Minimal Prompt Perturbations Lead to Code Vulnerabilities: Prompt Fragility and Hidden-State Signals in Coding LLMs
Pith reviewed 2026-06-29 06:25 UTC · model grok-4.3
The pith
Token-level mutations as small as a single character can turn LLM-generated code from secure to vulnerable, with hidden states revealing predictability differences between vulnerability types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We apply token-level mutations to prompts across three models and five programming languages, and show that mutations as small as a single-character change can flip generated code from secure to vulnerable. Probing the models' hidden states reveals that this fragility is partially encoded in prompt representations, but unevenly so. Input-handling vulnerabilities, where the model omits validation or sanitization, are more predictable (mean AUC 0.753) than secure-defaults vulnerabilities, where insecure code stems from one local choice such as a weak algorithm or unsafe parameter (mean AUC 0.674). These results show that the threat model for LLM-assisted coding extends beyond prompt injection
What carries the argument
Token-level prompt mutations tested across models and languages, paired with linear probes on hidden states to measure predictability of input-handling versus secure-defaults vulnerabilities.
Load-bearing premise
The chosen token-level mutations and the specific vulnerability detection method accurately represent the security impact of typical developer prompt variations across real-world use.
What would settle it
Running the same mutations and hidden-state probes on prompts written by actual developers in production coding workflows rather than artificially constructed ones.
Figures













read the original abstract
LLM-based coding assistants are seeing rapid adoption, offering substantial gains in developer productivity. As organizations increasingly ship code these agents produce, the security of that code becomes critical. Prior work has shown that minor prompt perturbations degrade the functional correctness of LLM-generated code, but whether they also compromise code security has remained unstudied. We apply token-level mutations to prompts across three models and five programming languages, and show that mutations as small as a single-character change can flip generated code from secure to vulnerable. Probing the models' hidden states reveals that this fragility is partially encoded in prompt representations, but unevenly so. Input-handling vulnerabilities, where the model omits validation or sanitization, are more predictable (mean AUC 0.753) than secure-defaults vulnerabilities, where insecure code stems from one local choice such as a weak algorithm or unsafe parameter (mean AUC 0.674). These results show that the threat model for LLM-assisted coding extends beyond prompt injection to ordinary prompt variation, and indicate that input-handling flaws can be caught before generation while secure-defaults flaws require intervention during decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that token-level mutations as small as single-character changes to prompts can flip LLM-generated code from secure to vulnerable across three models and five languages. It further reports that hidden-state representations allow better prediction of input-handling vulnerabilities (mean AUC 0.753) than secure-defaults vulnerabilities (mean AUC 0.674), and concludes that the threat model for LLM-assisted coding therefore extends beyond prompt injection to ordinary prompt variation.
Significance. If the empirical measurements hold under more representative perturbations, the work would establish prompt fragility as a distinct security concern for coding LLMs and demonstrate that certain vulnerability classes are detectable from prompt embeddings before generation. The multi-model, multi-language design and the distinction between vulnerability types are strengths of the measurement study.
major comments (2)
- [Abstract and §5] Abstract and §5: The central claim that results extend the threat model to 'ordinary prompt variation' is load-bearing for the paper's broader significance, yet the token-level mutations used are not shown to be a reasonable proxy for naturalistic developer prompt changes (e.g., rephrasings collected from GitHub issues or Stack Overflow). No such comparison is reported.
- [§3] §3 (Methods): The procedure for labeling generated code as secure or vulnerable, including the exact detection rules and any post-hoc choices, is not described in sufficient detail to evaluate the reliability of the reported flip rates or AUC values.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major comments and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5: The central claim that results extend the threat model to 'ordinary prompt variation' is load-bearing for the paper's broader significance, yet the token-level mutations used are not shown to be a reasonable proxy for naturalistic developer prompt changes (e.g., rephrasings collected from GitHub issues or Stack Overflow). No such comparison is reported.
Authors: We agree that the manuscript does not report a direct comparison between our token-level mutations and naturalistic developer prompt changes drawn from GitHub issues or Stack Overflow. Our experiments were designed to isolate the effect of minimal perturbations. We will revise the abstract and §5 to qualify the broader claim, explicitly noting that the results demonstrate fragility under minimal changes and that extension to fully naturalistic variations remains an open question for future work. This will be a partial revision. revision: partial
-
Referee: [§3] §3 (Methods): The procedure for labeling generated code as secure or vulnerable, including the exact detection rules and any post-hoc choices, is not described in sufficient detail to evaluate the reliability of the reported flip rates or AUC values.
Authors: We acknowledge that §3 does not provide sufficient detail on the labeling procedure. In the revised manuscript we will expand this section to specify the exact detection rules, any automated tools or heuristics employed, and all post-hoc choices made when classifying generated code as secure or vulnerable. revision: yes
Circularity Check
Empirical measurement study; no derivations or self-referential reductions
full rationale
The paper conducts an experimental study: token-level mutations are applied to prompts, code is generated across models and languages, vulnerabilities are detected, and hidden-state probes yield AUC values. No equations, fitted parameters, or derivations are described that reduce the reported flip rates or AUCs to quantities defined by the same data or by self-citation chains. The central claims rest on direct empirical measurements rather than any load-bearing self-definition, ansatz smuggling, or uniqueness theorem imported from prior author work. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
the mutation does not change the metric
Information-theoretic probing for linguistic structure. InProceedings of the 58th Annual Meet- ing of the Association for Computational Linguistics, pages 4609–4622, Online. Association for Computa- tional Linguistics. Fazle Rabbi, Zishuo Ding, and Jinqiu Yang. 2026. A multi-language perspective on the robustness of llm code generation.Preprint, arXiv:250...
