Conformal Certification of Reasoning Trace Prefixes
Pith reviewed 2026-06-29 06:57 UTC · model grok-4.3
The pith
CROP certifies the longest prefix of a reasoning trace with controlled error probability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CROP is a verifier-agnostic calibration procedure that, given any step-level risk proxy, selects a calibrated threshold and returns the longest contiguous prefix whose step risk proxies remain below it. Assuming exchangeability, CROP rigorously controls the marginal probability that the returned prefix contains an annotated error.
What carries the argument
The CROP calibration procedure, which sets a threshold on step-level risk proxies to return the longest prefix below that threshold while providing a conformal guarantee on error inclusion.
If this is right
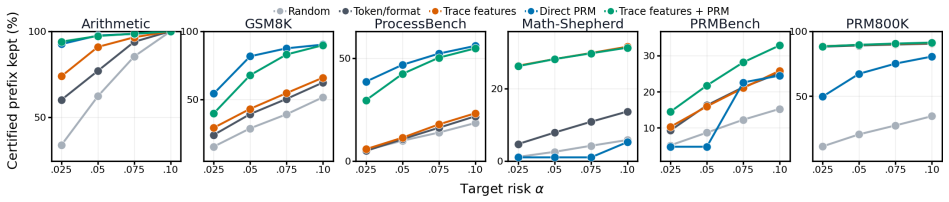
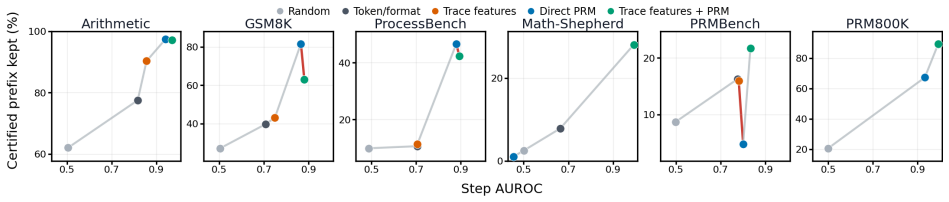
- Standard step-level metrics such as AUROC do not fully capture prefix utility.
- Verifiers should instead be evaluated by certified prefix length.
- CROP balances over- and under-withholding of trace segments.
- Using CROP improves downstream repair accuracy by preserving valid intermediate reasoning while discarding misleading suffixes.
Where Pith is reading between the lines
- The same calibration idea could be tested on sequential outputs other than reasoning traces, such as generated code or mathematical derivations.
- Process supervision techniques might gain statistical safety properties by pairing their risk scores with conformal threshold selection.
- Hybrid repair pipelines could treat the certified prefix as a fixed reliable base and focus human or model effort only on the uncertified suffix.
Load-bearing premise
The reasoning traces or their risk proxies satisfy the exchangeability assumption required for the conformal guarantee to hold.
What would settle it
On a new collection of traces, the observed fraction of certified prefixes that contain an annotated error exceeds the nominal level chosen at calibration time.
Figures

read the original abstract
Language model reasoning traces are rarely all-or-nothing; they frequently contain valid intermediate steps before a critical error occurs. Existing uncertainty quantification methods typically certify final answers or entire responses, failing to provide statistical guarantees for the proportion of a sequential trace that can be safely retained. To address this, we introduce CROP (Conformal Reasoning Output Prefixes), a verifier-agnostic calibration procedure for clean-prefix certification. Given any step-level risk proxy, CROP selects a calibrated threshold and returns the longest contiguous prefix whose step risk proxies remain below it, routing the uncertified suffix for downstream review or repair. Assuming exchangeability, CROP rigorously controls the marginal probability that the returned prefix contains an annotated error. Across six process-labeled reasoning datasets, we demonstrate that standard step-level metrics such as AUROC do not fully capture prefix utility, suggesting verifiers should instead be evaluated by certified prefix length. Furthermore, CROP balances over- and under-withholding, improving downstream repair accuracy by preserving valid intermediate reasoning while discarding misleading suffixes. Ultimately, this work positions prefix certification as a rigorous, practical bridge between process supervision, abstention, and repair.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CROP (Conformal Reasoning Output Prefixes), a verifier-agnostic calibration procedure that, given any step-level risk proxy, selects a threshold and returns the longest contiguous prefix of a reasoning trace whose proxies remain below the threshold. Under the assumption of exchangeability, it claims to rigorously control the marginal probability that the returned prefix contains an annotated error. Experiments across six process-labeled datasets show that AUROC does not fully capture prefix utility, that CROP balances over- and under-withholding, and that it improves downstream repair accuracy by preserving valid intermediate steps while discarding misleading suffixes.
