuracy on held-out rare-context examples; if accuracy does not rise relative to the unaugmented baseline or prior augmentation methods, the claim is falsified.
Figures

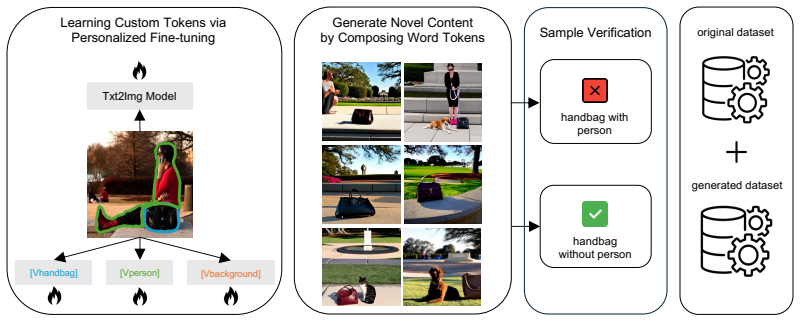








read the original abstract
Different visual patterns appear with different frequencies in the world: e.g., beach balls appear on sand more often than they do on a road. These statistics are reflected in vision datasets, and as a result trained models more easily recognize objects in common scenarios. However, recognizing a beach ball on a road may arguably be even more important than recognizing it on sand. We study how to mitigate this discrepancy. Since collecting uncommon images in the real world may be difficult, we explore whether generating images with less frequent contexts can serve as effective training augmentation. A key challenge is guiding generations to remain close to the original dataset distribution while creating diverse images with uncommon contexts. We introduce Decoupling Contextual Patterns with Generations (DecoupleGen), a method that personalizes text-to-image diffusion models to facilitate coherent synthesis of images with rare contexts while preserving original visual details. The generated images contain semantically meaningful content and remain visually aligned with the original datasets. We further apply verification constraints to ensure relevance of the augmented data. We evaluate our approach on object classification and recognition tasks on complex scene datasets. Our experiments demonstrate consistent improvements over previous approaches, and our analyses identify factors underlying these improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DecoupleGen, a method to personalize text-to-image diffusion models for synthesizing images with rare contexts while preserving visual details from the original dataset. It applies verification constraints to ensure relevance of the augmentations and evaluates the approach on object classification and recognition tasks, claiming consistent improvements over prior methods along with analyses identifying contributing factors.
Significance. If the central claims hold with rigorous evidence, the work could offer a scalable alternative to real-world data collection for contextual debiasing in vision models. The emphasis on keeping generations distributionally close to the source data addresses a key practical challenge in generative augmentation.
major comments (2)
- [Abstract] The abstract asserts that verification constraints ensure relevance and that generated images 'remain visually aligned' without introducing new biases, yet provides no implementation details, ablation on constraint strength, or quantitative metrics (e.g., bias amplification scores, OOD failure rates) demonstrating that the augmentation does not silently degrade performance on common contexts.
- The central claim of consistent improvements requires evidence that the generated rare-context images remain distributionally safe; the weakest assumption (semantic meaningfulness and absence of new biases) is stated but not supported by the quantitative details, error bars, or ablation evidence referenced in the reader's assessment of the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in the abstract and stronger quantitative support for the safety of generated augmentations. We will perform a major revision to incorporate the requested details, metrics, and ablations while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that verification constraints ensure relevance and that generated images 'remain visually aligned' without introducing new biases, yet provides no implementation details, ablation on constraint strength, or quantitative metrics (e.g., bias amplification scores, OOD failure rates) demonstrating that the augmentation does not silently degrade performance on common contexts.
Authors: We agree the abstract is high-level and omits these specifics. The full manuscript details the verification constraints and their implementation in Section 3, along with ablations on constraint strength in Section 5.2. To directly address the concern, we will revise the abstract to reference key quantitative results (including bias amplification scores and performance retention on common contexts) and add a dedicated table or paragraph summarizing OOD failure rates and error bars from the experiments. revision: yes
-
Referee: The central claim of consistent improvements requires evidence that the generated rare-context images remain distributionally safe; the weakest assumption (semantic meaningfulness and absence of new biases) is stated but not supported by the quantitative details, error bars, or ablation evidence referenced in the reader's assessment of the abstract.
