What to Test Next: Interpretable Coverage Gap Discovery in Driving VLMs
Pith reviewed 2026-06-28 15:34 UTC · model grok-4.3
The pith
A deterministic scorer using exposure and neighbor-failure priors recommends high-risk missing test slices for driving VLMs more effectively than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
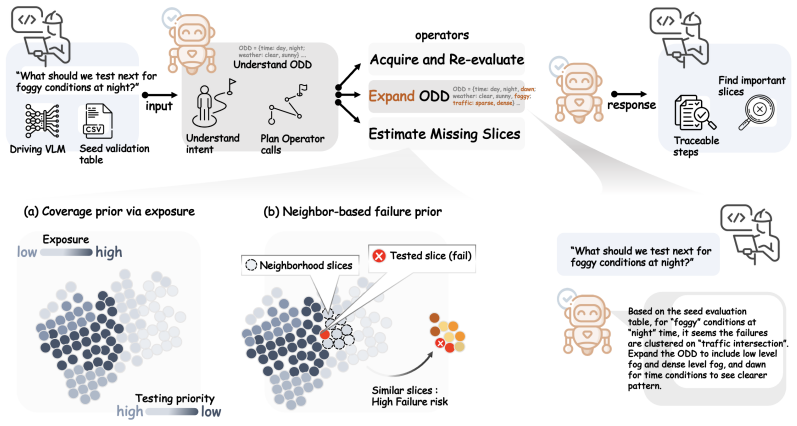
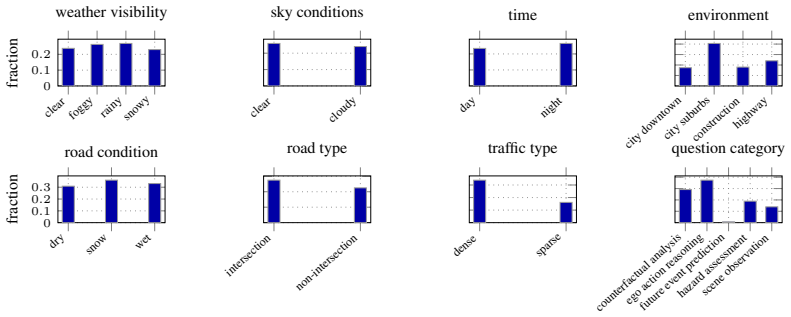
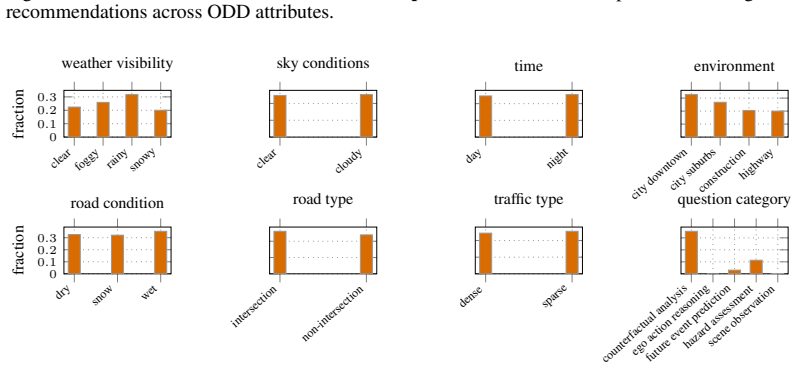
SliceScorer is a deterministic scoring rule that combines an exposure-based coverage prior to prioritize rare, under-tested regions with a neighbor-failure prior that propagates risk from similar tested conditions. When embedded in the SliceNav pipeline, which uses an LLM to interpret queries and select operators while preserving deterministic scoring, it surfaces high-risk coverage gaps more effectively than prior slice-discovery methods on three driving VLMs while maintaining diverse recommendations.
What carries the argument
SliceScorer, a deterministic scoring rule combining exposure-based coverage prior and neighbor-failure prior for missing-slice recommendation.
If this is right
- The method identifies coverage gaps that carry higher failure risk than those found by earlier techniques.
- Recommendations remain spread across the condition space rather than clustering in narrow areas.
- Both the exposure and neighbor components are necessary, as shown by ablations.
