Towards 3D-Aware Video Diffusion Models: Render-Free Human Motion Control with Mesh Tokenization
Pith reviewed 2026-06-28 15:00 UTC · model grok-4.3
The pith
Conditioning video diffusion models directly on 3D human mesh tokens enables render-free motion control by forcing joint reasoning over geometry, appearance, and viewpoint.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a render-free framework conditioning video generation directly on compressed 3D human mesh tokens, processed jointly with video tokens in a DiT architecture, makes the model reason jointly about appearance, 3D structure, and camera viewpoint, yielding stronger results on motion control benchmarks and fewer artifacts than 2D guidance approaches.
What carries the argument
Compressed 3D human mesh tokens that preserve full geometric information and are fed into the same token-based DiT pipeline as video tokens.
If this is right
- The method achieves strong performance on human motion control benchmarks.
- It reduces artifacts induced by view-dependent 2D guidance.
- It reduces trajectory-pose mismatches during editing tasks.
- Generated videos better capture complex 3D human structures and their interactions with the surrounding environment.
Where Pith is reading between the lines
- Similar mesh token conditioning could be tested on video generation tasks involving rigid objects or animals to check if the 3D reasoning benefit generalizes.
- The unified token pipeline might allow simpler integration of additional control signals like lighting or object interactions without extra rendering stages.
- If the joint reasoning works, it could reduce the need for multi-stage pipelines that first render guidance and then generate video.
Load-bearing premise
Conditioning directly on compressed 3D mesh tokens preserves complete geometric details and compels the model to reason about 3D structure instead of 2D projections.
What would settle it
Videos generated from the mesh tokens that still show view-dependent distortions or 3D-inconsistent human poses when viewed from new angles would indicate the claim does not hold.
