Social Reasoning in Machines: Investigating Collective Truth-Seeking Dynamics in Large Language Model Debate
Pith reviewed 2026-06-29 00:01 UTC · model grok-4.3
The pith
When LLMs are engineered for epistemic diversity, their multi-agent adversarial debates improve truth-seeking on questionnaires even if individuals perform poorly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Simulating ATR through LLM multi-agent debate shows that an epistemically diverse set of models produces significantly better truth-seeking results on questionnaires than isolated models, with the improvement mechanistically linked to adversarial debate principles, indicating collective reasoning can be advantageous beyond biological systems.
What carries the argument
LLM-MAD, the multi-agent debate protocol in which LLMs engage in adversarial discourse engineered for epistemic diversity to replicate ATR conditions.
Load-bearing premise
Performance gains come specifically from ATR-style adversarial debate rather than model selection, prompting, or statistical aggregation.
What would settle it
A controlled experiment that holds model selection and prompting fixed while removing the adversarial debate format and still observes the same accuracy gains would falsify the central claim.
Figures


read the original abstract
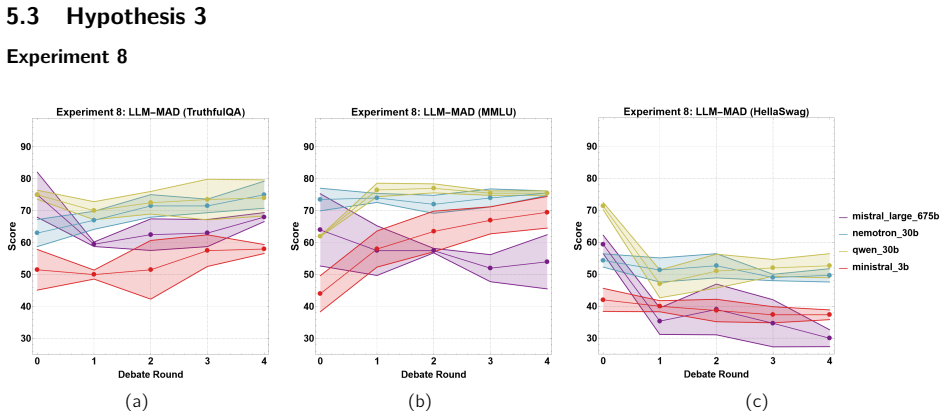
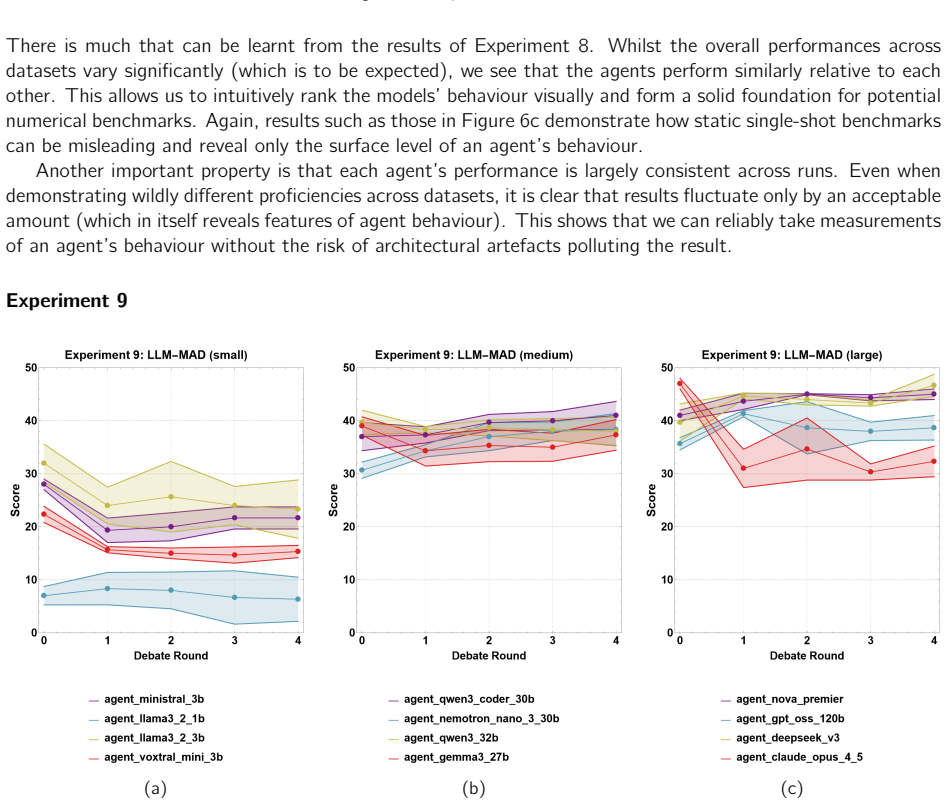
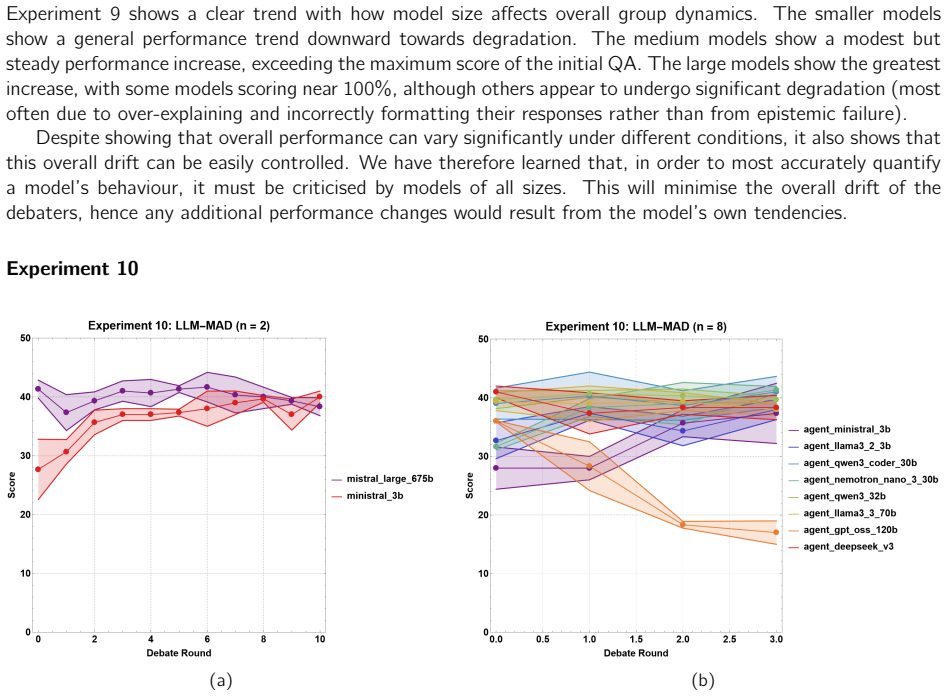
Human reasoning has long been theorised to operate socially, not through isolated individual cognition, but through collective adversarial discourse, a framework known as the Argumentative Theory of Reasoning (ATR). Rather than relying on individual "intellectualist reasoners" as the primary vehicle for truth-seeking, ATR reconceptualises truth as an emergent property of social epistemology: the product of imperfect individual