An Empirical Audit of k-NAF Budget Accounting for Anchored Decoding
Pith reviewed 2026-06-29 12:14 UTC · model grok-4.3
The pith
k-NAF budget accounting in Anchored Decoding keeps cumulative KL spend below sequence-level limits on tested workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the fixed workload, mean cumulative KL spend remains far below the sequence-level budgets K in {600, 1000}, and an empirical Bernstein-style proxy stays below K for every class; surface-overlap diagnostics (ROUGE-L and 5-gram Jaccard) are correspondingly small. Adaptive search increases the proxy spend ratio but does not produce clear budget exhaustion. On a held-out copyright-domain workload at k = 3, several prompts exhibit proxy ratios above 1 under early-stopped evaluations with small realized sample sizes; re-evaluating the same prompts with larger allocation reduces the proxy ratio to the range [0.26, 0.40] under comparable mean spend, consistent with proxy artifacts rather than per
What carries the argument
The k-NAF budget-accounting mechanism that uses cumulative KL divergence tracked against sequence-level budgets K via an empirical Bernstein-style proxy.
If this is right
- Mean cumulative KL spend on fixed workloads is far below K values of 600 and 1000.
- The Bernstein-style proxy remains below budget for every prompt class tested.
- Surface-overlap metrics such as ROUGE-L and 5-gram Jaccard stay small.
- Adaptive search targeting high proxy ratios does not result in clear budget exhaustion.
- Apparent proxy violations on copyright prompts resolve to low ratios with increased sample sizes.
Where Pith is reading between the lines
- The proxy metric may be sensitive to small sample sizes and early stopping, leading to overestimation of spend.
- Budget mechanisms like k-NAF may be more conservative than necessary in practice.
- Similar empirical audits could test whether the pattern holds for other prompt domains or decoding strategies.
- Future work might examine if larger fixed workloads reveal rare exhaustion cases.
Load-bearing premise
The fixed and adaptive workloads along with the ROUGE-L and 5-gram Jaccard diagnostics are representative enough that the observed non-exhaustion applies more broadly and that the proxy reliably indicates true budget violations.
What would settle it
Finding a set of prompts where the proxy spend ratio remains above 1 even after allocating much larger sample sizes and confirming actual per-trajectory KL spend exceeds K.
Figures



read the original abstract
We empirically audit the k-NAF budget-accounting mechanism in Anchored Decoding using (i) a fixed, class-stratified workload (approximately 8,500 randomized executions across six prompt classes) and (ii) an adaptive prompt-search procedure targeting high proxy spend ratios. On the fixed workload, mean cumulative KL spend remains far below the sequence-level budgets K in {600, 1000}, and an empirical Bernstein-style proxy stays below K for every class; surface-overlap diagnostics (ROUGE-L and 5-gram Jaccard) are correspondingly small. Adaptive search increases the proxy spend ratio but does not produce clear budget exhaustion. On a held-out copyright-domain workload at k = 3, several prompts exhibit proxy ratios above 1 under early-stopped evaluations with small realized sample sizes; re-evaluating the same prompts with larger allocation reduces the proxy ratio to the range [0.26, 0.40] under comparable mean spend, consistent with proxy artifacts rather than per-trajectory budget failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically audits the k-NAF budget-accounting mechanism in Anchored Decoding via a fixed class-stratified workload (~8,500 executions across six prompt classes) and an adaptive prompt-search procedure. It reports that mean cumulative KL spend remains far below sequence-level budgets K in {600, 1000}, an empirical Bernstein-style proxy stays below K in every class, surface-overlap diagnostics are small, adaptive search does not produce exhaustion, and apparent proxy ratios >1 on small held-out samples reduce to [0.26, 0.40] with larger allocations.
Significance. If the empirical measurements hold, the work supplies direct evidence that the k-NAF accounting is conservative in practice and that early proxy violations are sample-size artifacts rather than per-trajectory failures. This strengthens in the mechanism's safety properties for anchored decoding and illustrates the value of both fixed and adaptive workloads plus surface-overlap checks for auditing budget proxies.
major comments (1)
- [Experimental setup and results sections] Experimental setup and results sections: the manuscript states results from ~8,500 executions and re-evaluations with larger samples but provides neither the full per-class data tables, the precise randomization and stratification procedure, nor the statistical tests used to establish that mean spend is 'far below' K and that proxy ratios reliably drop with sample size. These omissions are load-bearing for the central claim that non-exhaustion generalizes and that early violations are artifacts.
minor comments (2)
- [Abstract and §3] The abstract and text refer to 'six prompt classes' and 'held-out copyright-domain workload' without enumerating the classes or the exact copyright prompts; adding this enumeration would improve reproducibility.
