Beyond Sinusoids: A Morlet Wavelet Framework for Transformer Positional Encoding
Pith reviewed 2026-06-28 17:32 UTC · model grok-4.3
The pith
Morlet wavelets unify sinusoidal and rotary positional encodings as limiting cases while adding per-dimension learnable locality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
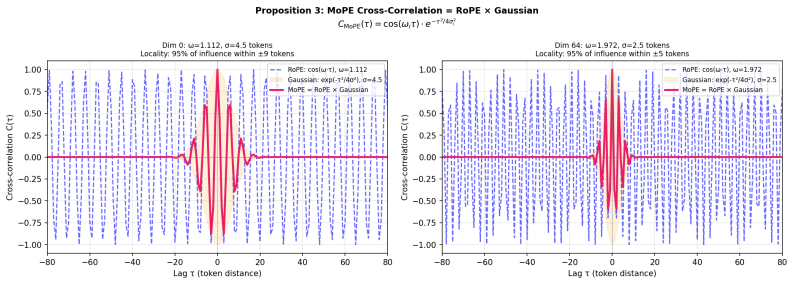
The central claim is that the Morlet wavelet supplies the natural basis for positional encoding because it minimizes joint uncertainty in position and frequency. MoPE therefore generalizes both sinusoidal PE and RoPE: when every locality bandwidth sigma_i tends to infinity the correlation kernel of MoPE reduces to the RoPE kernel and the phase recovers the exact rotation angle of RoPE, while the amplitude term supplies an additional learned Gaussian locality envelope absent from the earlier encodings.
What carries the argument
Morlet Positional Encoding (MoPE), in which each embedding dimension independently learns a frequency and a locality bandwidth parameter from data.
If this is right
- Sinusoidal positional encodings and the RoPE correlation kernel both emerge as exact limiting cases of MoPE.
- MoPE supplies an extra learned Gaussian locality kernel that neither sinusoidal nor RoPE encodings contain.
- MoPE combined with energy-gated attention produces a 0.119 accuracy gain on TinyShakespeare over either component used alone.
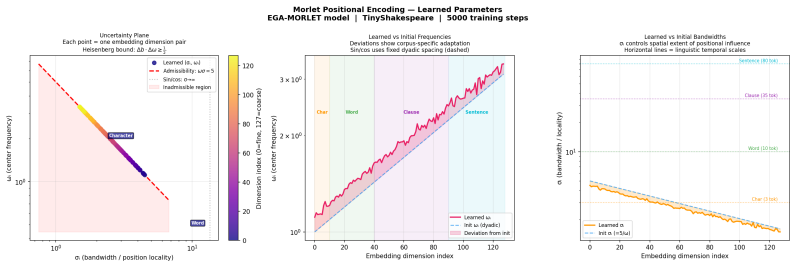
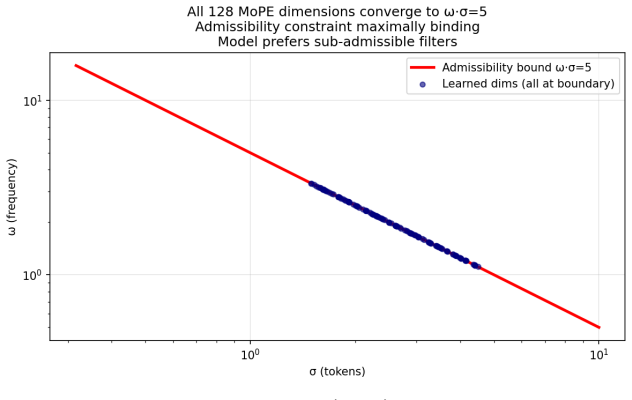
- All 128 learned frequency-bandwidth pairs converge to the wavelet admissibility boundary on character-level language data.
Where Pith is reading between the lines
- The convergence of parameters to the admissibility boundary may indicate a reproducible spectral property of character-level sequences that could be tested on other modalities.
- Because MoPE interpolates continuously between fully local and fully global positional effects, it could be used to diagnose how much locality a given task actually requires.
- The unification suggests that future positional schemes could be derived by choosing different admissible wavelets instead of fixing the Morlet form.
Load-bearing premise
The Morlet wavelet is the natural basis for positional encoding because it simultaneously minimizes uncertainty in position and frequency.
