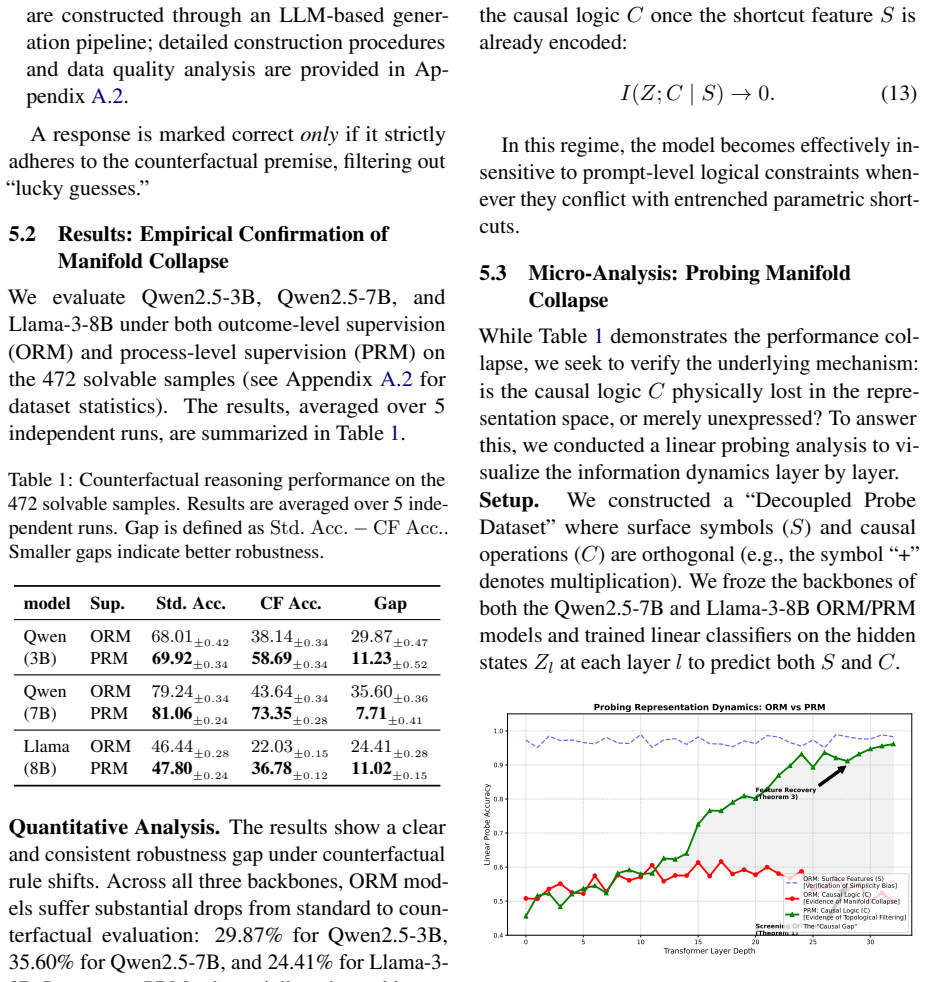
The Paradox of Outcome Optimization: A Causal Information-Theoretic Bound on Reasoning Shortcuts in LLMs
Pith reviewed 2026-06-28 19:33 UTC · model grok-4.3
The pith
Outcome optimization biases LLMs toward reasoning shortcuts whenever training distributions permit Markovian screening of causal mechanisms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We establish a theoretical framework bridging Structural Causal Models (SCM) and the Information Bottleneck (IB) principle to explain Reward-Induced Manifold Collapse. Reasoning is defined as a high-complexity causal process and shortcut learning as the exploitation of low-complexity spurious correlations. Under the implicit inductive bias of SGD, models optimized for outcome rewards are biased toward shortcut solutions whenever the training distribution allows for a Markovian Screening of the true causal mechanism. We derive a new generalization bound based on Semantic Coverage Measure (η) rather than sample size, showing why data scaling on homogeneous distributions may fail to correct rea
What carries the argument
Markovian Screening of the true causal mechanism within the SCM-IB framework, which permits SGD to favor low-complexity spurious correlations over high-complexity causal reasoning.
If this is right
- Data scaling on homogeneous distributions cannot eliminate reasoning flaws because the bound is controlled by Semantic Coverage Measure η rather than sample size.
- Process Reward Models act as Topological Filters that impose step-wise mutual information constraints and thereby exclude the shortcut manifold.
- Outcome optimization creates a systematic preference for low-complexity solutions over high-complexity causal processes when screening is possible.
- The framework supplies a mathematical basis for preferring process supervision over pure outcome supervision in model alignment.
Where Pith is reading between the lines
- Alignment pipelines that rely solely on final-answer rewards may systematically underperform on tasks requiring novel causal reasoning.
- The Semantic Coverage Measure could be used to diagnose datasets likely to induce shortcut learning before training begins.
- Similar screening effects may appear in other domains where optimization operates on partially observed causal structures.
Load-bearing premise
The training distribution allows a Markovian Screening of the true causal mechanism, enabling SGD to bias models toward shortcut solutions.
