Taming the Loss Landscape of PINNs with Noisy Feynman-Kac Supervision: Operator Preconditioning and Non-Asymptotic Error Bounds
Pith reviewed 2026-06-28 18:16 UTC · model grok-4.3
The pith
A pointwise data-fidelity term preconditions the PINN loss operator, reducing its condition number and enabling non-asymptotic L2 error bounds for FK-PINNs with tanh networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the added pointwise data-fidelity term serves as an operator-level preconditioner for the PINN loss. Comparison bounds show that for appropriate weights the condition number is substantially smaller than that of the standard residual-plus-boundary loss, and this holds independently of the source of the pointwise labels. For the class of PDEs that admit a Feynman-Kac representation, Monte Carlo estimates of the FK functional supply the labels, producing FK-PINNs. For these networks with tanh activation, non-asymptotic L²(Ω) error bounds are obtained after finitely many gradient-descent steps. Pseudo-dimension bounds for the first- and second-order derivatives of tanh
What carries the argument
The pointwise data-fidelity supervision term added to residual and boundary losses, acting as an operator-level preconditioner.
Load-bearing premise
The PDE must belong to the class that admits a Feynman-Kac representation so Monte Carlo labels can be generated, and suitable weights for the data-fidelity term must exist to achieve the condition-number reduction.
