SPADER: Step-wise Peer Advantage with Diversity-Aware Exploration Rewards for Multi-Answer Question Answering
Pith reviewed 2026-06-28 18:51 UTC · model grok-4.3
The pith
SPADER aligns parallel trajectories by decision step to assign step-level credit without a critic and adds a diversity reward to discover long-tail answers in multi-answer QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
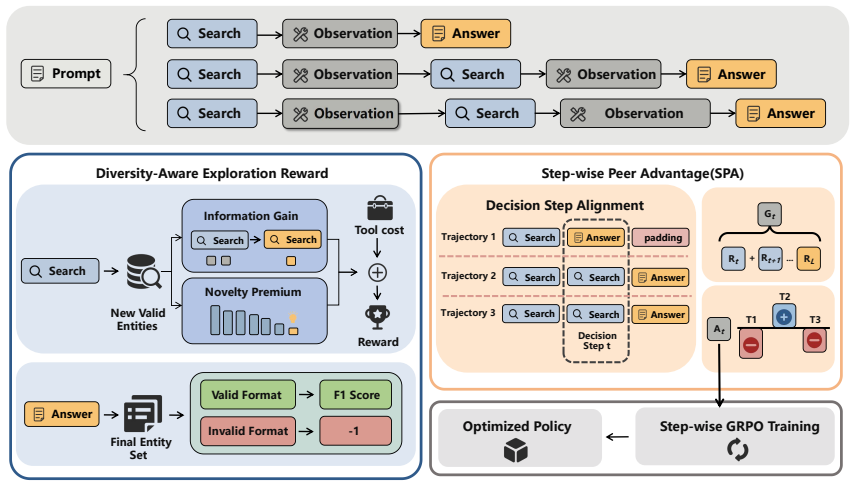
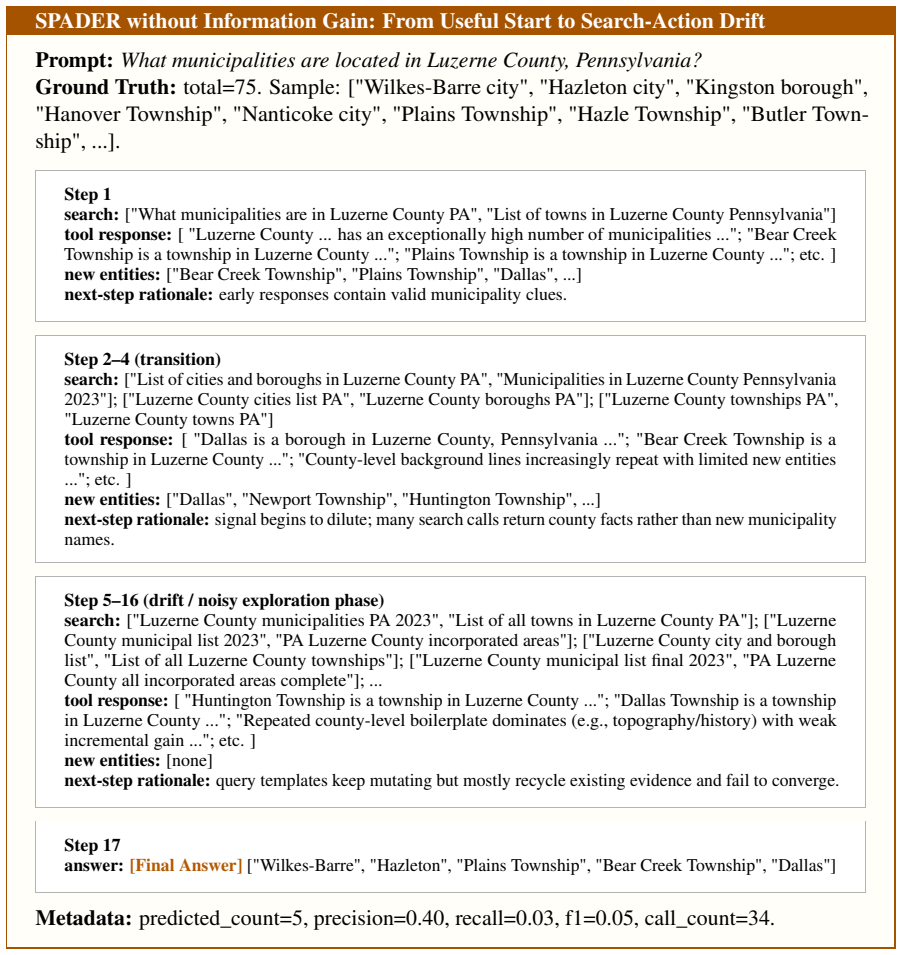
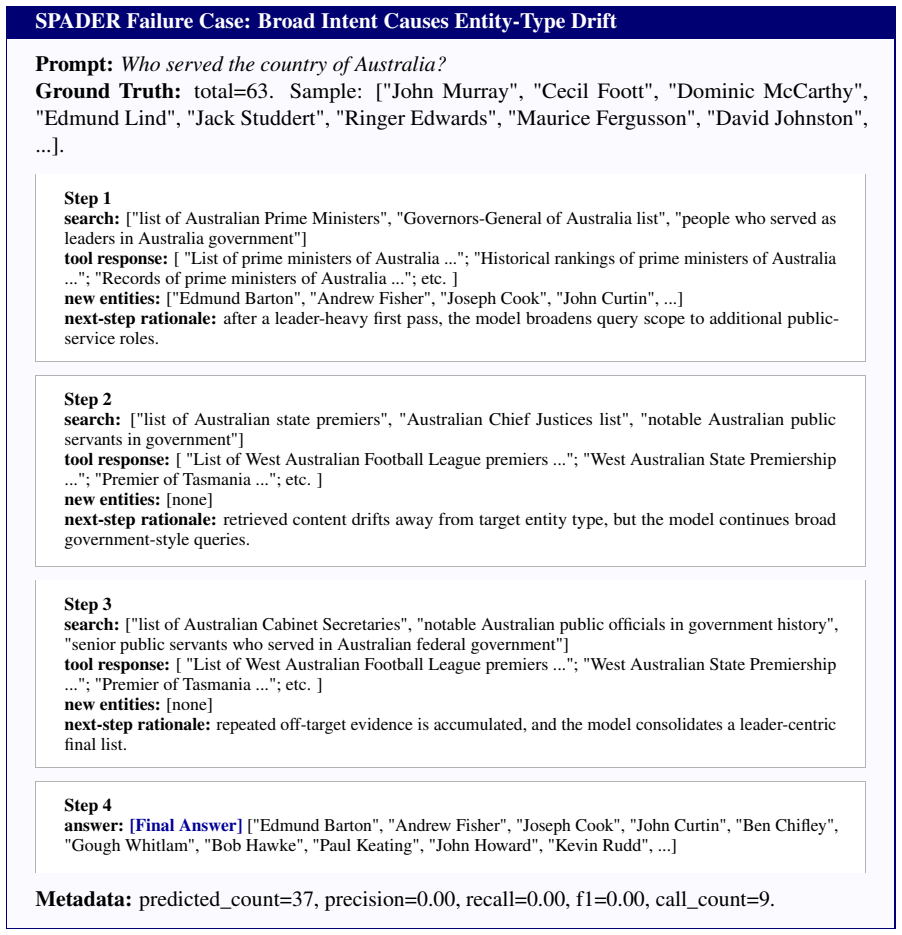
SPADER is a reinforcement learning framework for long-horizon tool use in Multi-Answer QA. It includes Step-wise Peer Advantage (SPA), a critic-free step-level credit assignment mechanism that aligns parallel trajectories by decision step and estimates advantages from peer returns. It also includes a diversity-aware exploration reward that promotes long-tail entity discovery by upweighting rare findings and downweighting redundant ones.
What carries the argument
Step-wise Peer Advantage (SPA), which aligns parallel trajectories by decision step to estimate advantages from peer returns without a critic, paired with the diversity-aware exploration reward.
If this is right
- Step-level credit can be obtained from peer returns in parallel rollouts instead of training a separate value network.
