Mind the Gap: Mixtures of Gaussians in Approximate Differential Privacy
Pith reviewed 2026-06-29 11:42 UTC · model grok-4.3
The pith
Mixture mechanisms built from offset Gaussians achieve (ε, δ)-DP with lower expected noise and variance than the analytic Gaussian mechanism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
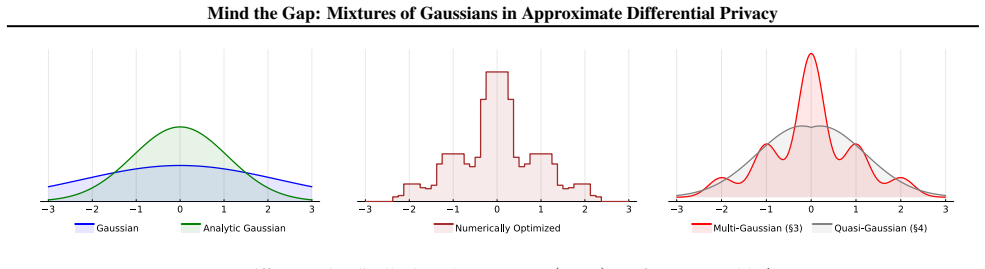
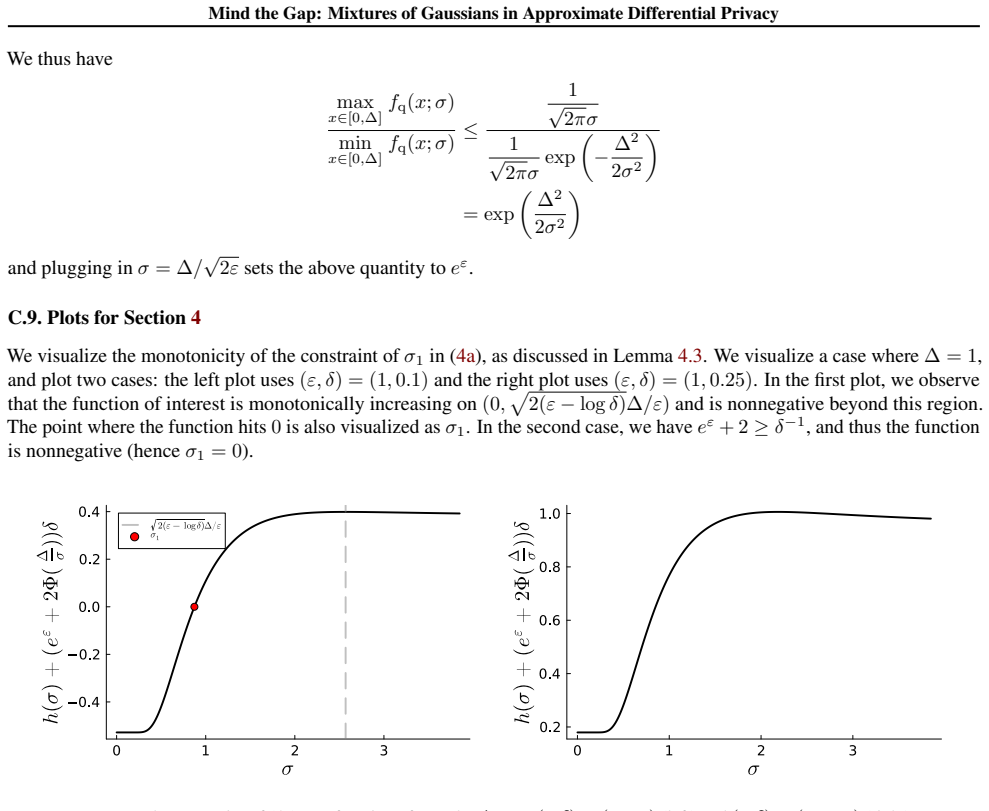
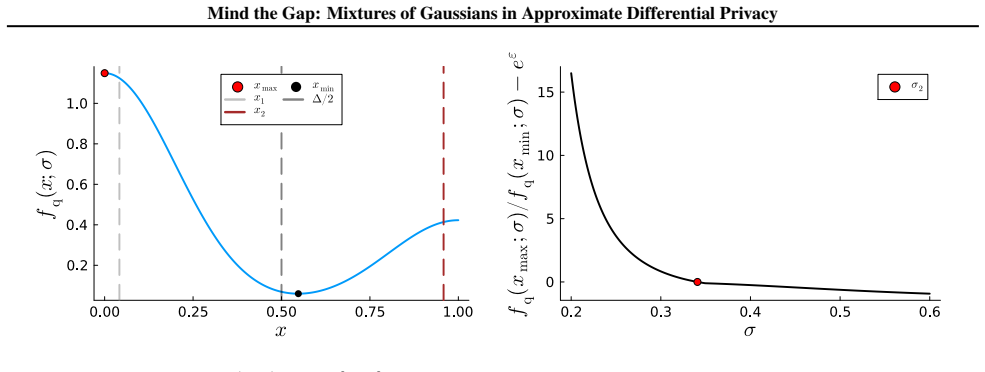
By mixing multiple Gaussians that share the same variance but differ in their means and weights, one obtains distributions that meet the (ε, δ)-DP definition at strictly smaller noise levels than the analytic Gaussian mechanism; the construction is tight for the chosen variance and the gap to optimality shrinks to near zero in the low-privacy regime that motivates the design.
