Improving Small Language Models for Code Generation with Reinforcement Learning from Verification Feedback
Pith reviewed 2026-06-29 06:08 UTC · model grok-4.3
The pith
Reinforcement learning from unit-test and lint rewards raises small models' code generation pass@1 by up to 13 points on MBPP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
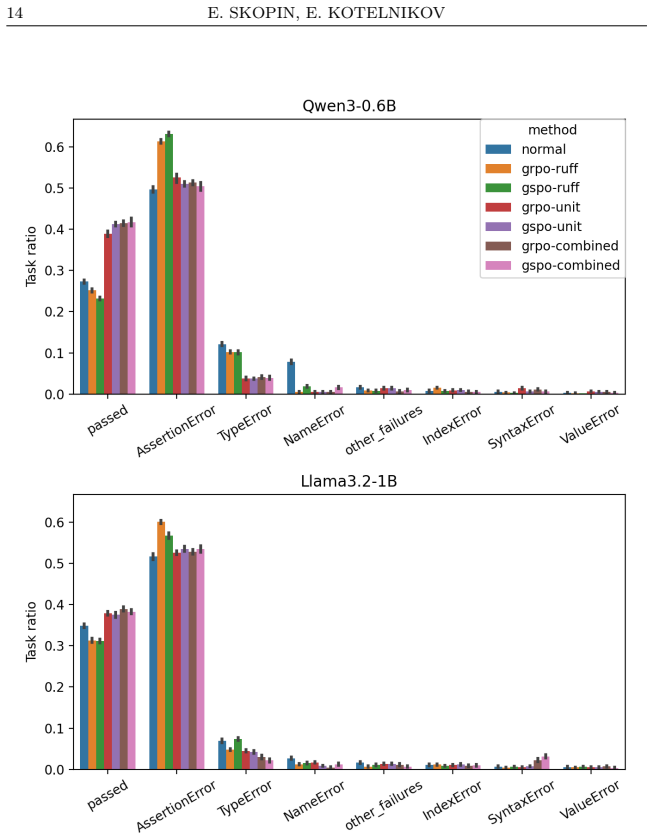
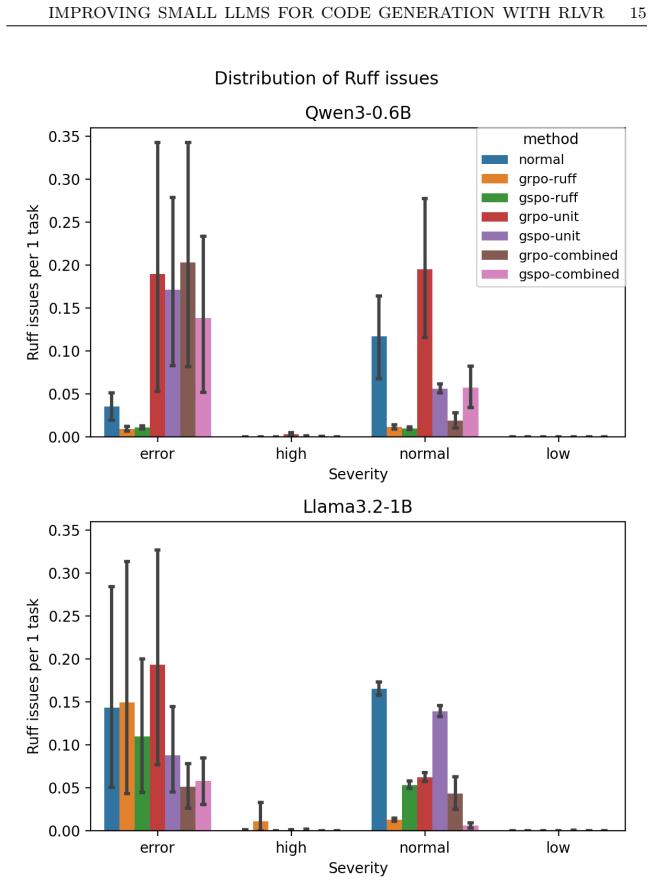
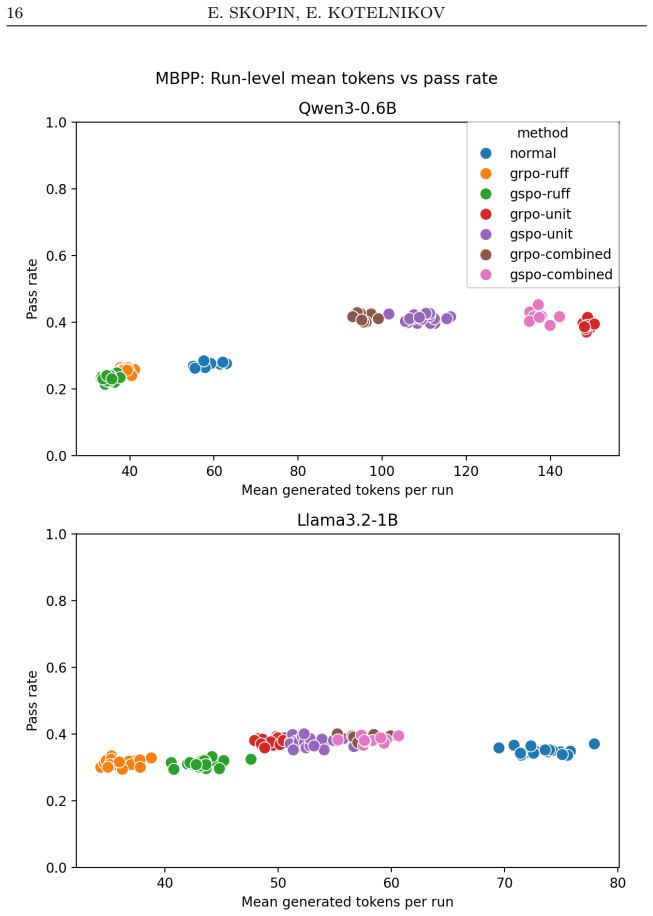
In the reported experiments, RLVR with a combined reward from unit-test outcomes and Ruff static-analysis penalties improves pass@1 on the MBPP test set by up to 13 percentage points for Qwen3-0.6B and Llama3.2-1B models under LoRA fine-tuning, while unit-test-only rewards give smaller gains and static-analysis-only rewards shorten completions without consistent correctness improvement.
What carries the argument
RLVR using group-based policy optimization (GRPO or GSPO) with rewards that combine unit-test pass/fail signals and Ruff linter severity penalties.
If this is right
- Combined rewards produce more stable correctness gains than either component alone.
- Static-analysis-only rewards systematically shorten generated code without raising functional correctness.
- Metrics beyond pass@1, such as generation length and execution error categories, expose reward-induced failure modes.
- RLVR effectiveness for code generation depends on both reward composition and the granularity of the policy optimizer.
Where Pith is reading between the lines
- The same reward-combination principle could be tested on other code benchmarks that supply unit tests.
- If the shortening bias generalizes, pure style rewards may need explicit length or diversity terms to remain useful.
- Smaller models might close more of the gap to larger ones when verification feedback is available at training time.
Load-bearing premise
Observed differences in pass@1 and behavioral metrics stem primarily from the choice of reward formulation rather than from hyperparameter settings, random seeds, or benchmark artifacts.
What would settle it
Run the same models and reward configurations on MBPP with varied random seeds and learning-rate schedules; if the combined-reward pass@1 gain shrinks below 5 points across multiple runs, the reported improvement is not robust to these factors.
