LoSATok: Low-dimensional Semantic-Acoustic Tokenizer for Cross-Domain Audio Understanding and Generation
Pith reviewed 2026-06-29 10:21 UTC · model grok-4.3
The pith
LoSATok compresses 1280-dimensional semantic audio features to 128 dimensions while keeping enough detail for both understanding and generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
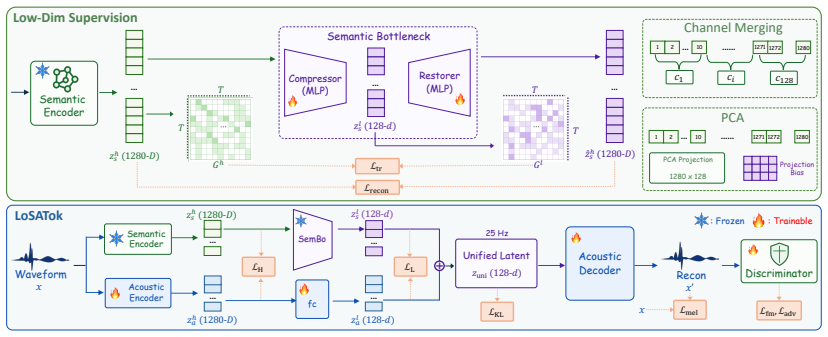
LoSATok uses a Semantic Bottleneck to compress 1280-dimensional semantic encoder features into 128 dimensions, regularized by a time-relation loss for temporal feature consistency and dual-level semantic supervision that combines high- and low-dimensional signals, so the resulting compact latents jointly capture semantics and acoustic details and support both understanding and improved Diffusion Transformer modeling.
What carries the argument
Semantic Bottleneck, which compresses semantic encoder features from 1280 to 128 dimensions while time-relation loss and dual-level supervision preserve temporal consistency plus semantic and acoustic content.
If this is right
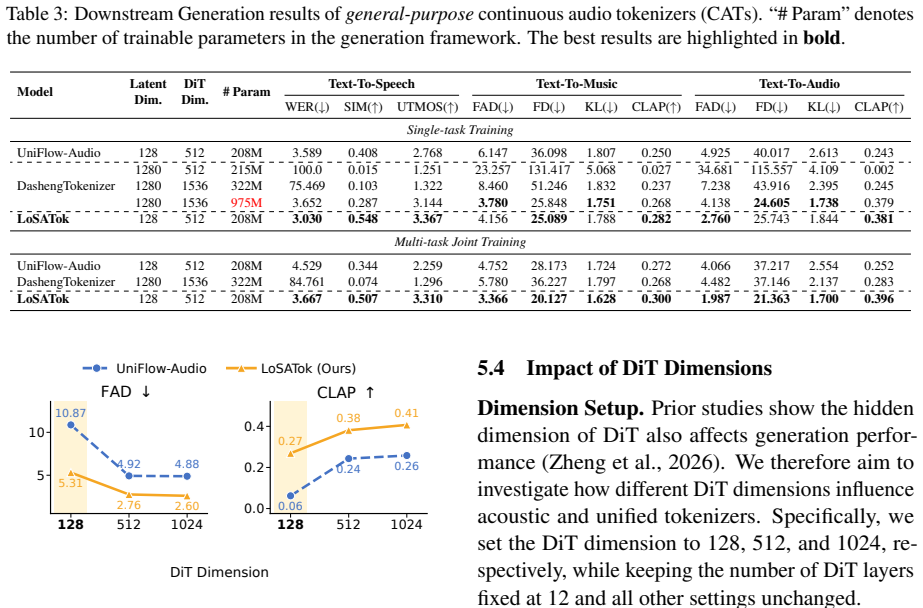
- Low-dimensional representations maintain competitive results on audio understanding tasks compared with higher-dimensional semantic encoders.
- The same compact latents improve Diffusion Transformer modeling performance on speech, music, and general audio generation.
- A single low-dimensional space can serve both understanding and generation across multiple audio domains.
Where Pith is reading between the lines
- The compression may reduce memory and compute costs when training or running long-sequence audio models.
- The same bottleneck-plus-dual-supervision pattern could be tested on video or multimodal tokenizers to check whether similar dimension reduction works.
