Recognition: no theorem link
Think-with-Rubrics: From External Evaluator to Internal Reasoning Guidance
Pith reviewed 2026-05-11 01:47 UTC · model grok-4.3
The pith
Making LLMs generate rubrics first as part of their reasoning trace, then supervising consistency with both self-created and golden rubrics, turns external evaluation into internal guidance and raises benchmark scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
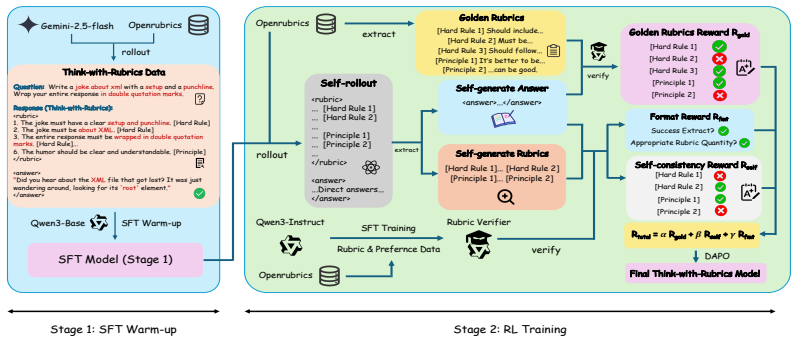
Think-with-Rubrics has the LLM sequentially generate a rubric followed by a response; a trained rubric verifier then provides joint supervision by scoring the consistency of the response against both the self-generated rubric and the golden rubric. This integration converts the rubric from a disconnected external artifact into an internal component of the generation process, yielding measurable gains over standard rubric-as-reward training.
What carries the argument
The sequential generation of a rubric before the response, combined with joint verifier supervision on consistency to both self-generated and golden rubrics, which supplies the training signal that guides internal reasoning.
If this is right
- Responses become more internally consistent with the evaluation criteria the model itself produced.
- Self-generated rubrics increase in quality when the model receives supervision from both them and golden rubrics.
- Golden-rubric supervision primarily refines the model's ability to produce useful rubrics, while self-rubric supervision strengthens response coherence.
- The approach reduces reliance on purely post-generation reward signals for open-ended instruction tasks.
Where Pith is reading between the lines
- Models could apply the same upfront-rubric pattern at inference time to produce more self-aligned answers without any external verifier.
- The joint-supervision pattern might generalize to other internal structures, such as explicit step-by-step plans or uncertainty estimates generated before the final answer.
- Over repeated training cycles the model might internalize rubric creation so thoroughly that the explicit rubric step becomes optional while still retaining the consistency benefits.
- This internal-guidance design could complement or reduce the need for separate reward models in reinforcement-learning pipelines for open-ended tasks.
Load-bearing premise
The trained rubric verifier must supply reliable consistency signals that actually improve the quality of the model's internal reasoning trace rather than merely correlating with better outputs.
What would settle it
Replace the trained verifier with a random or fixed inconsistent scorer during training; if performance then falls to or below the Rubric-as-Reward baseline, the claim that joint supervision drives the gains would be falsified.
Figures


read the original abstract
Rubrics have been extensively utilized for evaluating unverifiable, open-ended tasks, with recent research incorporating them into reward systems for reinforcement learning. However, existing frameworks typically treat rubrics only as external evaluator disjointed from the policy's primary reasoning trace. Such design confines rubrics to post-hoc measurement, leaving them unable to actively guide the model's generation process. In this work, we introduce Think-with-Rubrics, a novel paradigm for instruction following tasks. Think-with-Rubrics integrates rubric generation into the reasoning context, transforming the rubric from an independent artifact into an internal guidance of LLM's generation. During training, LLM sequentially generates a rubric followed by a response, while a trained rubric verifier provides joint supervision by evaluating the consistency between the answer and the self-generated / golden rubrics. Experiments across multiple benchmarks demonstrate that Think-with-Rubrics consistently outperforms the Rubric-as-Reward baseline supervised by golden rubrics by an average of 3.87 points. We have also discussed the mechanism by which Think-with-Rubrics enhances model performance. Experimental results demonstrate that supervision from golden rubrics and self-generated rubrics enhances the performance of Think-with-Rubrics by improving the quality of self-generated rubrics and increasing the internal consistency of responses respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Think-with-Rubrics, a paradigm for instruction-following tasks in which an LLM sequentially generates a rubric followed by a response as part of its internal reasoning trace. A trained rubric verifier supplies joint supervision by checking consistency between the response and both the self-generated rubric and golden rubrics. Experiments across multiple benchmarks report that this approach outperforms the Rubric-as-Reward baseline (supervised only by golden rubrics) by an average of 3.87 points, with additional discussion of mechanisms by which golden-rubric and self-rubric supervision improve rubric quality and internal response consistency, respectively.
