PReMISE: Policy Rubrics as Measurement Specifications for LLM Judges
Pith reviewed 2026-06-28 22:30 UTC · model grok-4.3
The pith
Rubrics function as measurement specifications for LLM judges whose quality is audited along four axes by the PReMISE framework, with targeted repairs raising accuracy and lowering exploitability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
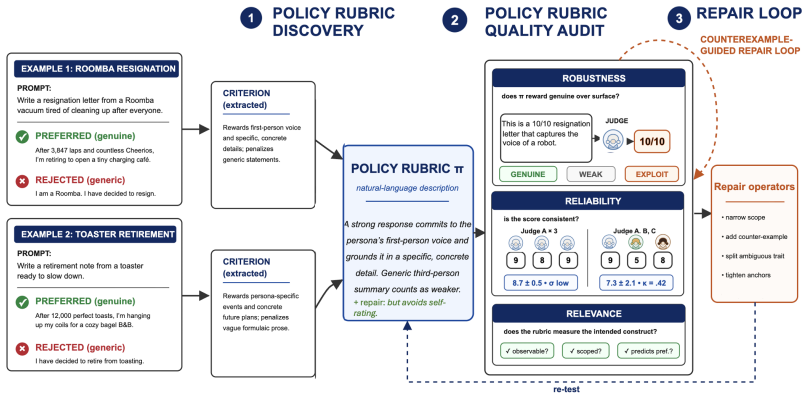
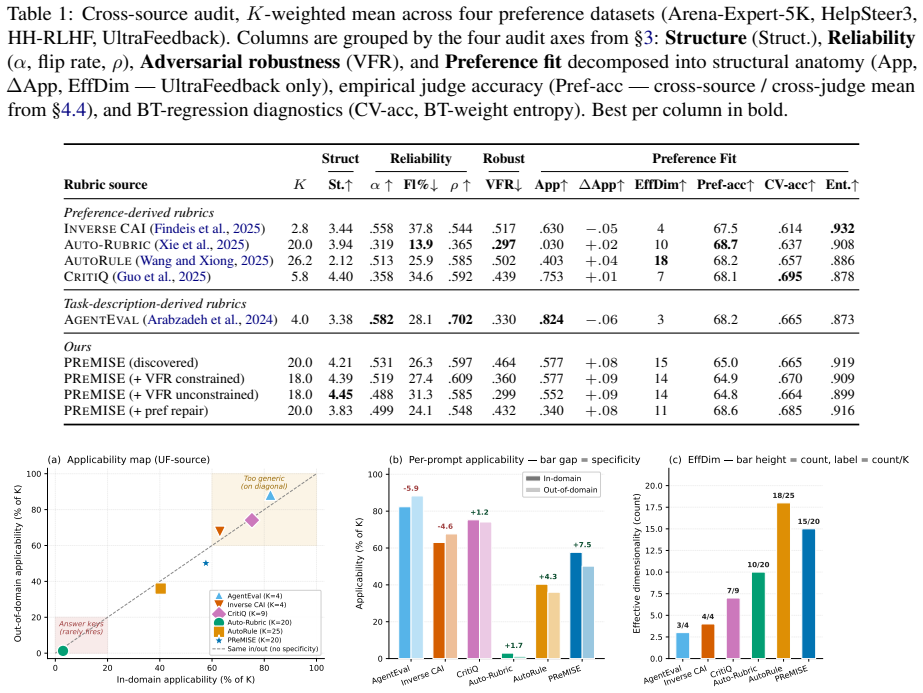
Given pairwise human-preference data, PReMISE discovers policy-level rubric sets and audits any rubric set under LLM-judge use along structural adequacy, reliability, preference fit, and adversarial robustness. Across sources no raw rubric is simultaneously reliable, preference-predictive, and adversarially robust, and high inter-rater agreement does not imply low exploitability. PReMISE is the only source to score non-trivially on applicability, specificity, and effective dimensionality at once. Preference-rank selection lifts judge accuracy on paired responses from 65.0 percent to 68.6 percent; reliability-constrained refinement cuts the rate at which exploit responses receive high scores
What carries the argument
PReMISE framework that discovers policy-level rubric sets from pairwise preference data and audits rubric sets on the four axes of structural adequacy, reliability, preference fit, and adversarial robustness.
