How and What to Imagine? Visual Thinking in Unified Multimodal Models for Cross-View Spatial Reasoning
Pith reviewed 2026-06-29 18:16 UTC · model grok-4.3
The pith
Panoramic thinking images combined with View Dropout let unified multimodal models rely on generated visuals for cross-view spatial reasoning instead of language alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
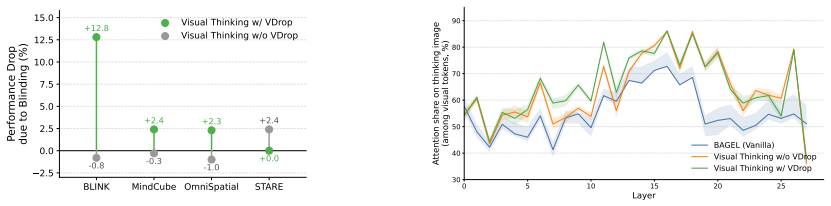
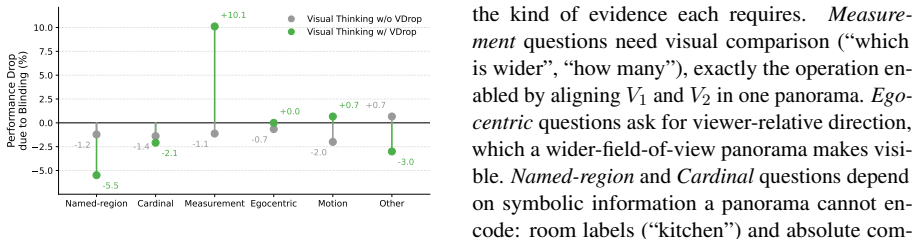
Panoramic visual thinking with VDrop is the only configuration that is both informative and learnable, and it achieves the best out-of-domain generalization.
What carries the argument
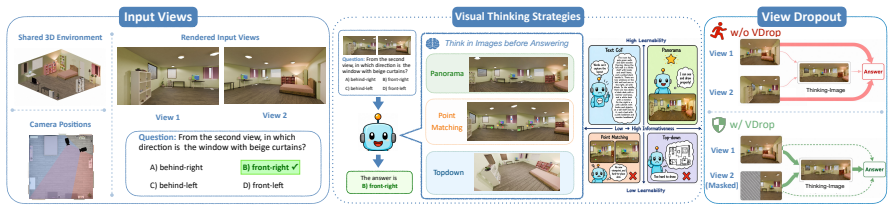
View Dropout (VDrop), a training-time intervention that hides parts of one input view from the answer span while keeping them visible to the thinking-image tokens.
If this is right
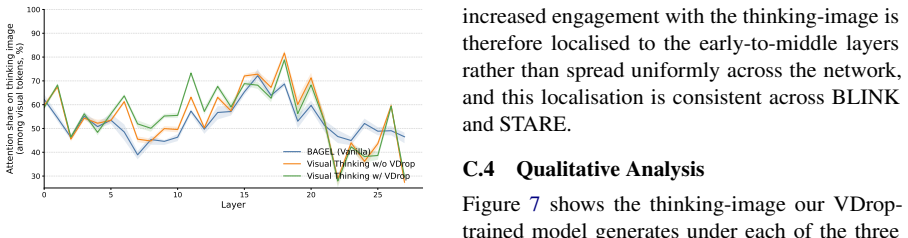
- Training with VDrop prevents models from defaulting to language-only reasoning and forces use of the generated thinking image.
- Panoramic renderings supply the right amount of geometric context without exceeding what the model can reliably produce during generation.
- Top-down and point-matching renderings are either insufficiently informative or too difficult to generate accurately from the input views.
- Synthetic scene training transfers to real-world tasks once the thinking-image type satisfies both learnability and informativeness.
- The same training intervention and rendering comparison can be applied to other spatial reasoning benchmarks that require fine-grained geometry.
Where Pith is reading between the lines
- The learnability-informativeness tradeoff may generalize to other intermediate visual representations beyond spatial reasoning.
- Models might benefit from dynamically selecting the thinking-image style based on scene complexity rather than fixing one type.
- Extending VDrop to hide varying fractions of the input view could reveal the minimal amount of masking needed to enforce visual reliance.
- The approach suggests that future unified models could interleave multiple thinking images of different styles within a single reasoning trace.
Load-bearing premise
Forcing attention to the thinking image via View Dropout on synthetic data will produce genuine reliance on its visual evidence rather than new spurious correlations, and the synthetic-to-real gap will not invalidate the observed learnability-informativeness tradeoff.