- The full pipeline supports traceable workflows from a natural-language query to concrete evaluations.
Where Pith is reading between the lines
- This scoring approach could be applied to other verification tasks where test conditions form a continuous space with local similarity.
- If the priors align with real failure modes, it may allow more efficient allocation of testing resources in safety validation.
- The separation of LLM orchestration from deterministic scoring might reduce risks of inconsistent or unexplainable recommendations in regulated domains.
Load-bearing premise
The exposure-based coverage prior and neighbor-failure prior accurately reflect actual risk of failure in untested slices.
What would settle it
Running targeted evaluations on the slices recommended by SliceNav versus those from baseline methods and finding that the recommended slices do not exhibit higher failure rates.
Figures



read the original abstract
Driving vision-language models (VLMs) must accurately understand scenes across diverse conditions defined by Operational Design Domains (ODDs), yet verification remains sparse: many slices are missing, making empirical failure rates unreliable. We propose SliceScorer, a deterministic scoring rule for missing-slice recommendation that combines (i) an exposure-based coverage prior to prioritize rare, under-tested regions, and (ii) a neighbor-failure prior that propagates risk from similar tested conditions. SliceScorer is deliberately simple - interpretable, auditable, and conservative - properties essential for safety-critical validation. For stress testing beyond the declared ODD, we embed SliceScorer within SliceNav, an LLM-orchestrated verification pipeline where the model interprets developer queries to select relevant operators (triage, scoring, acquisition, evaluation) and vocabulary extensions, composing verification workflows while keeping all scoring deterministic and auditable. Experiments on three driving VLMs (WiseAD, DriveMM, Cosmos-Reason2-2B) show that SliceNav surfaces high-risk coverage gaps more effectively than prior slice-discovery methods while maintaining diverse recommendations across the condition space. Ablations confirm both scoring components contribute, and qualitative analysis demonstrates end-to-end workflows from developer query to targeted evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SliceScorer, a deterministic scoring rule combining an exposure-based coverage prior (prioritizing rare under-tested regions) and a neighbor-failure prior (propagating risk from similar tested conditions) to recommend missing slices for driving VLM verification. SliceScorer is embedded in SliceNav, an LLM-orchestrated pipeline that interprets developer queries to select operators and compose auditable verification workflows. Experiments on three VLMs (WiseAD, DriveMM, Cosmos-Reason2-2B) claim SliceNav outperforms prior slice-discovery methods at surfacing high-risk gaps while maintaining diversity across the condition space; ablations confirm both scoring components contribute.
Significance. If the result holds, the work supplies a deliberately simple, interpretable, and auditable approach to coverage-gap discovery for safety-critical VLM validation in autonomous driving. The deterministic nature of the scoring rule, the explicit separation of priors from the LLM orchestration layer, and the reported ablations are concrete strengths that align with verification needs. The approach could support more systematic ODD testing if the priors are shown to track actual failure risk.
major comments (2)
- [Experiments section] Experiments section (as summarized in the abstract): the claim that SliceNav 'surfaces high-risk coverage gaps more effectively' is evaluated using SliceScorer itself; no results are reported from subsequently running the three VLMs on the recommended slices and measuring empirical failure rates (e.g., incorrect scene descriptions or predictions). Without this independent signal, superiority reduces to a coverage-diversity comparison rather than a risk-identification result.
- [Ablations] Ablations paragraph (abstract): the statement that 'ablations confirm both scoring components contribute' measures contribution against the composite SliceScorer score; this does not test whether the exposure or neighbor-failure prior actually correlates with higher VLM failure rates on the surfaced slices.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback, particularly the emphasis on distinguishing score-based evaluation from direct empirical validation of risk. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (as summarized in the abstract): the claim that SliceNav 'surfaces high-risk coverage gaps more effectively' is evaluated using SliceScorer itself; no results are reported from subsequently running the three VLMs on the recommended slices and measuring empirical failure rates (e.g., incorrect scene descriptions or predictions). Without this independent signal, superiority reduces to a coverage-diversity comparison rather than a risk-identification result.