What carries the argument
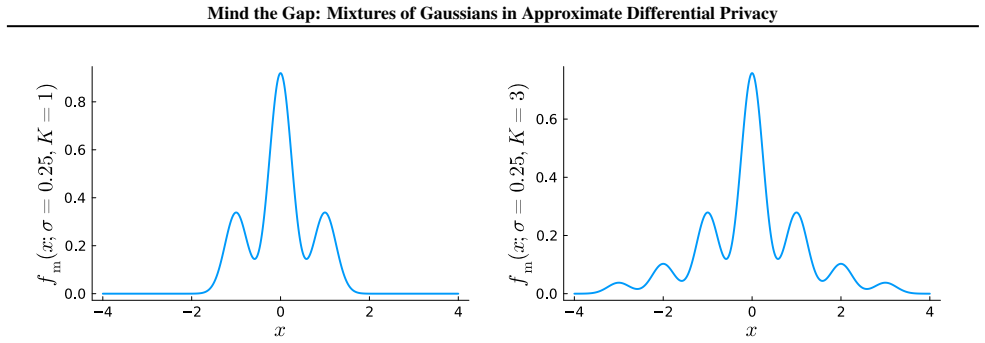
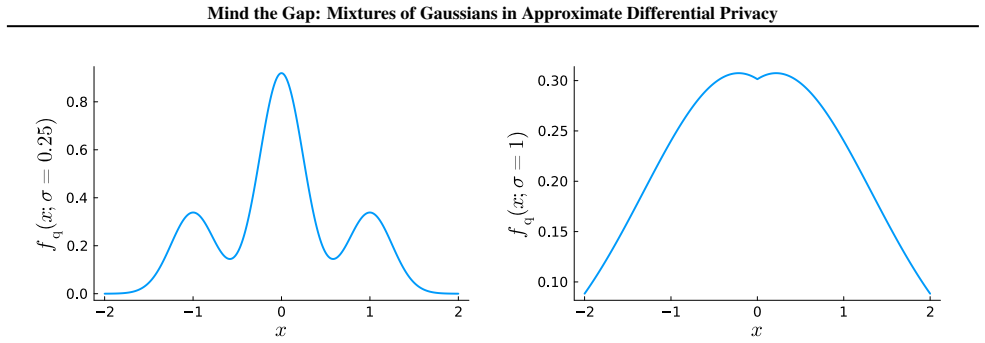
Mixture mechanisms: convex combinations of a zero-mean Gaussian and additional Gaussians whose means scale with query sensitivity and whose weights are chosen so the overall distribution satisfies the (ε, δ) definition under derived variance conditions.
If this is right
- Expected absolute noise (l1-loss) is substantially lower than under the analytic Gaussian mechanism.
- Variance (l2-loss) is lower for the zero-mean component of the mixture.
- The optimality gap of the analytic Gaussian mechanism is nearly eliminated in moderate and low privacy regimes.
- The required variances can be computed efficiently from the derived closed-form conditions.
Where Pith is reading between the lines
- The same mixture idea could be tested on vector-valued queries by applying it coordinate-wise or jointly.
- Practical data-release pipelines that currently use the analytic Gaussian mechanism could switch to these mixtures with immediate utility gains in low-privacy settings.
