SVI-Bench: A Dynamic Microworld for Strategic Video Intelligence
Pith reviewed 2026-06-28 22:55 UTC · model grok-4.3
The pith
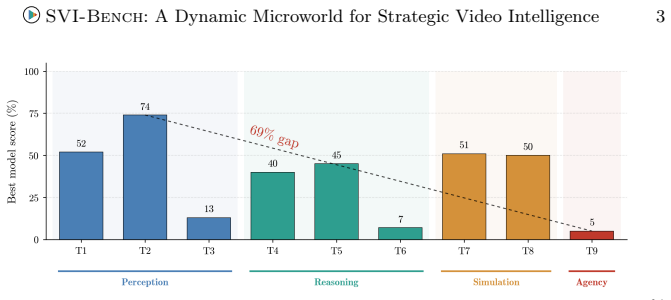
SVI-Bench shows video models reach 73 percent on action recognition but fall to 5 percent on tasks that require gathering evidence across clips and planning actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
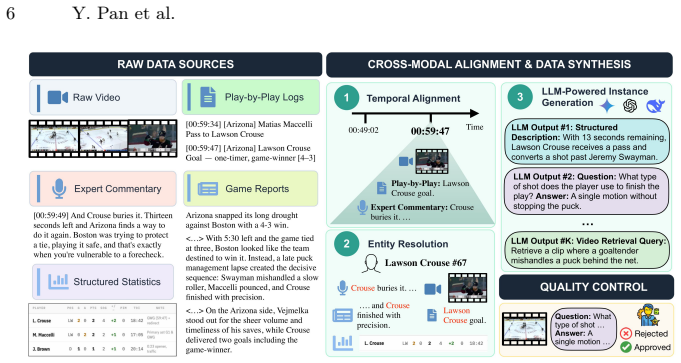
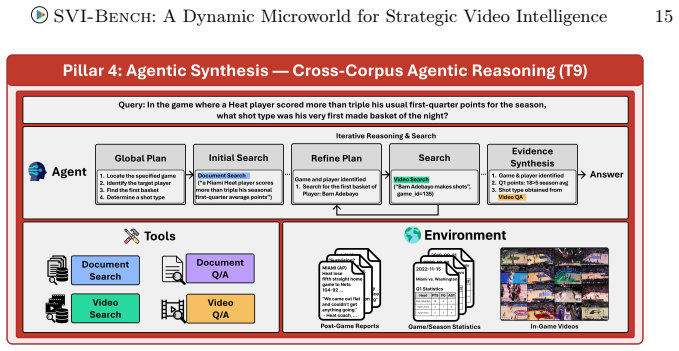
SVI-Bench converts 35K hours of basketball, soccer, and hockey footage plus commentary and statistics into a dense corpus that supports questions at four successive cognitive stages: Dynamic Scene Understanding, Causal Reasoning, Strategic Simulation, and Agentic Synthesis. The data engine cross-references 15M actions, 15K hours of commentary, and 103K statistical records to create ground-truth answers. When tested, leading models achieve roughly 73 percent on fine-grained action questions yet the strongest reaches only 5 percent when required to autonomously collect and integrate information across a corpus of 1.8M clips.
What carries the argument
The four-pillar task hierarchy that maps perception, causal explanation, outcome simulation, and autonomous evidence gathering onto the same underlying sports recordings.
If this is right
- Architectures tuned only for single-clip perception will not transfer to tasks that require cross-clip search and decision making.
- Existing video benchmarks that stop at action recognition will miss the largest performance gaps in current systems.
- Sports footage supplies a scalable source of multi-agent interactions whose outcomes are fixed by published rules.
- Agentic synthesis tasks expose the current inability of multimodal models to plan their own information collection.
- Progress on the higher pillars will require new training signals that reward simulation accuracy and evidence integration.
Where Pith is reading between the lines
- If the measured cliff is real, future training should add explicit losses for causal and planning consistency rather than perception alone.
- The same data engine could be applied to other rule-governed domains such as traffic or laboratory procedures to test whether the hierarchy generalizes.
- Low agentic scores suggest that pairing vision models with explicit search or planning modules may close more of the gap than scaling perception alone.
Load-bearing premise
The ordering of tasks by cognitive demand actually tracks increasing strategic difficulty instead of incidental differences in how the clips or questions were selected or labeled.