Significance. If the claimed marginal guarantee holds under the stated exchangeability assumption, the work provides a statistically grounded method for certifying partial reasoning traces rather than entire outputs. This is a practical extension of conformal prediction to sequential prefixes and could serve as a bridge between process supervision, abstention, and repair in LLM pipelines. The suggestion to evaluate verifiers by certified prefix length rather than AUROC is a useful reframing, though its impact depends on the strength of the empirical results.
minor comments (3)
- The abstract states the conformal guarantee follows from the standard argument once exchangeability is assumed, but the manuscript should explicitly state the precise conformal score function (e.g., whether it is the maximum risk proxy in the prefix or another aggregation) and the exact form of the threshold calibration in the main text or an appendix.
- Section describing the experimental setup should include quantitative results on certified prefix lengths, error rates, and repair accuracy improvements with confidence intervals or statistical tests to allow assessment of practical effect sizes.
- The paper should clarify whether the exchangeability assumption is intended to hold at the level of full traces, individual steps, or risk-proxy sequences, and discuss any sensitivity analysis or diagnostics for this assumption.
Simulated Author's Rebuttal
We thank the referee for their positive and constructive review, which accurately summarizes the core contribution of CROP and recommends minor revision. We appreciate the recognition that the marginal guarantee under exchangeability offers a statistically grounded approach to prefix certification, and that evaluating verifiers by certified prefix length rather than AUROC is a useful reframing. No specific major comments were provided in the report, so we will incorporate minor improvements to clarity, presentation, and any suggested refinements in the revised manuscript.
Circularity Check
No significant circularity identified
full rationale
The paper's central guarantee is explicitly conditional on the exchangeability assumption and is presented as a direct application of the standard conformal prediction marginal coverage result to the longest clean prefix construction. No equations or procedures in the provided abstract reduce a claimed prediction or uniqueness result to a fitted parameter or self-citation defined inside the paper; the risk-proxy threshold calibration follows the usual nonconformity score ordering without internal redefinition. External conformal theory supplies the coverage property once exchangeability holds, satisfying the criteria for an independent, non-circular derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Exchangeability of the reasoning traces or their risk proxies
invented entities (1)
-
CROP procedure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[2]
Generating with confidence: Uncertainty quantification for black-box large language models.Transactions on Machine Learning Research, 2024
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quantification for black-box large language models.Transactions on Machine Learning Research, 2024
2024
-
[3]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations, volume 2024, pages 39578–39601, 2024
2024
-
[4]
Know what you don’t know: Uncertainty calibration of process reward models.Advances in Neural Information Processing Systems, 38:38852–38895, 2025
Young-Jin Park, Kristjan Greenewald, Kaveh Alimohammadi, Hao Wang, and Navid Azizan. Know what you don’t know: Uncertainty calibration of process reward models.Advances in Neural Information Processing Systems, 38:38852–38895, 2025
2025
-
[5]
Conformal prediction for natural language processing: A survey.Transactions of the Association for Computational Linguistics, 12:1497–1516, 2024
Margarida Campos, António Farinhas, Chrysoula Zerva, Mário AT Figueiredo, and André FT Martins. Conformal prediction for natural language processing: A survey.Transactions of the Association for Computational Linguistics, 12:1497–1516, 2024
2024
-
[6]
arXiv preprint arXiv:2305.18404 , year=
Bhawesh Kumar, Charlie Lu, Gauri Gupta, Anil Palepu, David Bellamy, Ramesh Raskar, and Andrew Beam. Conformal prediction with large language models for multi-choice question answering.arXiv preprint arXiv:2305.18404, 2023. 11