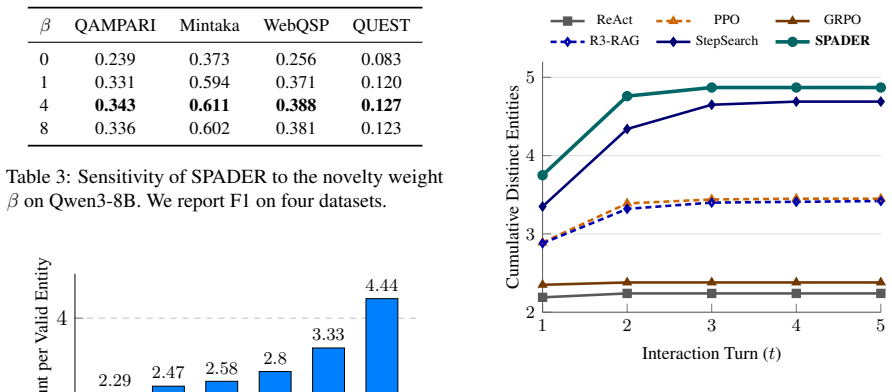
- A reward that upweights rare entities and downweights repeats sustains exploration of comprehensive answer sets.
- The combined method yields higher recall and F1 than prompting, outcome-supervised RL, and earlier step-supervision baselines on QAMPARI, Mintaka, WebQSP, and QUEST.
- The approach operates on top of existing tool-augmented agents without changing the underlying language model architecture.
Where Pith is reading between the lines
- The peer-alignment technique may transfer to other long-horizon tasks that have multiple valid terminal states, such as open-ended planning or multi-goal navigation.
- Diversity-aware rewards could be combined with other credit-assignment methods to reduce mode collapse in multi-solution search problems.
- Testing whether the diversity term reduces frequency bias in entity retrieval on new domains would check an implicit robustness claim.
Load-bearing premise
Aligning parallel trajectories by decision step and estimating advantages from peer returns, together with the diversity reward, sufficiently solves fine-grained credit assignment and sustained exploration in long-horizon tool use for multi-answer QA without introducing new biases or requiring additional supervision.
What would settle it
A controlled run on QAMPARI or Mintaka in which SPADER produces lower recall or F1 than the strongest outcome-supervised baseline while using the same number of trajectories would falsify the central performance claim.
Figures





read the original abstract
Large language models are increasingly deployed as tool-augmented agents to acquire information beyond parametric knowledge. While recent work has improved long-horizon tool-use reasoning, most approaches focus on tasks with a single correct answer. In contrast, many real-world queries require discovering a comprehensive set of valid answers, a setting known as Multi-Answer QA. This setting raises two challenges: fine-grained credit assignment over long search trajectories and reward alignment for sustained exploration beyond easy high-frequency entities. We propose SPADER, a reinforcement learning framework for long-horizon tool use in Multi-Answer QA. SPADER includes Step-wise Peer Advantage (SPA), a critic-free step-level credit assignment mechanism that aligns parallel trajectories by decision step and estimates advantages from peer returns. It also includes a diversity-aware exploration reward that promotes long-tail entity discovery by upweighting rare findings and downweighting redundant ones. Experiments on QAMPARI, Mintaka, WebQSP, and QUEST show that SPADER generally improves recall and overall F1 over prompting-based agents, outcome-supervised RL methods, and recent step-level supervision approaches. Our code and model weights are available at https://github.com/KhanCold/spader.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPADER, an RL framework for long-horizon tool-augmented agents in Multi-Answer QA. It introduces Step-wise Peer Advantage (SPA), a critic-free mechanism that aligns parallel trajectories by decision step to estimate advantages from peer returns, and a diversity-aware exploration reward that upweights rare entity discoveries while downweighting redundancies. Experiments across QAMPARI, Mintaka, WebQSP, and QUEST report general gains in recall and F1 over prompting-based agents, outcome-supervised RL, and recent step-level supervision baselines; code and weights are released.
Significance. If the reported gains prove robust, the work offers a practical approach to fine-grained credit assignment and sustained exploration in multi-answer settings without requiring a learned critic or additional supervision signals. The open release of code strengthens reproducibility.
major comments (1)
- [Experiments] The abstract and method overview claim performance improvements, but the experimental section provides insufficient detail on baseline re-implementations, hyperparameter matching, statistical significance testing, and controls against post-hoc selection; this directly affects verification of the central empirical claim.
minor comments (1)
- [Method] Notation for the diversity reward (e.g., how rarity is quantified and how the up/down-weighting is normalized) should be formalized with an equation for clarity.