What would settle it
An experiment in which the same models achieve comparable accuracy on all four pillars, or a re-analysis showing that accuracy gaps align with video length or question format rather than the intended cognitive stages.
Figures






read the original abstract
True video intelligence demands more than recognizing what is visible: it requires reasoning about why events unfold, predicting what would change under different conditions, and deciding what to do next. We refer to this progression, from perception through causal reasoning and simulation to strategic planning, as Strategic Video Intelligence (SVI). No existing benchmark evaluates this capability stack: in-the-wild videos lack verifiable ground truth for causal and strategic questions, while synthetic environments sacrifice the complexity of real multi-agent systems. To bridge this gap, we introduce SVI-Bench, a large-scale benchmark that leverages team sports as a dynamic microworld, combining the complexity of real-world multi-agent interaction (10-22 agents making coordinated decisions under adversarial pressure) with the verifiability of explicit rules and definitive outcomes. SVI-Bench comprises approximately 35K hours of broadcast video, 15M annotated actions, 15K hours of expert commentary, 23K game reports, and 103K structured statistical records across basketball, soccer, and hockey, all constructed via a data engine that transforms raw game data into a dense, cross-referenced corpus. We organize evaluation into 9 tasks spanning a progressive four-pillar hierarchy: Dynamic Scene Understanding, Causal Reasoning, Strategic Simulation, and Agentic Synthesis. Evaluating strong multimodal and agentic baselines, we find a capability cliff: models perform competently on perceptual tasks, achieving approximately 73% on fine-grained action QA, but degrade sharply at each successive cognitive level. Agentic tasks prove hardest: the strongest model achieves only 5% accuracy when required to autonomously gather and integrate evidence across a corpus of 1.8M clips.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SVI-Bench, a large-scale benchmark for Strategic Video Intelligence (SVI) that uses broadcast team-sports video (basketball, soccer, hockey) as a dynamic microworld. It assembles ~35K hours of video, 15M annotated actions, expert commentary, game reports, and statistical records via a data engine, then organizes evaluation into 9 tasks across a four-pillar hierarchy (Dynamic Scene Understanding, Causal Reasoning, Strategic Simulation, Agentic Synthesis). Strong multimodal and agentic baselines are reported to reach ~73% on fine-grained action QA yet fall to 5% on the hardest agentic tasks that require autonomous evidence gathering across a 1.8M-clip corpus.
Significance. If the four-pillar tasks and sports-derived data engine can be shown to isolate the claimed cognitive progression without dataset artifacts or model shortcuts, the benchmark would supply a valuable, verifiable testbed for video understanding beyond perception. The scale (35K hours, 15M actions, explicit rules and outcomes) and the explicit contrast with both in-the-wild and fully synthetic environments are genuine strengths that could support reproducible progress on causal and strategic reasoning.
major comments (3)
- [Abstract] Abstract: the central empirical claim of a 'capability cliff' (73% perceptual to 5% agentic) cannot be evaluated because the manuscript supplies no task definitions, question formats, answer distributions, or annotation protocols for the nine tasks. Without these, it is impossible to determine whether performance differences track the intended cognitive hierarchy or reflect dataset regularities (recurring play sequences, commentary correlations) or annotation biases.
- [Abstract] Abstract / data-engine description: the claim that the sports microworld supplies 'verifiability of explicit rules and definitive outcomes' while preserving real multi-agent complexity is load-bearing for the benchmark's validity, yet no controls are described for statistical shortcuts, commentary leakage, or the distinction between retrieval and autonomous evidence gathering in the agentic tasks.
- [Abstract] Abstract: baseline implementations, prompting strategies, and evaluation protocols for the 'strong multimodal and agentic baselines' are omitted, preventing assessment of whether the reported 5% agentic accuracy reflects a genuine limitation or an artifact of how the 1.8M-clip corpus is accessed or how evidence integration is scored.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the abstract requires additional detail to allow independent evaluation of the capability cliff and data-engine claims. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of a 'capability cliff' (73% perceptual to 5% agentic) cannot be evaluated because the manuscript supplies no task definitions, question formats, answer distributions, or annotation protocols for the nine tasks. Without these, it is impossible to determine whether performance differences track the intended cognitive hierarchy or reflect dataset regularities (recurring play sequences, commentary correlations) or annotation biases.