What would settle it
A controlled attention-map comparison on held-out real scenes showing that the model still attends primarily to the original input views rather than the generated thinking image even after VDrop training, or a result where point-matching or top-down renderings outperform panoramic ones on the real benchmarks.
Figures


read the original abstract
Cross-view spatial reasoning remains a weak spot for vision-language models (VLMs): they often reason in language and lose the fine-grained geometry needed for the task. Thinking with images aims to address this by generating an intermediate thinking image, but recent work shows that models often ignore the visual evidence in these traces. We therefore ask how to make visual thinking matter, and what kind of visual thinking works best. We study these questions in unified multimodal models (UMMs), which natively support interleaved image-text generation. For the first question, we propose View Dropout (VDrop), a training-time intervention that hides parts of one input view from the answer span while keeping them visible to the thinking-image tokens. This encourages the model to use the thinking image when answering, instead of relying only on the input views. Once the thinking image is used for answer prediction, we study which type of visual thinking is most effective. We frame this as a learnability-informativeness tradeoff and compare three thinking-image variants: top-down, panoramic, and point-matching renderings. Trained on synthetic scenes and evaluated on five real-world out-of-domain benchmarks, panoramic visual thinking with VDrop is the only configuration that is both informative and learnable, and it achieves the best out-of-domain generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that cross-view spatial reasoning in unified multimodal models (UMMs) can be improved by generating intermediate thinking images, but models often ignore the visual content. It introduces View Dropout (VDrop), a training intervention that hides input-view regions from the answer span while keeping them visible to thinking-image tokens, to encourage reliance on the generated image. It then compares three thinking-image variants (top-down, panoramic, point-matching) under a learnability-informativeness tradeoff, trained on synthetic scenes and evaluated on five real-world out-of-domain benchmarks. The central result is that only panoramic visual thinking combined with VDrop is both informative and learnable, yielding the best OOD generalization.
Significance. If the central result holds, the work supplies a practical training mechanism (VDrop) and an evaluation framework for making visual thinking effective rather than decorative in VLMs. The synthetic-to-real OOD setup and explicit tradeoff analysis are strengths that could guide future work on intermediate visual representations for spatial tasks. The finding that only one configuration succeeds provides a falsifiable prediction for follow-up studies.
major comments (2)
- [Method section on View Dropout] Method section on View Dropout: the mechanism hides input regions only from the answer span while leaving them visible to thinking-image tokens. No ablation is described that tests whether performance drops when the thinking image is removed at inference (or when its content is corrupted), which is required to establish that the model is actually extracting geometric evidence rather than learning new token-answer shortcuts. This is load-bearing for the claim that VDrop produces genuine visual reliance and for the learnability-informativeness tradeoff.
- [Results section reporting OOD benchmark performance] Results section reporting OOD benchmark performance: the claim that panoramic+VDrop is the only informative+learnable configuration and achieves best generalization rests on the assumption that the synthetic-to-real gap does not introduce domain-specific shortcuts. No analysis (e.g., feature attribution or controlled corruption of the thinking image on real benchmarks) is provided to rule out that the observed gains survive distribution shift for reasons other than visual reasoning.
minor comments (2)
- [Introduction and Method] The definitions of 'informative' and 'learnable' are introduced in the abstract and method but would benefit from explicit operationalization (e.g., quantitative thresholds or equations) early in the paper for reproducibility.
- [Figures] Figure captions for the thinking-image variants could include example renderings side-by-side with input views to make the differences between top-down, panoramic, and point-matching immediately clear.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments below and will incorporate additional experiments to strengthen the evidence for visual reliance and OOD generalization.
read point-by-point responses
-
Referee: [Method section on View Dropout] Method section on View Dropout: the mechanism hides input regions only from the answer span while leaving them visible to thinking-image tokens. No ablation is described that tests whether performance drops when the thinking image is removed at inference (or when its content is corrupted), which is required to establish that the model is actually extracting geometric evidence rather than learning new token-answer shortcuts. This is load-bearing for the claim that VDrop produces genuine visual reliance and for the learnability-informativeness tradeoff.
Authors: We agree that an inference-time ablation removing or corrupting the thinking image is needed to directly confirm reliance on its geometric content rather than token shortcuts. Although VDrop is explicitly designed to make thinking-image tokens the only source for hidden regions during training, the manuscript does not report such controls at inference. We will add these ablations (both removal and corruption) for all three thinking-image variants on both synthetic and real benchmarks in the revision. revision: yes
-
Referee: [Results section reporting OOD benchmark performance] Results section reporting OOD benchmark performance: the claim that panoramic+VDrop is the only informative+learnable configuration and achieves best generalization rests on the assumption that the synthetic-to-real gap does not introduce domain-specific shortcuts. No analysis (e.g., feature attribution or controlled corruption of the thinking image on real benchmarks) is provided to rule out that the observed gains survive distribution shift for reasons other than visual reasoning.