Figures

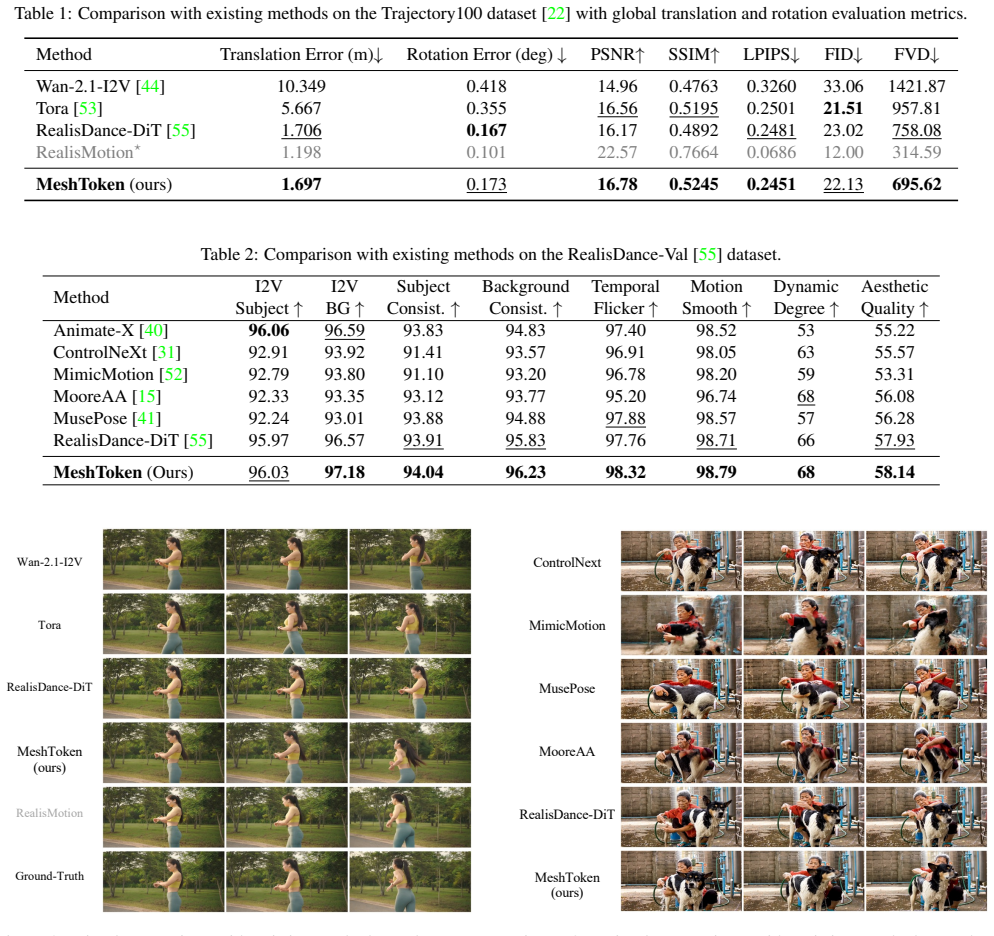
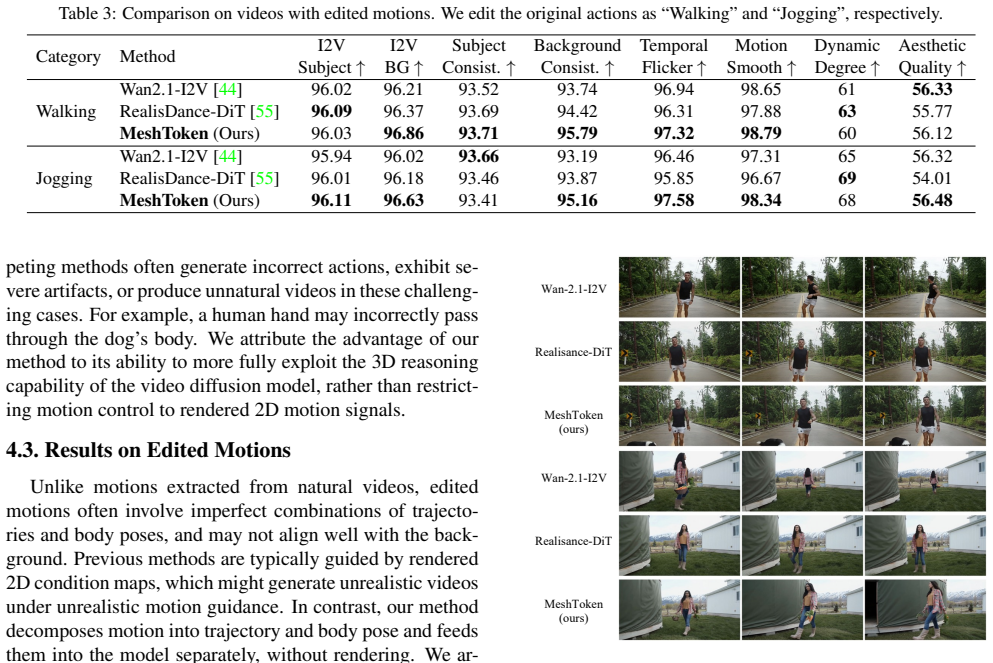
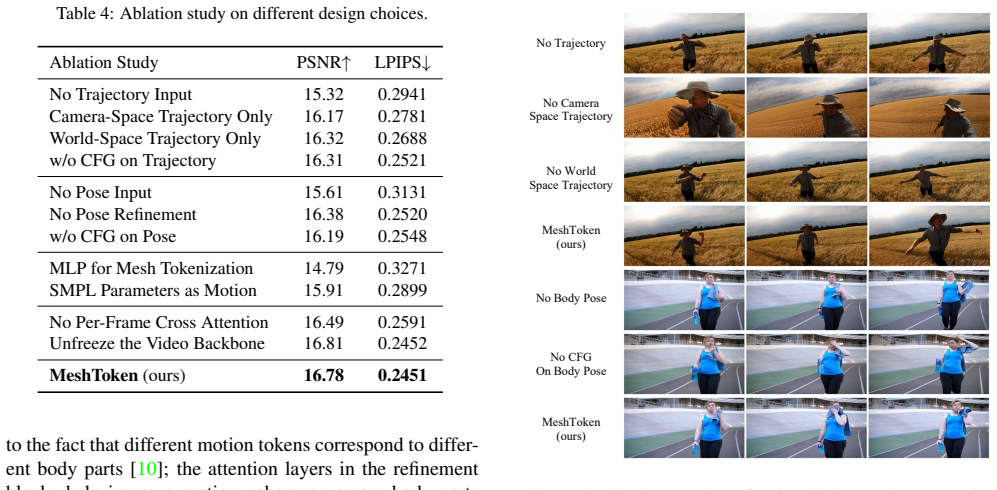
read the original abstract
Diffusion models have shown remarkable success in video generation. However, whether such models are truly aware of the 3D structure underlying visual observations, rather than simply reproducing plausible 2D projections, remains an open question. In this work, we investigate this question through human motion control, a task that requires precise modelling of 3D human geometry, motion, camera viewpoint, and scene context. Unlike prior methods that rely on rendered 2D motion guidance videos, we propose a render-free framework that conditions video generation directly on compressed 3D human mesh tokens. This representation preserves full 3D geometric information while enabling a unified token-based generation pipeline that processes video tokens jointly with motion tokens in a DiT-based architecture. This design requires the model to reason jointly about appearance, 3D structure, and camera viewpoint during video generation. Experimental results demonstrate strong performance on human motion control benchmarks, while reducing artifacts induced by view-dependent 2D guidance and trajectory-pose mismatches during editing. These findings suggest that video diffusion models, when equipped with mesh tokenization, can better capture complex 3D human structures and their interactions with the surrounding environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether video diffusion models are truly 3D-aware by focusing on human motion control. It proposes a render-free framework that conditions a DiT-based video generator directly on compressed 3D human mesh tokens (instead of 2D rendered motion videos), claiming this preserves full geometric information, forces joint reasoning over appearance/structure/viewpoint, reduces view-dependent artifacts and trajectory-pose mismatches, and yields stronger benchmark performance on human motion control.