What would settle it
Running the identical transformer architecture with MoPE but forcing every locality bandwidth to infinity and verifying that both the learned weights and the task performance become statistically indistinguishable from a standard RoPE baseline.
Figures

read the original abstract
Standard positional encodings for transformers - sinusoidal and rotary (RoPE) - treat every position as equally local: they encode where a token is, but not how far its positional influence should extend. We propose that the Morlet wavelet, which simultaneously minimises uncertainty in position and frequency, is the natural basis for positional encoding, and introduce Morlet Positional Encoding (MoPE): each embedding dimension learns its own frequency and locality bandwidth from data. The main theoretical result is a unification: sinusoidal PE and the RoPE correlation kernel both emerge as limiting cases of MoPE when locality is switched off (sigma_i -> infinity). The phase of MoPE recovers the RoPE rotation angle exactly; the amplitude adds a learned Gaussian locality kernel that standard encodings lack. Empirically, MoPE combined with Energy-Gated Attention achieves +0.119 improvement over standard attention on TinyShakespeare, outperforming either component alone. Analysis of the learned parameters reveals that all 128 frequency-bandwidth pairs converge to the wavelet admissibility boundary - an empirical observation consistent with a companion result on energy gating, suggesting a reproducible property of character-level language signals that warrants further investigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Morlet Positional Encoding (MoPE) based on the Morlet wavelet, with each embedding dimension learning its own frequency and locality bandwidth (sigma_i). The central theoretical claim is a unification result: standard sinusoidal positional encodings and the RoPE correlation kernel both emerge exactly as limiting cases of MoPE when sigma_i -> infinity, with the phase of MoPE recovering the RoPE rotation angle exactly. The amplitude term supplies an additional learned Gaussian locality kernel absent from prior encodings. Empirically, MoPE combined with Energy-Gated Attention yields a +0.119 gain over standard attention on TinyShakespeare; learned parameters are observed to converge to the wavelet admissibility boundary.
Significance. If the unification holds, the framework supplies a single parametric family that recovers two widely used encodings as special cases while adding learnable locality, which is a clean generalization. The observation that all 128 learned (frequency, bandwidth) pairs converge to the admissibility boundary is presented as potentially reproducible for character-level signals. These strengths are offset by the fact that the reported numeric gain cannot be attributed to the positional encoding in isolation.
major comments (2)
- [Abstract] Abstract / empirical evaluation: the reported +0.119 improvement is obtained only for the combination of MoPE with Energy-Gated Attention on a single small dataset (TinyShakespeare); no ablation isolating the positional-encoding contribution is provided, so the performance claim for MoPE itself is not load-bearing.
- [Theoretical result] Theoretical unification result: the claimed exact recovery of the RoPE angle and the emergence of both sinusoidal PE and the RoPE kernel are obtained by substituting the limit sigma_i -> infinity directly into the MoPE definition; the correspondence is therefore definitional once the wavelet form is chosen rather than an independent derivation.
minor comments (1)
- [Abstract] The abstract states that the Morlet wavelet 'simultaneously minimises uncertainty in position and frequency' as motivation; a brief reference to the Heisenberg uncertainty principle or the wavelet admissibility condition would clarify this for readers unfamiliar with the property.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract / empirical evaluation: the reported +0.119 improvement is obtained only for the combination of MoPE with Energy-Gated Attention on a single small dataset (TinyShakespeare); no ablation isolating the positional-encoding contribution is provided, so the performance claim for MoPE itself is not load-bearing.
Authors: We agree that the reported gain is for the combined MoPE + Energy-Gated Attention system and that isolating the positional-encoding contribution would make the empirical claims more robust. In the revised manuscript we will add ablation experiments that compare (i) MoPE versus sinusoidal encodings under standard attention and (ii) MoPE versus the baseline under the same energy-gated attention, all on TinyShakespeare. These results will be reported in a new table and discussed in the experimental section. revision: yes
-
Referee: [Theoretical result] Theoretical unification result: the claimed exact recovery of the RoPE angle and the emergence of both sinusoidal PE and the RoPE kernel are obtained by substituting the limit sigma_i -> infinity directly into the MoPE definition; the correspondence is therefore definitional once the wavelet form is chosen rather than an independent derivation.