Authors: The five real-world OOD benchmarks already demonstrate consistent gains for panoramic+VDrop, which we interpret as evidence against purely synthetic shortcuts. We nevertheless acknowledge that explicit controls such as feature attribution or thinking-image corruption on the real benchmarks would further isolate visual reasoning as the source of improvement. We will add these analyses in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical comparison of training interventions on held-out benchmarks
full rationale
The paper introduces View Dropout as a training-time masking intervention and evaluates three thinking-image variants (top-down, panoramic, point-matching) by training unified multimodal models on synthetic scenes then measuring performance on five real-world out-of-domain benchmarks. The central claim—that panoramic+VDrop is the only informative+learnable configuration with best generalization—is presented as an observed experimental outcome rather than a quantity derived by definition or by fitting a parameter to the target metric. No equations, self-citations, or ansatzes are invoked that reduce the reported result to its own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, and 45 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, Tongxi Zhou, Jiaqi Li, Hui En Pang, Oscar Qian, Yukun Wei, Zhiqian Lin, Xuanke Shi, Kewang Deng, Xiaoyang Han, and 10 others. 2026. Scaling spatial intelligence with multimodal foundation models. In Proceedings of the IEEE/CVF Conferenc...
2026
-
[3]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455--14465
2024
-
[4]
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. 2025 a . Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Zihui Cheng, Qiguang Chen, Xiao Xu, Jiaqi Wang, Weiyun Wang, Hao Fei, Yidong Wang, Alex Jinpeng Wang, Zhi Chen, Wanxiang Che, and 1 others. 2026. Visual thoughts: A unified perspective of understanding multimodal chain-of-thought. Advances in Neural Information Processing Systems, 38:96084--96112
2026
-
[7]
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. 2025. Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Haiwen Diao, Penghao Wu, Hanming Deng, Jiahao Wang, Shihao Bai, Silei Wu, Weichen Fan, Wenjie Ye, Wenwen Tong, Xiangyu Fan, and 1 others. 2026. Sensenova-u1: Unifying multimodal understanding and generation with neo-unify architecture. arXiv preprint arXiv:2605.12500
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. 2024. Blink: Multimodal large language models can see but not perceive. In European Conference on Computer Vision, pages 148--166. Springer
2024
-
[10]
Simon Garrod and Anthony Anderson. 1987. Saying what you mean in dialogue: A study in conceptual and semantic co-ordination. Cognition, 27(2):181--218
1987
-
[11]
Jiawei Gu, Yunzhuo Hao, Huichen Will Wang, Linjie Li, Michael Qizhe Shieh, Yejin Choi, Ranjay Krishna, and Yu Cheng. 2026. https://openreview.net/forum?id=mB3vxfrQZM Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning . In The Fourteenth International Conference on Learning Representations
2026
-
[12]
Leekyeung Han, Hyunji Min, Gyeom Hwangbo, Jonghyun Choi, and Paul Hongsuck Seo. 2025. Dialnav: Multi-turn dialog navigation with a remote guide. In IEEE/CVF International Conference on Computer Vision, ICCV 2025, Honolulu, HI, USA, October 19-25, 2025 , pages 8514--8523. IEEE
2025
-
[13]
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. 2024. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. Advances in Neural Information Processing Systems, 37:139348--139379
2024
-
[14]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, XinQiang Yu, Jiawei He, He Wang, and Li Yi. 2026. https://openreview.net/forum?id=6nZKT2rL0H Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models . In The Fourteenth International Conference on Learning Representations
2026
-
[15]
Stephen C Levinson. 2003. Space in language and cognition: Explorations in cognitive diversity, volume 5. Cambridge University Press
2003
-
[16]
Ang Li, Charles Wang, Deqing Fu, Kaiyu Yue, Zikui Cai, Wang Bill Zhu, Ollie Liu, Peng Guo, Willie Neiswanger, Furong Huang, Tom Goldstein, and Micah Goldblum. 2026 a . https://openreview.net/forum?id=c6XIVI3TiQ Zebra-cot: A dataset for interleaved vision-language reasoning . In The Fourteenth International Conference on Learning Representations
2026
-
[17]
Linjie Li, Mahtab Bigverdi, Jiawei Gu, Zixian Ma, Yinuo Yang, Ziang Li, Yejin Choi, and Ranjay Krishna. 2026 b . https://openreview.net/forum?id=fbGmSV6tUw Unfolding spatial cognition: Evaluating multimodal models on visual simulations . In The Fourteenth International Conference on Learning Representations
2026
-
[18]
Zhiheng Liu, Weiming Ren, Xiaoke Huang, Shoufa Chen, Tianhong Li, Mengzhao Chen, Yatai Ji, Sen He, Jonas Schult, Tao Xiang, Wenhu Chen, Ping Luo, Luke Zettlemoyer, and Yuren Cong. 2026. Tuna-2: Pixel embeddings beat vision encoders for unified understanding and generation. arXiv preprint arXiv:2604.24763
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Zhiheng Liu, Weiming Ren, Haozhe Liu, Zijian Zhou, Shoufa Chen, Haonan Qiu, Xiaoke Huang, Zhaochong An, Fanny Yang, Aditya Patel, Viktar Atliha, Tony Ng, Xiao Han, Chuyan Zhu, Chenyang Zhang, Ding Liu, Juan-Manuel Perez-Rua, Sen He, Jürgen Schmidhuber, and 6 others. 2025 a . https://arxiv.org/abs/2512.02014 Tuna: Taming unified visual representations for ...