What would settle it
Construct a training distribution that blocks Markovian screening of the causal mechanism and measure whether outcome-optimized models still exhibit the same degree of OOD reasoning collapse as on standard distributions.
Figures

read the original abstract
Large Language Models (LLMs) aligned via outcome-based Reinforcement Learning (RL) frequently exhibit a critical failure mode: they achieve high performance on in-distribution benchmarks while demonstrating brittle reasoning capabilities on out-of-distribution (OOD) tasks. We term this phenomenon Reward-Induced Manifold Collapse. We establish a theoretical framework bridging Structural Causal Models (SCM) and the Information Bottleneck (IB) principle to explain this paradox. We define reasoning as a high-complexity causal process and shortcut learning as the exploitation of low-complexity spurious correlations. Under the implicit inductive bias of Stochastic Gradient Descent (SGD), models optimized for outcome rewards are biased toward shortcut solutions whenever the training distribution allows for a ``Markovian Screening'' of the true causal mechanism. We derive a new generalization bound based on Semantic Coverage Measure ($\eta$) rather than sample size, showing why data scaling on homogeneous distributions may fail to correct reasoning flaws. We also show that Process Reward Models (PRMs) function as Topological Filters, enforcing step-wise mutual information constraints that render the low-complexity shortcut manifold inadmissible. These results provide a mathematical grounding for the role of process supervision beyond simple credit assignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that outcome-based RL alignment in LLMs produces Reward-Induced Manifold Collapse, where models achieve high in-distribution performance but brittle OOD reasoning. It bridges SCMs with the Information Bottleneck, treats reasoning as high-complexity causal paths and shortcuts as low-complexity correlations, invokes SGD's simplicity bias, and derives a generalization bound replacing sample size with a Semantic Coverage Measure η under the assumption that the training distribution permits Markovian Screening of the true causal mechanism. It further claims that Process Reward Models act as topological filters enforcing step-wise mutual information constraints that exclude shortcut manifolds.
Significance. If the derivation of the η-based bound is valid and the Markovian Screening assumption holds without circularity, the framework would supply a causal-information-theoretic account for why homogeneous data scaling fails to eliminate reasoning shortcuts and would mathematically motivate process supervision over pure outcome rewards. The explicit linkage of SCMs, IB, and SGD bias is a potentially useful synthesis, though its load-bearing steps require verification against the actual equations.
major comments (2)
- [Abstract] The abstract asserts a derived generalization bound based on Semantic Coverage Measure η rather than sample size, yet the visible text supplies neither the bound statement, its proof, nor the definition of η. Without these, it is impossible to assess whether the bound is non-vacuous or whether η is independently grounded versus fitted to the same data it purports to explain.
- [Theoretical Framework] The central claim rests on the training distribution permitting 'Markovian Screening' of the true causal mechanism. The manuscript must explicitly state the formal condition under which this screening occurs and demonstrate that it is not tautological with the shortcut-learning phenomenon being explained.
minor comments (2)
- Notation for η, the Information Bottleneck quantities, and the topological-filter property of PRMs should be introduced with explicit definitions before being used in claims.
- The paper should include at least one concrete example (synthetic or real) showing how the η-bound predicts observed collapse where a standard sample-size bound does not.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below by clarifying the locations and content of the theoretical results and by strengthening the formal presentation of the key assumption. Both points will be incorporated via targeted revisions to improve accessibility and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts a derived generalization bound based on Semantic Coverage Measure η rather than sample size, yet the visible text supplies neither the bound statement, its proof, nor the definition of η. Without these, it is impossible to assess whether the bound is non-vacuous or whether η is independently grounded versus fitted to the same data it purports to explain.
Authors: The bound appears as Theorem 1 in Section 4: for a model trained under outcome optimization, the generalization gap satisfies R_gen(P_test) ≤ C · (1 - η) + ε, where η ∈ [0,1] is the Semantic Coverage Measure defined as η = 1 - sup_{f ∈ F_shortcut} I(f(X); Y) / I(C; Y) and C denotes the true causal mechanism. The proof (Appendix B) proceeds by combining the Information Bottleneck decomposition with the SGD simplicity bias, replacing the usual n-dependent term with an η-dependent term that remains large when the training distribution screens off high-complexity paths. η is derived directly from the SCM factorization and is not fitted to data; it can be estimated from interventional queries on the causal graph. We will revise the abstract to include a one-sentence statement of the bound and move the definition of η into the main text (Section 3) to address visibility. revision: yes
-
Referee: [Theoretical Framework] The central claim rests on the training distribution permitting 'Markovian Screening' of the true causal mechanism. The manuscript must explicitly state the formal condition under which this screening occurs and demonstrate that it is not tautological with the shortcut-learning phenomenon being explained.