Significance. If the results hold after proper validation, the work offers a concrete way to move rubrics from external post-hoc evaluators into the model's generative process, which could improve reasoning quality and alignment on open-ended tasks. The reported gains and mechanistic discussion provide a starting point for this shift, though the current evidence base is too thin to assess generalizability or the precise source of the improvement.
major comments (3)
- [Abstract] Abstract: the central claim of a consistent 3.87-point average improvement is stated without identifying the benchmarks, number of runs, statistical tests, model scales, or training hyperparameters, leaving the empirical support for the paradigm shift only moderately substantiated.
- [Method] The description of the trained rubric verifier (and its role in joint supervision): no accuracy metrics, human agreement scores, or ablation studies isolating verifier errors are reported. Because the method replaces external evaluation with verifier-mediated internal guidance, the absence of verifier validation makes it impossible to rule out that the 3.87-point margin arises from policy exploitation of verifier idiosyncrasies rather than improved reasoning traces.
- [Abstract] Abstract / Experiments: the mechanistic claim that golden-rubric supervision improves self-generated rubric quality while self-rubric supervision increases internal consistency is asserted without quantitative breakdowns, controls, or ablations separating the two contributions, undermining attribution of the overall gain to the proposed internal-guidance mechanism.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement distinguishing the training-time sequential generation plus verifier supervision from any inference-time usage of the method.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional details and analyses would strengthen the presentation of our empirical results and mechanistic insights. We address each major comment below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a consistent 3.87-point average improvement is stated without identifying the benchmarks, number of runs, statistical tests, model scales, or training hyperparameters, leaving the empirical support for the paradigm shift only moderately substantiated.
Authors: We agree that the abstract would benefit from greater specificity to substantiate the reported improvement. In the revised manuscript, we have expanded the abstract to explicitly name the benchmarks, report the number of runs, describe the statistical tests performed, indicate the model scales evaluated, and summarize the key training hyperparameters. These additions provide readers with the necessary context while preserving the abstract's conciseness. revision: yes
-
Referee: [Method] The description of the trained rubric verifier (and its role in joint supervision): no accuracy metrics, human agreement scores, or ablation studies isolating verifier errors are reported. Because the method replaces external evaluation with verifier-mediated internal guidance, the absence of verifier validation makes it impossible to rule out that the 3.87-point margin arises from policy exploitation of verifier idiosyncrasies rather than improved reasoning traces.
Authors: We acknowledge the importance of validating the rubric verifier, as its reliability is central to attributing gains to internal guidance rather than verifier artifacts. The original submission focused on the overall paradigm and did not include these metrics. In the revision, we have added the verifier's accuracy on held-out data, human agreement scores, and ablation experiments that quantify the impact of verifier errors. These results support that the observed improvements arise from enhanced reasoning traces. revision: yes
-
Referee: [Abstract] Abstract / Experiments: the mechanistic claim that golden-rubric supervision improves self-generated rubric quality while self-rubric supervision increases internal consistency is asserted without quantitative breakdowns, controls, or ablations separating the two contributions, undermining attribution of the overall gain to the proposed internal-guidance mechanism.