Significance. If the central claim holds, the work would provide evidence that mesh-token conditioning can make diffusion models more geometrically grounded than 2D-guidance baselines, with potential implications for controllable 3D-aware video synthesis. The render-free, unified token pipeline is a clean design point that avoids an external rendering step.
minor comments (2)
- [Abstract] Abstract states that the mesh representation 'preserves full 3D geometric information' and 'enables a unified token-based generation pipeline,' but supplies no description of the compression/tokenization procedure, token dimensionality, or how geometric fidelity is maintained after compression.
- [Abstract] The abstract asserts 'strong performance on human motion control benchmarks' and 'reducing artifacts' without any quantitative metrics, baselines, ablations, or dataset details, preventing assessment of whether the reported gains actually support the 3D-awareness claim.
Simulated Author's Rebuttal
We thank the referee for their review and for acknowledging the potential significance of investigating 3D awareness in video diffusion models via render-free mesh token conditioning. We note that the report contains no specific major comments to address point-by-point.
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present a design proposal for mesh token conditioning in video diffusion models without any equations, parameter fitting, derivations, or self-citations that reduce claims to inputs by construction. No load-bearing steps match the enumerated circularity patterns; the central argument remains a coherent architectural choice rather than a self-referential reduction. This is the expected honest non-finding for a methods paper whose claims rest on empirical demonstration rather than closed-form derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Compressed 3D human mesh tokens preserve full geometric information sufficient for joint reasoning about appearance, structure, and viewpoint.