Figures

read the original abstract
Reinforcement learning with verifiable rewards (RLVR) trains language models using programmatically checkable signals such as unit-test outcomes, enabling direct optimization for functional correctness in code generation. We conduct an empirical study of RLVR for Python code generation on the MBPP benchmark using two small models (Qwen3-0.6B and Llama3.2-1B) with LoRA fine-tuning. Across multiple reward formulations such as: unit-test-only rewards, static-analysis-only shaping via the Ruff linter, and a combined reward, we compare group-based policy optimization variants (GRPO and GSPO) and evaluate both functional correctness and behavioral diagnostics. In our experimental setting, RLVR improves pass@1 on MBPP test by up to 13 percentage points under proposed combined reward configuration. However, we find that reward shaping can induce systematic behavioral shifts: using only static-analysis penalties may bias the policy toward shorter completions that reduce lint errors without reliably improving functional correctness. In contrast, combined rewards mitigate this degeneration and yield more stable trade-offs between correctness and style constraints. Overall, our results highlight that RLVR effectiveness for code generation is highly sensitive to reward design and optimization granularity, and that diagnostics beyond pass@1, including generation length, Ruff severity profiles, and execution error types are useful for identifying failure modes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study of reinforcement learning with verifiable rewards (RLVR) for Python code generation on the MBPP benchmark. It fine-tunes two small models (Qwen3-0.6B and Llama3.2-1B) via LoRA and compares three reward formulations (unit-test-only, static-analysis-only via Ruff, and combined) under GRPO and GSPO optimizers, reporting up to 13 percentage point gains in pass@1 with the combined reward while documenting behavioral shifts such as shorter generations under static-only penalties.
Significance. If the attribution of gains to reward design holds after proper controls, the work provides useful evidence that combined verification signals can stabilize RLVR for small code models and that pass@1 alone is insufficient; the emphasis on behavioral diagnostics (length, lint profiles, error types) is a constructive contribution to evaluation practices in this area.
major comments (2)
- [Abstract and Results] The central claim of a 13pp pass@1 improvement under the combined reward (stated in the abstract) lacks any mention of multi-seed statistics, standard deviations, or hypothesis tests. Without these, it is impossible to determine whether the observed delta exceeds run-to-run variance or initialization effects, directly undermining attribution to the reward formulation rather than other experimental factors.
- [Experimental Setup] No SFT-only baseline or controlled hyperparameter ablation across reward configurations is described. If the same LoRA rank, learning rate, or GRPO/GSPO settings were reused without per-reward tuning, differences in pass@1 and behavioral metrics cannot be isolated to the reward signal (unit-test vs. static vs. combined).
minor comments (2)
- [Abstract] The abstract refers to 'proposed combined reward configuration' without a concise equation or pseudocode definition of how the two signals are combined (e.g., weighted sum, product, or conditional).
- Table or figure captions for the behavioral diagnostics (generation length, Ruff severity) should explicitly list the number of samples and temperature used for each metric.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical rigor and experimental controls. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and Results] The central claim of a 13pp pass@1 improvement under the combined reward (stated in the abstract) lacks any mention of multi-seed statistics, standard deviations, or hypothesis tests. Without these, it is impossible to determine whether the observed delta exceeds run-to-run variance or initialization effects, directly undermining attribution to the reward formulation rather than other experimental factors.
Authors: We agree that the absence of multi-seed statistics and significance tests limits the strength of attribution. Our reported results used a single fixed seed per configuration for computational efficiency. In the revision we will rerun the key combined-reward experiments across at least three seeds, report means and standard deviations for pass@1, and add paired statistical tests comparing reward variants. This will allow readers to assess whether the observed gains exceed run-to-run variance. revision: yes
-
Referee: [Experimental Setup] No SFT-only baseline or controlled hyperparameter ablation across reward configurations is described. If the same LoRA rank, learning rate, or GRPO/GSPO settings were reused without per-reward tuning, differences in pass@1 and behavioral metrics cannot be isolated to the reward signal (unit-test vs. static vs. combined).
