SkillGuard: A Permission Framework for Agent Skills
Pith reviewed 2026-06-28 10:05 UTC · model grok-4.3
The pith
SkillGuard connects a skill's declared intent to its runtime behavior through a dual-plane permission model to limit injection attacks in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
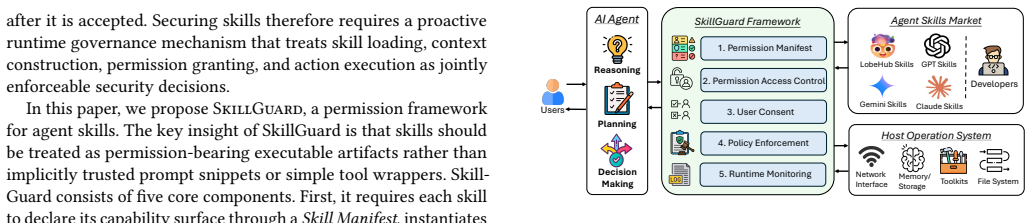
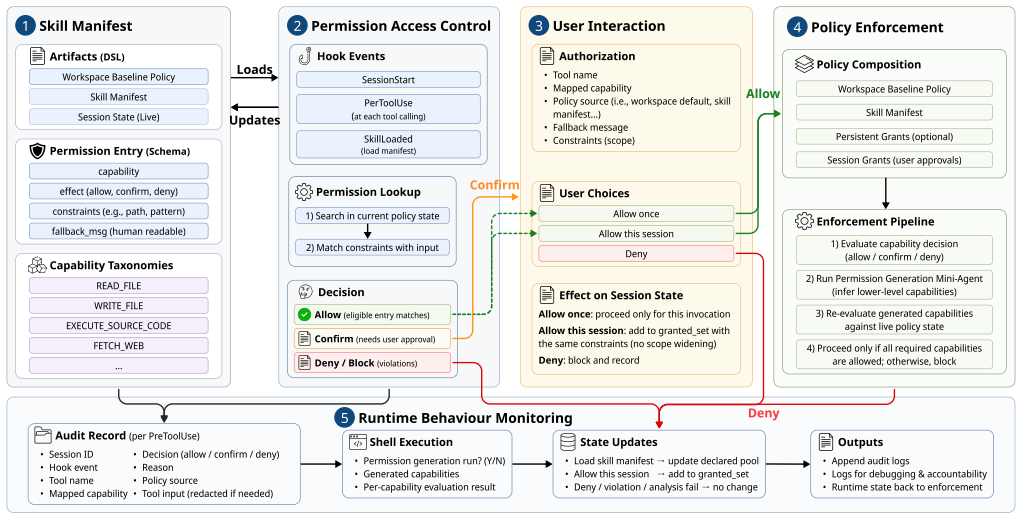
SkillGuard treats skills as permission-bearing executable artifacts and introduces a dual-plane governance model that jointly regulates context influence and action side effects through skill manifests, runtime access control, user-mediated authorization, deny-by-default enforcement, capability inference, and behavior monitoring.
What carries the argument
dual-plane governance model that jointly regulates context influence and action side effects
If this is right
- Skill ecosystems can shift from trust-based loading to manifest-enforced permissions at the skill level.
- Automated manifest generation can reliably describe capabilities for the majority of observed skills.
- Contextual injection attacks can be reduced without degrading performance on standard agent tasks.
- Runtime monitoring combined with deny-by-default can catch side effects that static inspection misses.
Where Pith is reading between the lines
- Similar permission layers could apply to tool-calling agents that lack explicit skill manifests.
- Skill marketplaces might adopt manifest standards to reduce liability from injection incidents.
- Long-term monitoring data could surface usage patterns that refine the taxonomy over time.
Load-bearing premise
The dual-plane governance model successfully connects a skill's declared intent with its actual runtime behavior across diverse real-world skills.
What would settle it
In an expanded set of skills or new injection attacks, the permission taxonomy covers substantially fewer than 99 percent of protected objects or SkillGuard fails to lower attack success rates below the reported baselines.