reasoning refined under the adversarial pressure of debate. This distributed method of collective intelligence has guided humanity to ever-greater epistemic heights and underpins the foundational principles of all democratic systems. This thesis breaks new ground by, for the first time, simulating ATR through the multi-agent debate (MAD) of large language models (LLMs). With rigorous empirical analysis, we demonstrate that, when correctly engineering an epistemically diverse set of models, LLM-MAD can significantly improve truth-seeking performance on questionnaire-based tasks, even when individual debate participants exhibit limited standalone performance. Furthermore, we present strong empirical evidence that this performance gain is mechanistically grounded in the central principles of ATR, suggesting that collective reasoning may be universally favourable over individualist reasoning, rather than a quirk in biology or evolution. Finally, drawing on our analysis of debate dynamics, we propose a novel benchmarking methodology that leverages LLM-MAD to measure intrinsic model properties (such as hallucination propensity) in order to compare models in ways that current static benchmarking approaches cannot support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to be the first simulation of the Argumentative Theory of Reasoning (ATR) via multi-agent debate (MAD) among large language models. It asserts that engineering an epistemically diverse set of LLMs enables LLM-MAD to significantly improve truth-seeking performance on questionnaire-based tasks even when individual models show limited standalone performance, that this gain is mechanistically grounded in ATR principles, and that debate dynamics can be used to propose a novel benchmarking methodology for measuring intrinsic model properties such as hallucination propensity.