Authors: We agree that the reported experiments evaluate SliceNav by comparing SliceScorer values and diversity metrics across methods, without additional VLM inference runs on the newly recommended slices to obtain independent failure rates. The 'high-risk' designation in the manuscript is defined operationally via the exposure and neighbor-failure priors. We recognize that this constitutes an evaluation of coverage and diversity under the proposed scoring rule rather than an independent demonstration of risk identification through measured VLM errors. In the revision we will update the abstract and experiments section to describe the results more precisely as superior slice discovery according to the defined priors and metrics, and we will explicitly note the lack of direct failure-rate measurements as a limitation of the current evaluation. revision: yes
-
Referee: [Ablations] Ablations paragraph (abstract): the statement that 'ablations confirm both scoring components contribute' measures contribution against the composite SliceScorer score; this does not test whether the exposure or neighbor-failure prior actually correlates with higher VLM failure rates on the surfaced slices.
Authors: The ablations compare the full SliceScorer against ablated variants using the same composite scoring and ranking criteria, thereby showing that each prior improves the overall score. We acknowledge that these results do not establish a direct empirical correlation between the individual priors and observed VLM failure rates. We will revise the abstract and ablation discussion to state that the ablations confirm the contribution of both components to the composite scoring rule. revision: yes
Circularity Check
No circularity: deterministic heuristic with independent evaluation claims
full rationale
The paper defines SliceScorer explicitly as a deterministic, non-learned combination of two priors (exposure-based coverage and neighbor-failure) and embeds it in SliceNav without any equations, parameter fitting, or self-citation chains that reduce the output to the input by construction. Experiments compare recommendation quality against prior slice-discovery methods on three VLMs and include ablations on the two components; no derivation step is shown that renames a fitted quantity as a prediction or imports uniqueness from the authors' prior work. The method is therefore self-contained as a proposed auditable heuristic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automated Data Slicing for Model Validation:A Big data - AI Integration Approach
Yeounoh Chung, Tim Kraska, Steven Euijong Whang, and Neoklis Polyzotis. Slice finder: Automated data slicing for model validation.arXiv preprint arXiv:1807.06068, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Sliceline: Fast, linear-algebra-based slice finding for ml model debugging
Svetlana Sagadeeva and Matthias Boehm. Sliceline: Fast, linear-algebra-based slice finding for ml model debugging. InSIGMOD, 2021
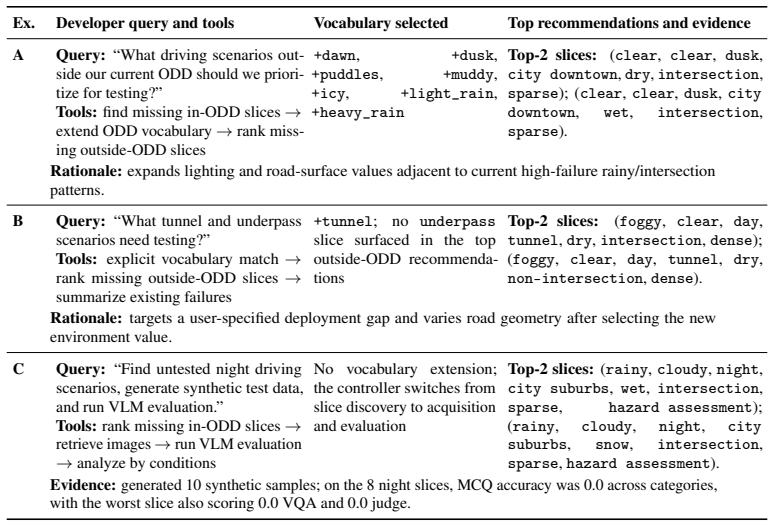
2021
-
[3]
Standard ISO 34503:2023, International Organization for Standardization, Geneva, CH, Aug 2023
Road vehicles — Test scenarios for automated driving systems — Specification for operational design domain. Standard ISO 34503:2023, International Organization for Standardization, Geneva, CH, Aug 2023. Accessed: 05 March 2026
2023
-
[4]
Road vehicles — safety of the intended func- tionality
International Organization for Standardization. Road vehicles — safety of the intended func- tionality. Standard ISO 21448:2022, International Organization for Standardization, Geneva, CH, jun 2022
2022
-
[5]
Coverage metrics for a scenario database for the scenario-based assessment of automated driving systems
Erwin de Gelder, Maren Buermann, and Olaf Op Den Camp. Coverage metrics for a scenario database for the scenario-based assessment of automated driving systems. In2024 IEEE International Automated Vehicle Validation Conference (IAVVC), pages 1–8. IEEE, 2024