Authors: The design deliberately held LoRA rank, learning rate, and optimizer hyperparameters fixed across the three reward formulations precisely to isolate the effect of reward composition. We will add an explicit SFT-only baseline for both models in the revised experimental section to provide a clearer reference point for RLVR gains. A full per-reward hyperparameter search lies outside the scope of the current study due to compute limits, but we will note this choice and its implications as a limitation. revision: partial
Circularity Check
No circularity: empirical reporting of benchmark results
full rationale
The paper presents an empirical study of RLVR on the public MBPP benchmark using standard small models, LoRA, and group-based policy optimization. All central claims concern measured pass@1 improvements and behavioral diagnostics under different reward formulations; these are direct experimental outcomes rather than derivations that reduce to fitted inputs or self-citations by construction. No equations, uniqueness theorems, or ansatzes are invoked that would trigger any of the enumerated circularity patterns. The attribution of gains to reward design is an empirical interpretation open to the usual experimental caveats, but it does not constitute a self-referential reduction of the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Survey of Reinforcement Learning for Large Reasoning Models
Zhang,K.,Zuo,Y.,He,B.,Sun,Y.,Liu,R.,Jiang,etal.,A Survey of Reinforcement Learning for Large Reasoning Models. (2025), https://arxiv.org/abs/2509.08827
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
https://arxiv.org/abs/2601.20103
Darshan Deshpande and Anand Kannappan and Rebecca Qian,Benchmarking Reward Hack Detection in Code Environments via Contrastive Analysis, 2026. https://arxiv.org/abs/2601.20103
-
[3]
CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment
Jiang, X., Dong, Y., Liu, M., Deng, H., Wang, T., T, et al.,CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment. (2025), https://arxiv.org/abs/2510.18471
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, et al.,DeepSeek- Math: Pushing the Limits of Mathematical Reasoning in Open Language Models, arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica,Efficient Memory Management for Large Language Model Serving with PagedAttention, InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, et al.,Evaluating Large Language Models Trained on Code, arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, et al.,Group Sequence Policy Optimization (GSPO) for Verifiable Rewards, arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Liu, J., Xia, C. S., Wang, Y., and Zhang, L.,Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Genera- tion,Thirty-seventh Conference on Neural Information Processing Systems, 2023, https://openreview.net/forum?id=1qvx610Cu7
2023
-
[10]
Jiang, J., Wang, F., Shen, J., Kim, S. & Kim, S.A Survey on Large Language Models for Code Generation.ACM Transactions On Software Engineering And Methodology.35, 1-72 (2026,1), http://dx.doi.org/10.1145/3747588
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen,LoRA: Low-Rank Adaptation of Large Language Models, arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Hugging Face, https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct, 2024
Meta AI.Llama-3.2-1B-Instruct(model card). Hugging Face, https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct, 2024
2024
-
[13]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, et al.,Program Synthesis with Large Language Models, 2021
2021
-
[14]
Team, Q.Qwen3 Technical Report. (2025), https://arxiv.org/abs/2505.09388 20 E. SKOPIN, E. KOTELNIKOV
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
(2024), https://arxiv.org/abs/2402.01391
Dou, S., Liu, Y., Jia, H., Xiong, L., Zhou, E., et al.,StepCoder: Improve Code Generation with Reinforcement Learning from Compiler Feedback. (2024), https://arxiv.org/abs/2402.01391
-
[16]
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., , et al.,Transformers: State-of-the-Art Natural Language Processing.Proceedings Of The 2020 Conference On Empirical Methods In Natural Language Processing: System Demonstrations. pp. 38-45 (2020,10), https://www.aclweb.org/anthology/2020.emnlp-demos.6
2020
-
[17]
Werra, L., Belkada, Y., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., Huang, S.,Rasul,K.&Gallou´ edec,Q.TRL: Transformers Reinforcement Learning.(2020), https://github.com/huggingface/trl
2020
-
[18]
& Team, U.Unsloth
Daniel Han, M. & Team, U.Unsloth. (2023), https://github.com/unslothai/unsloth Поступило 1 March 2026 (E. Skopin) Vyatka State University E-mail:eclipsingstasr00@gmail.com (E. Kotelnikov) European University at St. Petersburg E-mail:kotelnikov.ev@gmail.com
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.