Figures



read the original abstract
Agent skills extend LLM agents with reusable instructions, scripts, tool bindings, and contextual dependencies. However, current skill ecosystems largely rely on trust-based loading and static inspection, leaving a gap between what a skill can inject into an agent's context and what it can cause the agent to do at runtime. This gap introduces new security and privacy risks, and existing defenses primarily inspect skill files statically or regulate individual tool calls, without systematically connecting a skill's declared intent with its runtime behavior. In this paper, we present SkillGuard, a skill-centric permission framework that treats skills as permission-bearing executable artifacts. SkillGuard introduces a dual-plane governance model that jointly regulates context influence and action side effects through skill manifests, runtime access control, user-mediated authorization, deny-by-default enforcement, capability inference, and behavior monitoring. We evaluate SkillGuard on 315 real-world skills and SkillInject. The permission taxonomy covers 99.76% of observed protected objects, and automated manifest generation reaches 91.0% F1. In adversarial evaluations, SkillGuard reduces attack success from 32.37% to 23.02% for contextual injections and from 25.56% to 16.67% for obvious injections, while maintaining benign task utility. These results suggest that SkillGuard, as a skill-centric permission framework, can provide a practical foundation for improving the privacy and security of agent skill ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillGuard, a skill-centric permission framework for LLM agent skills that employs a dual-plane governance model to jointly regulate context influence and runtime action side effects. The model incorporates skill manifests, runtime access control, user-mediated authorization, deny-by-default enforcement, capability inference, and behavior monitoring. Evaluation on 315 real-world skills and the SkillInject adversarial test suite reports 99.76% coverage of the permission taxonomy over observed protected objects, 91.0% F1 for automated manifest generation, and reductions in attack success rate from 32.37% to 23.02% (contextual injections) and 25.56% to 16.67% (obvious injections) while preserving benign task utility.
Significance. If the dual-plane model and evaluation results hold under scrutiny, the work provides a concrete, skill-centric approach to closing the gap between static skill inspection and runtime behavior in agent ecosystems. The quantitative results on real-world skills and adversarial tests, combined with the explicit taxonomy and manifest-generation pipeline, offer a practical foundation that could inform permission systems beyond the current trust-based or tool-call-only defenses.
major comments (2)
- [Evaluation] Evaluation section: the methodology for constructing the 315-skill corpus, selecting protected objects, and defining the SkillInject attack suite is not described in sufficient detail (e.g., sampling criteria, inter-rater agreement on taxonomy labels, or statistical power of the reported attack-success deltas) to verify that the threat landscape and usage patterns are representative; these details are load-bearing for the claim that SkillGuard supplies a practical foundation.
- [§3] §3 (Dual-plane governance model): the description of capability inference and behavior monitoring does not include a concrete mapping or worked example showing how a skill's declared manifest intent is enforced against its actual runtime context-injection and tool-call side effects; without this, the central claim that the model successfully bridges declared intent and runtime behavior remains difficult to assess.
minor comments (2)
- The abstract and evaluation tables would benefit from explicit reporting of confidence intervals or standard errors on the F1 and attack-success figures.
- Notation for the permission taxonomy (e.g., how protected objects are enumerated) should be introduced earlier and used consistently in the evaluation tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments on our manuscript. We address each major comment point-by-point below. We agree that additional methodological details and a worked example will improve clarity and will incorporate them in the revised version.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the methodology for constructing the 315-skill corpus, selecting protected objects, and defining the SkillInject attack suite is not described in sufficient detail (e.g., sampling criteria, inter-rater agreement on taxonomy labels, or statistical power of the reported attack-success deltas) to verify that the threat landscape and usage patterns are representative; these details are load-bearing for the claim that SkillGuard supplies a practical foundation.
Authors: We agree that the Evaluation section lacks sufficient detail on corpus construction and evaluation methodology. In the revised manuscript, we will expand this section to specify: (1) sampling criteria for the 315 skills (drawn from public repositories with stratification across domains such as productivity, finance, and social media); (2) the process for selecting protected objects and taxonomy labeling, including inter-rater agreement (e.g., Cohen's kappa scores from multiple annotators); and (3) statistical analysis of the attack-success deltas, including confidence intervals and power calculations to support the observed reductions. These additions will better demonstrate representativeness without altering the reported results. revision: yes
-
Referee: [§3] §3 (Dual-plane governance model): the description of capability inference and behavior monitoring does not include a concrete mapping or worked example showing how a skill's declared manifest intent is enforced against its actual runtime context-injection and tool-call side effects; without this, the central claim that the model successfully bridges declared intent and runtime behavior remains difficult to assess.