2024
-
[6]
Songyan Zhang, Wenhui Huang, Zihui Gao, Hao Chen, and Chen Lv. Wisead: Knowl- edge augmented end-to-end autonomous driving with vision-language model.arXiv preprint arXiv:2412.09951, 2024
-
[7]
arXiv preprint arXiv:2412.07689 (2024) 4, 8
Zhijian Huang, Chengjian Fen, Feng Yan, Baihui Xiao, Zequn Jie, Yujie Zhong, Xiaodan Liang, and Lin Ma. Drivemm: All-in-one large multimodal model for autonomous driving.arXiv preprint arXiv:2412.07689, 2024
-
[8]
Cosmos-Reason2 — NVIDIA Documentation
NVIDIA Corporation. Cosmos-Reason2 — NVIDIA Documentation. https://docs.nvidia. com/cosmos/latest/reason2/index.html, 2026. Accessed: 2026-03-05
2026
-
[9]
Autoslicer: Scalable automated data slicing for ml model analysis
Zifan Liu, Evan Rosen, et al. Autoslicer: Scalable automated data slicing for ml model analysis. 2022
2022
-
[10]
Divisi: Interactive search and visualization for scalable exploratory subgroup analysis
Venkatesh Sivaraman, Zexuan Li, and Adam Perer. Divisi: Interactive search and visualization for scalable exploratory subgroup analysis. pages 1–17, 2025
2025
-
[11]
Looking for trouble: Analyzing classifier behavior via pattern divergence
Eliana Pastor, Luca De Alfaro, and Elena Baralis. Looking for trouble: Analyzing classifier behavior via pattern divergence. InProceedings of the 2021 International Conference on Management of Data, pages 1400–1412, 2021
2021
-
[12]
Sabri Eyuboglu, Maya Varma, Khaled Saab, Jean-Benoit Delbrouck, Christopher Lee-Messer, Jared Dunnmon, James Zou, and Christopher Ré. Domino: Discovering systematic errors with cross-modal embeddings.arXiv preprint arXiv:2203.14960, 2022
-
[13]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng et al. Judging llm-as-a-judge with mt-bench and chatbot arena.arXiv preprint arXiv:2306.05685, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, et al. Mm-vet: Evaluating large multimodal models for integrated capabilities.arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Towards A Rigorous Science of Interpretable Machine Learning
Finale Doshi-Velez and Been Kim. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608, 2017. 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness? InACL, 2020
Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness? InACL, 2020
2020
-
[18]
Domino: Discovering systematic errors with cross-modal embeddings
Sabri Eyuboglu, Maya Varma, Khaled Saab, Jean-Benoit Delbrouck, Christopher Lee-Messer, Jared Dunnmon, James Zou, and Christopher Ré. Domino: Discovering systematic errors with cross-modal embeddings. InICLR, 2022
2022
-
[19]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024
2024
-
[20]
McNee, Joseph A
Cai-Nicolas Ziegler, Sean M. McNee, Joseph A. Konstan, and Georg Lausen. Improving recommendation lists through topic diversification. InProceedings of the 14th International Conference on World Wide Web (WWW), pages 22–32, 2005
2005
-
[21]
ContextVLM: Zero-shot and few-shot context understanding for autonomous driving using vision language models.arXiv [cs.CV], August 2024
Sural Shounak, Naren, and Rajkumar Ragunathan. ContextVLM: Zero-shot and few-shot context understanding for autonomous driving using vision language models.arXiv [cs.CV], August 2024
2024
-
[22]
Drama: Joint risk localization and captioning in driving
Srikanth Malla, Chiho Choi, Isht Dwivedi, Joon Hee Choi, and Jiachen Li. Drama: Joint risk localization and captioning in driving. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1043–1052, 2023
2023
-
[23]
Charles Corbière, Simon Roburin, Syrielle Montariol, Antoine Bosselut, and Alexandre Alahi. Drivingvqa: Analyzing visual chain-of-thought reasoning of vision language models in real- world scenarios with driving theory tests.arXiv preprint arXiv:2501.04671, 2025
-
[24]
Lingoqa: Visual question answering for autonomous driving