Authors: The full manuscript provides task definitions, question formats, answer distributions, and annotation protocols in Sections 3.2–3.5 and the appendix, which ground the reported performance differences in the four-pillar hierarchy. The abstract is space-constrained, but we will add a concise paragraph summarizing the task structure, question types, and annotation process to enable direct assessment of whether the cliff reflects the intended progression. revision: yes
-
Referee: [Abstract] Abstract / data-engine description: the claim that the sports microworld supplies 'verifiability of explicit rules and definitive outcomes' while preserving real multi-agent complexity is load-bearing for the benchmark's validity, yet no controls are described for statistical shortcuts, commentary leakage, or the distinction between retrieval and autonomous evidence gathering in the agentic tasks.
Authors: Section 2 and the supplementary material describe the data engine's cross-referencing with official rules, play-by-play logs, and statistical records to enforce verifiability. Independent annotation streams and statistical filters are used to limit commentary leakage; agentic tasks explicitly require models to issue queries without pre-retrieved evidence. We will add a dedicated sentence to the abstract and expand the controls discussion in the main text. revision: yes
-
Referee: [Abstract] Abstract: baseline implementations, prompting strategies, and evaluation protocols for the 'strong multimodal and agentic baselines' are omitted, preventing assessment of whether the reported 5% agentic accuracy reflects a genuine limitation or an artifact of how the 1.8M-clip corpus is accessed or how evidence integration is scored.
Authors: Section 5 and the appendix fully specify the baseline models, prompting templates, corpus access interface, and scoring rubric for evidence integration. The 5% result uses a standardized agentic protocol in which models must autonomously retrieve and synthesize across the 1.8M-clip index. We will include a brief overview of these protocols in the revised abstract. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential fits
full rationale
The paper introduces SVI-Bench as a new dataset and task hierarchy for evaluating video intelligence, with all claims grounded in the construction of the data engine (35K hours video, 15M actions) and direct model evaluations on the 9 tasks. No equations, parameter fits, predictions, or uniqueness theorems appear that could reduce to inputs by construction. The four-pillar hierarchy is presented as an organizational choice for the benchmark, not derived from prior self-citations or ansatzes. Self-citations are absent from the provided text, and the capability cliff is reported as an empirical observation rather than a forced result. This is a standard non-circular benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Team sports videos offer verifiable ground truth for causal and strategic questions due to explicit rules and outcomes.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2102.03291 (2021),https: //arxiv.org/abs/2102.032915
Alcorn, M.A., Nguyen, A.: baller2vec: A multi-entity transformer for multi- agent spatiotemporal modeling. arXiv preprint arXiv:2102.03291 (2021),https: //arxiv.org/abs/2102.032915
-
[2]
In: Advances in Neural Information Processing Systems (NeurIPS) (2024) 5
Alonso, E., Jelley, A., Micheli, V., Kanervisto, A., Storkey, A., Pearce, T., Fleuret, F.: Diffusion for world modeling: Visual details matter in atari. In: Advances in Neural Information Processing Systems (NeurIPS) (2024) 5
2024
-
[3]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Anne Hendricks, L., Wang, O., Shechtman, E., Sivic, J., Darrell, T., Russell, B.: Localizing moments in video with natural language. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 5803–5812 (2017) 9
2017
-
[4]
In: Advances in Neural Information Pro- cessing Systems (NeurIPS)
Bakhtin, A., van der Maaten, L., Johnson, J., Gustafson, L., Girshick, R.: Phyre: A new benchmark for physical reasoning. In: Advances in Neural Information Pro- cessing Systems (NeurIPS). vol. 32 (2019) 3, 5
2019
-
[5]
In: International Conference on Learning Represen- tations (ICLR) (2020) 5
Baradel, F., Neverova, N., Mille, J., Mori, G., Wolf, C.: Cophy: Counterfactual learning of physical dynamics. In: International Conference on Learning Represen- tations (ICLR) (2020) 5
2020
-
[6]
In: Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track (2021) 5
