Recognition: no theorem link
Self-Preference Bias in Rubric-Based Evaluation of Large Language Models
Pith reviewed 2026-05-10 18:14 UTC · model grok-4.3
The pith
LLM judges are up to 50% more likely to mark their own failed outputs as passing in rubric evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
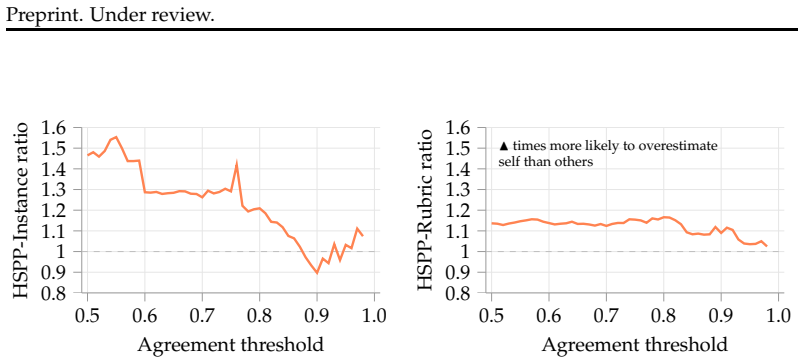
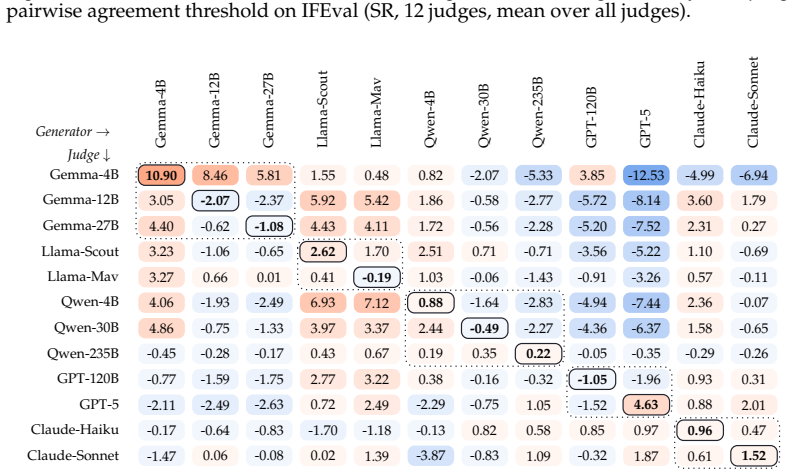
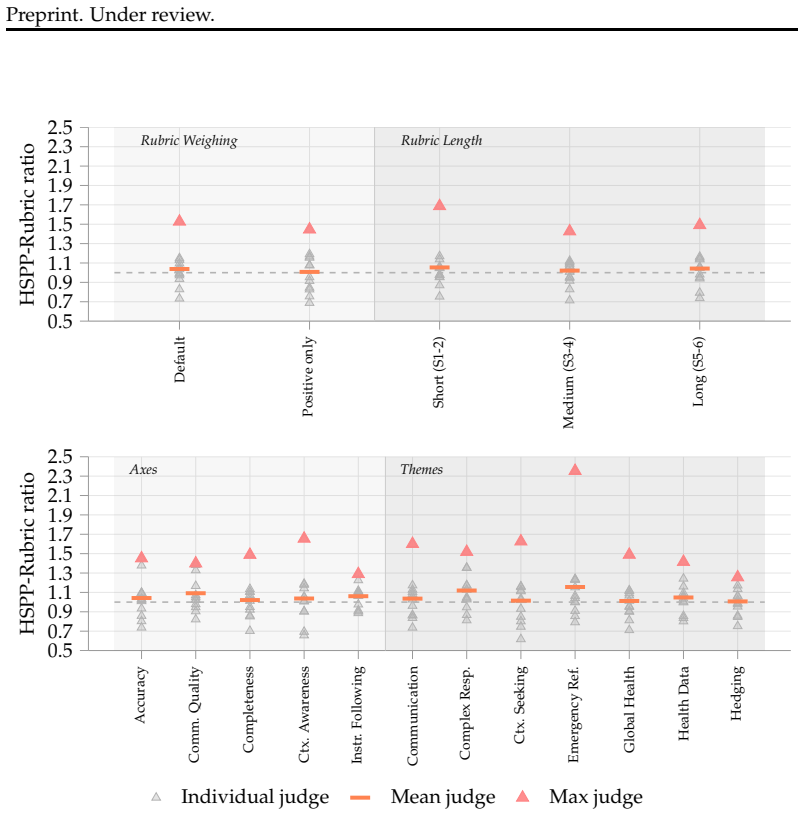
In rubric-based evaluation using IFEval, among cases where the generator fails a criterion, judges are up to 50% more likely to incorrectly declare the criterion satisfied when the output is their own. On HealthBench the bias shifts model scores by up to 10 points. The effect is stronger for negative rubrics, unusually long or short rubrics, and subjective topics such as emergency medical referrals. Ensembling multiple judges reduces the bias but leaves a residual effect.