Authors: We will add Definition 2 in Section 3.1: the training distribution P permits Markovian Screening of the true causal mechanism if there exists a low-complexity variable Z (spurious) such that Y ⊥ C | Z holds in the observational distribution while the interventional distribution P(Y | do(C)) retains dependence on C. This is a purely distributional property of the data-generating SCM and is independent of the learner; it is verified by checking d-separation in the graph and is illustrated by the concrete example in Figure 2 (homogeneous vs. diverse data). The phenomenon of shortcut learning is then a consequence of SGD bias acting on a distribution that already satisfies the screening condition, so the assumption is not tautological. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a derived generalization bound replacing sample size with Semantic Coverage Measure η, framed via SCM-IB bridging and Markovian Screening. No quoted equations or steps reduce the bound to a self-definition of η, a fitted parameter renamed as prediction, or a self-citation chain. The framework invokes standard external principles (SCM, IB, SGD bias) without load-bearing self-citations or ansatz smuggling. The derivation remains self-contained with independent content from the causal setup; η is introduced as a new measure grounded in the topology of the training distribution rather than fitted to the target result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[9]
Training language models to follow instructions with human feedback , url =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[11]
Chain-of-
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , editor =. Chain-of-. Advances in. 2022 , pages =
2022
-
[12]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[14]
Defining and Characterizing Reward Gaming , url =
Skalse, Joar and Howe, Nikolaus and Krasheninnikov, Dmitrii and Krueger, David , booktitle =. Defining and Characterizing Reward Gaming , url =
-
[15]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[16]
Transactions on machine learning research , year=
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models , author=. Transactions on machine learning research , year=
-
[19]
2015 ieee information theory workshop (itw) , pages=
Deep learning and the information bottleneck principle , author=. 2015 ieee information theory workshop (itw) , pages=. 2015 , organization=
2015
-
[20]
2009 , publisher=
Causality , author=. 2009 , publisher=
2009
-
[21]
A closer look at memorization in deep networks , year =
Arpit, Devansh and Jastrzundefinedbski, Stanis. A closer look at memorization in deep networks , year =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =
-
[24]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[26]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[28]
and Sifre, Laurent , title =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
2022
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[30]
EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework , author =
-
[31]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[32]
Measuring
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , editor =. Measuring. Proceedings of the
-
[33]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Frame: Feedback-refined agent methodology for enhancing medical research insights , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[34]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man \'e . 2016. Concrete problems in ai safety. arXiv preprint arXiv:1606.06565
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, and Simon Lacoste-Julien
Devansh Arpit, Stanis aw Jastrzundefinedbski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S. Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, and Simon Lacoste-Julien. 2017. A closer look at memorization in deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML'17, page 233...
2017
-
[36]
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Micha Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2024. https://doi.org/10.1609/aaai.v38i16.29720 Graph of thoughts: solving elaborate problems with large language models . In Proceedings of the Thirty-Eighth AAAI Conferenc...
-
[37]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30
2017
-
[38]
Robert Geirhos, J \"o rn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. 2020. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665--673
2020
-
[39]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/file/be83ab3ecd0db773eb2dc1b0a17836a1-Paper-round2.pdf Measuring Mathematical Problem Solving With the MATH Dataset . In Proceedings of the Neural Information P...
2021
-
[40]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, and 3 others. 2022. Training compute-optimal ...
2022
-
[41]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[42]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199--22213
2022
-
[43]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let's verify step by step. In The Twelfth International Conference on Learning Representations
2023
-
[44]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/b...
2022
-
[45]
Judea Pearl. 2009. Causality. Cambridge university press
2009
-
[46]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/3d719fee332caa23d5038b8a90e81796-Paper-Conference.pdf Defining and characterizing reward gaming . In Advances in Neural Information Processing Systems, volume 35, pages 9460--9471. Curran Associates, Inc
2022
-
[48]
Naftali Tishby, Fernando C Pereira, and William Bialek. 2000. The information bottleneck method. arXiv preprint physics/0004057
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[49]
Naftali Tishby and Noga Zaslavsky. 2015. Deep learning and the information bottleneck principle. In 2015 ieee information theory workshop (itw), pages 1--5. Ieee
2015
-
[50]
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 2022. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Guillermo Valle-Perez, Chico Q Camargo, and Ard A Louis. 2018. Deep learning generalizes because the parameter-function map is biased towards simple functions. arXiv preprint arXiv:1805.08522
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[52]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf Chain-of- Thought Prompting Elicits Reasoning in Large Language Models . In Advances in Neural Information Processing System...
2022
-
[54]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36:11809--11822
2023
-
[55]
Chengzhang Yu, Yiming Zhang, Zhixin Liu, Zenghui Ding, Yining Sun, and Zhanpeng Jin. 2025. Frame: Feedback-refined agent methodology for enhancing medical research insights. In Findings of the Association for Computational Linguistics: ACL 2025, pages 7690--7704
2025
-
[56]
Yaowei Zheng, Junting Lu, Shenzhi Wang, Zhangchi Feng, Dongdong Kuang, and Yuwen Xiong. 2025. Easyr1: An efficient, scalable, multi-modality rl training framework. https://github.com/hiyouga/EasyR1
2025
-
[57]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. http://arxiv.org/abs/2403.13372 Llamafactory: Unified efficient fine-tuning of 100+ language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand. Assoc...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.