What would settle it
A numerical computation showing that the condition number of the augmented loss exceeds that of the standard PINN loss for all weights on a test PDE, or that the observed L2 error after finite GD steps exceeds the derived bound by a large factor.
Figures
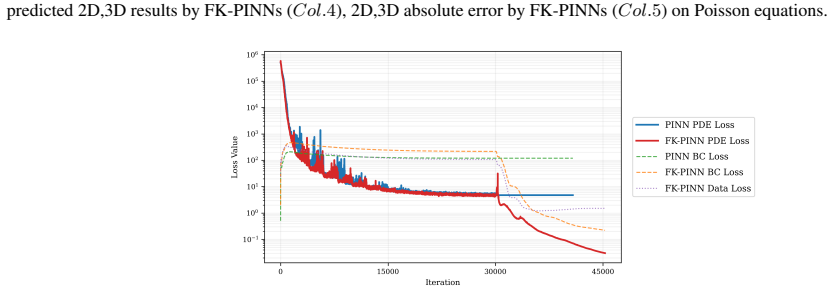
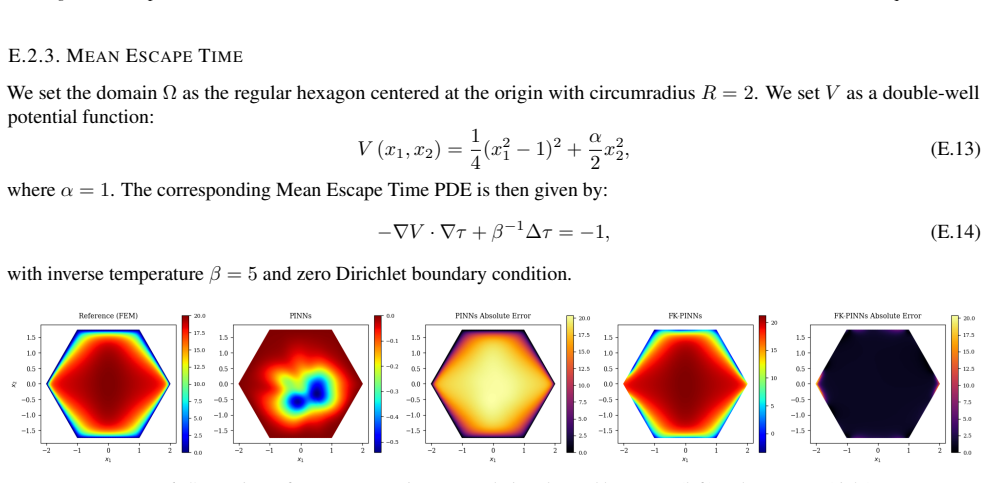
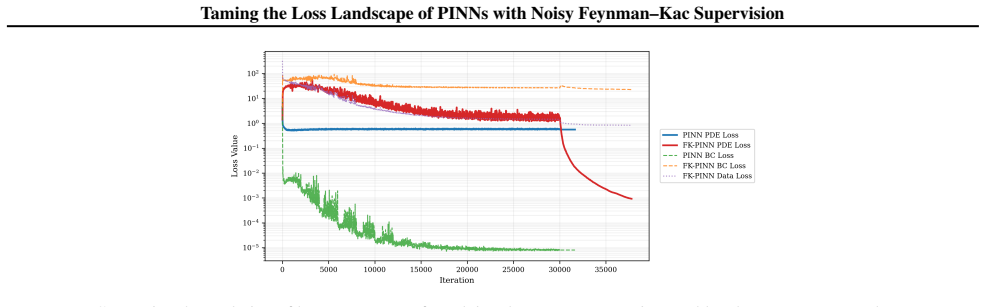
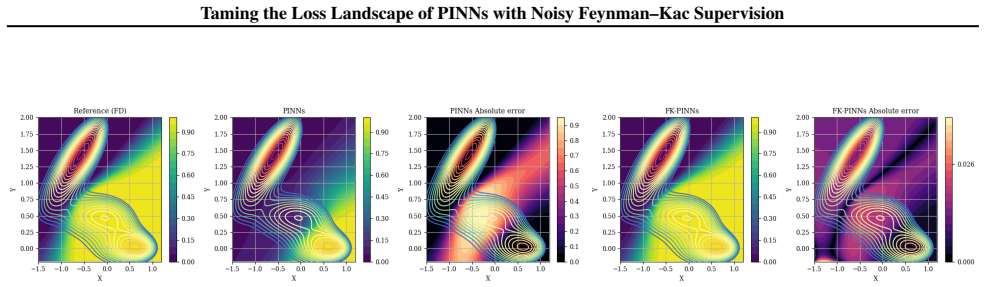
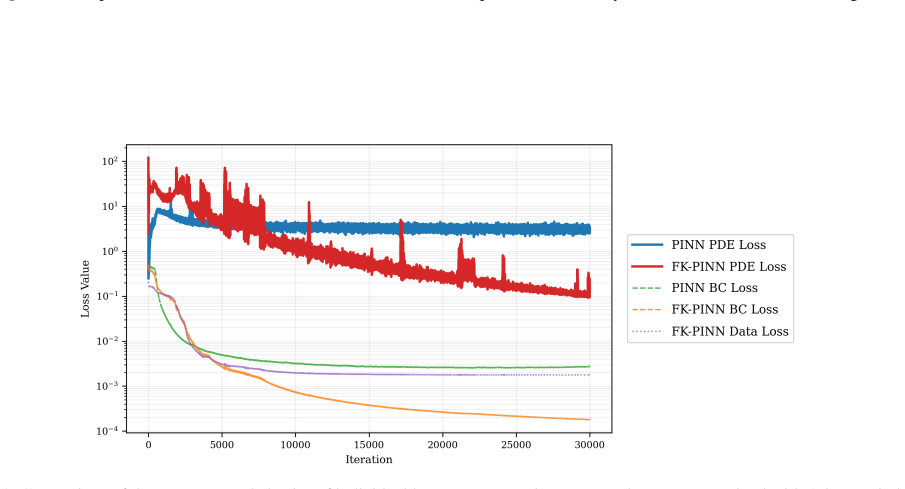


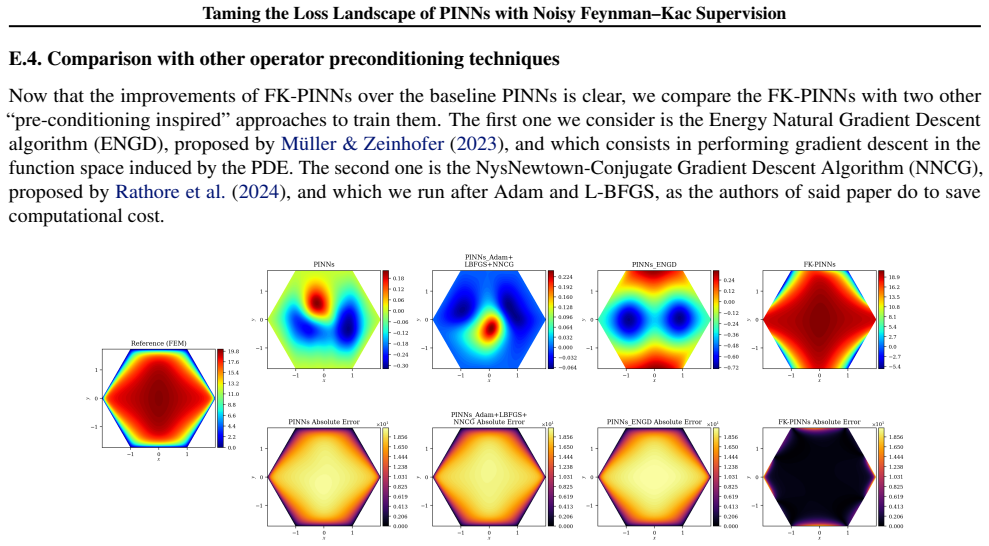
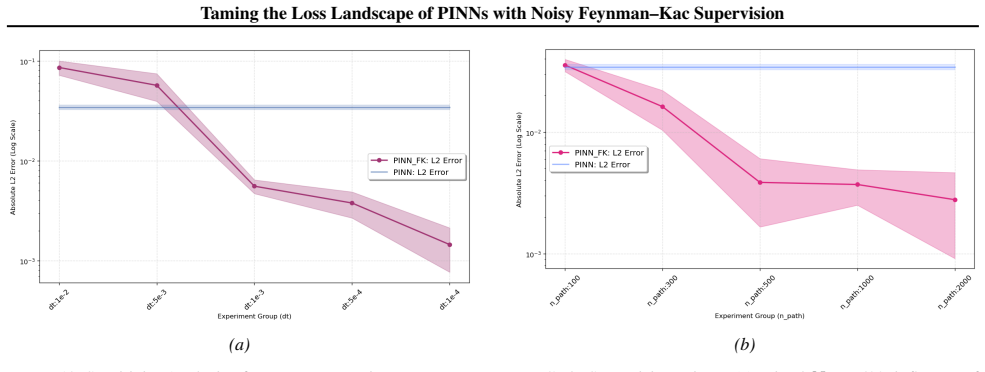
read the original abstract
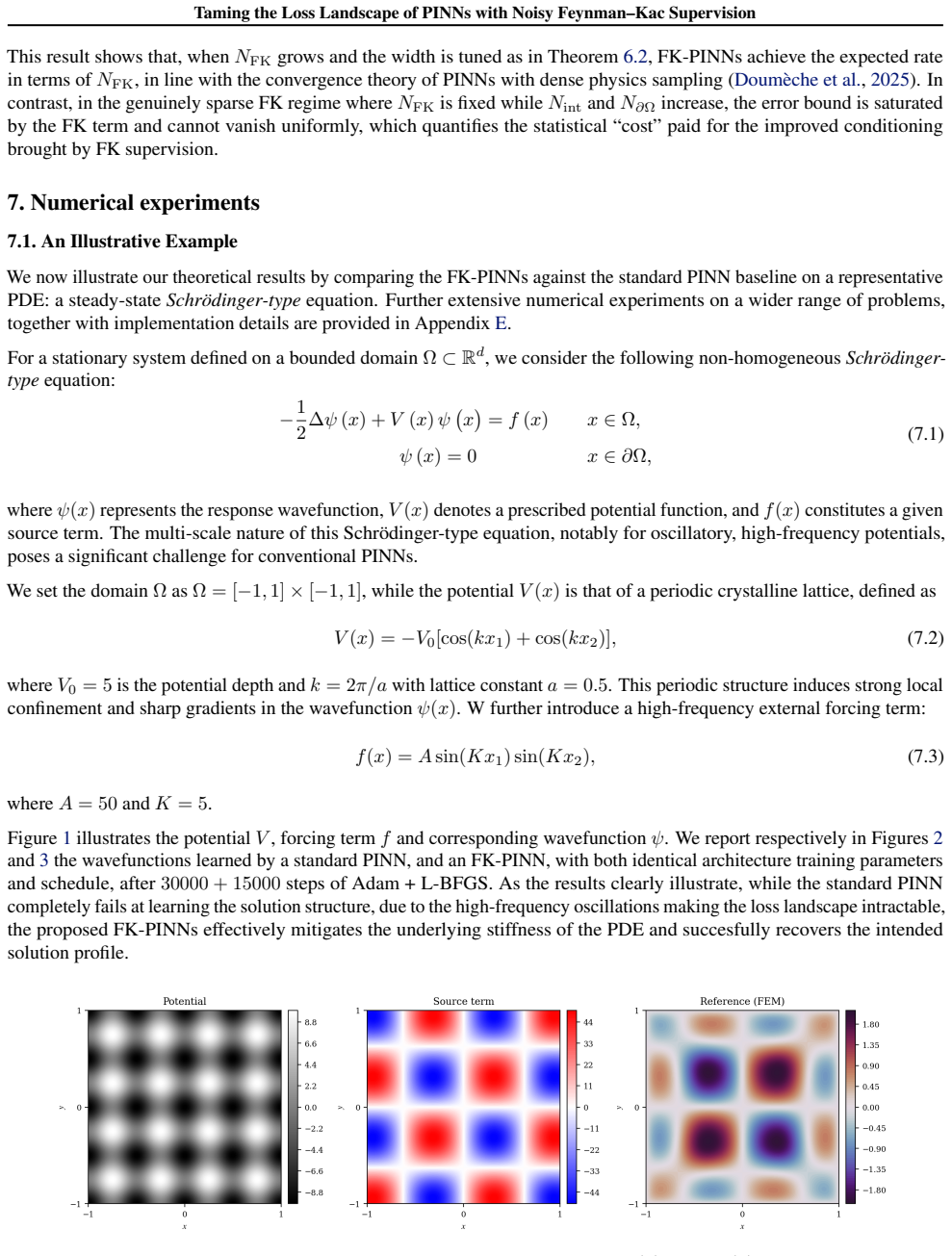
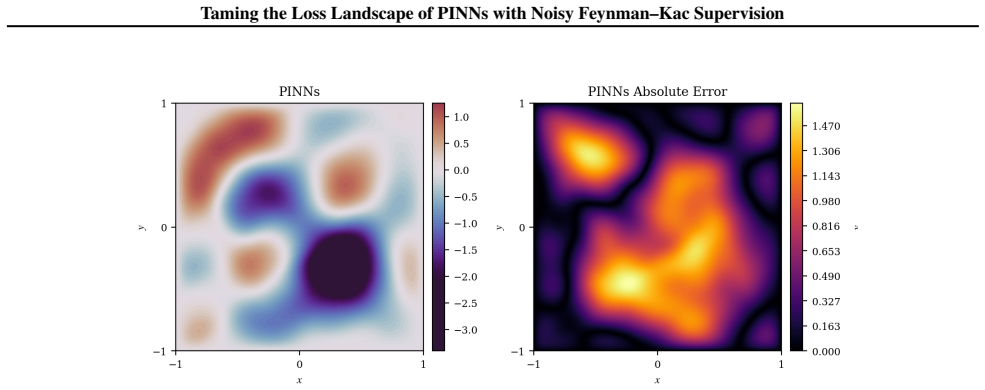
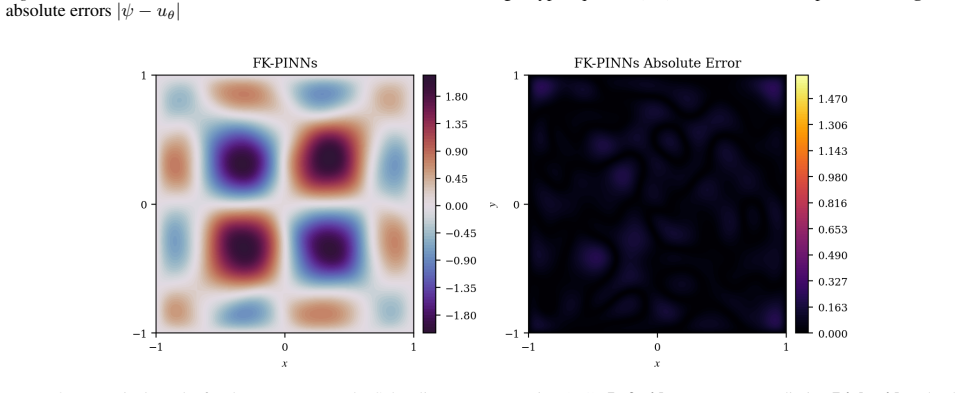
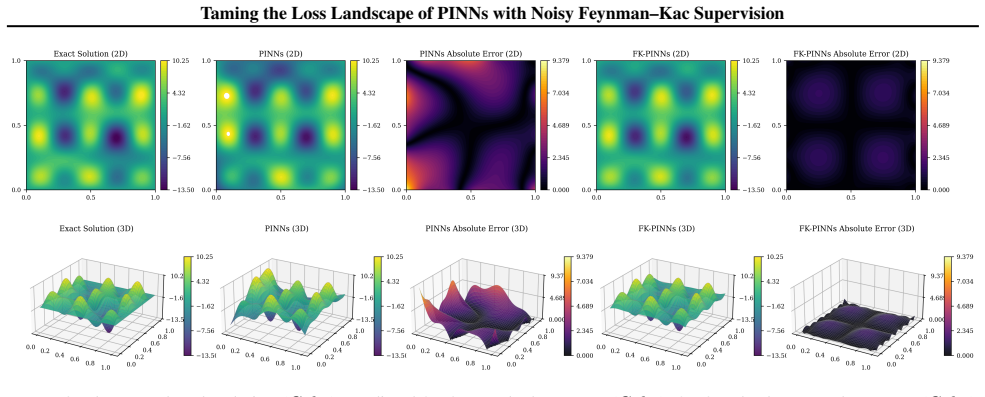
Physics-Informed Neural Networks (PINNs) often train slowly or fail to converge on challenging partial differential equations (PDEs), a behavior recently linked to severely ill-conditioned loss landscapes inherited from the underlying differential operator. We study PINNs augmented with a pointwise data-fidelity term, added at a few points in the domain to the standard residual and boundary losses. We show that this supervision term acts as an operator-level preconditioner: for suitable weights, our comparison bounds guarantee a substantially smaller