Authors: We respectfully disagree that the result is merely definitional. The contribution consists in selecting the Morlet wavelet on the basis of its joint time-frequency localization properties and then demonstrating that this specific parametric family recovers both sinusoidal positional encodings and the RoPE kernel exactly in the infinite-bandwidth limit while simultaneously introducing a learnable Gaussian locality term absent from prior work. The exact phase recovery and the emergence of the two prior methods are therefore consequences of a principled choice rather than an arbitrary substitution. We will add a short paragraph in the theoretical section clarifying this motivation. revision: no
Circularity Check
No significant circularity identified
full rationale
The paper defines MoPE using the standard Morlet wavelet form (complex exponential times Gaussian envelope) with per-dimension parameters, then states that the sigma_i -> infinity limit recovers sinusoidal PE and the RoPE kernel with exact phase match. This is a direct mathematical consequence of the chosen functional form and standard wavelet properties, not a reduction of an independent derivation to its inputs. No self-citation chain, fitted parameter renamed as prediction, or ansatz smuggled via prior work is present in the unification claim. The empirical results on TinyShakespeare and learned parameter analysis are separate and do not rely on the limit statement. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-dimension frequency and locality bandwidth (sigma_i)
axioms (1)
- domain assumption The Morlet wavelet simultaneously minimises uncertainty in position and frequency and is therefore the natural basis for positional encoding.
Forward citations
Cited by 1 Pith paper
-
Multiscale POD of Transformer Attention Fields: Scale-Selective Analysis via Morlet Scalogram
Applies multiscale POD with Morlet scalograms to transformer attention fields to extract dominant modes per scale and reports layer-dependent scale organisation.
Reference graph
Works this paper leans on
-
[1]
Energy- G ated A ttention: S pectral S alience as an I nductive B ias for T ransformer A ttention
Zeris, A. Energy- G ated A ttention: S pectral S alience as an I nductive B ias for T ransformer A ttention. arXiv preprint arXiv:2605.21842v1, 2026
Pith/arXiv arXiv 2026
-
[2]
Zeris. A. E nergy- G ated A ttention and W avelet P ositional E ncoding: C omplementary I nductive B iases for T ransformer A ttention. arXiv preprint arXiv:2605.26355v1, 2026
Pith/arXiv arXiv 2026
-
[3]
FNet : M ixing T okens with F ourier T ransforms
Lee-Thorp, J., Ainslie, J., Eckstein, I., and Ontanon, S. FNet : M ixing T okens with F ourier T ransforms. arXiv preprint arXiv:2105.03824, 2021
arXiv 2021
-
[4]
A Wavelet Tour of Signal Processing
Mallat, S. A Wavelet Tour of Signal Processing. Academic Press, 1999
1999
-
[5]
A., and Lewis, M
Press, O., Smith, N. A., and Lewis, M. Train short, test long: A ttention with linear biases enables input length extrapolation. In ICLR, 2022
2022
-
[6]
N., Vinyals, O., Senior, A., and Sak, H
Sainath, T. N., Vinyals, O., Senior, A., and Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In ICASSP, pp.\ 4580--4584, 2015
2015
-
[7]
Self-attention with relative position representations
Shaw, P., Uszkoreit, J., and Vaswani, A. Self-attention with relative position representations. In NAACL, 2018
2018
-
[8]
RoFormer : E nhanced T ransformer with R otary P osition E mbedding
Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., and Liu, Y. RoFormer : E nhanced T ransformer with R otary P osition E mbedding. arXiv preprint arXiv:2104.09864, 2021
Pith/arXiv arXiv 2021
-
[9]
Language through a prism: A spectral approach for multiscale language representations
Tamkin, A., Jurafsky, D., and Goodman, N. Language through a prism: A spectral approach for multiscale language representations. In NeurIPS, volume 33, 2020
2020
-
[10]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. In NeurIPS, volume 30, 2017
2017
-
[11]
Verma, P. and Pilanci, M. Towards signal processing in large language models. arXiv preprint arXiv:2406.10254, 2024
arXiv 2024
-
[12]
LEAF : A L earnable F rontend for A udio C lassification
Zeghidour, N., Teboul, O., de Chaumont Quitry, F., and Tagliasacchi, M. LEAF : A L earnable F rontend for A udio C lassification. In ICLR, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.