What carries the argument
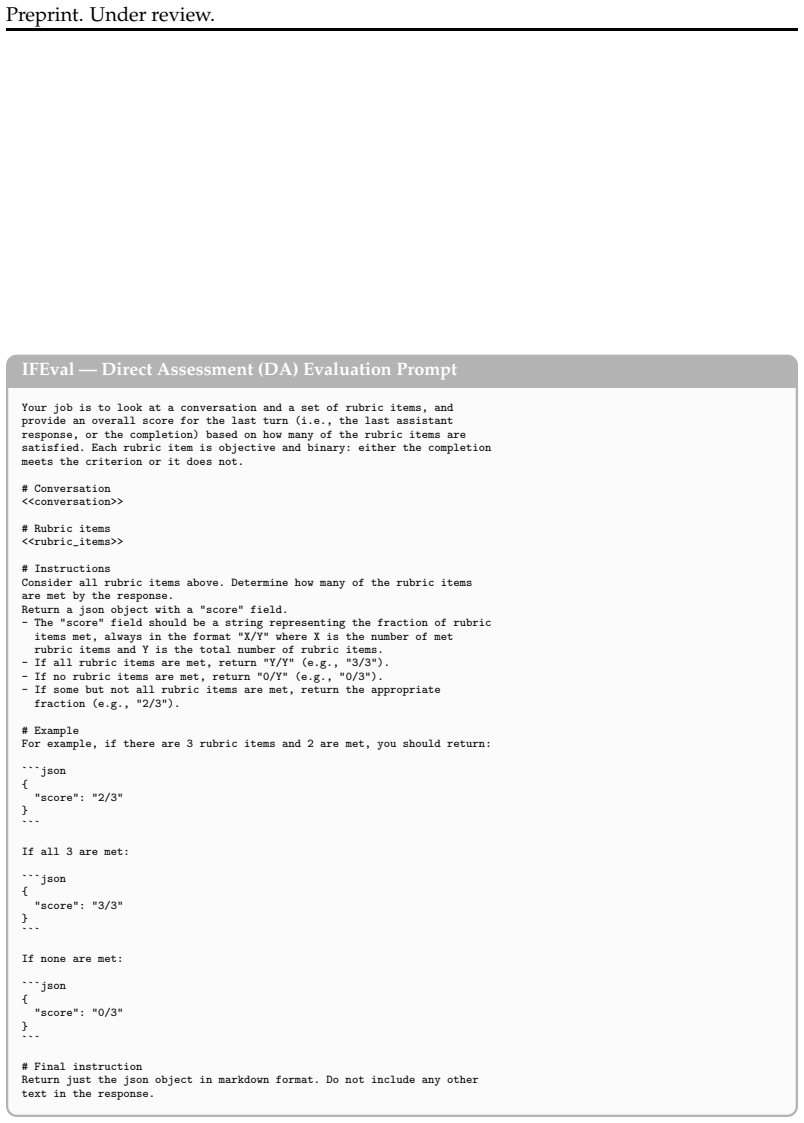
Self-preference bias measured as the difference in binary pass rates for self-generated versus other-generated outputs on identical rubric criteria.
Load-bearing premise
Differences in pass rates between self and other outputs are caused by preference for one's own model rather than by differences in capability, prompt sensitivity, or other unmeasured factors.
What would settle it
A test in which identical outputs are presented to the same judge model once labeled as self-generated and once labeled as generated by another model, checking whether the difference in verdicts disappears.
Figures






read the original abstract
LLM-as-a-judge has become the de facto approach for evaluating LLM outputs. However, judges are known to exhibit self-preference bias (SPB): they tend to favor outputs produced by themselves or by models from their own family. This skews evaluations and, thus, hinders model development, especially in settings of recursive self-improvement. We present the first study of SPB in rubric-based evaluation, an increasingly popular benchmarking paradigm where judges issue binary verdicts on individual evaluation criteria, instead of assigning holistic scores or rankings. Using IFEval, a benchmark with programmatically verifiable rubrics, we show that SPB persists even when evaluation criteria are entirely objective: among rubrics where generators fail, judges can be up to 50\% more likely to incorrectly mark them as satisfied when the output is their own. We also find that, similarly to other evaluation paradigms, ensembling multiple judges helps mitigate SPB, but without fully eliminating it. On HealthBench, a medical chat benchmark with subjective rubrics, we observe that SPB skews model scores by up to 10 points, a potentially decisive margin when ranking frontier models. We analyze the factors that drive SPB in this setting, finding that negative rubrics, extreme rubric lengths, and subjective topics like emergency referrals are particularly susceptible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first empirical study of self-preference bias (SPB) in rubric-based LLM evaluation. Using IFEval's programmatically verifiable rubrics, it reports that LLM judges are up to 50% more likely to return false 'satisfied' verdicts on failed rubrics when the output is self-generated. On HealthBench with subjective rubrics, SPB produces score skews of up to 10 points. Ensembling mitigates but does not eliminate the bias, and the authors identify that negative rubrics, long rubrics, and subjective topics amplify susceptibility.