Reference graph
Works this paper leans on
-
[1]
Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 1
Pith/arXiv arXiv 2025
-
[2]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 1, 3
Pith/arXiv arXiv 2023
-
[3]
Chenjie Cao, Jingkai Zhou, Shikai Li, Jingyun Liang, Chaohui Yu, Fan Wang, Xiangyang Xue, and Yanwei Fu. Uni3c: Unifying precisely 3d-enhanced camera and hu- man motion controls for video generation.arXiv preprint arXiv:2504.14899, 2025. 3
arXiv 2025
-
[4]
Diffusion forcing: Next-token prediction meets full-sequence diffu- sion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Mart ´ı Mons´o, Yilun Du, Max Sim- chowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffu- sion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024. 1
2024
-
[5]
Yingjie Chen, Yifang Men, Yuan Yao, Miaomiao Cui, and Liefeng Bo. Perception-as-control: Fine-grained control- lable image animation with 3d-aware motion representation. arXiv preprint arXiv:2501.05020, 2025. 3
arXiv 2025
-
[6]
Yuren Cong, Mengmeng Xu, Christian Simon, Shoufa Chen, Jiawei Ren, Yanping Xie, Juan-Manuel Perez-Rua, Bodo Rosenhahn, Tao Xiang, and Sen He. Flatten: optical flow- guided attention for consistent text-to-video editing.arXiv preprint arXiv:2310.05922, 2023. 2
arXiv 2023
-
[7]
Structure and content-guided video synthesis with diffusion models
Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7346–7356, 2023. 2
2023
-
[8]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[9]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 2
2021
-
[10]
Vq-hps: Hu- man pose and shape estimation in a vector-quantized latent space
Gu ´enol´e Fiche, Simon Leglaive, Xavier Alameda-Pineda, Antonio Agudo, and Francesc Moreno-Noguer. Vq-hps: Hu- man pose and shape estimation in a vector-quantized latent space. InEuropean Conference on Computer Vision, pages 471–490. Springer, 2024. 2, 4, 5, 8
2024
-
[11]
Xiao Fu, Xian Liu, Xintao Wang, Sida Peng, Menghan Xia, Xiaoyu Shi, Ziyang Yuan, Pengfei Wan, Di Zhang, and Dahua Lin. 3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation.arXiv preprint arXiv:2412.07759, 2024. 3
arXiv 2024
-
[12]
Qijun Gan, Yi Ren, Chen Zhang, Zhenhui Ye, Pan Xie, Xiang Yin, Zehuan Yuan, Bingyue Peng, and Jianke Zhu. Humandit: Pose-guided diffusion transformer for long- form human motion video generation.arXiv preprint arXiv:2502.04847, 2025. 2, 3
arXiv 2025
-
[13]
Humans in 4d: Re- constructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Re- constructing and tracking humans with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023. 2
2023
-
[14]
Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–12, 2025. 3
2025
-
[15]
Animate anyone: Consistent and controllable image- to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image- to-video synthesis for character animation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8153–8163, 2024. 1, 2, 6
2024
-
[16]
Li Hu, Guangyuan Wang, Zhen Shen, Xin Gao, Dechao Meng, Lian Zhuo, Peng Zhang, Bang Zhang, and Liefeng Bo. Animate anyone 2: High-fidelity character image animation with environment affordance.arXiv preprint arXiv:2502.06145, 2025. 1, 2
arXiv 2025
-
[17]
Siqiao Huang, Jialong Wu, Qixing Zhou, Shangchen Miao, and Mingsheng Long. Vid2world: Crafting video diffu- sion models to interactive world models.arXiv preprint arXiv:2505.14357, 2025. 1
arXiv 2025
-
[18]
Tianyu Huang, Wangguandong Zheng, Tengfei Wang, Yuhao Liu, Zhenwei Wang, Junta Wu, Jie Jiang, Hui Li, Ryn- son WH Lau, Wangmeng Zuo, et al. V oyager: Long-range and world-consistent video diffusion for explorable 3d scene generation.arXiv preprint arXiv:2506.04225, 2025. 3
arXiv 2025
-
[19]
VBench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Com- prehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Reco...