Ana-Maria Marcu, Long Chen, Jan Hünermann, Alice Karnsund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shotton, et al. Lingoqa: Visual question answering for autonomous driving. InEuropean Conference on Computer Vision, pages 252–269. Springer, 2024
2024
-
[25]
Realworldqa.https://x.ai/blog/realworldqa, November 2024
X.AI. Realworldqa.https://x.ai/blog/realworldqa, November 2024. Blog post
2024
-
[26]
Sutd-trafficqa: A question answering benchmark and an efficient network for video reasoning over traffic events
Li Xu, He Huang, and Jun Liu. Sutd-trafficqa: A question answering benchmark and an efficient network for video reasoning over traffic events. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9878–9888, 2021
2021
-
[27]
TUMTraffic- VideoQA: A benchmark for unified spatio-temporal video understanding in traffic scenes.arXiv [cs.CV], February 2025
Xingcheng Zhou, Konstantinos Larintzakis, Hao Guo, Walter Zimmer, Mingyu Liu, Hu Cao, Jia- jie Zhang, Venkatnarayanan Lakshminarasimhan, Leah Strand, and Alois C Knoll. TUMTraffic- VideoQA: A benchmark for unified spatio-temporal video understanding in traffic scenes.arXiv [cs.CV], February 2025
2025
-
[28]
Canadian adverse driving conditions dataset.The Interna- tional Journal of Robotics Research, 40(4-5):681–690, 2021
Matthew Pitropov, Danson Evan Garcia, Jason Rebello, Michael Smart, Carlos Wang, Krzysztof Czarnecki, and Steven Waslander. Canadian adverse driving conditions dataset.The Interna- tional Journal of Robotics Research, 40(4-5):681–690, 2021
2021
-
[29]
Pesotif: A challenging visual dataset for perception sotif problems in long-tail traffic scenarios
Liang Peng, Jun Li, Wenbo Shao, and Hong Wang. Pesotif: A challenging visual dataset for perception sotif problems in long-tail traffic scenarios. In2023 IEEE Intelligent Vehicles Symposium (IV), pages 1–8. IEEE, 2023
2023
-
[30]
Dawn: vehicle detection in adverse weather nature dataset.arXiv preprint arXiv:2008.05402, 2020
Mourad A Kenk and Mahmoud Hassaballah. Dawn: vehicle detection in adverse weather nature dataset.arXiv preprint arXiv:2008.05402, 2020
-
[31]
Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving
Mina Alibeigi, William Ljungbergh, Adam Tonderski, Georg Hess, Adam Lilja, Carl Lindström, Daria Motorniuk, Junsheng Fu, Jenny Widahl, and Christoffer Petersson. Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20178–20188, 2023
2023
-
[32]
Radiate: A radar dataset for automotive perception in bad weather
Marcel Sheeny, Emanuele De Pellegrin, Saptarshi Mukherjee, Alireza Ahrabian, Sen Wang, and Andrew Wallace. Radiate: A radar dataset for automotive perception in bad weather. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 1–7. IEEE, 2021. 11
2021
-
[33]
Video weather recognition (varg): An intensity-labeled video weather recognition dataset.Journal of imaging, 10(11):281, 2024
Himanshu Gupta, Oleksandr Kotlyar, Henrik Andreasson, and Achim J Lilienthal. Video weather recognition (varg): An intensity-labeled video weather recognition dataset.Journal of imaging, 10(11):281, 2024
2024
-
[34]
Wedge: A multi-weather autonomous driving dataset built from generative vision-language models
Aboli Marathe, Deva Ramanan, Rahee Walambe, and Ketan Kotecha. Wedge: A multi-weather autonomous driving dataset built from generative vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3318–3327, 2023
2023
-
[35]
Wilddash-creating hazard-aware benchmarks
Oliver Zendel, Katrin Honauer, Markus Murschitz, Daniel Steininger, and Gustavo Fernandez Dominguez. Wilddash-creating hazard-aware benchmarks. InProceedings of the European conference on computer vision (ECCV), pages 402–416, 2018
2018
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Introducing GPT-5.2, 12 2025
OpenAI. Introducing GPT-5.2, 12 2025. Accessed: 2026-03-05
2025
-
[38]
Joseph L. Fleiss. Measuring nominal scale agreement among many raters.Psychological Bulletin, 76(5):378–382, 1971