Pith/arXiv arXiv 2026
-
[2]
"; pid_t pid = fork(); if(pid == 0) { dup2(pipefd[1], STDOUT_FILENO); // direct exec; argv separation execlp(
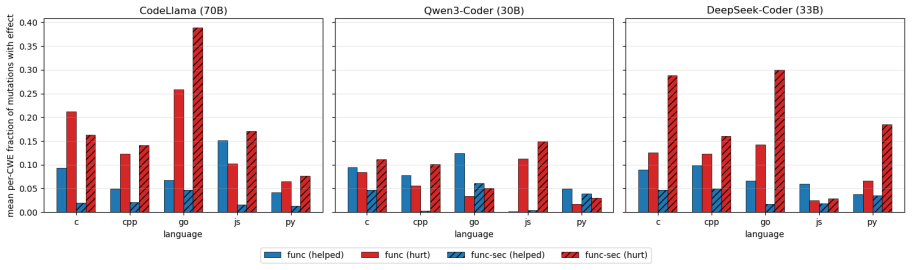
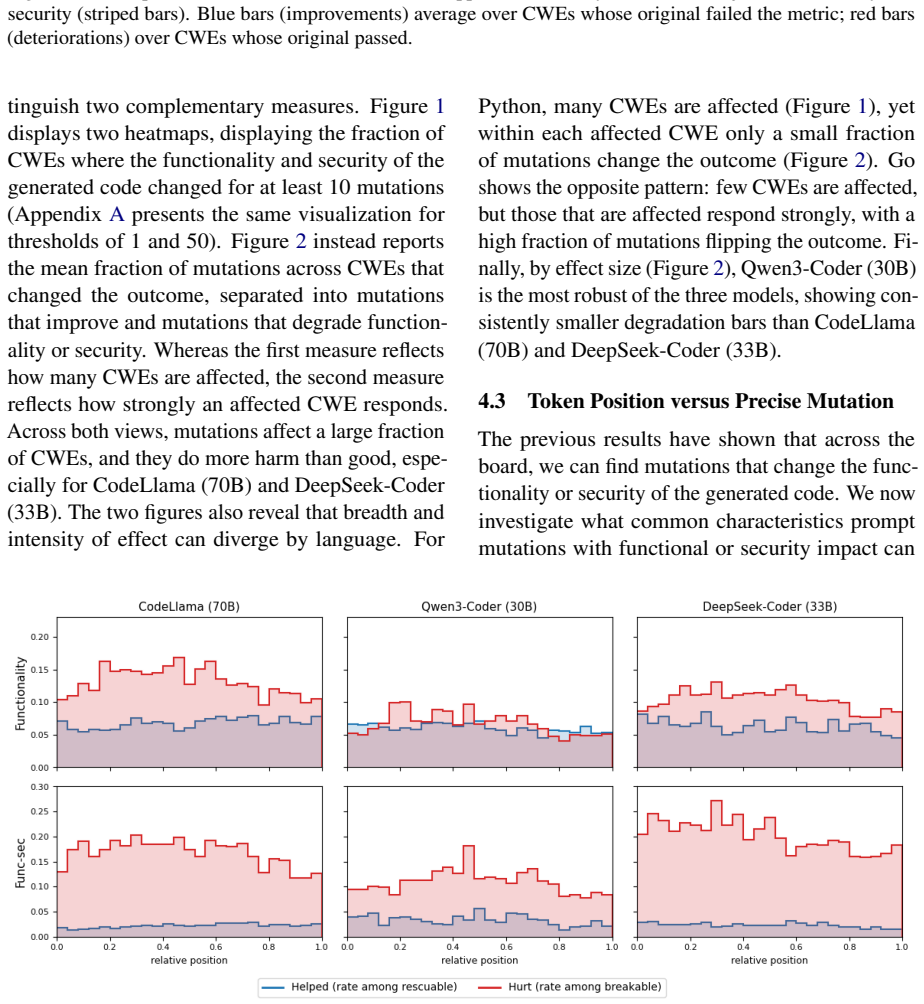
The overall picture is consistent with the temperature-0 finding: a non-trivial fraction of CWEs across every (model, language) cell exhibit at least one mutation that significantly perturbs the generation. We find that similar numbers of CWEs are affected both for functionality and joint functionality and security. This suggests that in- troducing more s...
-
[3]
tmp && echo hacked!
shows a harmful case: mutating the example literals removes the per-character subdomain vali- dation, producing an Server-Side Request Forgery (SSRF). The right panel shows the rarer case where the mutation improves security, by perturbing the parameter nameuser ID. One explanation is that the model relies more on its pretraining data when an essential co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.