Significance. If the differential false-positive rates are robust, this work is significant for LLM evaluation practice. Rubric-based methods are increasingly adopted for their granularity, yet undetected SPB could distort rankings and recursive self-improvement loops. The grounding in IFEval's objective verifier provides a reproducible, falsifiable measurement that strengthens the evidence beyond purely subjective judgments; the factor analysis offers practical guidance on when bias is most pronounced.
major comments (2)
- [IFEval results section] IFEval results section: The central claim of up to 50% relative increase in false-positive rates on self-outputs is load-bearing, yet the manuscript reports no sample sizes, statistical tests, confidence intervals, or controls for multiple comparisons. Without these, the magnitude and reliability of the effect cannot be assessed from the stated figures alone.
- [Interpretation and discussion of causes] Interpretation and discussion of causes: The attribution of elevated false-positive rates to self-preference bias (rather than judge familiarity with stylistic, length, or token-distribution features of own outputs) rests on an untested assumption. No ablation holds output characteristics fixed while varying only generator identity, which is required to isolate preference from distribution-shift error.
minor comments (2)
- [Abstract] Abstract: The 'up to 50%' and 'up to 10-point' claims should reference the specific models, number of rubrics, and conditions under which the maxima occur, with pointers to the relevant tables or figures.
- [HealthBench analysis] HealthBench analysis: Clarify how model capability differences were controlled when attributing the 10-point skew solely to SPB, given that subjective rubrics lack programmatic ground truth.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which has improved the statistical reporting and interpretive clarity of our work. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [IFEval results section] IFEval results section: The central claim of up to 50% relative increase in false-positive rates on self-outputs is load-bearing, yet the manuscript reports no sample sizes, statistical tests, confidence intervals, or controls for multiple comparisons. Without these, the magnitude and reliability of the effect cannot be assessed from the stated figures alone.
Authors: We agree that these details are necessary to evaluate the robustness of the reported effect. In the revised manuscript we now report the precise sample sizes (number of outputs per generator-judge pair and rubrics per output), apply two-proportion z-tests with p-values, include 95% confidence intervals on the false-positive rates, and apply Bonferroni correction for the family of model-pair comparisons. These additions appear in the IFEval results section, the main results table, and a new supplementary table. revision: yes
-
Referee: [Interpretation and discussion of causes] Interpretation and discussion of causes: The attribution of elevated false-positive rates to self-preference bias (rather than judge familiarity with stylistic, length, or token-distribution features of own outputs) rests on an untested assumption. No ablation holds output characteristics fixed while varying only generator identity, which is required to isolate preference from distribution-shift error.
Authors: The experimental design already holds output characteristics fixed: for every individual failed output we obtain verdicts from both its generator (self) and from other models (non-self) on the identical text, thereby controlling style, length, and token distribution while varying only the self/non-self relationship. We have revised the interpretation section to state this control explicitly and to discuss residual model-specific judgment differences as a possible contributing factor. We also added a limitations paragraph noting that a stricter isolation (e.g., via style-transferred or synthetic outputs) would require further experiments that we leave to future work. revision: partial
Circularity Check
No circularity: purely empirical measurements on public benchmarks
full rationale
The paper reports direct empirical observations of pass/fail rates and false-positive rates on IFEval (programmatic verifier) and HealthBench, comparing LLM judges on self-generated vs. other-generated outputs. No equations, fitted parameters, derivations, or self-citation chains appear in the provided text or abstract. Central claims (up to 50% higher false-positive rate on self-outputs; up to 10-point score skew) are presented as measured quantities, not as quantities that reduce by construction to inputs defined by the authors. Per guidelines, this is the normal case of a self-contained empirical study; no load-bearing self-definitional, fitted-prediction, or uniqueness-imported steps exist.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rubrics in IFEval are entirely objective and can be verified programmatically without ambiguity.