Authors: We agree that stronger quantitative evidence is needed to attribute the gains specifically to the internal-guidance mechanism. The original manuscript presented these mechanisms through discussion and overall results. We have revised the experiments section to include targeted ablations, quantitative breakdowns of rubric quality and response consistency metrics, and controls that isolate the effects of golden-rubric versus self-rubric supervision. These additions clarify the distinct contributions of each supervision signal. revision: yes
Circularity Check
No circularity detected in empirical claims
full rationale
The paper advances an empirical training paradigm in which an LLM generates rubrics then responses, supervised by a separately trained verifier on consistency with self-generated and golden rubrics. Its central result is a measured 3.87-point average gain over the Rubric-as-Reward baseline across benchmarks, presented as direct experimental comparison rather than any first-principles derivation, fitted-parameter prediction, or self-referential equation. No load-bearing steps reduce by construction to the method's own inputs; the verifier is treated as an external trained component, and performance is evaluated against an independent baseline. This structure is self-contained against external benchmarks and contains none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs are capable of generating task-appropriate rubrics as part of reasoning
- domain assumption A trained rubric verifier can accurately measure consistency between responses and rubrics
Reference graph
Works this paper leans on
-
[1]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Sunzhu Li, Jiale Zhao, Miteto Wei, Huimin Ren, Yang Zhou, Jingwen Yang, Shunyu Liu, Kaike Zhang, and Wei Chen. Rubrichub: A comprehensive and highly discriminative rubric dataset via automated coarse-to-fine generation.arXiv preprint arXiv:2601.08430, 2026
-
[5]
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, et al. Skywork-reward-v2: Scaling preference data curation via human-ai synergy.arXiv preprint arXiv:2507.01352, 2025
-
[6]
Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and llm alignment.arXiv preprint arXiv:2510.07743, 2025
-
[7]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems, 36:46534–46594, 2023
work page 2023
-
[8]
RewardBench 2: Advancing Reward Model Evaluation
Saumya Malik, Valentina Pyatkin, Sander Land, Jacob Morrison, Noah A Smith, Hannaneh Hajishirzi, and Nathan Lambert. Rewardbench 2: Advancing reward model evaluation.arXiv preprint arXiv:2506.01937, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833,
Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, and Hannaneh Hajishirzi. Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833, 2025
-
[10]
Infobench: Evaluating instruction following ability in large language models
Yiwei Qin, Kaiqiang Song, Yebowen Hu, Wenlin Yao, Sangwoo Cho, Xiaoyang Wang, Xuansheng Wu, Fei Liu, Pengfei Liu, and Dong Yu. Infobench: Evaluating instruction following ability in large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13025–13048, 2024
work page 2024
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
work page 2025
-
[13]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[14]
Encheng Su, Jianyu Wu, Chen Tang, Lintao Wang, Pengze Li, Aoran Wang, Jinouwen Zhang, Yizhou Wang, Yuan Meng, Xinzhu Ma, et al. Sciif: Benchmarking scientific instruction following towards rigorous scientific intelligence.arXiv preprint arXiv:2601.04770, 2026
-
[15]
Shaoning Sun, Jiachen Yu, Zongqi Wang, Xuewei Yang, Tianle Gu, and Yujiu Yang. S2j: Bridging the gap between solving and judging ability in generative reward models.arXiv preprint arXiv:2509.22099, 2025
-
[16]
Judgebench: A benchmark for evaluating llm-based judges,
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica. Judgebench: A benchmark for evaluating llm-based judges.arXiv preprint arXiv:2410.12784, 2024. 10
-
[17]
Vijay Viswanathan, Yanchao Sun, Shuang Ma, Xiang Kong, Meng Cao, Graham Neubig, and Tong- shuang Wu. Checklists are better than reward models for aligning language models.arXiv preprint arXiv:2507.18624, 2025
