UniAudio-Token: Empowering Semantic Speech Tokenizers with General Audio Perception
Pith reviewed 2026-06-28 22:24 UTC · model grok-4.3
The pith
UniAudio-Token equips semantic speech tokenizers with general audio perception while preserving high-fidelity speech generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
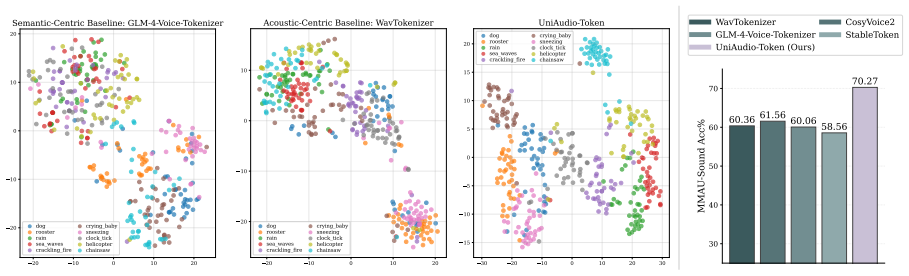
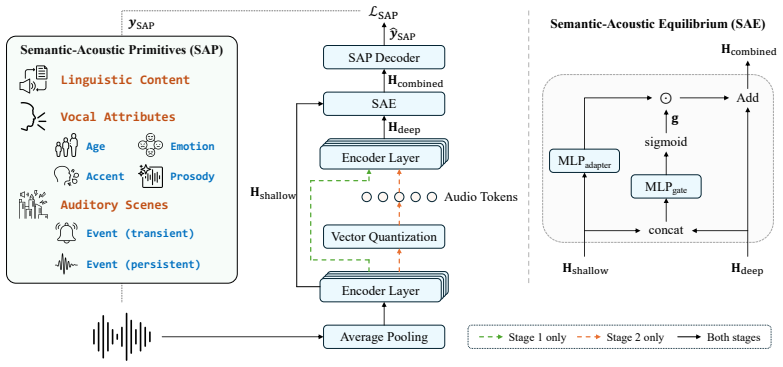
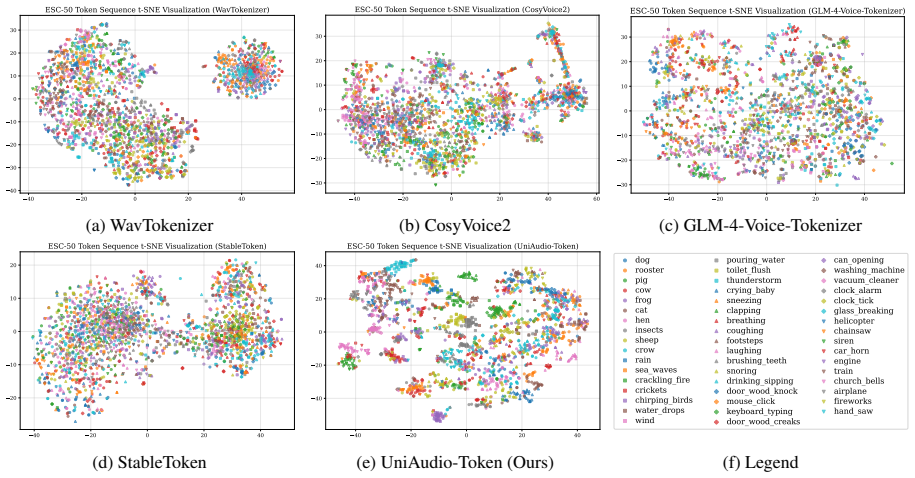
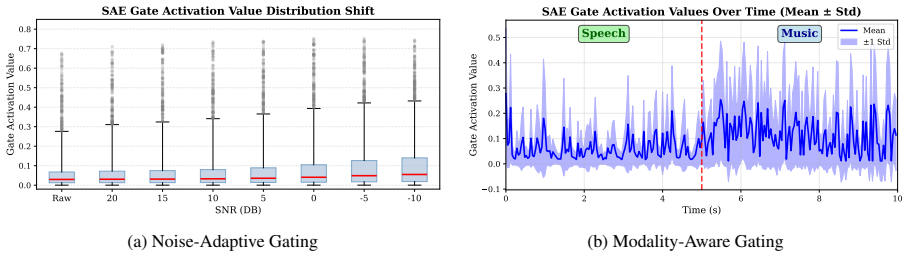
UniAudio-Token mitigates information loss in semantic tokenizers without altering their single-codebook paradigm. Semantic-Acoustic Primitives decompose audio into linguistic content, vocal attributes, and auditory-scene primitives for structured supervision. Semantic-Acoustic Equilibrium then applies content-aware gating to restore fine-grained acoustic details from shallow layers. The resulting representations support comprehensive universal audio understanding while maintaining high-fidelity speech generation. When connected to downstream LLMs, the tokenizer outperforms all single-codebook baselines on both understanding and generation tasks.