- The construction shows that deliberately introducing non-zero-mean noise components can offset the conservatism built into single-Gaussian mechanisms.
Load-bearing premise
The mixture weights and means can be chosen so the resulting distribution meets the (ε, δ)-DP definition exactly once the variance satisfies the derived conditions, assuming sensitivities are known and fixed.
What would settle it
A direct numerical verification that, for a chosen sensitivity and (ε, δ) pair, the mixture produced by the algorithm fails to satisfy the privacy inequality between some pair of neighboring datasets.
Figures
read the original abstract
We design a class of additive noise mechanisms that satisfy \((\varepsilon, \delta)\)-differential privacy (DP) for scalar, real-valued query functions with known sensitivities, with a particular focus on moderate and low-privacy regimes. These mechanisms, which we call \textit{mixture mechanisms}, are constructed by mixing multiple Gaussian distributions that share the same variance but differ in their means and mixture weights. The resulting distributions can be interpreted as convex combinations of a zero-mean Gaussian (as used in the analytic Gaussian mechanism) and additional Gaussians whose means depend on the sensitivity of the query function. We derive tight conditions on the variances required for \((\varepsilon, \delta)\)-DP and provide efficient algorithms to compute them. Compared to the analytic Gaussian mechanism, our mechanisms yield substantially lower expected noise amplitudes (\(l_1\)-loss) and variances (\(l_2\)-loss for zero-mean distributions). In the low-privacy regime that motivates our design, our mechanisms approach optimality, mitigating nearly all of the optimality gap of the analytic Gaussian mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a class of additive noise mechanisms called mixture mechanisms for (ε, δ)-differential privacy on scalar real-valued queries with known sensitivities. These are constructed as mixtures of Gaussians sharing a common variance but with different means (depending on sensitivity Δ) and weights, interpreted as convex combinations of a zero-mean Gaussian and additional shifted Gaussians. The work derives tight conditions on the variances to ensure exact (ε, δ)-DP satisfaction, supplies efficient algorithms to compute the parameters, and claims substantially lower l1-loss (expected noise amplitude) and l2-loss (variance for zero-mean cases) relative to the analytic Gaussian mechanism, with the gap nearly closed in low-privacy regimes.
Significance. If the variance derivations hold exactly, the mechanisms could meaningfully improve utility for DP noise addition on scalar queries in moderate-to-low privacy settings by reducing the optimality gap of the analytic Gaussian mechanism while preserving the exact DP guarantee. The emphasis on efficient parameter computation and the focus on regimes where standard mechanisms are suboptimal are practical strengths.
major comments (2)
- [Construction and variance derivation (abstract and main technical sections)] The derivation of the tight variance conditions (the load-bearing step for all utility claims) must be shown to guarantee that the mixture distribution satisfies the (ε, δ)-DP definition exactly for the chosen weights and Δ-dependent means; any restriction to specific component counts or mean ranges would invalidate the reported l1/l2 improvements and the comparison to the analytic Gaussian mechanism.
- [Privacy analysis and algorithm sections] The premise that mixture weights and means can be chosen so the resulting distribution meets (ε, δ)-DP exactly when the derived σ^{2} conditions hold enters all comparisons; the paper must demonstrate this without post-hoc adjustment or approximation in the privacy-loss analysis.
minor comments (2)
- [Experimental evaluation] Clarify the exact number of mixture components used in the reported experiments and whether the variance conditions scale with that number.
- [Notation and preliminaries] Ensure all notation for mixture weights, means, and the common variance is introduced before first use and is consistent across equations.
Simulated Author's Rebuttal
We thank the referee for the careful review and for recognizing the potential practical value of mixture mechanisms in moderate-to-low privacy regimes. We address the two major comments below, clarifying that the manuscript already contains exact derivations from the DP definition.
read point-by-point responses
-
Referee: [Construction and variance derivation (abstract and main technical sections)] The derivation of the tight variance conditions (the load-bearing step for all utility claims) must be shown to guarantee that the mixture distribution satisfies the (ε, δ)-DP definition exactly for the chosen weights and Δ-dependent means; any restriction to specific component counts or mean ranges would invalidate the reported l1/l2 improvements and the comparison to the analytic Gaussian mechanism.