1971
-
[39]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 3982–3992, 2019
2019
-
[40]
Étude comparative de la distribution florale dans une portion des alpes et des jura
Paul Jaccard. Étude comparative de la distribution florale dans une portion des alpes et des jura. Bulletin de la Société Vaudoise des Sciences Naturelles, 37:547–579, 1901
1901
-
[41]
Taxonomy and definitions for terms related to on-road motor vehicle automated driving systems.SAE Standard J, 3016:1, 2014
SAE On-Road Automated Vehicle Standards Committee et al. Taxonomy and definitions for terms related to on-road motor vehicle automated driving systems.SAE Standard J, 3016:1, 2014
2014
-
[42]
Roadwork: A dataset and benchmark for learning to recognize, observe, analyze and drive through work zones
Anurag Ghosh, Shen Zheng, Robert Tamburo, Khiem Vuong, Juan Alvarez-Padilla, Hailiang Zhu, Michael Cardei, Nicholas Dunn, Christoph Mertz, and Srinivasa G Narasimhan. Roadwork: A dataset and benchmark for learning to recognize, observe, analyze and drive through work zones. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6...
2025
-
[43]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles.arXiv preprint arXiv:2106.11810, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
NVIDIA Alpamayo
NVIDIA. NVIDIA Alpamayo. https://developer.nvidia.com/drive/alpamayo, 2025. Accessed: 2026-05-06
2025
-
[45]
BDD100K: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. BDD100K: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2636–2645, 2020
2020
-
[46]
environmental, geographical, and time-of-day restrictions, and/or the requisite presence or absence of certain traffic or roadway characteristics
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
2025
-
[47]
Extract predicatesfrom SliceLine’s top-k discovered slices, each with an associated error score
-
[48]
Assignsthe score of its best-matching (highest-scoring) predicate
Expand to full slices:For each candidate full slice s, find all predicates whose constraints are satisfied bys. Assignsthe score of its best-matching (highest-scoring) predicate
-
[49]
foggy + night
Rank by specificity then discovery order:Sort matched slices first by predicate specificity (number of constrained dimensions, descending), then by predicate discovery rank (ascending), then by predicate score (descending), with slice identifier as the final deterministic tie-breaker. This expansion allows SliceLine’s partial-predicate signal to propagate...
-
[50]
What driving scenarios outside our current ODD should we prioritize for testing?
-
[51]
Identify high-risk conditions we haven’t validated yet
-
[52]
What blind spots exist in our current test coverage? 18
-
[53]
Suggest untested edge cases that could cause failures in deployment
-
[54]
We’re expanding to construction zones - what untested scenarios should we prioritize?
-
[55]
What snow and ice scenarios are we missing?
-
[56]
What nighttime edge cases should we test?
-
[57]
We’re deploying on rural highways - what scenarios haven’t we covered?
-
[58]
What tunnel and underpass scenarios need testing?
-
[59]
We’re concerned about heavy rain - what wet road scenarios should we prioritize?
-
[60]
What rush hour congestion scenarios are undertested?
-
[61]
What dawn and dusk visibility scenarios are we missing?
-
[62]
Find high-risk untested scenarios and acquire test samples for evaluation
-
[63]
Identify missing foggy highway slices, retrieve test images, and evaluate the model
-
[64]
Outside - ODD
Find untested night driving scenarios, generate synthetic test data, and run VLM evaluation. H LLM choose-slices baseline prompts This section reproduces the prompts used by the LLM baseline in Analysis 4. Note that the baseline conditions on acompact text summaryof the seed triage CSV - marginals, support statistics, and aggregate judge scores - not the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.