What carries the argument
Semantic-Acoustic Primitives (SAP) for structured audio decomposition and Semantic-Acoustic Equilibrium (SAE) content-aware gating that restores acoustic details from shallow layers.
If this is right
- The tokenizer produces comprehensive universal representations across linguistic, vocal, and scene elements.
- High-fidelity speech generation capability remains intact.
- Integration with LLMs yields better results than prior single-codebook tokenizers on both understanding and generation.
- The method provides a single unified audio interface usable across diverse audio tasks.
Where Pith is reading between the lines
- The same primitive decomposition could extend to audio from video or music sources where scene and vocal cues matter.
- Content-aware gating offers a general pattern for balancing abstraction and detail in other tokenization schemes.
- Downstream systems might reduce reliance on multiple specialized tokenizers by adopting this unified design.
Load-bearing premise
The decomposition of audio into linguistic, vocal, and scene primitives combined with content-aware gating can restore acoustic details without any measurable loss in linguistic alignment or speech generation quality.
What would settle it
A side-by-side evaluation on a mixed speech-plus-non-speech dataset where the new tokenizer shows no accuracy gain over baselines in an LLM understanding task or produces lower speech synthesis fidelity scores.
Figures





read the original abstract
Semantic speech tokenizers have become a widely used interface for Audio-LLMs, owing to their compact single-codebook design and strong linguistic alignment. However, their focus on linguistic abstraction induces acoustic blindness, limiting their applicability beyond speech-centric tasks. We propose UniAudio-Token, a framework that empowers semantic tokenizers with general audio perception without compromising speech ability. Instead of altering the semantic paradigm, UniAudio-Token mitigates its information loss through two key innovations: (1) Semantic-Acoustic Primitives (SAP) provide structured supervision by decomposing audio into linguistic content, vocal attributes, and auditory-scene primitives; and (2) Semantic-Acoustic Equilibrium (SAE) introduces a content-aware gating mechanism that adaptively restores fine-grained acoustic details from shallow layers. Extensive evaluations show that UniAudio-Token learns comprehensive universal representations while preserving high-fidelity speech generation. When integrated with downstream LLMs, it outperforms all single-codebook baseline tokenizers on both understanding and generation tasks, effectively serving as a unified audio interface. We publicly release all our code, including training and inference scripts, together with the model checkpoints at https://github.com/Tencent/Universal_Audio_Tokenizer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniAudio-Token, a framework to enhance semantic speech tokenizers with general audio perception capabilities. It introduces Semantic-Acoustic Primitives (SAP) that decompose audio into linguistic content, vocal attributes, and auditory-scene primitives for structured supervision, and Semantic-Acoustic Equilibrium (SAE) that uses a content-aware gating mechanism to adaptively restore fine-grained acoustic details from shallow layers. The work claims this preserves high-fidelity speech generation while enabling comprehensive universal representations; when integrated with downstream LLMs, it outperforms all single-codebook baseline tokenizers on both understanding and generation tasks, serving as a unified audio interface. All code, training/inference scripts, and model checkpoints are publicly released.