Significance. If the empirical claims were supported by detailed methods, controls, ablations, and statistical evidence, the work would offer notable significance for multi-agent systems research by linking cognitive science theories to LLM collective reasoning and by suggesting new evaluation paradigms beyond static benchmarks. It could inform designs for improving truthfulness in AI through adversarial mechanisms.
major comments (2)
- [Abstract] Abstract: The abstract states claims of 'rigorous empirical analysis' and 'strong empirical evidence' that LLM-MAD improves truth-seeking and that gains are mechanistically grounded in ATR, but supplies no experimental details, model specifications, tasks, diversity metrics, controls, ablations, or statistical tests. Without these, the central empirical claims cannot be evaluated.
- [Abstract] Abstract: The assertion that performance gains are 'mechanistically grounded in the central principles of ATR' risks circularity, as no independent verification of the mechanism (e.g., explicit metrics for epistemic diversity or debate dynamics separate from the performance outcome) is described; diversity could be defined or selected post-hoc to match observed results.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. We address each point below and clarify how the manuscript supports its claims with details provided in the full text.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states claims of 'rigorous empirical analysis' and 'strong empirical evidence' that LLM-MAD improves truth-seeking and that gains are mechanistically grounded in ATR, but supplies no experimental details, model specifications, tasks, diversity metrics, controls, ablations, or statistical tests. Without these, the central empirical claims cannot be evaluated.
Authors: The abstract is intentionally concise as a high-level summary of contributions. The full manuscript details the experimental setup in dedicated Methods and Results sections, including specific LLMs used, questionnaire tasks, epistemic diversity metrics (defined via pre-debate disagreement and knowledge variance), controls, ablations, and statistical tests. These elements are reported with full transparency to allow evaluation of the claims. revision: partial
-
Referee: [Abstract] Abstract: The assertion that performance gains are 'mechanistically grounded in the central principles of ATR' risks circularity, as no independent verification of the mechanism (e.g., explicit metrics for epistemic diversity or debate dynamics separate from the performance outcome) is described; diversity could be defined or selected post-hoc to match observed results.
Authors: Epistemic diversity is operationalized independently via pre-defined metrics on model disagreement patterns and knowledge base differences measured before any debate occurs. Debate dynamics (argument exchange, convergence rates) are tracked and analyzed separately from final accuracy outcomes in dedicated analysis sections. This separation provides independent verification that observed gains align with ATR mechanisms rather than post-hoc fitting. revision: no
Circularity Check
No significant circularity identified
full rationale
The provided abstract and context contain no derivation chain, equations, fitted parameters called predictions, or self-citations that reduce any claimed result to its inputs by construction. Claims rest on empirical demonstration of performance gains from engineered epistemic diversity in LLM-MAD, with no quoted reduction (e.g., no self-definitional loop or ansatz smuggled via prior work) visible in the text. The full manuscript is referenced but not supplied, precluding identification of any load-bearing circular step under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Argumentative Theory of Reasoning accurately describes human truth-seeking
Reference graph
Works this paper leans on
-
[1]
Why do humans reason? arguments for an argumentative theory
Hugo Mercier and Dan Sperber. Why do humans reason? arguments for an argumentative theory. Behavioral and brain sciences, 34(2):57–74, 2011
2011
-
[2]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models.CoRR, abs/2201.11903, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Simple and scalable predictive uncertainty estimation using deep ensembles, 2017
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles, 2017
2017
-
[4]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, March 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, March 2023
2023
-
[5]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022
2022
-
[6]
Halueval: A large-scale hallucination evaluation benchmark for large language models
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. Halueval: A large-scale hallucination evaluation benchmark for large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 6449–6464, 2023
2023
-
[7]
Gaming truthfulqa: Simple heuristics exposed - dataset weaknesses