Authors: Section 3 derives the variance conditions directly from the (ε, δ)-DP definition. For neighboring inputs differing by Δ, we form the mixture densities (convex combinations of zero-mean and shifted Gaussians) and bound the privacy-loss random variable exactly: the probability that the log density ratio exceeds ε is at most δ. The resulting inequalities on σ² are solved without approximation or post-hoc adjustment, and hold for arbitrary numbers of components whose means are integer multiples of Δ. The algorithms in Section 4 simply optimize weights subject to these exact conditions; no restrictions on component count or mean range are imposed beyond the construction stated in the paper. revision: no
-
Referee: [Privacy analysis and algorithm sections] The premise that mixture weights and means can be chosen so the resulting distribution meets (ε, δ)-DP exactly when the derived σ² conditions hold enters all comparisons; the paper must demonstrate this without post-hoc adjustment or approximation in the privacy-loss analysis.
Authors: The privacy analysis begins from the definition and obtains closed-form conditions on σ² that make the mixture satisfy (ε, δ)-DP exactly for any valid choice of weights and Δ-dependent means. The subsequent numerical procedures locate the minimal-loss parameters inside the feasible region defined by those exact conditions; they do not relax or approximate the privacy guarantee itself. All reported l1/l2 improvements are therefore computed under distributions that meet the definition by construction. revision: no
Circularity Check
No significant circularity in derivation of mixture mechanisms and variance conditions
full rationale
The paper constructs additive noise mechanisms as mixtures of Gaussians sharing variance but differing in means and weights, then derives tight conditions on the variances to ensure exact (ε, δ)-DP for queries with known sensitivity. This derivation is presented as an independent computation (with efficient algorithms supplied), not as a quantity defined in terms of the target utility metrics or fitted to them. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described chain. The utility comparisons (lower l1- and l2-loss) follow from the mechanisms satisfying the DP definition under the derived conditions, making the central claim self-contained against external benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Query functions have known, fixed sensitivities
- standard math Standard definition of (ε, δ)-differential privacy for additive noise mechanisms
Reference graph
Works this paper leans on
-
[1]
B., Mironov, I., Talwar, K., and Zhang, L
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., and Zhang, L. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 308–318,
2016
-
[2]
M., Ashmead, R., Cumings-Menon, R., Garfinkel, S., Heineck, M., Heiss, C., Johns, R., Kifer, D., Leclerc, P., Machanavajjhala, A., et al
Abowd, J. M., Ashmead, R., Cumings-Menon, R., Garfinkel, S., Heineck, M., Heiss, C., Johns, R., Kifer, D., Leclerc, P., Machanavajjhala, A., et al. The 2020 Census Disclo- sure Avoidance System TopDown Algorithm.Harvard Data Science Review, 4(4),
2020
-
[3]
Concentrated Differential Privacy
Dwork, C. and Rothblum, G. N. Concentrated differential privacy.arXiv:1603.01887,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Differential Privacy and Machine Learning: a Survey and Review
Ji, Z., Lipton, Z. C., and Elkan, C. Differential privacy and machine learning: a survey and review.arXiv:1412.7584,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Parikh, N
Accessed: 2026-05-19. Parikh, N. and Boyd, S. Proximal algorithms.Foundations and Trends® in Optimization, 1(3):127–239,
2026
-
[6]
Rinberg, R., Shumailov, I., Singhal, V ., Cummings, R., and Papernot, N. Beyond laplace and gaussian: Exploring the generalized gaussian mechanism for private machine learning.arXiv:2506.12553,
-
[7]
Sinha, A., Mesnard, T., McKenna, R., Liu, D., Choquette- Choo, C. A., Huang, Y ., Yu, D., Kaissis, G., Charles, Z., Liu, R., Chua, L., Kamath, P., Manurangsi, P., He, S., Zhang, C., Ghazi, B., Pigem, B. D. B., Eruvbetine, P., Warkentin, T., Joulin, A., and Kumar, R. VaultGemma: A differentially private Gemma model.arXiv:2510.15001,
-
[8]
Privacy Loss in Apple's Implementation of Differential Privacy on MacOS 10.12
Tang, J., Korolova, A., Bai, X., Wang, X., and Wang, X. Privacy loss in Apple’s implementation of differential pri- vacy on macOS 10.12.arXiv preprint arXiv:1709.02753,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DAS 2020 Redistrict- ing Production Code
US Census Bureau. DAS 2020 Redistrict- ing Production Code. https://github. com/uscensusbureau/DAS_2020_ Redistricting_Production_Code,
2020
-
[10]
Vadhan, S
Accessed: 2025-10-01. Vadhan, S. The complexity of differential privacy. InTuto- rials on the Foundations of Cryptography, pp. 347–450. Springer,
2025
-
[11]
We can now prove Theorem 3.2
which coincides with the right-hand side presented in the lemma. We can now prove Theorem 3.2. Proof of Theorem 3.2.Given η∈(0,1) fix any β≤ √ 2πησδ , and assume the condition in the statement of this theorem holds: Z ∞ −∞ min{eεfm(x;σ, K)−f m(x+φ;σ, K),0}dx+ (1−η)δ≥0∀φ∈ {0, β,2β, . . . ,∆}.(6) 17 Mind the Gap: Mixtures of Gaussians in Approximate Differe...