condition number than under the standard PINN loss, independently of how the pointwise labels are obtained. For a broad class of PDEs admitting a Feynman-Kac (FK) representation, we generate such labels by Monte Carlo averages of the FK functional, resulting in what we call ``FK-PINNs", and using the excess risk decomposition approach, we derive non-asymptotic $L^2(\Omega)$-error bounds for FK-PINNs with $\tanh$ activation trained by finitely many steps of gradient descent. Along the way, we establish pseudo-dimension bounds for first- and second-order derivatives of $\tanh$ neural networks, which are of independent interest and, to the best of our knowledge, new. Numerical experiments on Poisson, Schr\"odinger, mean exit time, and committor problems corroborate the theory, and show that FK-PINNs can successfully solve PDEs for which standard PINNs exhibit severe failure modes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that augmenting the standard PINN loss with a pointwise data-fidelity term (generated via Monte Carlo sampling from the Feynman-Kac representation for PDEs admitting such a form) acts as an operator-level preconditioner. For suitable weights, comparison bounds show a substantially smaller condition number than the standard PINN loss, independently of label source. Using excess-risk decomposition, the authors derive non-asymptotic L²(Ω) error bounds for FK-PINNs with tanh activations trained by finitely many gradient-descent steps. New pseudo-dimension bounds for first- and second-order derivatives of tanh networks are established as auxiliary results. Numerical experiments on Poisson, Schrödinger, mean-exit-time, and committor problems are reported to corroborate the claims.
Significance. If the central claims hold, the work supplies a concrete mechanism for improving loss conditioning in PINNs together with non-asymptotic error guarantees that do not rely on asymptotic regimes. The independence of the preconditioning effect from the label source and the provision of new pseudo-dimension bounds for network derivatives are notable strengths. The approach is restricted to the class of PDEs admitting Feynman-Kac representations, but within that class the results appear to offer both theoretical and practical value for problems where standard PINNs fail.
minor comments (3)
- [Abstract] The abstract states that 'comparison bounds guarantee a substantially smaller condition number' but does not indicate the dependence of the weight choice on the operator or on the number of supervision points; a brief clarifying sentence would improve readability.
- [Introduction / Related work] The pseudo-dimension bounds are described as 'of independent interest and, to the best of our knowledge, new.' A short comparison with existing bounds for ReLU or other activations in the related-work section would help situate the contribution.
- [Numerical experiments] Numerical experiments are said to 'corroborate the theory,' yet the manuscript does not report the Monte-Carlo sample size used to generate FK labels or the precise schedule for the supervision weights; these details are needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed summary of our manuscript and the positive assessment of its significance. The recommendation for minor revision is appreciated. No specific major comments appear in the report, so we provide no point-by-point responses below. We will incorporate any minor editorial changes in the revised version.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper's central claims rest on comparison bounds for the preconditioning effect of the added supervision term (independent of label source) and on excess-risk plus pseudo-dimension arguments for the non-asymptotic L2 error bounds under finite GD steps. These steps are presented as derived from standard statistical learning tools and operator analysis rather than from fitted parameters renamed as predictions or from self-citation chains. The Feynman-Kac representation is an external assumption on the PDE class, not a self-referential definition. No load-bearing step reduces by construction to the paper's own inputs or prior self-citations.