Authors: The manuscript reports consistent improvements with supporting analyses in Sections 4 and 5. However, we acknowledge that explicit distributional safety metrics (e.g., feature distribution comparisons or bias amplification) and error bars are not sufficiently highlighted. We will add these quantitative elements, including ablations demonstrating no degradation on common contexts, to strengthen the central claim. revision: yes
Circularity Check
No derivation chain or equations present; empirical method evaluation
full rationale
The paper introduces DecoupleGen as a personalization technique for text-to-image diffusion models to generate rare-context images, followed by verification constraints and experimental evaluation on object classification tasks. No equations, derivations, parameter fittings, or mathematical claims are presented in the abstract or described structure. Claims of improvement rest on reported experiments rather than any reduction to inputs by construction, self-citation load-bearing premises, or ansatz smuggling. This is a standard empirical methods paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Paint by word.arXiv preprint arXiv:2103.10951, 2021
Alex Andonian, Sabrina Osmany, Audrey Cui, YeonHwan Park, Ali Jahanian, Antonio Torralba, and David Bau. Paint by word.arXiv preprint arXiv:2103.10951, 2021. 2
-
[2]
Martin Arjovsky, L ´eon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization.arXiv preprint arXiv:1907.02893, 2019. 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[3]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18208–18218, 2022. 2, 6
2022
-
[4]
Break-a-scene: Extracting multi- ple concepts from a single image
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen- Or, and Dani Lischinski. Break-a-scene: Extracting multi- ple concepts from a single image. InSIGGRAPH Asia 2023 Conference Papers, pages 1–12, 2023. 3, 1
2023
-
[5]
Blended latent diffusion.ACM Transactions on Graphics (TOG), 42 (4):1–11, 2023
Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion.ACM Transactions on Graphics (TOG), 42 (4):1–11, 2023. 5, 7, 3
2023
-
[6]
Shekoofeh Azizi, Simon Kornblith, Chitwan Saharia, Mo- hammad Norouzi, and David J Fleet. Synthetic data from diffusion models improves imagenet classification.arXiv preprint arXiv:2304.08466, 2023. 1, 2
-
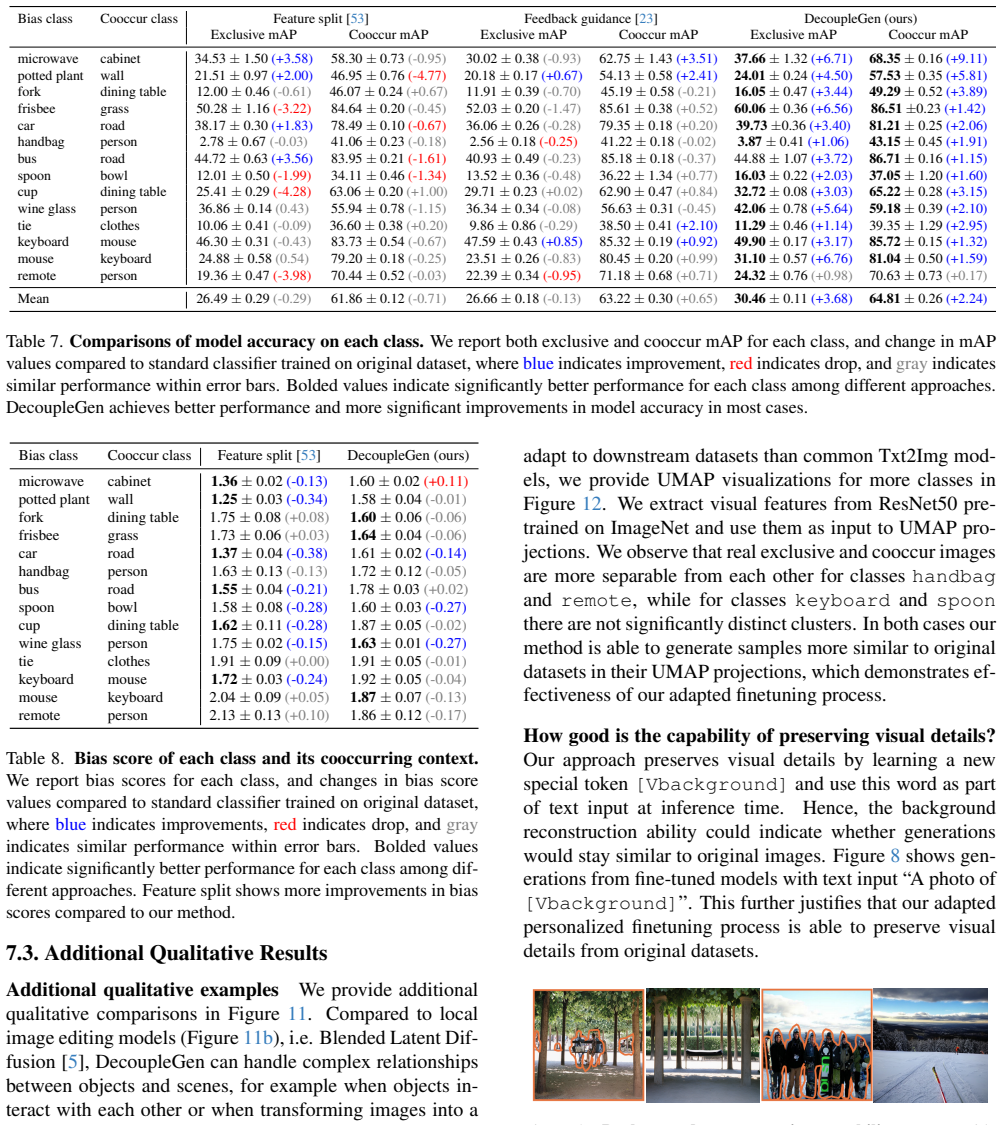
[7]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Dis- criminative learning under covariate shift.Journal of Ma- chine Learning Research, 10(9), 2009
Steffen Bickel, Michael Br ¨uckner, and Tobias Scheffer. Dis- criminative learning under covariate shift.Journal of Ma- chine Learning Research, 10(9), 2009. 1, 2
2009
-
[9]
Large image datasets: A pyrrhic win for computer vision? In2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1536–1546
Abeba Birhane and Vinay Uday Prabhu. Large image datasets: A pyrrhic win for computer vision? In2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1536–1546. IEEE, 2021. 1, 2
2021
-
[10]
Gender shades: Inter- sectional accuracy disparities in commercial gender classifi- cation
Joy Buolamwini and Timnit Gebru. Gender shades: Inter- sectional accuracy disparities in commercial gender classifi- cation. InConference on fairness, accountability and trans- parency, pages 77–91. PMLR, 2018. 1
2018
-
[11]
Coco- stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco- stuff: Thing and stuff classes in context. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1209–1218, 2018. 2, 5
2018
-
[12]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 1
2020
-
[13]
Context models and out-of-context objects.Pattern Recog- nition Letters, 33(7):853–862, 2012
Myung Jin Choi, Antonio Torralba, and Alan S Willsky. Context models and out-of-context objects.Pattern Recog- nition Letters, 33(7):853–862, 2012. 2
2012
-
[14]
Class-balanced loss based on effective number of samples
