Beyond Visual Memory: Mechanistic Diagnostics of Latent Visual Reasoning
Pith reviewed 2026-06-28 17:28 UTC · model grok-4.3
The pith
Gains from latent tokens in multimodal models arise from boundary markers and attention patterns, not from encoding visual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
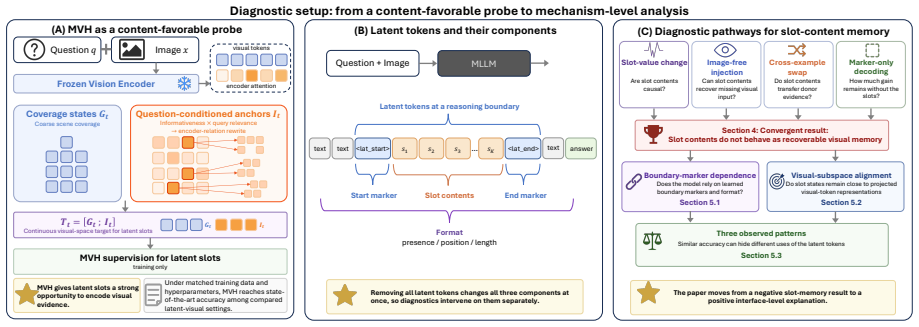
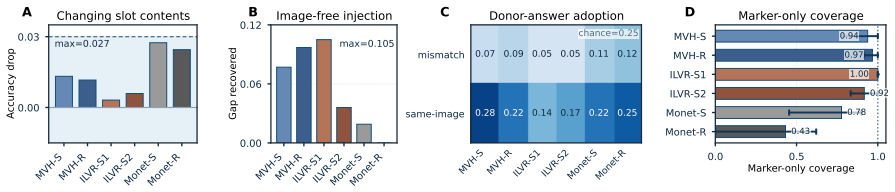
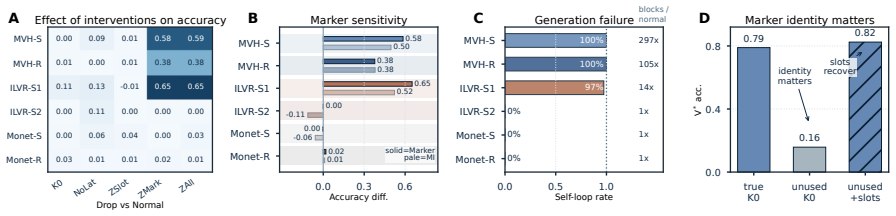
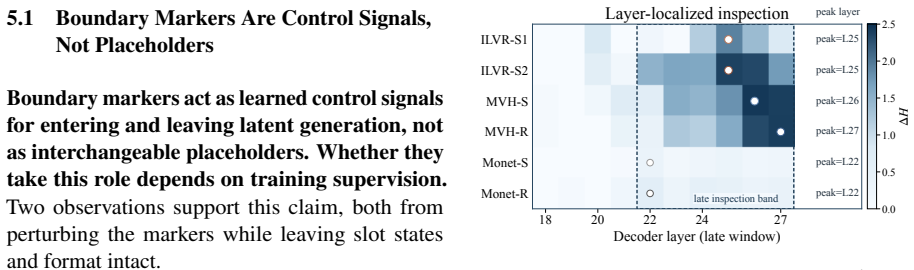
Decomposing latent tokens into latent slots, boundary markers, and format and testing under favorable conditions shows that latent slots contribute nothing consistent with visual memory. Boundary markers preserve 78–100 % of the gain in several cases, and attention at latent positions is narrower than at answer positions. The performance therefore traces to boundary markers, format, and the resulting attention pattern rather than to visual encoding inside the slots.
What carries the argument
Three-way decomposition of latent tokens into latent slots, boundary markers, and format, used as a diagnostic probe.
If this is right
- At the same accuracy level, different training regimes can produce different underlying mechanisms.
- Evaluation of latent visual reasoning must include mechanistic checks on what the model actually uses.
- The visual-memory explanation does not hold for the tested methods.
- Methods should be compared by the components they engage, not only by final accuracy.
Where Pith is reading between the lines
- Simpler formatting interventions could be tested as cheaper alternatives to full latent-token methods.
- The same decomposition could be applied to other multimodal architectures to check generality.
- Attention-pattern diagnostics might reveal efficiency gains by pruning unnecessary latent positions.
Load-bearing premise
The decomposition cleanly isolates the causal role of each component and the probe method tests the visual-memory account without adding its own confounds.
What would settle it
A controlled ablation in which boundary markers are removed while latent slots remain intact, and the full original gain disappears or is recovered solely by the slots.