Axiom & Free-Parameter Ledger
free parameters (1)
- supervision weights
axioms (2)
- domain assumption Target PDE admits a Feynman-Kac representation
- domain assumption Networks use tanh activation
Reference graph
Works this paper leans on
-
[1]
Journal of Computational physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational physics , volume=. 2019 , publisher=
2019
-
[2]
Journal of Scientific Computing , volume=
Scientific machine learning through physics--informed neural networks: Where we are and what’s next , author=. Journal of Scientific Computing , volume=. 2022 , publisher=
2022
-
[3]
Advances in neural information processing systems , volume=
Characterizing possible failure modes in physics-informed neural networks , author=. Advances in neural information processing systems , volume=
-
[4]
SIAM Journal on Scientific Computing , volume=
Understanding and mitigating gradient flow pathologies in physics-informed neural networks , author=. SIAM Journal on Scientific Computing , volume=. 2021 , publisher=
2021
-
[5]
Computer Methods in Applied Mechanics and Engineering , volume=
A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks , author=. Computer Methods in Applied Mechanics and Engineering , volume=. 2023 , publisher=
2023
-
[6]
The Twelfth International Conference on Learning Representations , year=
An operator preconditioning perspective on training in physics-informed machine learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[7]
International Conference on Machine Learning , pages=
Challenges in Training PINNs: A Loss Landscape Perspective , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[8]
Journal of Computational Physics , volume=
When and why PINNs fail to train: A neural tangent kernel perspective , author=. Journal of Computational Physics , volume=. 2022 , publisher=
2022
-
[9]
arXiv preprint arXiv:2410.06308 , year=
Quantifying training difficulty and accelerating convergence in neural network-based PDE solvers , author=. arXiv preprint arXiv:2410.06308 , year=
-
[10]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Gradient Alignment in Physics-informed Neural Networks: A Second-Order Optimization Perspective , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[11]
International Conference on Machine Learning , pages=
Achieving high accuracy with PINNs via energy natural gradient descent , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[12]
Forty-second International Conference on Machine Learning , year=
Learn Singularly Perturbed Solutions via Homotopy Dynamics , author=. Forty-second International Conference on Machine Learning , year=
-
[13]
2025 , url=
Nilo Schwencke and Cyril Furtlehner , booktitle=. 2025 , url=
2025
-
[14]
Stochastic differential equations: an introduction with applications , pages=
Stochastic differential equations , author=. Stochastic differential equations: an introduction with applications , pages=. 2003 , publisher=
2003
-
[15]
2014 , publisher=
Brownian motion and stochastic calculus , author=. 2014 , publisher=
2014
-
[16]
Sabelfeld , title =
Karl K. Sabelfeld , title =. 1991 , series =
1991
-
[17]
2022 , publisher=
Partial differential equations , author=. 2022 , publisher=
2022
-
[18]
2016 , publisher=
Monte-Carlo methods and stochastic processes: from linear to non-linear , author=. 2016 , publisher=
2016
-
[19]
2022 , publisher=
Monte Carlo Methods for Partial Differential Equations With Applications to Electronic Design Automation , author=. 2022 , publisher=
2022
-
[20]
Texts in applied mathematics , volume=
Stochastic processes and applications , author=. Texts in applied mathematics , volume=. 2014 , publisher=
2014
-
[21]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Kendall, Alex and Gal, Yarin and Cipolla, Roberto , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[22]
Applied and Computational Harmonic Analysis , volume=
Loss landscapes and optimization in over-parameterized non-linear systems and neural networks , author=. Applied and Computational Harmonic Analysis , volume=. 2022 , publisher=
2022
-
[23]
arXiv preprint arXiv:2405.13738 , year=
Interpolation with deep neural networks with non-polynomial activations: necessary and sufficient numbers of neurons , author=. arXiv preprint arXiv:2405.13738 , year=
-
[24]
On the Optimal Memorization Power of Re
Gal Vardi and Gilad Yehudai and Ohad Shamir , booktitle=. On the Optimal Memorization Power of Re. 2022 , url=
2022