- [Proxy definition] The Bernstein-style proxy is described only at a high level; a brief equation or pseudocode for its construction would clarify how it differs from the direct KL metric.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Experimental setup and results sections] Experimental setup and results sections: the manuscript states results from ~8,500 executions and re-evaluations with larger samples but provides neither the full per-class data tables, the precise randomization and stratification procedure, nor the statistical tests used to establish that mean spend is 'far below' K and that proxy ratios reliably drop with sample size. These omissions are load-bearing for the central claim that non-exhaustion generalizes and that early violations are artifacts.
Authors: We agree that these details are load-bearing and were omitted. In revision we will add: (1) an appendix with full per-class tables reporting mean cumulative KL spend, standard deviation, proxy ratio, and surface-overlap metrics for each of the six prompt classes; (2) a precise description of the procedure (class-stratified uniform sampling over the six prompt classes using a fixed random seed for reproducibility, with ~8500 total executions allocated proportionally); and (3) the statistical tests (one-sample t-tests of mean spend against K with Bonferroni correction, plus linear regression of proxy ratio on realized sample size to quantify the artifact). These additions will be placed in the Experimental Setup and Results sections and will not change the reported findings. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a direct empirical audit consisting of measurements of cumulative KL spend and Bernstein-style proxy ratios on fixed (~8500 executions) and adaptive workloads against external sequence-level budgets K in {600,1000}. No derivation chain, fitted parameters presented as predictions, self-definitional equations, or load-bearing self-citations appear in the described claims or abstract. The central results (mean spend far below K, proxy below K in all classes, ratios dropping to [0.26,0.40] on larger samples) are independent empirical observations against stated external budgets and diagnostics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blameless mechanism guarantees: What copyright asks of probabilistic bounds
Aloni Cohen. Blameless mechanism guarantees: What copyright asks of probabilistic bounds. arXiv preprint, 2025
2025
-
[2]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Anchored decoding: Operationalizing near-access-freeness at inference time.arXiv preprint, 2026
Jacqueline He et al. Anchored decoding: Operationalizing near-access-freeness at inference time.arXiv preprint, 2026
2026
-
[4]
Dp-auditorium: A flexible library for auditing differential privacy
William Kong, Andres Muñoz Medina, and Mónica Ribero. Dp-auditorium: A flexible library for auditing differential privacy. InProceedings on Privacy Enhancing Technologies (PoPETs), 2023
2023
-
[5]
Empirical bernstein bounds and sample variance penalization
Andreas Maurer and Massimiliano Pontil. Empirical bernstein bounds and sample variance penalization. InConference on Learning Theory (COLT), 2009
2009
-
[6]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[7]
Red teaming language models with language models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. InEmpirical Methods in Natural Language Processing (EMNLP), 2022
2022
-
[8]
Rainbow teaming: Open- ended generation of diverse adversarial prompts
Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, et al. Rainbow teaming: Open- ended generation of diverse adversarial prompts. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[9]
Privacy auditing with one (1) training run
Thomas Steinke, Milad Nasr, and Matthew Jagielski. Privacy auditing with one (1) training run. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[10]
Nikhil Vyas, Sham M. Kakade, and Boaz Barak. Provable copyright protection for generative models. InInternational Conference on Machine Learning (ICML), 2023. 10 A Notation Table 5 lists the symbols used throughout the paper. Symbol Meaning p, p s, p r Controlled (decoded), safe (anchor), risky (target) next-token / sequence distributions. x, y <t Prompt ...