Significance. If the empirical claims hold, the approach could meaningfully advance Audio-LLM interfaces by addressing the acoustic blindness of semantic tokenizers without introducing trade-offs in speech tasks, potentially enabling more versatile unified audio processing. The public release of code and checkpoints is a clear strength that supports reproducibility and community follow-up.
major comments (2)
- [Abstract] Abstract: The central claim that UniAudio-Token 'outperforms all single-codebook baseline tokenizers on both understanding and generation tasks' is presented without any quantitative results, tables, ablation studies, dataset details, error bars, or experimental methodology, which is load-bearing for validating the effectiveness of SAP and SAE and the outperformance assertion.
- [Abstract] Abstract: The descriptions of SAP decomposition into linguistic/vocal/scene primitives and the SAE content-aware gating mechanism are high-level only, with no equations, loss formulations, architectural details, or section references provided to assess how acoustic details are restored while preserving linguistic alignment.
minor comments (1)
- [Abstract] Abstract: The phrase 'extensive evaluations show' is used but no references to specific sections, tables, or figures containing those results are given.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting these points about the abstract. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that UniAudio-Token 'outperforms all single-codebook baseline tokenizers on both understanding and generation tasks' is presented without any quantitative results, tables, ablation studies, dataset details, error bars, or experimental methodology, which is load-bearing for validating the effectiveness of SAP and SAE and the outperformance assertion.
Authors: Abstracts are designed to be concise high-level summaries and conventionally omit specific quantitative results, tables, or detailed methodology to respect length constraints. The supporting evidence—including quantitative comparisons on understanding and generation tasks, ablation studies, dataset details, error bars, and full experimental methodology—is provided in the main body of the paper (Section 4). The outperformance claim is substantiated there through direct comparisons against single-codebook baselines when integrated with LLMs. revision: no
-
Referee: [Abstract] Abstract: The descriptions of SAP decomposition into linguistic/vocal/scene primitives and the SAE content-aware gating mechanism are high-level only, with no equations, loss formulations, architectural details, or section references provided to assess how acoustic details are restored while preserving linguistic alignment.
Authors: The abstract intentionally uses high-level descriptions to fit within standard length limits while conveying the core ideas. Complete technical details—including the SAP decomposition into linguistic content, vocal attributes, and auditory-scene primitives; the SAE content-aware gating mechanism; equations; loss formulations; architectural specifics; and how acoustic details are restored while preserving alignment—are fully specified in Section 3 of the manuscript. revision: no
Circularity Check
No significant circularity detected
full rationale
The manuscript introduces UniAudio-Token via two descriptive components (SAP decomposition and SAE gating) and reports downstream empirical results on understanding/generation tasks. No equations, parameter-fitting steps, derivation chains, or load-bearing self-citations appear in the abstract or described text. All performance claims are framed as outcomes of experimental evaluation rather than reductions to fitted inputs or prior self-referential results, rendering the contribution self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Cosyvoice 2: Scalable streaming speech synthesis with large language models.Preprint, arXiv:2412.10117. Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, and Yang Feng. 2025. Llama-omni: Seamless speech interaction with large language mod- els. InInternational Conference on Learning Repre- sentations, volume 2025, pages 57607–57624. 9 Gunna...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1–8
Yodas: Youtube-oriented dataset for audio and speech. In2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1–8. Chen-Chou Lo, Szu-Wei Fu, Wen-Chin Huang, Xin Wang, Junichi Yamagishi, Yu Tsao, and Hsin-Min Wang. 2019. MOSNet: Deep Learning-Based Objec- tive Assessment for V oice Conversion. InInterspeech 2019, pages 1541–1545. ...
2019
-
[3]
In Advances in Neural Information Processing Systems, volume 38
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix. In Advances in Neural Information Processing Systems, volume 38. Curran Associates, Inc. Christopher D. Manning, Prabhakar Raghavan, and Hin- rich Schütze. 2008.Introduction to Information Re- trieval. Cambridge University Press. Jan Melechovsky, Zixun Guo, Deepanway ...