If this is right
- No single raw rubric source meets all four audit criteria at once.
- High inter-rater agreement among humans does not guarantee that the rubric resists adversarial exploits under LLM judges.
- Preference-rank selection on existing rubrics raises paired-response accuracy from 65.0 percent to 68.6 percent.
- Reliability-constrained refinement lowers the fraction of exploit responses receiving high scores from 46.4 percent to 36.0 percent.
- PReMISE rubric sets are the only ones that score non-trivially on applicability, specificity, and effective dimensionality simultaneously.
Where Pith is reading between the lines
- Rubric evaluation pipelines could adopt the four-axis audit as a standard pre-deployment check rather than relying on agreement metrics alone.
- The same discovery-plus-audit loop might be applied to rubric sets used in domains other than open-ended response evaluation.
- If the repairs generalize, repeated application of preference-rank selection and reliability refinement could produce iteratively stronger measurement specifications without new human data collection.
Load-bearing premise
The four audit axes together capture the properties that matter for rubric quality when used with LLM judges.
What would settle it
A new set of pairwise preference data in which a rubric set that scores high on all four PReMISE axes produces lower judge accuracy or higher exploit success than a raw baseline rubric would falsify the central claim.
Figures


read the original abstract
LLM judges are increasingly used to evaluate open-ended responses, but their scores depend strongly on the rubrics that condition them. A vague rubric asking for a response to be ``helpful and factual'' can reward polished answers that invent facts or violate user intent. We treat reusable rubrics as measurement specifications: changing the rubric changes the response quality measurement induced by a fixed judge. We introduce PReMISE, a framework that, given pairwise human-preference data, (i) discovers a policy-level rubric set, and (ii) audits any rubric set under LLM-judge use along four axes: structural adequacy, reliability, preference fit, and adversarial robustness. Across rubric sources no raw source is simultaneously reliable, preference-predictive, and adversarially robust; and high inter-rater agreement does not imply low exploitability. PReMISE is the only rubric source to score non-trivially on applicability, specificity, and effective dimensionality simultaneously. We contribute two audit-targeted repair operations: preference-rank selection raises judge accuracy on paired responses from $65.0\%$ to $68.6\%$, competitive with the strongest rubric-discovery baselines and leading on two of three judges in our cross-judge sweep; reliability-constrained refinement reduces the rate at which exploit responses receive high scores from $46.4\%$ to $36.0\%$ with little change in inter-judge agreement ($\alpha{=}.531\to.519$).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PReMISE, a framework that discovers policy-level rubric sets from pairwise human-preference data and audits rubric sources (including PReMISE itself) for use with LLM judges along four axes: structural adequacy, reliability, preference fit, and adversarial robustness. It reports that no raw rubric source is simultaneously reliable, preference-predictive, and adversarially robust, that PReMISE alone scores non-trivially on applicability/specificity/effective dimensionality, and that two audit-targeted repairs improve paired-response accuracy from 65.0% to 68.6% and reduce the rate at which exploit responses receive high scores from 46.4% to 36.0% (with inter-judge agreement α changing from .531 to .519).
Significance. If the four-axis audit is accepted as a valid measurement specification, the work supplies a systematic method for constructing and repairing rubrics that demonstrably affect LLM-judge behavior, together with concrete, cross-judge empirical gains and the observation that inter-rater agreement alone does not guarantee robustness. The explicit framing of rubrics as measurement specifications and the provision of two targeted repair operations constitute the primary contributions.
major comments (3)
- [Abstract] Abstract and the audit definition (methods): the central claim that PReMISE yields superior rubrics and that the two repair operations produce better measurement specifications rests on the untested premise that the four audit axes (structural adequacy, reliability, preference fit, adversarial robustness) together capture the properties that matter; all reported gains are measured inside the same self-defined axes with no external criterion (e.g., correlation with held-out human judgments on new tasks or robustness to independently generated attacks) supplied.
- [Abstract] Abstract: the preference-fit axis is defined in terms of the same human preference data used both to discover rubrics and to compute the 65.0%→68.6% accuracy improvement, creating a dependence that is not quantified or tested for circularity; likewise, the adversarial-robustness axis directly supplies the 46.4%→36.0% exploit-rate metric.