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9268–9277,
-
[15]
Diversify your vision datasets with automatic diffusion-based augmentation.Ad- vances in Neural Information Processing Systems, 36, 2024
Lisa Dunlap, Alyssa Umino, Han Zhang, Jiezhi Yang, Joseph E Gonzalez, and Trevor Darrell. Diversify your vision datasets with automatic diffusion-based augmentation.Ad- vances in Neural Information Processing Systems, 36, 2024. 1, 2
2024
-
[16]
Scaling laws of syn- thetic images for model training
Lijie Fan, Kaifeng Chen, Dilip Krishnan, Dina Katabi, Phillip Isola, and Yonglong Tian. Scaling laws of syn- thetic images for model training... for now.arXiv preprint arXiv:2312.04567, 2023. 2
-
[17]
Cost-sensitive learning.Learning from imbalanced data sets, pages 63–78, 2018
Alberto Fern ´andez, Salvador Garc ´ıa, Mikel Galar, Ronaldo C Prati, Bartosz Krawczyk, Francisco Her- rera, Alberto Fern ´andez, Salvador Garc ´ıa, Mikel Galar, Ronaldo C Prati, et al. Cost-sensitive learning.Learning from imbalanced data sets, pages 63–78, 2018. 1, 2
2018
-
[18]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014. 2
2014
-
[20]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4
2016
-
[21]
Ruifei He, Shuyang Sun, Xin Yu, Chuhui Xue, Wenqing Zhang, Philip Torr, Song Bai, and Xiaojuan Qi. Is synthetic data from generative models ready for image recognition? arXiv preprint arXiv:2210.07574, 2022. 1, 2
-
[22]
Towards non-iid image classification: A dataset and baselines.Pattern Recognition, 110:107383, 2021
Yue He, Zheyan Shen, and Peng Cui. Towards non-iid image classification: A dataset and baselines.Pattern Recognition, 110:107383, 2021. 2, 4
2021
-
[23]
Feedback-guided data synthesis for imbalanced classifica- tion.arXiv preprint arXiv:2310.00158, 2023
Reyhane Askari Hemmat, Mohammad Pezeshki, Florian Bordes, Michal Drozdzal, and Adriana Romero-Soriano. Feedback-guided data synthesis for imbalanced classifica- tion.arXiv preprint arXiv:2310.00158, 2023. 1, 2, 4, 5, 6, 7, 3
-
[24]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1, 2
2020
-
[26]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021. 1 9
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Ali Jahanian, Xavier Puig, Yonglong Tian, and Phillip Isola. Generative models as a data source for multiview represen- tation learning.arXiv preprint arXiv:2106.05258, 2021. 2
-
[28]
Oneformer: One transformer to rule universal image segmentation
Jitesh Jain, Jiachen Li, Mang Tik Chiu, Ali Hassani, Nikita Orlov, and Humphrey Shi. Oneformer: One transformer to rule universal image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2989–2998, 2023. 4
2023
-
[29]
Identifying and correct- ing label bias in machine learning
Heinrich Jiang and Ofir Nachum. Identifying and correct- ing label bias in machine learning. InInternational confer- ence on artificial intelligence and statistics, pages 702–712. PMLR, 2020. 2
2020
-
[30]
Decoupling representation and classifier for long -tailed recognition,
Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decou- pling representation and classifier for long-tailed recogni- tion.arXiv preprint arXiv:1910.09217, 2019. 4, 5, 1
-
[31]
Undoing the dam- age of dataset bias
Aditya Khosla, Tinghui Zhou, Tomasz Malisiewicz, Alexei A Efros, and Antonio Torralba. Undoing the dam- age of dataset bias. InComputer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part I 12, pages 158–171. Springer, 2012. 2
2012
-
[32]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1931–1941, 2023. 2, 3
1931
-
[33]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 5
2023
-
[34]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language pro- cessing, pages 292–305, 2023. 2
2023
-
[35]
Zhaoyang Li, Zhan Ling, Yuchen Zhou, Litian Gong, Erdem Bıyık, and Hao Su. Oric: Benchmarking object recognition under contextual incongruity in large vision-language mod- els.arXiv preprint arXiv:2509.15695, 2025. 2
-
[36]
Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3292–3310, 2022
Yiyi Liao, Jun Xie, and Andreas Geiger. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3292–3310, 2022. 1
2022
-
[37]
Palm up: Playing in the latent manifold for unsupervised pre- training.Advances in Neural Information Processing Sys- tems, 35:35880–35893, 2022
Hao Liu, Tom Zahavy, V olodymyr Mnih, and Satinder Singh. Palm up: Playing in the latent manifold for unsupervised pre- training.Advances in Neural Information Processing Sys- tems, 35:35880–35893, 2022. 2
2022
-
[38]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022. 2
2022
-
[39]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimen- sion reduction.arXiv preprint arXiv:1802.03426, 2018. 6
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
The role of context for object detection and semantic segmentation in the wild
Roozbeh Mottaghi, Xianjie Chen, Xiaobai Liu, Nam-Gyu Cho, Seong-Whan Lee, Sanja Fidler, Raquel Urtasun, and Alan Yuille. The role of context for object detection and semantic segmentation in the wild. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014. 1, 2
2014
-
[41]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741, 2021. 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[42]
Context encoders: Feature learning by inpainting
Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2536–2544, 2016. 2
2016
-
[43]
Lance: Stress-testing visual models by generating language-guided counterfactual images.Ad- vances in Neural Information Processing Systems, 36, 2024
Viraj Prabhu, Sriram Yenamandra, Prithvijit Chattopadhyay, and Judy Hoffman. Lance: Stress-testing visual models by generating language-guided counterfactual images.Ad- vances in Neural Information Processing Systems, 36, 2024. 2
2024
-
[44]
Fair attribute classification through latent space de-biasing
Vikram V Ramaswamy, Sunnie SY Kim, and Olga Rus- sakovsky. Fair attribute classification through latent space de-biasing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9301–9310,
-
[45]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational confer- ence on machine learning, pages 8821–8831. Pmlr, 2021. 1
2021
-
[46]
Balanced meta-softmax for long-tailed visual recog- nition.Advances in neural information processing systems, 33:4175–4186, 2020
Jiawei Ren, Cunjun Yu, Xiao Ma, Haiyu Zhao, Shuai Yi, et al. Balanced meta-softmax for long-tailed visual recog- nition.Advances in neural information processing systems, 33:4175–4186, 2020. 4, 5, 1
2020
-
[47]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 2, 4, 5, 6
2022
-
[48]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22500– 22510, 2023. 2, 3
2023
-
[49]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015. 4
2015
-
[50]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst- case generalization.arXiv preprint arXiv:1911.08731, 2019. 4, 5, 1
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[51]
Shreya Shankar, Yoni Halpern, Eric Breck, James Atwood, Jimbo Wilson, and D Sculley. No classification without rep- resentation: Assessing geodiversity issues in open data sets 10 for the developing world.arXiv preprint arXiv:1711.08536,
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Don’t judge an object by its context: Learning to overcome con- textual bias
Krishna Kumar Singh, Dhruv Mahajan, Kristen Grauman, Yong Jae Lee, Matt Feiszli, and Deepti Ghadiyaram. Don’t judge an object by its context: Learning to overcome con- textual bias. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11070– 11078, 2020. 1, 2, 5, 6, 7, 3
2020
-
[54]
Learning vision from models rivals learning vision from data.arXiv preprint arXiv:2312.17742, 2023
Yonglong Tian, Lijie Fan, Kaifeng Chen, Dina Katabi, Dilip Krishnan, and Phillip Isola. Learning vision from models rivals learning vision from data.arXiv preprint arXiv:2312.17742, 2023. 2
-
[55]
Stablerep: Synthetic images from text-to- image models make strong visual representation learners
Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang, and Dilip Krishnan. Stablerep: Synthetic images from text-to- image models make strong visual representation learners. Advances in Neural Information Processing Systems, 36,
-
[56]
A deeper look at dataset bias.Domain adaptation in computer vision applications, pages 37–55, 2017
Tatiana Tommasi, Novi Patricia, Barbara Caputo, and Tinne Tuytelaars. A deeper look at dataset bias.Domain adaptation in computer vision applications, pages 37–55, 2017. 2
2017
-
[57]
Effective data augmentation with diffusion models.arXiv preprint arXiv:2302.07944, 2023
Brandon Trabucco, Kyle Doherty, Max Gurinas, and Ruslan Salakhutdinov. Effective data augmentation with diffusion models.arXiv preprint arXiv:2302.07944, 2023. 2
-
[58]
Stereotyping and Bias in the Flickr30K Dataset
Emiel Van Miltenburg. Stereotyping and bias in the flickr30k dataset.arXiv preprint arXiv:1605.06083, 2016. 1
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[59]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chau- mond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R´emi Louf, Morgan Funtowicz, et al. Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771, 2019. 1
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[60]
Change is hard: A closer look at subpopulation shift.arXiv preprint arXiv:2302.12254, 2023
Yuzhe Yang, Haoran Zhang, Dina Katabi, and Marzyeh Ghassemi. Change is hard: A closer look at subpopulation shift.arXiv preprint arXiv:2302.12254, 2023. 4, 1
-
[61]
Improving out-of-distribution robustness via selective augmentation
Huaxiu Yao, Yu Wang, Sai Li, Linjun Zhang, Weixin Liang, James Zou, and Chelsea Finn. Improving out-of-distribution robustness via selective augmentation. InInternational Con- ference on Machine Learning, pages 25407–25437. PMLR,
-
[62]
Chenshuang Zhang, Fei Pan, Junmo Kim, In So Kweon, and Chengzhi Mao. Imagenet-d: Benchmarking neural net- work robustness on diffusion synthetic object.arXiv preprint arXiv:2403.18775, 2024. 2
-
[63]
mixup: Beyond Empirical Risk Minimization
Hongyi Zhang. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017. 4, 5, 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[64]
Under- standing and evaluating racial biases in image captioning
Dora Zhao, Angelina Wang, and Olga Russakovsky. Under- standing and evaluating racial biases in image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14830–14840, 2021. 1
2021
-
[65]
Learning deep features for discrimi- native localization
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discrimi- native localization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 5, 1 11 Personalized Generative Models for Contextual Debiasing Supplementary Material
2016
-
[66]
Experimental Details 6.1. Descriptions of Previous Approaches We provide more detailed descriptions of existing ap- proaches that we compared against for each downstream task below: Image ClassificationWe compare DecoupleGen to a set of approaches mentioned in [23, 60].GroupDRO[50] min- imizes the worst-case group loss by reweighting training ex- amples b...
-
[67]
Additional Experimental Results 7.1. Image classification Decompose group-wise model accuracy on NICO dataset.In NICO dataset, in addition to overall accuracy and worst group accuracy, we take a closer look at classifier accuracies on object-context combinations, after removing groups that contain few data points in validation split (less than 25 samples ...
-
[68]
A photo of [Vbackground]
based on Txt2Img models, which only improves 2 out of 14 classes in exclusive mAP and 4 classes in cooccur mAP. As discussed in the main paper, such discrepancy is possibly due to that Txt2Img models fail to generate sam- ples that maintain similar to original datasets compared to our approach, therefore providing limited information help- ful to downstre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.