Bear, D., Wang, E., Mrowca, D., Brock, F., Tung, H.Y., Pramod, R., Holdaway, C., Tao, S., Smith, K., Sun, F.Y.: Physion: Evaluating physical prediction from vision in humans and machines. In: Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track (2021) 5
2021
-
[7]
In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020) 12
Bertasius, G., Torresani, L.: Classifying, segmenting, and tracking object instances in video with mask propagation. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020) 12
2020
-
[8]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion mod- els. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22563–22575 (2023) 13 SVI-Bench: A Dynamic Microworld for Strategic Video Intelligence 19
2023
-
[9]
In: International Conference on Machine Learning (ICML) (2024) 5
Bruce, J., Dennis, M., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M.: Genie: Generative interactive environments. In: International Conference on Machine Learning (ICML) (2024) 5
2024
-
[10]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Caba Heilbron, F., Escorcia, V., Ghanem, B., Carlos Niebles, J.: Activitynet: A large-scale video benchmark for human activity understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 961–970 (2015) 4
2015
-
[11]
In: arXiv preprint arXiv:1907.06987 (2019) 4
Carreira, J., Noland, E., Hillier, C., Zisserman, A.: A short note on the kinetics-700 human action dataset. In: arXiv preprint arXiv:1907.06987 (2019) 4
-
[12]
doi: 10.1080/01621459.2016.1211016
Cervone, D., D’Amour, A., Bornn, L., Goldsberry, K.: A multiresolution stochastic process model for predicting basketball possession outcomes. Journal of the Ameri- can Statistical Association111(514), 585–599 (2016).https://doi.org/10.1080/ 01621459.2016.11416855
-
[13]
In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
Chen, M., Chu, Z., Wiseman, S., Gimpel, K.: Summscreen: A dataset for ab- stractive screenplay summarization. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL). pp. 8602–8615 (2022) 11
2022
-
[14]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems
Chen, T., Liu, H., He, T., Chen, Y., Gan, C., Ma, X., Zhong, C., Zhang, Y., Wang, Y., Lin, H., Lin, W.: Mecd: unlocking multi-event causal discovery in video reason- ing. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. NeurIPS ’24, Curran Associates Inc., Red Hook, NY, USA (2024) 5
2024
-
[15]
arXiv preprint arXiv:2312.06722 (2023) 5
Chen, Y., Ge, Y., Ge, Y., Ding, M., Li, B., Wang, R., Xu, R., Shan, Y., Liu, X.: Egoplan-bench: Benchmarking multimodal large language models for human-level planning. arXiv preprint arXiv:2312.06722 (2023) 5
-
[16]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Cioppa, A., Giancola, S., Deliège, A., Kang, L., Zhou, X., Cheng, Z., Ghanem, B., Van Droogenbroeck, M.: Soccernet-tracking: Multiple object tracking dataset and benchmark in soccer videos. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 3491–3502 (2022) 5
2022
-
[17]
Clark, C., Zhang, J., Ma, Z., Park, J.S., Salehi, M., Tripathi, R., Lee, S., Ren, Z., Kim, C.D., Yang, Y., Shao, V., Yang, Y., Huang, W., Gao, Z., Anderson, T., Zhang, J., Jain, J., Stoica, G., Han, W., Farhadi, A., Krishna, R.: Molmo2: Open weights and data for vision-language models with video understanding and grounding (2026),https://arxiv.org/abs/260...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cui, Y., Zeng, C., Zhao, X., Yang, Y., Wu, G., Wang, L.: Sportsmot: A large multi- object tracking dataset in multiple sports scenes. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9921–9931 (2023) 5
2023
-
[19]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Deliège, A., Cioppa, A., Giancola, S., Seber, M.J., Dueholm, J.V., Nasrollahi, K., Ghanem,B.,Moeslund,T.B.,VanDroogenbroeck,M.:Soccernet-v2:Adatasetand benchmarks for holistic understanding of broadcast soccer videos. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 4508–4519 (2021) 5
2021
-
[20]
In: Eu- ropean Conference on Computer Vision (ECCV)
Felsen, P., Lucey, P., Ganguly, S.: Where will they go? predicting fine-grained adversarial multi-agent motion using conditional variational autoencoders. In: Eu- ropean Conference on Computer Vision (ECCV). pp. 732–747 (2018) 5
2018
-
[21]