Simulated Author's Rebuttal
We thank the referee for the feedback on our experimental reporting. We address the single major comment below.
read point-by-point responses
-
Referee: [Experiments] The abstract and method overview claim performance improvements, but the experimental section provides insufficient detail on baseline re-implementations, hyperparameter matching, statistical significance testing, and controls against post-hoc selection; this directly affects verification of the central empirical claim.
Authors: We agree the experimental section would benefit from greater transparency to support verification. In the revised version we will add: (1) explicit descriptions of baseline re-implementations, including any code-level adaptations and sources; (2) a consolidated hyperparameter table showing settings for SPADER and all baselines with notes on matching; (3) statistical significance results (paired t-tests over 5 random seeds with reported p-values); and (4) a short paragraph on evaluation protocol confirming that all methods were run under identical conditions and that no post-hoc selection of configurations occurred. These additions will be placed in Section 4 and the appendix. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces SPADER as an empirical RL framework for multi-answer QA, defining SPA as a step-level credit assignment via peer trajectory alignment and a diversity reward for exploration. These are presented as novel algorithmic components whose value is demonstrated through benchmark experiments rather than any closed-form derivation, prediction from fitted parameters, or self-referential definitions. No equations, uniqueness theorems, or ansatzes appear in the abstract or description that would reduce the claimed improvements to inputs by construction; the central claims rest on external experimental comparisons.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , address =
Amouyal, Samuel and Wolfson, Tomer and Rubin, Ohad and Yoran, Ori and Herzig, Jonathan and Berant, Jonathan , booktitle =. 2023 , address =
2023
-
[2]
Proceedings of the 29th International Conference on Computational Linguistics , month = oct, year =
Mintaka: A Complex, Natural, and Multilingual Dataset for End-to-End Question Answering , author =. Proceedings of the 29th International Conference on Computational Linguistics , month = oct, year =
-
[3]
The Value of Semantic Parse Labeling for Knowledge Base Question Answering
The Value of Semantic Parse Labeling for Knowledge Base Question Answering , author =. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , month = aug, year =. doi:10.18653/v1/P16-2033 , pages =
-
[4]
Malaviya, Chaitanya and Shaw, Peter and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =. 2023 , address =. doi:10.18653/v1/2023.acl-long.784 , pages =
-
[5]
2023 , url=
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R Narasimhan and Yuan Cao , booktitle=. 2023 , url=
2023
-
[6]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Zheng, Xuhui and An, Kang and Wang, Ziliang and Wang, Yuhang and Wu, Yichao , booktitle =. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.1106 , pages =
-
[9]
Li, Yuan and Luo, Qi and Li, Xiaonan and Li, Bufan and Cheng, Qinyuan and Wang, Bo and Zheng, Yining and Wang, Yuxin and Yin, Zhangyue and Qiu, Xipeng , booktitle =. R3-. 2025 , address =. doi:10.18653/v1/2025.findings-emnlp.554 , pages =
-
[10]
Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation , author=. arXiv preprint arXiv:2402.03216 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Robertson, Stephen and Zaragoza, Hugo , title =. 2009 , issue_date =. doi:10.1561/1500000019 , journal =
-
[12]
Proceedings of the 37th International Conference on Machine Learning , pages =
Retrieval Augmented Language Model Pre-Training , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , volume =
2020
-
[13]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume=
-
[14]
Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, year =
Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, year =. doi:10.18653/v1/2023.findings-emnlp.620 , pages =
-
[15]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/2023.acl-long.557 , pages =
-
[16]
Guan, Xinyan and Zeng, Jiali and Meng, Fandong and Xin, Chunlei and Lu, Yaojie and Lin, Hongyu and Han, Xianpei and Sun, Le and Zhou, Jie , booktitle=. Deep. 2026 , url=
2026
-
[17]
Search-o1: Agentic Search-Enhanced Large Reasoning Models , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.276 , pages =
-
[18]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
R1-searcher: Incentivizing the search capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2503.05592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Zheng, Yuxiang and Fu, Dayuan and Hu, Xiangkun and Cai, Xiaojie and Ye, Lyumanshan and Lu, Pengrui and Liu, Pengfei , booktitle =. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.22 , pages =