-
[11]
Match the safe model to the risky model in capability.If the anchor is substantially weaker or differently tuned than the risky model, DKL(p∥p s) may primarily reflect capability differences rather than memorization-relevant divergence.Pass criterion:on a benign workload, the mean spend differs by ≤20% between two anchors of comparable capability
-
[12]
Do not omit classes; instead, report the worst-performing class explicitly.Pass criterion: UEBB ≤K for every class under the data-dependentR eff (not the worst-caseR)
Execute the fixed workload with M≥1500 executions per class.For each class, report mean spend, sample variance, Reff, and UEBB. Do not omit classes; instead, report the worst-performing class explicitly.Pass criterion: UEBB ≤K for every class under the data-dependentR eff (not the worst-caseR)
-
[13]
Compute downstream overlap metrics (ROUGE-L and n-gram Jaccard) alongside KL spendwhen reference text is available. KL spend is a proxy for memorization, whereas overlap metrics more directly reflect copying.Pass criterion:the proxies agree qualitatively (no class has low spend but high overlap, or vice versa)
-
[14]
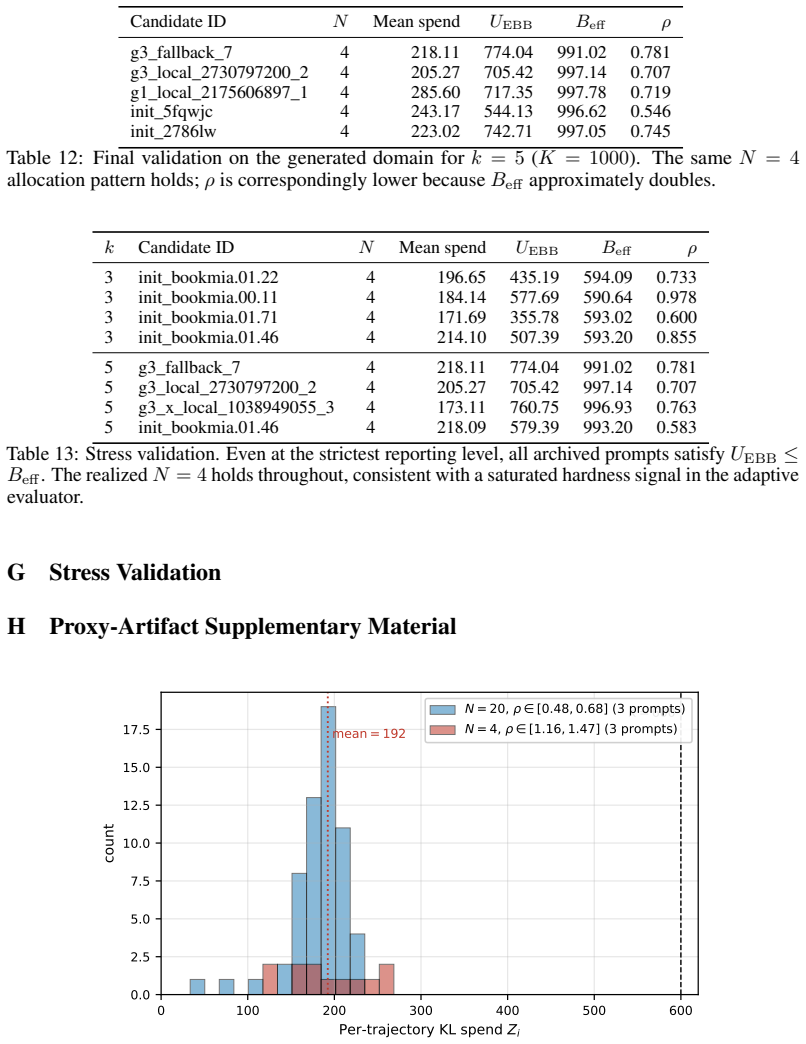
At N=20 and δ=0.0033 , the deterministic Bernstein term falls to ≤192 for Reff ≤200 (Table 14); in this regime,ρ >1is informative rather than artifactual
In the adversarial stage, enforce a minimum-N floor.Run at least Nmin = 20 trajectories for any prompt whose preliminary ρ exceeds 0.9, regardless of the survivor-test outcome. At N=20 and δ=0.0033 , the deterministic Bernstein term falls to ≤192 for Reff ≤200 (Table 14); in this regime,ρ >1is informative rather than artifactual. 16
-
[15]
Identical ratios (e.g., ρ= 1.4 ) at N= 4 versus N= 50 convey materially different uncertainty
Report the Bernstein width alongside the point estimatein every per-prompt table. Identical ratios (e.g., ρ= 1.4 ) at N= 4 versus N= 50 convey materially different uncertainty
-
[16]
Section 4.2).Pass criterion:surrogate AUC ≥0.8 on a held-out split before starting the search
Validate any surrogate prior to relying on it for allocation.If maxP(safe) saturates near 1, the surrogate provides little discrimination and surrogate-driven allocation may collapse to the minimum (cf. Section 4.2).Pass criterion:surrogate AUC ≥0.8 on a held-out split before starting the search
-
[17]
Complete the prefix:\n
Replicate the search using at least two random seeds.Report variability in the archive maximum. Single-seed results, including those in this paper, are suggestive rather than definitive. In the present study, we pass steps (2), (3), (5), and partially step (6), but do not pass steps (1), (4), or (7). K Reproducibility Appendix This appendix specifies the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.