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., Chen, P., Li, Y., Lin, S., Zhao, S., Li, K., Xu, T., Zheng, X., Chen, E., Shan, C., He, R., Sun, X.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis (2025),https://arxiv.org/abs/ 2405.210753, 5, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team: Gemini: A family of highly capable multimodal models (2025), https://arxiv.org/abs/2312.118055 20 Y. Pan et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Giancola, S., Amine, M., Dghaily, T., Ghanem, B.: Soccernet: A scalable dataset foractionspottinginsoccervideos.In:IEEE/CVFConferenceonComputerVision and Pattern Recognition Workshops (CVPRW). pp. 1711–1721 (2018) 5
2018
-
[24]
International Conference on Learning Representations (ICLR) (2024) 13
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion mod- els without specific tuning. International Conference on Learning Representations (ICLR) (2024) 13
2024
-
[25]
In: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Gupta, A., Johnson, J., Fei-Fei, L., Savarese, S., Alahi, A.: Social gan: Socially ac- ceptable trajectories with generative adversarial networks. In: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 2255–2264 (2018) 10
2018
-
[26]
Ha, D., Schmidhuber, J.: World models. In: arXiv preprint arXiv:1803.10122 (2018) 5
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
In: International Conference on Learning Representations (ICLR) (2021) 5
Hafner, D., Lillicrap, T., Norouzi, M., Ba, J.: Mastering atari with discrete world models. In: International Conference on Learning Representations (ICLR) (2021) 5
2021
-
[28]
Mastering Diverse Domains through World Models
Hafner, D., Pasukonis, J., Ba, J., Lillicrap, T.: Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104 (2023) 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
arXiv preprint arXiv:2311.08414 (2023) 11
He, J., et al.: Autolecture: Automatic lecture summarization with large language models. arXiv preprint arXiv:2311.08414 (2023) 11
-
[30]
In: Advances in Neural Information Processing Systems (NeurIPS) (2022) 5, 13
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video dif- fusion models. In: Advances in Neural Information Processing Systems (NeurIPS) (2022) 5, 13
2022
-
[31]
Idrees, H., Zamir, A.R., Jiang, Y.G., Gorban, A., Laptev, I., Sukthankar, R., Shah, M.: The thumos challenge on action recognition for videos “in the wild”. Computer Vision and Image Understanding155, 1–23 (Feb 2017).https://doi.org/10. 1016/j.cviu.2016.10.018,http://dx.doi.org/10.1016/j.cviu.2016.10.0184
- [32]
-
[33]
The Kinetics Human Action Video Dataset
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017) 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Krishna,R.,Hata,K.,Ren,F.,Fei-Fei,L.,Niebles,J.C.:Dense-captioningeventsin videos. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 706–715 (2017) 7, 9
2017
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025) 12
Lee, Y.C., Lu, E., Rumbley, S., Geyer, M., Huang, J.B., Dekel, T., Cole, F.: Gener- ative omnimatte: Learning to decompose video into layers. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025) 12
2025
-
[36]
arXiv preprint arXiv:2602.00288 (2026) 5
Li, B., Zhao, K., Zhang, C., Mitra, C., Nyandwi, J.d.D., Bertasius, G.: TimeBlind: A spatio-temporal compositionality benchmark for video LLMs. arXiv preprint arXiv:2602.00288 (2026) 5
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2022) 5
Li, J., Niu, L., Zhang, L.: From representation to reasoning: Towards both evidence and commonsense reasoning for video question-answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2022) 5
2022
-
[38]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) (2023) 14 SVI-Bench: A Dynamic Microworld for Strategic Video Intelligence 21
Li, M., Song, F., Yu, B., Yu, H., Li, Z., Huang, F., Li, Y.: Api-bank: A com- prehensive benchmark for tool-augmented llms. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) (2023) 14 SVI-Bench: A Dynamic Microworld for Strategic Video Intelligence 21
2023
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Q., Xing, Z., Wang, R., Zhang, H., Dai, Q., Wu, Z.: Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12112–12123 (2025) 12
2025
-
[40]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Liang, J., Jiang, L., Murphy, K., Yu, T., Hauptmann, A.: The garden of forking paths: Towards multi-future trajectory prediction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10508– 10518 (2020) 10
2020
-
[41]
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection (2023) 5
2023
-
[42]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning (2023),https:// arxiv.org/abs/2304.084855
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [43]
-
[44]
TempCompass: Do Video LLMs Really Understand Videos?