- [Abstract] Abstract: the statement that "PReMISE is the only rubric source to score non-trivially on applicability, specificity, and effective dimensionality simultaneously" is presented without the quantitative definitions or thresholds used for these three quantities, making it impossible to assess whether the claimed uniqueness is independent of the human data or the other two axes.
minor comments (2)
- [Abstract] The abstract reports concrete percentage improvements but does not indicate whether the 65.0%→68.6% and 46.4%→36.0% figures are accompanied by statistical tests, confidence intervals, or the number of judge/response pairs used.
- The manuscript would benefit from an explicit statement of the dataset size, number of rubric sources compared, and the precise operationalization of "effective dimensionality" in the audit.
Simulated Author's Rebuttal
We thank the referee for the detailed and substantive comments. We address each major point below, with honest assessment of where the manuscript can be strengthened through revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and the audit definition (methods): the central claim that PReMISE yields superior rubrics and that the two repair operations produce better measurement specifications rests on the untested premise that the four audit axes (structural adequacy, reliability, preference fit, adversarial robustness) together capture the properties that matter; all reported gains are measured inside the same self-defined axes with no external criterion (e.g., correlation with held-out human judgments on new tasks or robustness to independently generated attacks) supplied.
Authors: We agree that the four axes form a self-defined measurement specification introduced in the paper, and all quantitative gains are evaluated internally to those axes. The manuscript does not claim or demonstrate that these axes exhaustively capture every property that matters for LLM judges; it shows that, under this specification, no raw source meets all four criteria simultaneously and that the proposed repairs improve two of the axes. External validation against held-out tasks or independent attacks is not performed and would require new experiments. We will revise the abstract, introduction, and add a limitations paragraph to explicitly frame the axes as a proposed starting specification rather than a validated universal standard. revision: partial
-
Referee: [Abstract] Abstract: the preference-fit axis is defined in terms of the same human preference data used both to discover rubrics and to compute the 65.0%→68.6% accuracy improvement, creating a dependence that is not quantified or tested for circularity; likewise, the adversarial-robustness axis directly supplies the 46.4%→36.0% exploit-rate metric.
Authors: The dependence is by construction: the preference-fit axis is defined to measure alignment with the human preference data that also drives rubric discovery, and the reported accuracy is that direct measure. The exploit-rate is likewise the operational definition of the adversarial-robustness axis. The paper does not perform separate tests for circularity beyond reporting these metrics. We will add explicit language in the methods and abstract clarifying that these axes are intentionally self-referential to the data used for discovery and auditing, and that this is a deliberate feature of the evaluation framework. revision: partial
-
Referee: [Abstract] Abstract: the statement that "PReMISE is the only rubric source to score non-trivially on applicability, specificity, and effective dimensionality simultaneously" is presented without the quantitative definitions or thresholds used for these three quantities, making it impossible to assess whether the claimed uniqueness is independent of the human data or the other two axes.
Authors: The quantitative definitions, scoring procedures, and thresholds for applicability, specificity, and effective dimensionality appear in the Methods section. The abstract statement summarizes the outcome of that full evaluation. To improve self-containment, we will revise the abstract to include brief inline definitions or parenthetical references to the methods for these three quantities. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes PReMISE as a new framework that takes pairwise human-preference data as input to discover rubrics and then audits them along four explicitly defined axes (structural adequacy, reliability, preference fit, adversarial robustness). Reported numerical improvements (65.0% to 68.6% accuracy; 46.4% to 36.0% exploit rate) are presented as direct empirical outcomes of applying the two repair operations inside this framework. No equations, parameter-fitting steps, or self-citations are shown that would reduce these outcomes to the input data by construction. The audit axes are introduced as part of the contribution rather than derived from prior results, and the comparative claims rest on measurements performed under the proposed specification rather than on any tautological renaming or load-bearing self-reference. The derivation chain is therefore self-contained as an empirical evaluation of a proposed method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rubric-Grounded RL: Structured Judge Rewards for Generalizable Reasoning
Rubric-grounded RL: Structured judge re- wards for generalizable reasoning.arXiv preprint arXiv:2605.08061. Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. 2024. UltraFeedback: Boosting lan- guage models with scaled AI feedback. InICML. DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing rea- soning c...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Adrian Kuhn, Stéphane Ducasse, and Tudor Gîrba
Writing-Zero: Bridge the gap between non- verifiable tasks and verifiable rewards.arXiv preprint arXiv:2506.00103. Ai Jian, Jingqing Ruan, Xing Ma, Xiaoyun Zhang, Dailin Li, Weipeng Zhang, Ke Zeng, and Xunliang Cai. 2025. PaTaRM: Bridging pairwise and point- wise signals via preference-aware task-adaptive re- ward modeling.arXiv preprint arXiv:2510.24235....