2018
-
[12]
The monotonicity proof is complete since we proved the desired inequality (18). Now, to see thatσ=σ g satisfies (2), consider the stronger condition Z ∞ −∞ min{eεfm(x;σ, K)−f m(x+φ;σ, K),0}dx+ (1−η)δ≥0∀φ∈[0,∆], which coincides with the definition of (ε,(1−η)δ) -DP (cf.proof of Theorem 3.2). A sufficient condition for this is when each mixture density 1√ 2...
2025
-
[13]
Given that Algorithm 1 applies a bisection search within (0, r), the runtime of the rest of this algorithm dominates the computation of the analytic Gaussian
The function, however, can be evaluated in constant time. Given that Algorithm 1 applies a bisection search within (0, r), the runtime of the rest of this algorithm dominates the computation of the analytic Gaussian. We borrow the upper bound r=O(ε −1p log(δ−1)) for the analysis of our bisection search method next. Our bisection method is restricted to an...
2016
-
[14]
satisfies ∆2 2σ2 -zCDP. That is, for any µ and any neighbors(D, D ′)∈ Nsatisfying|q(D)−q(D ′)| ≤∆, we have Dα (N(µ+q(D), σ)∥N(µ+q(D ′), σ))≤α ∆2 2σ2 ,∀α∈(1,∞).(22) Thus, our multi-Gaussian mixture mechanism fm(x;σ, K) = 1 cK PK k=−K e−|k|εϕ(x;k∆, σ) is also ∆2 2σ2 -zCDP, which follows from the fact that for anyα∈(1,∞)we have Dα 1 cK KX k=−K e−|k|εϕ(·;q(D)...
2016
-
[15]
We observe that in 143/150 of the cases, multimodality provides strict improvements (expected l2-loss) over unimodality
We note that the improvements for the l2-loss are qualitatively better compared to the improvements for the l1-loss. We observe that in 143/150 of the cases, multimodality provides strict improvements (expected l2-loss) over unimodality. Across all instances, the mean improvement is 61.86% (sd 35.35) and the median improvement is79.44%. 43 Mind the Gap: M...
2025
-
[16]
Price of privacy in ML (unabridged) Thus far, we have compared privacy mechanisms based on their expected losses
D.7. Price of privacy in ML (unabridged) Thus far, we have compared privacy mechanisms based on their expected losses. We now evaluate the performance of these mechanisms in a machine learning task implemented under (ε, δ)-DP. Specifically, we compare the in- and out-of-sample performances of privacy-preserving linear classifiers. Each classifier is train...
2025
-
[17]
The proximal operator has sensitivity ∆ = 2 assuming the feature vectors are pre-processed so that ∥xi∥∞ ≤1, i∈[N]
who inject noise into each proximal update step (which is a scalar update and thus our mechanisms are applicable), and the post processing property (Dwork & Roth, 2014, §2.1) of differential privacy guarantees that the resulting classifier is also differentially private. The proximal operator has sensitivity ∆ = 2 assuming the feature vectors are pre-proc...
2014
-
[18]
Table 8 reports the mean in- and out-of-sample errors across 500 random training-set/test-set (80/20%) splits of various datasets
or via numerical composition (Gopi et al., 2021), which we implement in Python for our mechanisms since the quasi-Gaussian mixture mechanism does not satisfy the zCDP property verbatim. Table 8 reports the mean in- and out-of-sample errors across 500 random training-set/test-set (80/20%) splits of various datasets. We use 6 of the most popular UCI classif...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.