2024
-
[20]
Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025. 1, 2
Pith/arXiv arXiv 2025
-
[21]
Movideo: Motion-aware video generation with diffusion model
Jingyun Liang, Yuchen Fan, Kai Zhang, Radu Timofte, Luc Van Gool, and Rakesh Ranjan. Movideo: Motion-aware video generation with diffusion model. InEuropean Con- ference on Computer Vision, pages 56–74. Springer, 2024. 2
2024
-
[22]
Jingyun Liang, Jingkai Zhou, Shikai Li, Chenjie Cao, Lei Sun, Yichen Qian, Weihua Chen, and Fan Wang. Realismo- tion: Decomposed human motion control and video gener- ation in the world space.arXiv preprint arXiv:2508.08588,
-
[23]
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, and Chao Liang. Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models.arXiv preprint arXiv:2502.01061, 2025. 2 9
arXiv 2025
-
[24]
Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 5
Pith/arXiv arXiv 2022
-
[25]
Llava-next: Im- proved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, January 2024. 5
2024
-
[26]
Smpl: A skinned multi- person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. ACM, 2023. 1, 2, 3
2023
-
[27]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5
Pith/arXiv arXiv 2017
-
[28]
Yifang Men, Yuan Yao, Miaomiao Cui, and Liefeng Bo. Mimo: Controllable character video synthesis with spatial decomposed modeling.arXiv preprint arXiv:2409.16160,
-
[29]
Dreamdance: Animating human images by enriching 3d geometry cues from 2d poses
Yatian Pang, Bin Zhu, Bin Lin, Mingzhe Zheng, Francis EH Tay, Ser-Nam Lim, Harry Yang, and Li Yuan. Dreamdance: Animating human images by enriching 3d geometry cues from 2d poses. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 14039–14050,
-
[30]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019. 2
2019
-
[31]
Bohao Peng, Jian Wang, Yuechen Zhang, Wenbo Li, Ming- Chang Yang, and Jiaya Jia. Controlnext: Powerful and effi- cient control for image and video generation.arXiv preprint arXiv:2408.06070, 2024. 2, 6
arXiv 2024
-
[32]
Gen3c: 3d-informed world-consistent video generation with precise camera con- trol
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas M ¨uller, Alexan- der Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera con- trol. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6121–6132, 2025. 3
2025
-
[33]
Avid: Adapting video diffusion models to world models
Marc Rigter, Tarun Gupta, Agrin Hilmkil, and Chao Ma. Avid: Adapting video diffusion models to world models. arXiv preprint arXiv:2410.12822, 2024. 1
arXiv 2024
-
[34]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 3
2022
-
[35]
Worldexplorer: Towards generating fully naviga- ble 3d scenes.arXiv preprint arXiv:2506.01799, 2025
Manuel-Andreas Schneider, Lukas H ¨ollein, and Matthias Nießner. Worldexplorer: Towards generating fully naviga- ble 3d scenes.arXiv preprint arXiv:2506.01799, 2025. 3
arXiv 2025
-
[36]
World-grounded human motion recovery via gravity-view coordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view coordinates. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 2, 5
2024
-
[37]
Wham: Reconstructing world-grounded humans with accu- rate 3d motion
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J Black. Wham: Reconstructing world-grounded humans with accu- rate 3d motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2070– 2080, 2024. 2
2070
-
[38]
Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 5
Pith/arXiv arXiv 2010
-
[39]
Shuai Tan, Biao Gong, Zhuoxin Liu, Yan Wang, Xi Chen, Yifan Feng, and Hengshuang Zhao. Animate-x++: Universal character image animation with dynamic backgrounds.arXiv preprint arXiv:2508.09454, 2025. 3
arXiv 2025
-
[40]
Shuai Tan, Biao Gong, Xiang Wang, Shiwei Zhang, Dandan Zheng, Ruobing Zheng, Kecheng Zheng, Jingdong Chen, and Ming Yang. Animate-x: Universal character image ani- mation with enhanced motion representation.arXiv preprint arXiv:2410.10306, 2024. 2, 6
arXiv 2024
-
[41]
Musepose: a pose-driven image-to-video framework for virtual human generation, 2024
Zhengyan Tong, Chao Li, Zhaokang Chen, Bin Wu, and Wenjiang Zhou. Musepose: a pose-driven image-to-video framework for virtual human generation, 2024. 2, 6
2024
-
[42]
Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017. 4
2017
-
[43]