-
[25]
Linear convergence of gradient and proximal-gradient methods under the polyak-
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle=. Linear convergence of gradient and proximal-gradient methods under the polyak-. 2016 , organization=
2016
-
[26]
Zhurnal vychislitel'noi matematiki i matematicheskoi fiziki , volume=
Gradient methods for minimizing functionals , author=. Zhurnal vychislitel'noi matematiki i matematicheskoi fiziki , volume=. 1963 , publisher=
1963
-
[27]
Neural Networks , volume=
On the approximation of functions by tanh neural networks , author=. Neural Networks , volume=. 2021 , publisher=
2021
-
[28]
Communications in Computational Physics , year=
A rate of convergence of physics informed neural networks for the linear second order elliptic pdes , author=. Communications in Computational Physics , year=. doi:10.4208/cicp.OA-2021-0186 , number=
-
[29]
Conference on learning theory , pages=
A priori generalization analysis of the deep Ritz method for solving high dimensional elliptic partial differential equations , author=. Conference on learning theory , pages=. 2021 , organization=
2021
-
[30]
2012 , publisher=
Matrix analysis , author=. 2012 , publisher=
2012
-
[31]
Proceedings of the 36th International Conference on Machine Learning , pages =
Gradient Descent Finds Global Minima of Deep Neural Networks , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , volume =
2019
-
[32]
Journal of Machine Learning Research , volume=
Piratenets: Physics-informed deep learning with residual adaptive networks , author=. Journal of Machine Learning Research , volume=
-
[33]
1991 , publisher=
Functional Analysis , author=. 1991 , publisher=
1991
-
[34]
Constructive approximation , volume=
Learning theory estimates via integral operators and their approximations , author=. Constructive approximation , volume=. 2007 , publisher=
2007
-
[35]
Bernoulli , volume=
On the convergence of PINNs , author=. Bernoulli , volume=. 2025 , publisher=
2025
-
[36]
1995 , publisher=
Positive harmonic functions and diffusion , author=. 1995 , publisher=
1995
-
[37]
First time to exit of a continuous It
Bouchard, Bruno and Geiss, Stefan and Gobet, Emmanuel , journal=. First time to exit of a continuous It
-
[38]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[39]
Stochastic processes and their applications , volume=
Weak approximation of killed diffusion using Euler schemes , author=. Stochastic processes and their applications , volume=. 2000 , publisher=
2000
-
[40]
Stochastic Processes and Their Applications , volume=
Stopped diffusion processes: boundary corrections and overshoot , author=. Stochastic Processes and Their Applications , volume=. 2010 , publisher=
2010
-
[41]
Neurocomputing , volume=
Improved physics-informed neural network in mitigating gradient-related failures , author=. Neurocomputing , volume=. 2025 , publisher=
2025
-
[42]
Nonlinearity , volume=
Algorithms for solving high dimensional PDEs: from nonlinear Monte Carlo to machine learning , author=. Nonlinearity , volume=. 2021 , publisher=
2021
-
[43]
Communications in Mathematics and Statistics , volume=
Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations , author=. Communications in Mathematics and Statistics , volume=. 2017 , publisher=
2017
-
[44]
International Conference on Monte Carlo and Quasi-Monte Carlo Methods in Scientific Computing , year=
Stochastic methods for solving high-dimensional partial differential equations , author=. International Conference on Monte Carlo and Quasi-Monte Carlo Methods in Scientific Computing , year=
-
[45]
, author=
Towards a Theory of Transition Paths. , author=. Journal of Statistical Physics , volume=
-
[46]
Markov Processes: Volume 1 , pages=
Markov processes , author=. Markov Processes: Volume 1 , pages=. 1965 , publisher=
1965
-
[47]
2009 , publisher=
Markov processes: characterization and convergence , author=. 2009 , publisher=
2009
-
[48]
Applebaum, David , year=. L
-
[49]
2006 , publisher=
Controlled Markov processes and viscosity solutions , author=. 2006 , publisher=
2006
-
[50]
Kloeden and Eckhard Platen , title =
Peter E. Kloeden and Eckhard Platen , title =. 1992 , doi =
1992
-
[51]
2004 , publisher=
Monte Carlo methods in financial engineering , author=. 2004 , publisher=
2004
-
[52]
Systems & control letters , volume=
Adapted solution of a backward stochastic differential equation , author=. Systems & control letters , volume=. 1990 , publisher=