-
[7]
Conformal language modeling
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi Jaakkola, and Regina Barzilay. Conformal language modeling. InInternational Conference on Learning Representations, volume 2024, pages 11654–11681, 2024
2024
-
[8]
Language models with conformal factuality guarantees
Christopher Mohri and Tatsunori Hashimoto. Language models with conformal factuality guarantees. InForty-first International Conference on Machine Learning, 2024
2024
-
[9]
Mitigating LLM hallucinations via conformal abstention.arXiv preprint arXiv:2405.01563,
Yasin Abbasi Yadkori, Ilja Kuzborskij, David Stutz, András György, Adam Fisch, Arnaud Doucet, Iuliya Beloshapka, Wei-Hung Weng, Yao-Yuan Yang, Csaba Szepesvári, et al. Mitigating llm hallucinations via conformal abstention.arXiv preprint arXiv:2405.01563, 2024
-
[10]
Veri- fying chain-of-thought reasoning via its computational graph
Zheng Zhao, Yeskendir Koishekenov, Xianjun Yang, Naila Murray, and Nicola Cancedda. Veri- fying chain-of-thought reasoning via its computational graph. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id= CxiNICq0Rr
2026
-
[11]
Processbench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1009–1024, 2025
2025
-
[12]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
2024
-
[13]
Prmbench: A fine- grained and challenging benchmark for process-level reward models
Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, and Yu Cheng. Prmbench: A fine- grained and challenging benchmark for process-level reward models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25299–25346, 2025
2025
-
[14]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Teaching models to express their uncertainty in words.Transactions on Machine Learning Research, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.Transactions on Machine Learning Research, 2022
2022
-
[16]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages ...
2023
-
[17]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[18]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023. 12
2023
-
[19]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017, 2023
2023
-
[20]
The internal state of an llm knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, 2023
2023
-
[21]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025
2025
-
[22]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Premise-augmented reasoning chains improve error identification in math reasoning with llms
Sagnik Mukherjee, Abhinav Chinta, Takyoung Kim, Tarun Anoop Sharma, and Dilek Hakkani Tur. Premise-augmented reasoning chains improve error identification in math reasoning with llms. InForty-second International Conference on Machine Learning, 2025
2025
-
[25]
Xiao-Wen Yang, Xuan-Yi Zhu, Wen-Da Wei, Ding-Chu Zhang, Jie-Jing Shao, Zhi Zhou, Lan-Zhe Guo, and Yu-Feng Li. Step back to leap forward: Self-backtracking for boosting reasoning of language models.arXiv preprint arXiv:2502.04404, 2025
-
[26]
To backtrack or not to backtrack: When sequential search limits model reasoning
Tian Qin, David Alvarez-Melis, Samy Jelassi, and Eran Malach. To backtrack or not to backtrack: When sequential search limits model reasoning. InSecond Conference on Language Modeling, 2025
2025
-
[27]
Hongyi James Cai, Junlin Wang, Xiaoyin Chen, and Bhuwan Dhingra. How much backtracking is enough? exploring the interplay of sft and rl in enhancing llm reasoning.arXiv preprint arXiv:2505.24273, 2025
-
[28]
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars
Kanishk Gandhi, Ayush K Chakravarthy, Anikait Singh, Nathan Lile, and Noah Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars. InSecond Conference on Language Modeling, 2025
2025
-
[29]
Backtracking improves generation safety
Yiming Zhang, Jianfeng Chi, Hailey Nguyen, Kartikeya Upasani, Daniel Bikel, Jason E Weston, and Eric Michael Smith. Backtracking improves generation safety. InInternational Conference on Learning Representations, volume 2025, pages 41156–41173, 2025
2025
-
[30]
Backtracking for safety.arXiv preprint arXiv:2503.08919, 2025
Bilgehan Sel, Dingcheng Li, Phillip Wallis, Vaishakh Keshava, Ming Jin, and Siddhartha Reddy Jonnalagadda. Backtracking for safety.arXiv preprint arXiv:2503.08919, 2025
-
[31]
Springer, 2005