Liu, Y., Li, S., Liu, Y., Wang, Y., Ren, S., Li, L., Chen, S., Sun, X., Hou, L.: Tempcompass: Do video llms really understand videos? (2024),https://arxiv. org/abs/2403.004765
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Luo, N., Cao, Z., Mamitsuka, H., Zhu, S.: From tracking data to play prediction: A deep learning approach for basketball possession outcomes. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining(KDD).pp.1866–1876.ACM(2020).https://doi.org/10.1145/3394486. 34030555
-
[46]
arXiv preprint arXiv:2401.00896 (2024) 12
Ma, W.D.K., Huang, J., Kolkin, N., et al.: Trailblazer: Trajectory control for diffusion-based video generation. arXiv preprint arXiv:2401.00896 (2024) 12
-
[47]
Advances in Neural Information Processing Systems36(2024) 3, 4, 5, 8
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems36(2024) 3, 4, 5, 8
2024
-
[48]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Mangalam, K., Girase, H., Aber, S., Lee, J., Malik, J.: It is not the journey but the destination: Endpoint conditioned trajectory prediction. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 759–776 (2020) 10
2020
-
[49]
International Conference on Learning Repre- sentations (ICLR) (2024) 14
Mialon, G., Fourrier, C., Swift, C., Wolf, T., LeCun, Y., Scialom, T.: Gaia: A benchmark for general ai assistants. International Conference on Learning Repre- sentations (ICLR) (2024) 14
2024
-
[50]
In: International Conference on Learning Representations (2023) 5
Micheli,V.,Alonso,E.,Fleuret,F.:Transformersaresample-efficientworldmodels. In: International Conference on Learning Representations (2023) 5
2023
-
[51]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) (2023) 11
Min, S., Krishna, K., Lyu, X., Lewis, M., Yih, W.t., Koh, P.W., Iyyer, M., Zettle- moyer, L., Hajishirzi, H.: Factscore: Fine-grained atomic evaluation of factual pre- cision in long form text generation. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) (2023) 11
2023
-
[52]
In: arXiv preprint arXiv:2411.04989 (2024) 12
Namekata, K., et al.: Sg-i2v: Self-guided trajectory control in image-to-video gen- eration. In: arXiv preprint arXiv:2411.04989 (2024) 12
-
[53]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA, Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., et al.: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025) 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
OpenAI: Gpt-4o system card (2024),https://arxiv.org/abs/2410.212765
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
arXiv preprint arXiv:2511.05489 (2025) 5, 14 22 Y
Pan, J., Zhang, Q., Zhang, R., Lu, M., Wan, X., Zhang, Y., Liu, C., She, Q.: Timesearch-r: Adaptive temporal search for long-form video understanding via self-verification reinforcement learning. arXiv preprint arXiv:2511.05489 (2025) 5, 14 22 Y. Pan et al
-
[56]
In: CVPR (2025) 5
Pan, Y., Zhang, C., Bertasius, G.: Basket: A large-scale video dataset for fine- grained skill estimation. In: CVPR (2025) 5
2025
-
[57]
In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL)
Papalampidi, P., Keller, F., Frermann, L., Lapata, M.: Screenplay summarization using latent narrative structure. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL). pp. 1920–1933 (2020) 11
1920
-
[58]
International Conference on Learning Representations (ICLR) (2024) 14
Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., et al.: Toolllm: Facilitating large language models to master 16000+ real- world apis. International Conference on Learning Representations (ICLR) (2024) 14
2024
-
[59]
Qwen Team: Qwen3 technical report (2025),https://arxiv.org/abs/2505.09388 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
arXiv preprint arXiv:2511.23477 (2025) 5
Rasheed, H., Zumri, M., Maaz, M., Yang, M.H., Khan, F.S., Khan, S.: Video- com: Interactive video reasoning via chain of manipulations. arXiv preprint arXiv:2511.23477 (2025) 5
-
[61]
arXiv preprint arXiv:2303.07109 (2023)
Robine, J., Höftmann, M., Uelwer, T., Harmeling, S.: Transformer-based world models are happy with 100k interactions. arXiv preprint arXiv:2303.07109 (2023). https://doi.org/10.48550/arXiv.2303.07109,https://arxiv.org/abs/2303. 071095
-