- [20]
-
[21]
Alexander Raistrick, Lingjie Mei, Karhan Kayan, David Yan, Yiming Zuo, Beining Han, Hongyu Wen, Meenal Parakh, Stamatis Alexandropoulos, Lahav Lipson, Zeyu Ma, and Jia Deng. 2024. Infinigen indoors: Photorealistic indoor scenes using procedural generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21783--21794
2024
- [22]
-
[23]
Anh Thai, Songyou Peng, Kyle Genova, Leonidas Guibas, and Thomas Funkhouser. 2025. Splattalk: 3d vqa with gaussian splatting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4712--4721
2025
-
[24]
Barbara Tversky. 2003. Structures of mental spaces: How people think about space. Environment and behavior, 35(1):66--80
2003
-
[25]
Qineng Wang, Baiqiao Yin, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, Saining Xie, Jiajun Wu, Li Fei-Fei, and Manling Li. 2026. https://openreview.net/forum?id=0FhrtdKLtD Mindcube: Spatial mental modeling from limited views . In The Fourteenth International Conference on Learning...
2026
-
[26]
Yipu Wang, Yuheng Ji, Yuyang Liu, Enshen Zhou, Ziqiang Yang, Yuxuan Tian, Ziheng Qin, Yue Liu, Huajie Tan, Cheng Chi, Zhiyuan Ma, Daniel Dajun Zeng, and Xiaolong Zheng. 2025. https://arxiv.org/abs/2512.04686 Towards cross-view point correspondence in vision-language models . Preprint, arXiv:2512.04686
-
[27]
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, and 1 others. 2025. Janus: Decoupling visual encoding for unified multimodal understanding and generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 12966--12977
2025
-
[28]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. 2026. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. Advances in neural information processing systems, 38:13569--13597
2026
-
[29]
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. 2025. Show-o: One single transformer to unify multimodal understanding and generation. In International Conference on Learning Representations, volume 2025, pages 28240--28264
2025
-
[30]
Yi Xu, Chengzu Li, Han Zhou, Xingchen Wan, Caiqi Zhang, Anna Korhonen, and Ivan Vuli \'c . 2026. https://openreview.net/forum?id=wsnse46kRO Visual planning: Let's think only with images . In The Fourteenth International Conference on Learning Representations
2026
-
[31]
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, Dahua Lin, Tai Wang, and Jiangmiao Pang. 2026 a . https://openreview.net/forum?id=gHRoX4vXm3 MMSI -bench: A benchmark for multi-image spatial intelligence . In The Fourteenth International Conference on Learning Representations
2026
-
[32]
Yuncong Yang, Jiageng Liu, Zheyuan Zhang, Siyuan Zhou, Reuben Tan, Jianwei Yang, Yilun Du, and Chuang Gan. 2026 b . Mindjourney: Test-time scaling with world models for spatial reasoning. Advances in Neural Information Processing Systems, 38:109855--109885
2026
-
[33]
Shoubin Yu, Yue Zhang, Zun Wang, Jaehong Yoon, Huaxiu Yao, Mingyu Ding, and Mohit Bansal. 2026. When and how much to imagine: Adaptive test-time scaling with world models for visual spatial reasoning. arXiv preprint arXiv:2602.08236
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Le Zhang, Jihan Yang, Soundarya Krishnan, Jimit Majmudar, Xiou Ge, Prasoon Puri, Prathamesh Nandkishor Saraf, Shruti Bhargava, Dhivya Piraviperumal, Yinan Ling, and 1 others. 2026 a . From where things are to what they are for: Benchmarking spatial-functional intelligence in multimodal llms. arXiv preprint arXiv:2605.02130
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [35]
-
[36]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[37]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.