-
[3]
Dynabench: Rethinking benchmarking in NLP. InNAACL. Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. 2024a. Prometheus 2: An open source language model specialized in evaluating other language mod- els. InProceedings of EMNLP. Seungone Kim and 1 others. 2024b. ...
-
[4]
RVPO: Risk-sensitive alignment via variance regularization.arXiv preprint arXiv:2605.05750. OpenAI. 2024. OpenAI Model Spec. https:// model-spec.openai.com. Tianjun Pan, Xuan Lin, Wenyan Yang, Qianyu He, Shisong Chen, Licai Qi, Wanqing Xu, Hongwei Feng, Bo Xu, and Yanghua Xiao. 2026. RubricE- val: A rubric-level meta-evaluation benchmark for LLM judges in...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Self-Preference Bias in Rubric-Based Evaluation of Large Language Models
Self-preference bias in rubric-based eval- uation of large language models.arXiv preprint arXiv:2604.06996. Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond accuracy: Behav- ioral testing of NLP models with CheckList. InACL. Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2024. Quantifying language models’ sen...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Detecting proxy gaming in RL and LLM alignment via evaluator stress tests.arXiv preprint arXiv:2507.05619. Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. 2022. Defining and characteriz- ing reward hacking. InNeurIPS. Hwanjun Song and 1 others. 2024. FineSurE: Fine- grained summarization evaluation using LLMs. In ACL. Pragya Srivast...
-
[7]
Think-with-Rubrics: From External Evaluator to Internal Reasoning Guidance
Think-with-rubrics: From external evalua- tor to internal reasoning guidance.arXiv preprint arXiv:2605.07461. Jifan Zhang, Henry Sleight, Andi Peng, John Schulman, and Esin Durmus. 2025. Stress-testing model specs reveals character differences among language models. arXiv preprint arXiv:2510.07686. Qiyuan Zhang, Junyi Zhou, Yufei Wang, Fuyuan Lyu, Yidong ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2603.01562 (2026)
RubricBench: Aligning model-generated rubrics with human standards.arXiv preprint arXiv:2603.01562. Xinran Zhang. 2026. Rethinking atomic decomposi- tion for LLM judges: A prompt-controlled study of reference-grounded QA evaluation.arXiv preprint arXiv:2603.28005. Yulai Zhao, Haolin Liu, Dian Yu, Sunyuan Kung, Mei- jia Chen, Haitao Mi, and Dong Yu. 2025. ...
-
[9]
Atomicity: the rubric measures a single be- havioral dimension, not multiple conflated properties
-
[10]
Internal consistency: the rubric does not con- tain internally contradictory rules
-
[11]
Response observability: the rubric can be assessed solely from the prompt and response, without external knowledge or ground truth
-
[12]
Operationalizability: the rubric can be ex- pressed as a concrete, answerable scoring question
-
[13]
violation are well- defined
Unambiguous scope: the boundaries of what counts as adherence vs. violation are well- defined. Each property is scored pass/fail by majority vote across the 3 judges (structural judge prompt in §F). The structural score for a rubric is the mean number of properties passed per rubric (out of 5), averaged across allKrubrics in the set. B.1.3 BT Preference-F...