- If the 128-dimensional space proves stable, it opens the possibility of lighter real-time audio pipelines that still support both recognition and synthesis.
Load-bearing premise
High-dimensional semantic features can be reduced to 128 dimensions without losing the semantic capacity and acoustic details that downstream understanding and generation tasks require.
What would settle it
A controlled test in which the dimension is forced to 128 and either understanding accuracy drops sharply below baseline semantic representations or Diffusion Transformer generation quality shows no improvement on standard speech, music, or audio benchmarks.
Figures




read the original abstract
Audio tokenizers are fundamental to unifying audio understanding and generation. Understanding requires high-level semantics, while generation demands semantic and acoustic details. Existing unified tokenizers jointly encode both in high-dimensional continuous latents, which increases the modeling burden of Diffusion Transformers (DiTs) for generation. We propose LoSATok, a low-dimensional audio tokenizer for cross-domain audio understanding and generation. Motivated by the observation that 1280-dimensional semantic encoder features are compressible, we introduce a Semantic Bottleneck that compresses them into 128 dimensions, regularized by the proposed time-relation loss for temporal feature consistency. We further design a dual-level semantic supervision method that leverages both high- and low-dimensional semantic signals, enabling the tokenizer to jointly capture semantics and acoustic details within a compact latent space. Experiments on speech, music, and general audio show that SemBo preserves strong low-dimensional semantic capacity and LoSATok retains competitive understanding performance compared with several semantic representations, while consistently improving DiT modeling performance on speech, music, and audio generation. These results demonstrate that LoSATok's low-dimensional representations can effectively support audio understanding and generation. Our code is provided at https://github.com/wxzyd123/LoSATok.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoSATok, a low-dimensional audio tokenizer that introduces a Semantic Bottleneck to compress 1280-dimensional semantic encoder features to 128 dimensions, regularized by a time-relation loss for temporal consistency and a dual-level semantic supervision scheme. This design aims to jointly retain semantic capacity and acoustic details in a compact latent space suitable for both understanding tasks and DiT-based generation. Experiments across speech, music, and general audio domains report competitive understanding performance relative to existing semantic representations and improved DiT modeling for generation; the manuscript includes supporting tables, ablations, and open-source code.
Significance. If the reported compression preserves the claimed semantic and acoustic fidelity, the work offers a practical route to lower the modeling cost of Diffusion Transformers for unified audio tasks without sacrificing cross-domain utility. Credit is given for the provision of reproducible code at https://github.com/wxzyd123/LoSATok, which strengthens the contribution beyond the algorithmic claims.
minor comments (2)
- [Abstract] Abstract: the summary of experimental outcomes would be strengthened by inclusion of at least one or two key quantitative metrics (e.g., accuracy or FID deltas versus baselines) to allow readers to gauge the scale of improvement without immediately consulting the tables.
- [Section 4] Section 4 (Experiments): confirm that all ablation tables explicitly state the number of runs or seeds used to compute reported means, consistent with the error-bar discussion in the text.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical value for DiT modeling, and the recommendation for minor revision. We are grateful for the credit given to the open-sourced code. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's construction begins from an external observation about 1280-dim feature compressibility and introduces a Semantic Bottleneck, time-relation loss, and dual-level supervision as design choices. These are then evaluated empirically on understanding and DiT-based generation tasks across domains, with code released. No equation or central claim reduces by construction to a fitted parameter or self-citation chain; the reported improvements are independent experimental outcomes rather than definitional or tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Midashenglm: Efficient audio understand- ing with general audio captions.arXiv preprint arXiv:2508.03983. Heinrich Dinkel, Xingwei Sun, Gang Li, Jiahao Mei, Yadong Niu, Jizhong Liu, Xiyang Li, Yifan Liao, Jiahao Zhou, Junbo Zhang, and 1 others. 2026. Dashengtokenizer: One layer is enough for unified audio understanding and generation.arXiv preprint arXiv:...
-
[2]
Musdb18 - a corpus for music separation. Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2022. UTMOS: UTokyo-SaruLab Sys- tem for V oiceMOS Challenge 2022. InInterspeech 2022, pages 4521–4525. Hubert Siuzdak. 2024. V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.