2008
-
[4]
DASB - Discrete Audio and Speech Benchmark
Dasb - discrete audio and speech benchmark. Preprint, arXiv:2406.14294. Vassil Panayotov, Guoguo Chen, Daniel Povey, and San- jeev Khudanpur. 2015. Librispeech: An asr corpus based on public domain audio books. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206–5210. Karol J. Piczak. 2015. Esc: Dataset for...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Mmau: A massive multi-task audio under- standing and reasoning benchmark. InInternational Conference on Learning Representations, volume 2025, pages 84929–84964. Amitay Sicherman and Yossi Adi. 2023. Analysing dis- crete self supervised speech representation for spoken language modeling. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Spe...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Hifi-codec: Group-residual vector quan- tization for high fidelity audio codec.Preprint, arXiv:2305.02765. Zhengdong Yang, Shuichiro Shimizu, Yahan Yu, and Chenhui Chu. 2025b. When large language models meet speech: A survey on integration approaches. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20298–20315, Vienna, Austria...
-
[7]
We use the officially released most powerful large, 75Hzvariant in our experiments
WavTokenizer(Ji et al., 2025), a high- compression single-codebook acoustic codecs. We use the officially released most powerful large, 75Hzvariant in our experiments
2025
-
[8]
CosyVoice2(Du et al., 2024), a leading speech tokenization and generation model, which introduces Finite-Scalar Quantization (FSQ) to replace traditional Vector Quantiza- tion (VQ) in its audio tokenizer for enhanced codebook utilization and representation effi- ciency
2024
-
[9]
It can compress speech into highly efficient discrete tokens at a significantly lower frame rate while ensuring robust semantic preservation
GLM-4-Voice-Tokenizer(Zeng et al., 2025), a representative semantic tokenizer tailored for Speech Large Language Models. It can compress speech into highly efficient discrete tokens at a significantly lower frame rate while ensuring robust semantic preservation. We use the officially released checkpoint which has a frame rate of 12.5Hz and a codebook size...
2025
-
[10]
Perfect Consistency
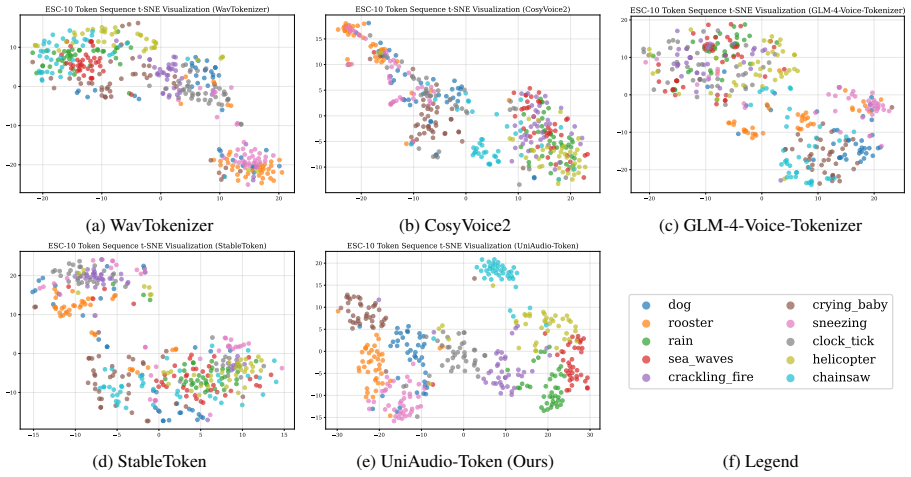
StableToken(Song et al., 2026), a novel se- mantic speech tokenizer with superior noise robustness. It employs a multi-branch V oting- LFQ architecture and adopts a bit-wise vot- ing mechanism and a noise-aware training strategy to extract noise-irrelevant semantic speech tokens. E ESC-10 Token Sequence t-SNE Visualization Results To further investigate t...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.