-
[14]
Scoring.DeepSeek-V3 scores both responses in each of n preference pairs on every rubric (ordinal [0,10] scale), producing a feature ma- trix S∈R n×K of per-rubric score differ- ences
-
[15]
The regularization strength Cis selected by nested CV within each fold
Regression.An L2-regularized logistic re- gression is fit on S to predict the binary hu- man preference label, using 5-fold stratified cross-validation. The regularization strength Cis selected by nested CV within each fold
-
[16]
Training uses n=1000 battles; holdout evaluation uses n=250 disjoint battles per dataset
Metrics.We report (a) CV accuracy: the mean held-out accuracy across 5 folds; (b) BT-weight entropy: the normalized Shannon entropy of the absolute logistic regression co- efficients, H(|β|/P |β|)/logK , measuring how uniformly individual rubrics contribute to preference prediction (higher = more rubrics carry signal). Training uses n=1000 battles; holdou...
-
[17]
Preference-rank selection (PREMISE (dis- covered) → PREMISE (+ pref repair)) produces a consistent lift across the cross- judge × cross-template grid.Hierarchical aggregate over (judge, template, source) cells: +2.80pp [CI+2.04,+3.59],p <0.001
-
[18]
The response should derive all claims from reported evidence or established mechanisms without intro- ducing assertions lacking direct support
PREMISE (+ pref repair) leads the 4- source mean on DS-V3 (direct 68.6, JSON 14 Table 3: Per-dataset breakdown of the main audit table. Each row is one (method, dataset) cell; “−” marks missing runs.Str.= structural pass score (out of 5);Flip%= stochastic re-run flip rate; ρ = mean paraphrase Spearman; VFR= Verified Fool Rate;CV-acc / Ent.= 5-fold logisti...
2000
-
[19]
helpfulness: Measures how effectively the response ad- dresses the user’s query by providing useful, actionable, and complete information.[truncated]
-
[20]
accuracy: Evaluates the factual correctness and scientific validity of the information provided.[truncated]
-
[21]
clarity: Assesses how clearly and understandably the re- sponse is presented.[truncated]
-
[22]
HelpSteer3 (K=4)
relevance: Determines how closely the content stays fo- cused on the user’s original request without introducing irrelevant or tangential information. HelpSteer3 (K=4)
-
[23]
[truncated]
helpfulness: Measures how effectively the response ad- dresses the user’s request or provides useful information. [truncated]
-
[24]
accuracy: Evaluates the factual correctness of the infor- mation provided in the response.[truncated]
-
[25]
Clear responses are well- structured, use plain language, and avoid ambiguity or confusion
clarity: Assesses how clearly and understandably the response is communicated. Clear responses are well- structured, use plain language, and avoid ambiguity or confusion
-
[26]
relevance: Determines how closely the response aligns with the user’s prompt and intent.[truncated] HH-RLHF (K=4)
-
[27]
helpfulness: Measures how effectively the AI response addresses the user’s request or question.[truncated]
-
[28]
accuracy: Evaluates whether the information provided in the response is factually correct, logically sound, and free from misinformation or hallucination
-
[29]
High clarity means the language is concise, well-structured, and avoids ambiguity or confu- sion
clarity: Assesses how clearly and understandably the re- sponse is phrased. High clarity means the language is concise, well-structured, and avoids ambiguity or confu- sion
-
[30]
relevance: Determines how closely the response stays on topic and aligns with the user’s original prompt.[trun- cated] 22 UltraFeedback (K=4)
-
[31]
helpfulness: Measures how effectively the response ad- dresses the user’s query by providing actionable, compre- hensive, and solution-oriented information.[truncated]
-
[32]
accuracy: Evaluates the factual correctness and reliability of the information provided in the response.[truncated]
-
[33]
clarity: Assesses how clearly and logically the response is structured and communicated.[truncated]
-
[34]
relevance: Determines how closely the response aligns with the user’s original request or topic.[truncated] Auto-Rubric Arena-Expert-5K (K=20)
-
[35]
[truncated]
Accuracy and relevance of the proposed alternative to the deprecated function: The response must correctly identify a modern, non-deprecated Neovim API method for. . .[truncated]
-
[36]
[truncated]
Accuracy and relevance of the technical explanation regard- ing the font error in Apache PDFBox, including correct identification of the API changes (e.g., deprecation of. . . [truncated]
-
[37]
[truncated]