Authors: We acknowledge that a concrete worked example would make the enforcement mechanism clearer. In the revised §3, we will add a detailed worked example for a representative skill (e.g., a calendar integration skill). This will include: the declared manifest intent, the capability inference step mapping it to permission planes, runtime context-injection detection, tool-call side-effect monitoring, and the exact deny-by-default enforcement actions taken. The example will explicitly trace how declared intent is checked against observed runtime behavior. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces SkillGuard as a new permission framework and reports direct empirical evaluations on 315 external real-world skills plus SkillInject adversarial tests. Metrics (99.76% taxonomy coverage, 91.0% manifest F1, attack-success reductions) are measured outcomes on independent data, not quantities defined by or fitted from the framework itself. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided claims or abstract. The derivation chain consists of design description followed by external validation and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Skills can be represented with manifests that declare intent sufficiently to enable runtime governance
invented entities (1)
-
Dual-plane governance model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agent Skills Marketplace
2026. Agent Skills Marketplace. https://skillsmp.com/
2026
-
[2]
The Artifacts of SkillGuard
2026. The Artifacts of SkillGuard. https://github .com/Dianshu-Liao/SkilLGuard
2026
-
[3]
Amirhossein Abaskohi, Amrutha Varshini Ramesh, Shailesh Nanisetty, Chirag Goel, David Vazquez, Christopher Pal, Spandana Gella, Giuseppe Carenini, and Issam H Laradji. 2025. AgentAda: Skill-Adaptive Data Analytics for Tailored Insight Discovery.arXiv preprint arXiv:2504.07421(2025)
-
[4]
Anthropic. 2025. Claude Sonnet 4.6. https://www .anthropic.com/claude/sonnet
2025
-
[5]
Anthropic. 2025. What is the Model Context Protocol (MCP)? https:// modelcontextprotocol.io/docs/getting-started/intro
2025
-
[6]
Anthropic. 2026. Claude Code Docs. https://code .claude.com/docs/en/overview
2026
-
[7]
Bhavyansh. 2026. MCP vs Agent Skills: Which AI Architecture Pattern to Use . https://bhavyansh001 .medium.com/mcp-vs-agent-skills-which-ai- architecture-pattern-to-use-mcp-deepdive-03-6a42185d9e7b
2026
-
[8]
Christoph Bühler, Matteo Biagiola, Luca Di Grazia, and Guido Salvaneschi. 2026. AgentBound: Securing Execution Boundaries of AI Agents. InProceedings of the 34th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (FSE)(Montreal, Canada, 2026-07) (2026, Vol. 3). ACM, New York, NY, USA, Article FSE096...