[62]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Rohrbach, A., Rohrbach, M., Tanber, N., Schiele, B.: A dataset for movie descrip- tion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3202–3212 (2015) 9
2015
-
[63]
In: European Conference on Computer Vision (ECCV)
Salzmann, T., Ivanovic, B., Chakravarty, P., Pavone, M.: Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. In: European Conference on Computer Vision (ECCV). pp. 683–700 (2020) 10
2020
-
[64]
Advances in neural information processing systems36, 68539–68551 (2023) 5
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettle- moyer, L., Cancedda, N., Scialom, T.: Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems36, 68539–68551 (2023) 5
2023
-
[65]
Nature588(7839), 604–609 (2020) 5
Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T.: Mastering Atari, Go, chess and shogi by planning with a learned model. Nature588(7839), 604–609 (2020) 5
2020
-
[66]
Nature550(7676), 354–359 (2017) 5
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A.: Mastering the game of go without human knowledge. Nature550(7676), 354–359 (2017) 5
2017
-
[67]
In: International Conference on Learning Representations (ICLR) (2023) 13
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., Parikh, D., Gupta, S., Taigman, Y.: Make-a-video: Text-to- video generation without text-video data. In: International Conference on Learning Representations (ICLR) (2023) 13
2023
- [68]
-
[69]
In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition
Tapaswi, M., Zhu, Y., Stiefelhagen, R., Torralba, A., Urtasun, R., Fidler, S.: Movieqa: Understanding stories in movies through question-answering. In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition. pp. 4631–4640 (2016) 9
2016
-
[70]
Team Wan: Wan: Open and advanced large-scale video generative models (2025), https://arxiv.org/abs/2503.2031412
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025) 12 SVI-Bench: A Dynamic Microworld for Strategic Vide...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Nature575(7782), 350–354 (2019) 5
Vinyals, O., Babuschkin, I., Czarnecki, W.M., Mathieu, M., Dudzik, A., Chung, J., Choi, D.H., Powell, R., Ewalds, T., Georgiev, P.: Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature575(7782), 350–354 (2019) 5
2019
-
[73]
arXiv preprint arXiv:2505.22944 (2025) 12
Wang, A., Huang, H., Fang, J.Z., Yang, Y., Ma, C.: Ati: Any trajectory instruction for controllable video generation. arXiv preprint arXiv:2505.22944 (2025) 12
-
[74]
Wang, G., Xie, Y., Jiang, Y., Mandlekar, A., Xiao, C., Zhu, Y., Fan, L., Anand- kumar, A.: Voyager: An open-ended embodied agent with large language models (2023),https://arxiv.org/abs/2305.162915
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[75]
arXiv preprint arXiv:2402.01566 (2024) 12
Wang, J., et al.: Boximator: Generating rich and controllable motions for video synthesis. arXiv preprint arXiv:2402.01566 (2024) 12
-
[76]
Wang, S., Jin, J., Wang, X., Song, L., Fu, R., Wang, H., Ge, Z., Lu, Y., Cheng, X.: Video-thinker: Sparking" thinking with videos" via reinforcement learning. arXiv preprint arXiv:2510.23473 (2025) 5
-
[77]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, X., Wu, J., Chen, J., Li, L., Wang, Y.F., Wang, W.Y.: Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4581–4591 (2019) 7
2019
-
[78]
Wei, J., Sun, Z., Papay, S., McKinney, S., Han, J., Fulford, I., Chung, H.W., Passos, A.T., Fedus, W., Glaese, A.: Browsecomp: A simple yet challenging benchmark for browsing agents (2025),https://arxiv.org/abs/2504.1251614
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
157543, 5
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context interleaved video-language understanding (2024),https://arxiv.org/abs/2407. 157543, 5
2024
-
[80]
arXiv preprint arXiv:2511.06499 (2025) 5
Xia, H., Ge, H., Zou, J., Choi, H.W., Zhang, X., Suradja, D., Rui, B., Tran, E., Jin, W., Ye, Z., Lin, X., Lai, C., Zhang, S., Miao, J., Chen, S., Tracy, R., Ordonez, V., Shen, W., Chen, H.: SportR: A benchmark for multimodal large language model reasoning in sports. arXiv preprint arXiv:2511.06499 (2025) 5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.