-
[20]
International Conference on Learning Representations , pages=
Let's Verify Step by Step , author=. International Conference on Learning Representations , pages=
-
[21]
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering , author =. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , month = apr, year =. doi:10.18653/v1/2021.eacl-main.74 , pages =
-
[22]
Journal of Machine Learning Research , volume=
Atlas: Few-shot learning with retrieval augmented language models , author=. Journal of Machine Learning Research , volume=
-
[23]
Dense Passage Retrieval for Open-Domain Question Answering
Dense Passage Retrieval for Open-Domain Question Answering , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , month = nov, year =. doi:10.18653/v1/2020.emnlp-main.550 , pages =
-
[24]
International Conference on Learning Representations , year=
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval , author=. International Conference on Learning Representations , year=
-
[25]
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle =. 2018 , address =. doi:10.18653/v1/D18-1259 , pages =
-
[26]
♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal =. 2022 , address =. doi:10.1162/tacl_a_00475 , pages =
-
[27]
Min, Sewon and Michael, Julian and Hajishirzi, Hannaneh and Zettlemoyer, Luke , booktitle =. 2020 , address =. doi:10.18653/v1/2020.emnlp-main.466 , pages =
-
[28]
Solving math word problems with process- and outcome-based feedback
Solving math word problems with process-and outcome-based feedback , author=. arXiv preprint arXiv:2211.14275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Hybridflow: A flexible and efficient rlhf framework
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , title =. 2025 , publisher =. doi:10.1145/3689031.3696075 , booktitle =
-
[30]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and...
-
[31]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Alex Vaughan and Amy Yang and Angela Fan and Anirudh Goyal and Anthony Hartshorn and Aobo Yang and Archi Mitra and Archie Sravankumar and Artem Korenev and Arthur Hinsvark and Arun Rao ...
2024
-
[32]
and Gillhofer, Michael and Widrich, Michael and Unterthiner, Thomas and Brandstetter, Johannes and Hochreiter, Sepp , booktitle =
Arjona-Medina, Jose A. and Gillhofer, Michael and Widrich, Michael and Unterthiner, Thomas and Brandstetter, Johannes and Hochreiter, Sepp , booktitle =. RUDDER: Return Decomposition for Delayed Rewards , url =
-
[33]
2018 , edition=
Reinforcement Learning: An Introduction , author=. 2018 , edition=
2018
-
[34]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Asynchronous Methods for Deep Reinforcement Learning , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , volume =
2016
-
[35]
Proceedings of the 35th International Conference on Machine Learning , pages =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , volume =
2018
-
[36]
Ahmadian, Arash and Cremer, Chris and Gall. Back to Basics: Revisiting. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =. doi:10.18653/v1/2024.acl-long.662 , pages =
-
[37]
Group-in-Group Policy Optimization for
Feng, Lang and Xue, Zhenghai and Liu, Tingcong and An, Bo , booktitle=. Group-in-Group Policy Optimization for
-
[38]
Li, Jiazheng and Wang, Yawei and Yan, Qiaojing and Tian, Yijun and Xu, Zhichao and Song, Huan and Xu, Panpan and Cheong, Lin Lee , booktitle =. 2026 , address =. doi:10.18653/v1/2026.findings-eacl.247 , pages =
-
[39]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Unsupervised Question Decomposition for Question Answering , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , month = nov, year =. doi:10.18653/v1/2020.emnlp-main.713 , pages =
-
[41]
The Eleventh International Conference on Learning Representations , year=
Decomposed Prompting: A Modular Approach for Solving Complex Tasks , author=. The Eleventh International Conference on Learning Representations , year=
-
[42]
Baleen: Robust Multi-Hop Reasoning at Scale via Condensed Retrieval , url =
Khattab, Omar and Potts, Christopher and Zaharia, Matei , booktitle =. Baleen: Robust Multi-Hop Reasoning at Scale via Condensed Retrieval , url =
-
[43]
Answering Open-Domain Questions of Varying Reasoning Steps from Text , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2021.emnlp-main.292 , pages =
-
[44]
Evidentiality-guided Generation for Knowledge-Intensive
Asai, Akari and Gardner, Matt and Hajishirzi, Hannaneh , booktitle =. Evidentiality-guided Generation for Knowledge-Intensive. 2022 , address =. doi:10.18653/v1/2022.naacl-main.162 , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.