-
[9]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi’c, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents.ArXivabs/2406.13352 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. More than you’ve asked for: A Comprehensive Analysis of Novel Prompt Injection Threats to Application-Integrated Large Language Models.ArXivabs/2302.12173 (2023). https://api .semanticscholar.org/ CorpusID:257102404
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real- World LLM-Integrated Applications with Indirect Prompt Injection.Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security(2023). https: //api.semanticscholar.org/CorpusID:258546941
2023
- [12]
-
[13]
Yinghan Hou and Zongyou Yang. 2026. Skillsieve: A hierarchical triage framework for detecting malicious ai agent skills.arXiv preprint arXiv:2604.06550(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Xiaojun Jia, Jie Liao, Simeng Qin, Jindong Gu, Wenqi Ren, Xiaochun Cao, Yang Liu, and Philip Torr. 2026. Skillject: Automating stealthy skill-based prompt injection for coding agents with trace-driven closed-loop refinement. InThe 6th Workshop of Adversarial Machine Learning on Computer Vision: Safety of Vision-Language Agents
2026
-
[15]
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guang- sheng Yu. 2026. SoK: Agentic Skills–Beyond Tool Use in LLM Agents.arXiv preprint arXiv:2602.20867(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
J Richard Landis and Gary G. Koch. 1977. An application of hierarchical kappa- type statistics in the assessment of majority agreement among multiple observers. Biometrics33 2 (1977), 363–74
1977
-
[17]
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. 2026. SkillsBench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [18]
-
[19]
Pei Liu, Li Li, Yanjie Zhao, Xiaoyu Sun, and John Grundy. 2020. Androzooopen: Collecting large-scale open source android apps for the research community. In Proceedings of the 17th International Conference on Mining Software Repositories. 548–552
2020
-
[20]
Yi Liu, Zhihao Chen, Yanjun Zhang, Gelei Deng, Yuekang Li, Jianting Ning, Ying Zhang, and Leo Yu Zhang. 2026. Malicious agent skills in the wild: A large-scale security empirical study.arXiv preprint arXiv:2602.06547(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Eugene Neelou, Ivan Novikov, Max Moroz, Om Narayan, Tiffany Saade, Mika Ayenson, Ilya Kabanov, Jen Ozmen, Edward Lee, Vineeth Sai Narajala, et al
- [22]
-
[23]
Linyue Pan, Lexiao Zou, Shuo Guo, Jingchen Ni, and Hai-Tao Zheng. 2026. Natural-language agent harnesses.arXiv preprint arXiv:2603.25723(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Yubin Qu, Yi Liu, Tongcheng Geng, Gelei Deng, Yuekang Li, Leo Yu Zhang, Ying Zhang, and Lei Ma. 2026. Supply-Chain Poisoning Attacks Against LLM Coding Agent Skill Ecosystems
2026
- [25]
-
[26]
Jerome H Saltzer and Michael D Schroeder. 1975. The protection of information in computer systems.Proc. IEEE63, 9 (1975), 1278–1308
1975
-
[28]
David Schmotz, Luca Beurer-Kellner, Sahar Abdelnabi, and Maksym An- driushchenko. 2026. Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks.ArXivabs/2602.20156 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Abdullah AL Mamun, Yu Fu, Pedram Zaree, Yue Dong, and Nael B
Erfan Shayegani, Md. Abdullah AL Mamun, Yu Fu, Pedram Zaree, Yue Dong, and Nael B. Abu-Ghazaleh. 2023. Survey of Vulnerabilities in Large Language 11 Models Revealed by Adversarial Attacks.ArXivabs/2310.10844 (2023). https: //api.semanticscholar.org/CorpusID:264172191
-
[30]
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. 2025. Progent: Programmable privilege control for llm agents. arXiv preprint arXiv:2504.11703(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
SkillsMP. 2026. SkillsMP: A Marketplace for Agent Skills. https://skillsmp .com/. Accessed: 2026-06-01
2026
-
[32]
Xiaoyu Sun, Xiao Chen, Li Li, Haipeng Cai, John Grundy, Jordan Samhi, Tegawendé Bissyandé, and Jacques Klein. 2023. Demystifying hidden sensi- tive operations in android apps.ACM Transactions on Software Engineering and Methodology32, 2 (2023), 1–30
2023
-
[33]
Guiyao Tie, Jiawen Shi, Pan Zhou, and Lichao Sun. 2026. Badskill: Backdoor at- tacks on agent skills via model-in-skill poisoning.arXiv preprint arXiv:2604.09378 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [34]
-
[35]
Qingtian Wang. 2025. The Comprehensive Review on Prompt Injection At- tacks and Defense Mechanisms in Large Language Models.Science and Tech- nology of Engineering, Chemistry and Environmental Protection(2025). https: //api.semanticscholar.org/CorpusID:279511010
2025
-
[36]
Xiaomi MiMo Team. 2025. MiMo-V2.5-Pro. https://mimo .xiaomi.com/mimo-v2- 5-pro
2025
-
[37]
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, et al . 2026. Ex- ternalization in llm agents: A unified review of memory, skills, protocols and harness engineering.arXiv preprint arXiv:2604.08224(2026). 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.