Alex Turner and Mark Kurzeja. Gaming truthfulqa: Simple heuristics exposed - dataset weaknesses. https://turntrout.com/original-truthfulqa-weaknesses, 2025. Accessed: 2025-11-12
2025
-
[8]
Reasoning, biases and dual processes: The lasting impact of wason (1960)
Jonathan St BT Evans. Reasoning, biases and dual processes: The lasting impact of wason (1960). Quarterly journal of experimental psychology, 69(10):2076–2092, 2016
1960
-
[9]
Stop fooling yourself! (diagnosing and treating confirmation bias).ENeuro, 11(10), 2024
Richard T Born. Stop fooling yourself! (diagnosing and treating confirmation bias).ENeuro, 11(10), 2024
2024
-
[10]
Harvard university press, 2017
Hugo Mercier and Dan Sperber.The enigma of reason. Harvard university press, 2017
2017
-
[11]
The selective laziness of reasoning
Emmanuel Trouche, Petter Johansson, Lars Hall, and Hugo Mercier. The selective laziness of reasoning. Cognitive science, 40(8):2122–2136, 2016
2016
-
[12]
Reasoning about a rule.Quarterly journal of experimental psychology, 20(3):273–281, 1968
Peter C Wason. Reasoning about a rule.Quarterly journal of experimental psychology, 20(3):273–281, 1968
1968
-
[13]
Collaborative reasoning: Evidence for collective rationality.Thinking & Reasoning, 4(3):231–248, 1998
David Moshman and Molly Geil. Collaborative reasoning: Evidence for collective rationality.Thinking & Reasoning, 4(3):231–248, 1998
1998
-
[14]
Stanovich and Richard F
Keith E. Stanovich and Richard F. West. Individual differences in reasoning: Implications for the rationality debate?Behavioral and Brain Sciences, 23(5):645–665, 2000
2000
-
[15]
The future of reasoning
Michael Stevens. The future of reasoning. YouTube, April 2021. Available at:https://youtu.be/ ˙ArVh3Cj9rw(Accessed on 08/12/2025)
2021
-
[16]
Does the chimpanzee have a theory of mind?Behavioral and brain sciences, 1(4):515–526, 1978
David Premack and Guy Woodruff. Does the chimpanzee have a theory of mind?Behavioral and brain sciences, 1(4):515–526, 1978
1978
-
[17]
Metarepresentations in an evolutionary perspective.Metarepresentations: A multidisciplinary perspective, 10:117–137, 2000
Dan Sperber. Metarepresentations in an evolutionary perspective.Metarepresentations: A multidisciplinary perspective, 10:117–137, 2000
2000
-
[18]
Epistemic vigilance.Mind & language, 25(4):359–393, 2010
Dan Sperber, Fabrice Cl´ ement, Christophe Heintz, Olivier Mascaro, Hugo Mercier, Gloria Origgi, and Deirdre Wilson. Epistemic vigilance.Mind & language, 25(4):359–393, 2010. 42
2010
-
[19]
Argumentation evolved: But how? coevolution of coordinated group behavior and reasoning
Fabian Seitz. Argumentation evolved: But how? coevolution of coordinated group behavior and reasoning. Argumentation, 34(2):237–260, 2020
2020
-
[20]
On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games.Artificial intelligence, 77(2):321–357, 1995
Phan Minh Dung. On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games.Artificial intelligence, 77(2):321–357, 1995
1995
-
[21]
The aspic+ framework for structured argumentation: a tutorial
Sanjay Modgil and Henry Prakken. The aspic+ framework for structured argumentation: a tutorial. Argument & Computation, 5(1):31–62, 2014
2014
-
[22]
An assumption-based framework for non-monotonic reasoning
Andrei Bondarenko, Francesca Toni, and Robert A Kowalski. An assumption-based framework for non-monotonic reasoning. InLPNMR, volume 93, pages 171–189, 1993
1993
-
[23]
Latent debate: A surrogate framework for interpreting llm thinking, 2026
Lihu Chen, Xiang Yin, and Francesca Toni. Latent debate: A surrogate framework for interpreting llm thinking, 2026
2026
-
[24]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger, editors,Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc., 2014
2014
-
[25]
Ai safety via debate, 2018
Geoffrey Irving, Paul Christiano, and Dario Amodei. Ai safety via debate, 2018
2018
-
[26]
Mechanism design for abstract argumentation
Iyad Rahwan and Kate Larson. Mechanism design for abstract argumentation. In7th International Joint Conference on Autonomous Agents and Multiagent Systems, pages 1031–1038. International Foundation for Autonomous Agents and Multiagent Systems, 2008
2008
-
[27]
Argmed-agents: Explainable clinical decision reasoning with llm disscusion via argumentation schemes
Shengxin Hong, Liang Xiao, Xin Zhang, and Jianxia Chen. Argmed-agents: Explainable clinical decision reasoning with llm disscusion via argumentation schemes. In2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 5486–5493. IEEE, 2024
2024
-
[28]
Theory of mind for multi-agent collaboration via large language models
Huao Li, Yu Chong, Simon Stepputtis, Joseph P Campbell, Dana Hughes, Charles Lewis, and Katia Sycara. Theory of mind for multi-agent collaboration via large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 180–192, 2023
2023
-
[29]
Peacemaker or troublemaker: How sycophancy shapes multi-agent debate, 2025