-
[18]
Plan- and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan- and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 2609–2634, 2023
work page 2023
-
[19]
Zhilin Wang, Yi Dong, Olivier Delalleau, Jiaqi Zeng, Gerald Shen, Daniel Egert, Jimmy J Zhang, Makesh N Sreedhar, and Oleksii Kuchaiev. Helpsteer 2: Open-source dataset for training top-performing reward models.Advances in Neural Information Processing Systems, 37:1474–1501, 2024
work page 2024
-
[20]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Learning llm-as-a-judge for preference alignment
Ziyi Ye, Xiangsheng Li, Qiuchi Li, Qingyao Ai, Yujia Zhou, Wei Shen, Dong Yan, and Yiqun Liu. Learning llm-as-a-judge for preference alignment. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[22]
Improve llm-as-a-judge ability as a general ability
Jiachen Yu, Shaoning Sun, Xiaohui Hu, Jiaxu Yan, Kaidong Yu, and Xuelong Li. Improve llm-as-a-judge ability as a general ability. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14110–14126, 2025
work page 2025
-
[23]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Compassjudger-2: Towards generalist judge model via verifiable rewards, 2025
Taolin Zhang, Maosong Cao, Alexander Lam, Songyang Zhang, and Kai Chen. Compassjudger-2: Towards generalist judge model via verifiable rewards.arXiv preprint arXiv:2507.09104, 2025
-
[25]
Yunfan Zhang, Yijie Bei, Jetashree Ravi, and Pawel Garbacki. Firebench: Evaluating instruction following in enterprise and api-driven llm applications.arXiv preprint arXiv:2603.04857, 2026
-
[26]
Llamafactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations), pages 400–410, 2024
work page 2024
-
[27]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models.arXiv preprint arXiv:2205.10625, 2022
work page internal anchor Pith review arXiv 2022
-
[28]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023. 11 A Appendix A.1 Limitation Despite the promising results achieved by THINK-WITH-RUBRICS, this work has two primary limitations. First, the scope of em...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Analyze the Request: Topic: Reflective essay on life changes since starting college. Tone: Academic, reflective. Length: 30 words or less. Format: English, capitalized, brief final answer
-
[30]
Drafting Content: Focus on personal growth, independence, and academic challenges. Keep it concise
-
[31]
Refining for Length: College has transformed my life from a sheltered student into an independent adult. I have learned to manage my time, navigate complex social dynamics, and develop a deeper sense of self-awareness, all of which have fundamentally reshaped my perspective on the world
-
[32]
Final Check: Is it 30 words or less? Yes. Is it in English? Yes. Is it capitalized? Yes. Is it brief? Yes. <answer>College has transformed my life from a sheltered student into an independent adult. I have learned to manage my time, navigate complex social dynamics, and develop a deeper sense of self-awareness, all of which have fundamentally reshaped my ...
- [33]
- [34]
- [35]
-
[36]
The response must provide recommendations for writing a reflective essay. [Hard Rule]
- [37]
-
[38]
[Principle] </rubric> <answer> START WITH A CLARIFYING QUESTION
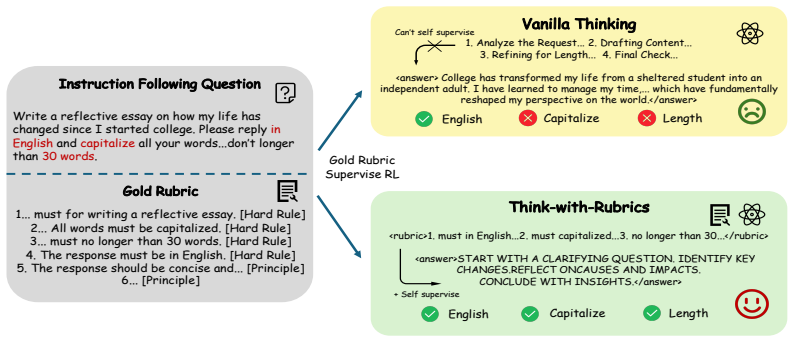
The response should directly address the user’s request. [Principle] </rubric> <answer> START WITH A CLARIFYING QUESTION. IDENTIFY KEY CHANGES. REFLECT ON CAUSES AND IMPACTS. CONCLUDE WITH INSIGHTS. </answer> Figure 3: A test case in IFEval that compares simple Rubric-as-Reward and THINK-WITH-RUBRICS. Under the THINK-WITH-RUBRICSsetting, the model generat...
-
[39]
[Principle] </rubric> <answer> [Insert Answer here] </answer> Figure 5: The prompt format used for THINK-WITH-RUBRICSmodels. The model is explicitly required to first enumerate hard rules and quality principles as a structured rubric before generating the final answer, mirroring the<rubric>→<answer>generation paradigm enforced during training. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.