Clarity, structure, and educational value of the explana- tion: The response should clearly explain the deprecation issue, present the solution in a well-organized manner. . . [truncated]
-
[38]
[truncated]
Code clarity and robustness: The code should be well- organized, clearly commented, use defensive programming practices (e.g., input validation, clamping), and include. . . [truncated]
-
[39]
[truncated]
Completeness and clarity of the code-level response, in- cluding whether the fix is clearly demonstrated, properly contextualized within the provided code snippet, and free of. . .[truncated]
-
[40]
[truncated]
Faithfulness to the query: The response must accurately implement all requested features—min distance, max dis- tance, and color gradient from green (0) to yellow (min). . . [truncated]
-
[41]
Jako[non-Latin text] syntetyzowania informacji i gbia in- terpretacji, obejmujca ocen potencjalnych rynkowych im- plikacji sygnaów, rozrónienie midzy moliwymi scenar- iuszami (np.[truncated]
-
[42]
[truncated]
Kompletno[non-Latin text] i precyzja analizy sygnaów ONC-W1 i SOC-S1, w tym dokadne wyjanienie mecha- nizmów dziaania transferów do PancakeSwap Router oraz róde i konsekwencji. . .[truncated]
-
[43]
[truncated]
Komplettheit und Tiefe der wissenschaftlichen Erk- lärung: Die Antwort muss das komplexe Zusammen- spiel von Juvenilhormon (JH) und Ecdysteroiden klar erk- lären,. . .[truncated]
-
[44]
[truncated]
The response clearly explains the meaning and interpre- tation of the order relation ‘≤‘ in each example (e.g., as approximation, information content, or convergence),. . . [truncated]
-
[45]
[truncated]
The response demonstrates a comprehensive, well- structured critical analysis that engages deeply with philo- sophical, logical, scientific, and practical dimensions of the concept. . .[truncated]
-
[46]
[truncated]
The response exhibits depth of insight by identifying core tensions within the argument (e.g., logical consistency, metaphysical implications, empirical plausibility), chal- lenging. . .[truncated]
-
[47]
[truncated]
The response must accurately diagnose the core issue of misaligned x-axis scaling between high-frequency target bitrate data (per frame) and low-frequency SCReAM sum- mary. . .[truncated]
-
[48]
[truncated]
The response must offer a reflective, meta-cognitive analy- sis that interprets the user’s learning journey and geometric intuition—especially the ’spiral spring’ analogy—within. . . [truncated]
-
[49]
[trun- cated]
The response must provide a technically precise and math- ematically rigorous explanation grounded in functional analysis, correctly defining and interrelating key. . .[trun- cated]
-
[50]
[truncated]
The response must provide clear, executable code modi- fications that correctly overlay the target bitrate onto the transmission rate subplot with appropriate time scaling, preserve. . .[truncated]
-
[51]
[truncated]
The response offers additional value through multiple well- crafted paraphrasing options or strategic rephrasing vari- ations that improve stylistic flexibility and adaptability,. . . [truncated]
-
[52]
[truncated] non-Latin text : , (, retention, CAC, LTV)
The response provides a diverse and illustrative set of small, concrete examples that span multiple domains (e.g., lists, functions, trees, intervals) to demonstrate the broad. . . [truncated] non-Latin text : , (, retention, CAC, LTV). ( ’ ’ ’ ’) — A/B-, , UTM. , /, , . non-Latin text Adjoint HelpSteer3 (K=20)
-
[53]
[truncated]
Accuracy and correctness of the SQL logic in retrieving the previous and next scheduledfilmid based on position ordering, ensuring that the previous item has a strictly lower. . .[truncated]
-
[54]
Clarity and simplicity of the code example, favoring id- iomatic SQLAlchemy usage without unnecessary complex- ity or redundant functions that could confuse the user
-
[55]
[truncated]
Clarity, efficiency, and safety of the SQL implementation, favoring solutions that avoid unnecessary complexity (e.g., redundant lateral joins or incorrect COALESCE fallbacks) and. . .[truncated]
-
[56]
[truncated]
Completeness and specificity of the hardware and soft- ware setup instructions: Higher-quality responses pro- vide detailed, concrete steps for configuring the BladeRF,. . . [truncated]
-
[57]
[truncated]
Precision and correctness of the proposed code solution, including proper destructuring in both the component defi- nition and the map function, while maintaining type safety and. . .[truncated]
-
[58]
[truncated]
Technical feasibility and domain-appropriate signal processing guidance: Higher-quality responses demon- strate accurate understanding of passive radar principles by. . .[truncated]
-
[59]
[truncated]