Forward citations
Cited by 1 Pith paper
-
Not All Proofs Are Equal: Evaluating LLM Proof Quality Beyond Correctness
LLM proofs for hard math problems show large differences in quality metrics like conciseness and cognitive simplicity that correctness-only tests miss, along with trade-offs between quality and correctness.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Qui ˜nonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, et al. Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775,
work page internal anchor Pith review arXiv
-
[3]
Do llm evaluators prefer themselves for a reason?, 2025
Wei-Lin Chen, Zhepei Wei, Xinyu Zhu, Shi Feng, and Yu Meng. Do llm evaluators prefer themselves for a reason?arXiv preprint arXiv:2504.03846,
-
[4]
Laura Dietz, Oleg Zendel, Peter Bailey, Charles Clarke, Ellese Cotterill, Jeff Dalton, Faegheh Hasibi, Mark Sanderson, and Nick Craswell. Llm-evaluation tropes: Perspectives on the validity of llm-evaluations.arXiv preprint arXiv:2504.19076,
-
[5]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746,
work page internal anchor Pith review arXiv
-
[6]
Reinforcement learning with rubric anchors.arXiv preprint arXiv:2508.12790,
Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haokai Xu, Tianyu Zhao, Ru Peng, Jiaqi Hu, Zhanming Shen, Xiaomeng Hu, et al. Reinforcement learning with rubric anchors.arXiv preprint arXiv:2508.12790,
-
[7]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, Louis Rouillard, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 4,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Ryan Koo, Minhwa Lee, Vipul Raheja, Jong Inn Park, Zae Myung Kim, and Dongyeop Kang. Benchmarking cognitive biases in large language models as evaluators.arXiv preprint arXiv:2309.17012,
-
[9]
Preference leakage: A contamination problem in llm- as-a-judge.arXiv preprint arXiv:2502.01534, 2025
Dawei Li, Renliang Sun, Yue Huang, Ming Zhong, Bohan Jiang, Jiawei Han, Xiangliang Zhang, Wei Wang, and Huan Liu. Preference leakage: A contamination problem in llm-as-a-judge.arXiv preprint arXiv:2502.01534,
-
[10]
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. Wildbench: Benchmark- ing llms with challenging tasks from real users in the wild.arXiv preprint arXiv:2406.04770,
-
[11]
Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, and William Yang Wang
Ac- cessed: 2026-03-15. Arjun Panickssery, Samuel R Bowman, and Shi Feng. Llm evaluators recognize and favor their own generations.arXiv preprint arXiv:2404.13076,
-
[12]
10 Preprint. Under review. Alexander Pugachev, Alena Fenogenova, Vladislav Mikhailov, and Ekaterina Artemova. Repa: Russian error types annotation for evaluating text generation and judgment capa- bilities.arXiv preprint arXiv:2503.13102,
-
[13]
Dani Roytburg, Matthew Bozoukov, Matthew Nguyen, Jou Barzdukas, Simon Fu, and Narmeen Oozeer. Breaking the mirror: Activation-based mitigation of self-preference in llm evaluators.arXiv preprint arXiv:2509.03647,
-
[14]
arXiv preprint arXiv:2501.17399 , year=
Ved Sirdeshmukh, Kaustubh Deshpande, Johannes Mols, Lifeng Jin, Ed-Yeremai Cardona, Dean Lee, Jeremy Kritz, Willow Primack, Summer Yue, and Chen Xing. Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms. arXiv preprint arXiv:2501.17399,
-
[15]
Evangelia Spiliopoulou, Riccardo Fogliato, Hanna Burnsky, Tamer Soliman, Jie Ma, Graham Horwood, and Miguel Ballesteros. Play favorites: A statistical method to measure self-bias in llm-as-a-judge.arXiv preprint arXiv:2508.06709,
-
[16]
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. Paperbench: Evalu- ating ai’s ability to replicate ai research.arXiv preprint arXiv:2504.01848,
-
[17]
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating llm generations with a panel of diverse models.arXiv preprint arXiv:2404.18796,
-
[18]
Self-Preference Bias in LLM-as-a-Judge
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. Self-preference bias in llm-as-a-judge. arXiv preprint arXiv:2410.21819,
work page internal anchor Pith review arXiv
-
[19]
Rickard Stureborg, Dimitris Alikaniotis, and Yoshi Suhara
Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, and William Yang Wang. Pride and prejudice: Llm amplifies self-bias in self-refinement.arXiv preprint arXiv:2402.11436,
-
[20]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Justin Zhao, Flor Miriam Plaza-del Arco, Benjamin Genchel, and Amanda Cercas Curry. Language model council: Democratically benchmarking foundation models on highly subjective tasks.arXiv preprint arXiv:2406.08598,
-
[22]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.