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world. Springer, 2005
2005
-
[32]
Conformal prediction: a unified review of theory and new challenges.Bernoulli, 29(1):1–23, 2023
Matteo Fontana, Gianluca Zeni, and Simone Vantini. Conformal prediction: a unified review of theory and new challenges.Bernoulli, 29(1):1–23, 2023. 13
2023
-
[33]
A tutorial on conformal prediction.Journal of machine learning research, 9(3), 2008
Glenn Shafer and Vladimir Vovk. A tutorial on conformal prediction.Journal of machine learning research, 9(3), 2008
2008
-
[34]
Conformal prediction: A gentle introduction
Anastasios N Angelopoulos and Stephen Bates. Conformal prediction: A gentle introduction. Foundations and Trends in Machine Learning, 16(4):494–591, 2023
2023
-
[35]
Theoretical Foundations of Conformal Prediction
Anastasios N Angelopoulos, Rina Foygel Barber, and Stephen Bates. Theoretical foundations of conformal prediction.arXiv preprint arXiv:2411.11824, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Conformal risk control
Anastasios Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Conformal risk control. InInternational conference on learning representations, volume 2024, pages 55198–55218, 2024
2024
-
[37]
Prune’n predict: Optimizing llm decision-making with conformal prediction
Harit Vishwakarma, Alan Mishler, Thomas Cook, Niccolo Dalmasso, Natraj Raman, and Sumitra Ganesh. Prune’n predict: Optimizing llm decision-making with conformal prediction. InInternational Conference on Machine Learning, pages 61601–61634. PMLR, 2025
2025
-
[38]
Non-exchangeable conformal language generation with nearest neighbors
Dennis Ulmer, Chrysoula Zerva, and André FT Martins. Non-exchangeable conformal language generation with nearest neighbors. InFindings of the Association for Computational Linguistics: EACL 2024, pages 1909–1929, 2024
2024
-
[39]
Conu: Conformal uncertainty in large language models with correctness coverage guarantees
Zhiyuan Wang, Jinhao Duan, Lu Cheng, Yue Zhang, Qingni Wang, Xiaoshuang Shi, Kaidi Xu, Heng Tao Shen, and Xiaofeng Zhu. Conu: Conformal uncertainty in large language models with correctness coverage guarantees. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6886–6898, 2024
2024
-
[40]
Do large language models know when not to answer in medical qa? InProceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025), pages 27–35, 2025
Sravanthi Machcha, Sushrita Yerra, Sharmin Sultana, Hong Yu, and Zonghai Yao. Do large language models know when not to answer in medical qa? InProceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025), pages 27–35, 2025
2025
-
[41]
Conformal language model reasoning with coherent factuality
Maxon Rubin-Toles, Maya Gambhir, Keshav Ramji, Aaron Roth, and Surbhi Goel. Conformal language model reasoning with coherent factuality. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[42]
Large language model validity via enhanced conformal prediction methods.Advances in Neural Information Processing Systems, 37:114812–114842, 2024
John J Cherian, Isaac Gibbs, and Emmanuel J Candès. Large language model validity via enhanced conformal prediction methods.Advances in Neural Information Processing Systems, 37:114812–114842, 2024
2024
-
[43]
A survey on llm-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.The Innovation, 2024
2024
-
[44]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[45]
Latent space chain-of- embedding enables output-free llm self-evaluation
Yiming Wang, Pei Zhang, Baosong Yang, Derek Wong, and Rui Wang. Latent space chain-of- embedding enables output-free llm self-evaluation. InInternational Conference on Learning Representations, volume 2025, pages 70938–70970, 2025
2025
-
[46]
Gemma 4 model card
Google. Gemma 4 model card. https://ai.google.dev/gemma/docs/core/model_card_4,
-
[47]
Accessed 2026-05-19. 14
2026
-
[48]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[49]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Jinhe Bi, Danqi Yan, Yifan Wang, Wenke Huang, Haokun Chen, Guancheng Wan, Mang Ye, Xun Xiao, Hinrich Schuetze, Volker Tresp, et al. Cot-kinetics: A theoretical modeling assessing lrm reasoning process.arXiv preprint arXiv:2505.13408, 2025. A Proofs We give the details for Lemma 1. We treat all training data, fitted risk proxy functions, preprocessing choi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.