Figures


read the original abstract
Recent latent visual reasoning methods achieve substantial gains by inserting continuous latent tokens into multimodal language models. These gains are commonly attributed to the tokens encoding visual evidence; recent analyses, however, reveal a paradox: the tokens are loosely tied to the image and contribute little to the answer. Critically, these analyses treat latent tokens as a single unit, obscuring the true source of the gains. We therefore decompose latent tokens into three testable components: latent slots, boundary markers, and format, and develop a state-of-the-art method as a probe under favorable conditions. Across six method-stage settings and four perception-heavy benchmarks, latent slots fail every prediction of the visual-memory account. Strikingly, retaining only the boundary markers preserves 78 to 100% of the gain in several settings, while the model attends to the image more narrowly at latent positions than at answer positions. The gain therefore comes from boundary markers, format, and this attention pattern, not from latent slots. How each method engages this mechanism depends on its training supervision: at matched accuracy, mechanisms can still differ markedly. Latent visual reasoning thus needs evaluation not only by accuracy but by what the model actually relies on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that performance gains from inserting continuous latent tokens into multimodal language models for visual reasoning are not due to latent slots encoding visual evidence. By decomposing tokens into latent slots, boundary markers, and format, and applying a state-of-the-art probe under favorable conditions across six method-stage settings and four perception-heavy benchmarks, the authors show that slots fail every prediction of the visual-memory account. Retaining only boundary markers preserves 78-100% of the gain in several settings, models attend more narrowly to images at latent positions than answer positions, and mechanisms vary by training supervision even at matched accuracy. The gains are attributed to boundary markers, format, and attention patterns rather than visual memory in slots.
Significance. If the decomposition and probe results hold, this work is significant for shifting the field away from assuming latent tokens provide visual memory toward mechanistic analysis of structural and attentional factors in multimodal models. The direct experimental outcomes across multiple settings and benchmarks, plus the emphasis on evaluating what models actually rely on (beyond accuracy), represent a strength and could improve design of interpretable latent reasoning methods.
major comments (2)
- [§3] §3 (decomposition into three components): The three-way split assumes boundary markers and format can be isolated from latent slots without residual interactions. Since markers are inserted structurally with slots, ablating slots may alter attention or format operation, so the 78-100% preservation when retaining markers does not necessarily demonstrate clean causal attribution to markers alone. This is load-bearing for the central claim that gains come from markers/format/attention rather than slots.
- [Methods] Methods and probe description: The state-of-the-art probe 'under favorable conditions' is invoked to show slots fail every visual-memory prediction, but no validation is reported that the probe itself does not bias toward non-slot mechanisms. Without such controls, the failure of slots could reflect probe artifacts rather than true mechanism, affecting the conclusion across all six settings.
minor comments (2)
- The abstract and introduction should explicitly name the six method-stage settings and four benchmarks to support reproducibility claims.
- Attention pattern figures would benefit from error bars or statistical tests to substantiate the 'narrower attention at latent positions' observation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and positive assessment of the work's significance. We respond point-by-point to the major comments below, addressing concerns about causal attribution in the decomposition and probe validation.
read point-by-point responses
-
Referee: [§3] §3 (decomposition into three components): The three-way split assumes boundary markers and format can be isolated from latent slots without residual interactions. Since markers are inserted structurally with slots, ablating slots may alter attention or format operation, so the 78-100% preservation when retaining markers does not necessarily demonstrate clean causal attribution to markers alone. This is load-bearing for the central claim that gains come from markers/format/attention rather than slots.
Authors: We acknowledge the possibility of residual interactions when ablating slots. However, the decomposition isolates components by construction while preserving overall input structure, and we separately measure attention patterns at latent versus answer positions to detect shifts. The fact that marker-only retention preserves 78-100% of gains consistently across six method-stage settings and four benchmarks, while slots fail all visual-memory predictions, indicates that interactions do not account for the primary effect. We will add explicit discussion of this assumption and any observed attention changes upon ablation to the revised manuscript. revision: partial
-
Referee: [Methods] Methods and probe description: The state-of-the-art probe 'under favorable conditions' is invoked to show slots fail every visual-memory prediction, but no validation is reported that the probe itself does not bias toward non-slot mechanisms. Without such controls, the failure of slots could reflect probe artifacts rather than true mechanism, affecting the conclusion across all six settings.