Binwei Yao, Chao Shang, Wanyu Du, Jianfeng He, Ruixue Lian, Yi Zhang, Hang Su, Sandesh Swamy, and Yanjun Qi. Peacemaker or troublemaker: How sycophancy shapes multi-agent debate, 2025
2025
-
[30]
Improving factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
2024
-
[31]
Yan Zhou and Yanguang Chen. Adaptive heterogeneous multi-agent debate for enhanced educational and factual reasoning in large language models.Journal of King Saud University Computer and Information Sciences, 37(10):330, 2025
2025
-
[32]
Encouraging divergent thinking in large language models through multi-agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi-agent debate. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 17889–17904, 2024
2024
-
[33]
Chateval: Towards better llm-based evaluators through multi-agent debate, 2023
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate, 2023
2023
-
[34]
Barrett, and Arnu Pretorius
Andries Smit, Paul Duckworth, Nathan Grinsztajn, Thomas D. Barrett, and Arnu Pretorius. Should we be going mad? a look at multi-agent debate strategies for llms, 2024
2024
-
[35]
A debate-driven experiment on llm hallucinations and accuracy, 2024
Ray Li, Tanishka Bagade, Kevin Martinez, Flora Yasmin, Grant Ayala, Michael Lam, and Kevin Zhu. A debate-driven experiment on llm hallucinations and accuracy, 2024. 43
2024
-
[36]
Interpreting and mitigating hallucination in mllms through multi-agent debate, 2024
Zheng Lin, Zhenxing Niu, Zhibin Wang, and Yinghui Xu. Interpreting and mitigating hallucination in mllms through multi-agent debate, 2024
2024
-
[37]
Enhancing hallucination detection in large language models through a dual-position debate multi-agent framework.International Conference on Intelligent Computing, 2025
Qile He and Siting Le. Enhancing hallucination detection in large language models through a dual-position debate multi-agent framework.International Conference on Intelligent Computing, 2025
2025
-
[38]
Confidencecal: Enhancing llms reliability through confidence calibration in multi-agent debate
Yilin Bai. Confidencecal: Enhancing llms reliability through confidence calibration in multi-agent debate. In2024 10th International Conference on Big Data and Information Analytics (BigDIA), pages 221–226. IEEE, 2024
2024
-
[39]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[40]
The hidden strength of disagreement: Unraveling the consensus-diversity tradeoff in adaptive multi-agent systems
Zengqing Wu and Takayuki Ito. The hidden strength of disagreement: Unraveling the consensus-diversity tradeoff in adaptive multi-agent systems. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15288–15308, 2025
2025
-
[41]
The truth becomes clearer through debate! multi-agent systems with large language models unmask fake news
Yuhan Liu, Yuxuan Liu, Xiaoqing Zhang, Xiuying Chen, and Rui Yan. The truth becomes clearer through debate! multi-agent systems with large language models unmask fake news. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 504–514, 2025
2025
-
[42]
When truth is overridden: Uncovering the internal origins of sycophancy in large language models
Keyu Wang, Jin Li, Shu Yang, Zhuoran Zhang, and Di Wang. When truth is overridden: Uncovering the internal origins of sycophancy in large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33566–33574, 2026
2026
-
[43]
Improving multi-agent debate with sparse communication topology
Yunxuan Li, Yibing Du, Jiageng Zhang, Le Hou, Peter Grabowski, Yeqing Li, and Eugene Ie. Improving multi-agent debate with sparse communication topology. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7281–7294, 2024
2024
-
[44]
Measuring massive multitask language understanding, 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021
2021
-
[45]
Hellaswag: Can a machine really finish your sentence?, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?, 2019
2019
-
[46]
Llm benchmarks: The saturation and contamination problem, 2024
LXT.ai. Llm benchmarks: The saturation and contamination problem, 2024. Available at:https: //www.lxt.ai/blog/llm-benchmarks/(Accessed on 1/5/2026)
2024
-
[47]
Livebench: A challenging, contamination-limited llm benchmark, 2025
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. Livebench: A challenging, contamination-limited llm benchmark, 2025
2025
-
[48]
Vempala, and Edwin Zhang
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. Why language models hallucinate, 2025
2025
-
[49]
Ezra Karger, Houtan Bastani, Chen Yueh-Han, Zachary Jacobs, Danny Halawi, Fred Zhang, and Philip E. Tetlock. Forecastbench: A dynamic benchmark of ai forecasting capabilities, 2025
2025
-
[50]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, 2023
2023
-
[51]
Snow White and the Seven Dwarfs
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline, 2024. 44 Appendices Appendix I: Prompt Templates Initial QA Prompt Example THE FOLLOWING IS A LOG OF QUESTIONS YOU HA VE ANSWERED, CRITIQUES OF YOUR ANSWER...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.