Attention is all you need.arXiv preprint arXiv:1706.03762, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Il- lia Polosukhin. Attention is all you need.arXiv preprint arXiv:1706.03762, 2017. 2
Pith/arXiv arXiv 2017
-
[44]
Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 1, 2, 3, 4, 5, 6, 7
Pith/arXiv arXiv 2025
-
[45]
Humandreamer: Generating controllable human-motion videos via decoupled generation
Boyuan Wang, Xiaofeng Wang, Chaojun Ni, Guosheng Zhao, Zhiqin Yang, Zheng Zhu, Muyang Zhang, Yukun Zhou, Xinze Chen, Guan Huang, et al. Humandreamer: Generating controllable human-motion videos via decoupled generation. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 12391–12401, 2025. 2
2025
-
[46]
Vividpose: Advancing stable video diffusion for realistic human image animation
Qilin Wang, Zhengkai Jiang, Chengming Xu, Jiangning Zhang, Yabiao Wang, Xinyi Zhang, Yun Cao, Weijian Cao, Chengjie Wang, and Yanwei Fu. Vividpose: Advancing stable video diffusion for realistic human image animation. arXiv preprint arXiv:2405.18156, 2024. 2
arXiv 2024
-
[47]
Cinemaster: A 3d-aware and controllable frame- work for cinematic text-to-video generation
Qinghe Wang, Yawen Luo, Xiaoyu Shi, Xu Jia, Huchuan Lu, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. Cinemaster: A 3d-aware and controllable frame- work for cinematic text-to-video generation. InProceedings of the Special Interest Group on Computer Graphics and In- teractive Techniques Conference Conference Papers, pages 1–10, 2025. 3
2025
-
[48]
Tan Wang, Linjie Li, Kevin Lin, Chung-Ching Lin, Zhengyuan Yang, Hanwang Zhang, Zicheng Liu, and Li- juan Wang. Disco: Disentangled control for referring human dance generation in real world.arXiv preprint arXiv:2307.00040, 2(3):4, 2023. 2
arXiv 2023
-
[49]
Xiang Wang, Shiwei Zhang, Longxiang Tang, Yingya Zhang, Changxin Gao, Yuehuan Wang, and Nong 10 Sang. Unianimate-dit: Human image animation with large-scale video diffusion transformer.arXiv preprint arXiv:2504.11289, 2025. 2, 3
arXiv 2025
-
[50]
Rethink sparse signals for pose-guided text-to-image generation
Wenjie Xuan, Jing Zhang, Juhua Liu, Bo Du, and Dacheng Tao. Rethink sparse signals for pose-guided text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15896–15906, 2025. 2
2025
-
[51]
Motion-conditioned image animation for video editing.arXiv preprint arXiv:2311.18827, 2023
Wilson Yan, Andrew Brown, Pieter Abbeel, Rohit Girdhar, and Samaneh Azadi. Motion-conditioned image animation for video editing.arXiv preprint arXiv:2311.18827, 2023. 2
arXiv 2023
-
[52]
Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, and Fangyuan Zou. Mim- icmotion: High-quality human motion video generation with confidence-aware pose guidance.arXiv preprint arXiv:2406.19680, 2024. 2, 6
arXiv 2024
-
[53]
Zhenghao Zhang, Junchao Liao, Menghao Li, Zuozhuo Dai, Bingxue Qiu, Siyu Zhu, Long Qin, and Weizhi Wang. Tora: Trajectory-oriented diffusion transformer for video genera- tion.arXiv preprint arXiv:2407.21705, 2024. 6
arXiv 2024
-
[54]
Jingkai Zhou, Benzhi Wang, Weihua Chen, Jingqi Bai, Dongyang Li, Aixi Zhang, Hao Xu, Mingyang Yang, and Fan Wang. Realisdance: Equip controllable character anima- tion with realistic hands.arXiv preprint arXiv:2409.06202,
-
[55]
Jingkai Zhou, Yifan Wu, Shikai Li, Min Wei, Chao Fan, Wei- hua Chen, Wei Jiang, and Fan Wang. Realisdance-dit: Sim- ple yet strong baseline towards controllable character anima- tion in the wild.arXiv preprint arXiv:2504.14977, 2025. 2, 3, 5, 6, 7
arXiv 2025
-
[56]
Fully convolutional mesh autoencoder using efficient spatially varying kernels.Ad- vances in neural information processing systems, 33:9251– 9262, 2020
Yi Zhou, Chenglei Wu, Zimo Li, Chen Cao, Yuting Ye, Jason Saragih, Hao Li, and Yaser Sheikh. Fully convolutional mesh autoencoder using efficient spatially varying kernels.Ad- vances in neural information processing systems, 33:9251– 9262, 2020. 4, 5
2020
-
[57]
Champ: Controllable and consistent human image an- imation with 3d parametric guidance
Shenhao Zhu, Junming Leo Chen, Zuozhuo Dai, Zilong Dong, Yinghui Xu, Xun Cao, Yao Yao, Hao Zhu, and Siyu Zhu. Champ: Controllable and consistent human image an- imation with 3d parametric guidance. InEuropean Confer- ence on Computer Vision, pages 145–162. Springer, 2024. 2 11
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.