Authors: The probe is a state-of-the-art architecture drawn from recent literature and applied under conditions (e.g., optimal hyperparameters, held-out training data, and multiple benchmarks) chosen to maximize detection of visual memory if present in the slots. Prior work validating this probe class has demonstrated recovery of visual information when it exists in representations. The uniform failure of slots across all settings, paired with the independent attention analysis showing narrower image focus at latent positions, supports that the result reflects mechanism rather than artifact. We will expand the methods section with explicit controls and limitations discussion in the revision. revision: partial
Circularity Check
No significant circularity; empirical decomposition and benchmark results are self-contained
full rationale
The paper reports direct experimental outcomes from decomposing latent tokens into slots/markers/format and testing predictions on six method-stage settings across four benchmarks. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes imported via prior work are present in the provided text. Claims rest on observed accuracy preservation (78-100%) and attention patterns rather than any self-referential reduction. This is the expected finding for an empirical diagnostic study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention patterns at latent positions indicate the model's reliance on image content for the task.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[2]
2026 , eprint=
Interleaved Latent Visual Reasoning with Selective Perceptual Modeling , author=. 2026 , eprint=
2026
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Monet: Reasoning in Latent Visual Space Beyond Images and Language , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[4]
The Fourteenth International Conference on Learning Representations , year=
Latent Visual Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[5]
Proceedings of the 43rd International Conference on Machine Learning , year=
Imagination Helps Visual Reasoning, But Not Yet in Latent Space , author=. Proceedings of the 43rd International Conference on Machine Learning , year=
-
[6]
2026 , eprint=
What's Holding Back Latent Visual Reasoning? , author=. 2026 , eprint=
2026
-
[7]
2026 , eprint=
Visual Latents Know More Than They Say: Unsilencing Latent Reasoning in MLLMs , author=. 2026 , eprint=
2026
-
[8]
2025 , eprint=
Do Latent Tokens Think? A Causal and Adversarial Analysis of Chain-of-Continuous-Thought , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens , author=. 2025 , eprint=
2025
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Think with 3D: Geometric Imagination Grounded Spatial Reasoning from Limited Views , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[11]
2026 , eprint=
Forest Before Trees: Latent Superposition for Efficient Visual Reasoning , author=. 2026 , eprint=
2026
-
[12]
2026 , eprint=
CoLVR: Enhancing Exploratory Latent Visual Reasoning via Contrastive Optimization , author=. 2026 , eprint=
2026
-
[13]
2025 , eprint=
Latent Sketchpad: Sketching Visual Thoughts to Elicit Multimodal Reasoning in MLLMs , author=. 2025 , eprint=
2025
-
[14]
Forty-second International Conference on Machine Learning , year=
Imagine While Reasoning in Space: Multimodal Visualization-of-Thought , author=. Forty-second International Conference on Machine Learning , year=
-
[15]
The Fourteenth International Conference on Learning Representations , year=
DeepEyes: Incentivizing ''Thinking with Images'' via Reinforcement Learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[16]
2025 , eprint=
Training Large Language Models to Reason in a Continuous Latent Space , author=. 2025 , eprint=
2025
-
[17]
International Conference on Learning Representations , volume=
Think before you speak: Training language models with pause tokens , author=. International Conference on Learning Representations , volume=
-
[18]
Bowman , booktitle=
Jacob Pfau and William Merrill and Samuel R. Bowman , booktitle=. Let. 2024 , url=
2024
-
[19]
The Twelfth International Conference on Learning Representations , year=
Vision Transformers Need Registers , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models
Hu, Yushi and Shi, Weijia and Fu, Xingyu and Roth, Dan and Ostendorf, Mari and Zettlemoyer, Luke and Smith, Noah and Krishna, Ranjay , booktitle =. Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models , url =. doi:10.52202/079017-4423 , editor =
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Man, Yunze and Huang, De-An and Liu, Guilin and Sheng, Shiwei and Liu, Shilong and Gui, Liang-Yan and Kautz, Jan and Wang, Yu-Xiong and Yu, Zhiding , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[22]
and Krishna, Ranjay , title =
Bigverdi, Mahtab and Luo, Zelun and Hsieh, Cheng-Yu and Shen, Ethan and Chen, Dongping and Shapiro, Linda G. and Krishna, Ranjay , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[23]
Wu, Penghao and Xie, Saining , booktitle=
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[25]
2025 , url=
YiFan Zhang and Huanyu Zhang and Haochen Tian and Chaoyou Fu and Shuangqing Zhang and Junfei Wu and Feng Li and Kun Wang and Qingsong Wen and Zhang Zhang and Liang Wang and Rong Jin , booktitle=. 2025 , url=
2025
-
[26]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[27]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[28]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[30]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
2025 , eprint=
VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models , author=. 2025 , eprint=
2025
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Comt: A novel benchmark for chain of multi-modal thought on large vision-language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
2025 , eprint=
A Survey on Latent Reasoning , author=. 2025 , eprint=
2025
-
[34]
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results , url =
Tarvainen, Antti and Valpola, Harri , booktitle =. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results , url =
-
[35]
Latent Chain-of-Thought for Visual Reasoning , url =
Sun, Guohao and Hua, Hang and Wang, Jian and Luo, Jiebo and Dianat, Sohail and RABBANI, MAJID and Rao, Raghuveer and Tao, Zhiqiang , booktitle =. Latent Chain-of-Thought for Visual Reasoning , url =
-
[36]
The Fourteenth International Conference on Learning Representations , year=
DeepEyesV2: Toward Agentic Multimodal Model , author=. The Fourteenth International Conference on Learning Representations , year=
-
[37]
Pixel Reasoner: Incentivizing Pixel Space Reasoning via Curiosity-Driven Reinforcement Learning , url =
Su, Alex and Wang, Haozhe and Ren, Weiming and Lin, Fangzhen and Chen, Wenhu , booktitle =. Pixel Reasoner: Incentivizing Pixel Space Reasoning via Curiosity-Driven Reinforcement Learning , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.