The response accurately and completely captures the core contribution of the paper, including the discovery of a new winning solution on an 8 ×8 Hex board with the first. . . [truncated]
-
[60]
[truncated]
The response accurately identifies and explains the limi- tations of storing files directly in MongoDB collections and distinguishes when to use GridFS versus alternative storage. . .[truncated]
-
[61]
[truncated]
The response accurately interprets COMPASS as ’Con- trastive Multimodal Pretraining for Autonomous Systems’ and leverages its core technical components—such as con- trastive. . .[truncated]
-
[62]
[truncated]
The response clearly distinguishes between the search vec- tor and database vectors, avoiding logical errors such as computing pairwise dot products between all rows in the. . . [truncated]
-
[63]
[truncated]
The response correctly extracts ’channel’ and ’ts’ fields from the event object to retrieve thread replies, ensuring compatibility with real-world Slack event payloads, and. . . [truncated]
-
[64]
[truncated]
The response correctly implements a flexible and scalable 23 SQL solution for computing the dot product between a search term vector and database vectors, with proper han- dling of. . .[truncated]
-
[65]
[truncated]
The response implements robust pagination with proper cursor handling in a loop and includes comprehensive error handling using try-except blocks specific to Slack API errors,. . .[truncated]
-
[66]
[truncated]
The response must correctly implement a drag-and-drop file upload functionality native to Google Colab (e.g., using ‘google.colab.files.upload()‘) that allows users to upload. . . [truncated]
-
[67]
[truncated]
The response must maintain functional equivalence with the original code by properly integrating the uploaded file data into the existing image processing and simulation pipeline,. . .[truncated]
-
[68]
[truncated]
The response must properly handle asynchronous parsing of the request body using ’await req.json()’ and include all necessary error handling and input validation logic to ensure. . .[truncated]
-
[69]
[truncated]
The response must provide a comprehensive and techni- cally accurate explanation of all assembly attributes present in the code, including their purpose, namespace context, and. . .[truncated]
-
[70]
[truncated]
The response must provide a precise, technically accurate, and comprehensive comparison between std::bitset and std::vector<bool>, explicitly addressing. . .[truncated]
-
[71]
[truncated]
The response provides a simple, interactive command-line interface using the ‘input()‘ function, enabling immedi- ate user interaction within Replit’s console environment, which. . .[truncated]
-
[72]
[truncated] HH-RLHF (K=20)
The response relies on command-line arguments via ‘sys.argv‘, which is less accessible in Replit’s default inter- active environment and requires users to know how to pass arguments. . .[truncated] HH-RLHF (K=20)
-
[73]
[truncated]
Clarity and constructive intent: The response should clearly interpret the user’s intent and provide a helpful, informative, and positively framed answer that promotes. . . [truncated]
-
[74]
[truncated]
Relevance and alignment with ethical guidelines: The response must directly address the query while adhering to ethical standards, avoiding encouragement or implica- tion. . .[truncated]
-
[75]
[truncated]
The response avoids promoting manipulative or transac- tional behaviors (such as using gifts or attention to earn love) and instead supports respectful, realistic, and emo- tionally. . .[truncated]
-
[76]
[truncated]
The response demonstrates clarity and directness in ad- dressing the user’s intent, either by seeking clarification when the query is ambiguous or by providing relevant,. . . [truncated]
-
[77]
[truncated]
The response demonstrates empathy and encourages self- reflection by considering the girl’s perspective and emo- tional autonomy, promoting healthy emotional processing rather than. . .[truncated]
-
[78]
[truncated]
The response must affirm the validity and dignity of trans- gender identities without implying judgment or requiring justification, prioritizing emotional safety and inclusivity for. . .[truncated]
-
[79]
[truncated]
The response must prioritize ethical and legal boundaries by clearly discouraging illegal activities, especially those involving privacy violations, and emphasize the serious. . . [truncated]
-
[80]
[truncated]
The response must prioritize ethical responsibility by strongly discouraging harmful, illegal, or inhumane acts— especially those involving violence toward living beings— rather. . .[truncated]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.