1990
-
[53]
Mathematical finance , volume=
Backward stochastic differential equations in finance , author=. Mathematical finance , volume=. 1997 , publisher=
1997
-
[54]
Probability theory and related fields , volume=
A probabilistic approach to one class of nonlinear differential equations , author=. Probability theory and related fields , volume=. 1991 , publisher=
1991
-
[55]
Annales de l’Institut Henri Poincar
Branching diffusion representation of semilinear PDEs and Monte Carlo approximation , author=. Annales de l’Institut Henri Poincar
-
[56]
Stochastic Processes and their Applications , volume=
Branching diffusion representation of semi-linear elliptic PDEs and estimation using Monte Carlo method , author=. Stochastic Processes and their Applications , volume=. 2020 , publisher=
2020
-
[57]
Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences , volume=
Second-order backward stochastic differential equations and fully nonlinear parabolic PDEs , author=. Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences , volume=. 2007 , publisher=
2007
-
[58]
Stochastic Processes and their applications , volume=
Discrete-time approximation and Monte-Carlo simulation of backward stochastic differential equations , author=. Stochastic Processes and their applications , volume=. 2004 , publisher=
2004
-
[59]
I , author=
Estimates near the boundary for solutions of elliptic partial differential equations satisfying general boundary conditions. I , author=. Communications on pure and applied mathematics , volume=. 1959 , publisher=
1959
-
[60]
Bartlett and Nick Harvey and Christopher Liaw and Abbas Mehrabian , title =
Peter L. Bartlett and Nick Harvey and Christopher Liaw and Abbas Mehrabian , title =. Journal of Machine Learning Research , year =
-
[61]
Journal of Computer and System Sciences , volume=
Polynomial bounds for VC dimension of sigmoidal and general Pfaffian neural networks , author=. Journal of Computer and System Sciences , volume=. 1997 , publisher=
1997
-
[62]
2009 , publisher=
Neural network learning: Theoretical foundations , author=. 2009 , publisher=
2009
-
[63]
2019 , publisher=
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
2019
-
[64]
2013 , publisher=
Probability in Banach Spaces: isoperimetry and processes , author=. 2013 , publisher=
2013
-
[65]
Applied and Computational Harmonic Analysis , volume=
Solving PDEs on spheres with physics-informed convolutional neural networks , author=. Applied and Computational Harmonic Analysis , volume=. 2025 , publisher=
2025
-
[66]
Machine Learning For Elliptic
Yiping Lu and Haoxuan Chen and Jianfeng Lu and Lexing Ying and Jose Blanchet , booktitle=. Machine Learning For Elliptic. 2022 , url=
2022
-
[67]
, author=
Transition-path theory and path-finding algorithms for the study of rare events. , author=. Annual review of physical chemistry , volume=
-
[68]
Aditya Prakash , booktitle=
Zhiyuan Zhao and Xueying Ding and B. Aditya Prakash , booktitle=. 2024 , url=
2024
-
[69]
Advances in neural information processing systems , volume=
Visualizing the loss landscape of neural nets , author=. Advances in neural information processing systems , volume=
-
[70]
SIAM Journal on Numerical Analysis , volume=
Value-gradient based formulation of optimal control problem and machine learning algorithm , author=. SIAM Journal on Numerical Analysis , volume=. 2023 , publisher=
2023
-
[71]
Journal of Computational Physics , volume=
PINN training using biobjective optimization: The trade-off between data loss and residual loss , author=. Journal of Computational Physics , volume=. 2023 , publisher=
2023
-
[72]
SIAM Journal on Scientific Computing , volume=
Deep splitting method for parabolic PDEs , author=. SIAM Journal on Scientific Computing , volume=. 2021 , publisher=
2021
-
[73]
Journal of Computational Physics , volume=
A derivative-free method for solving elliptic partial differential equations with deep neural networks , author=. Journal of Computational Physics , volume=. 2020 , publisher=
2020
-
[74]
SIAM Journal on Scientific Computing , volume=
Deep Picard iteration for high-dimensional nonlinear PDEs , author=. SIAM Journal on Scientific Computing , volume=. 2026 , publisher=
2026
-
[75]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Rigorous a posteriori error bounds for PDE-defined PINNs , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2023 , publisher=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.