How Visible Are Silent Manipulation Failures? An Observability Study of False-Success Detection in Simulated Robot Episodes
Pith reviewed 2026-06-28 10:14 UTC · model grok-4.3
The pith
False successes in robot manipulation are largely detectable from joint data in cube transfer but require vision to recover in peg insertion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
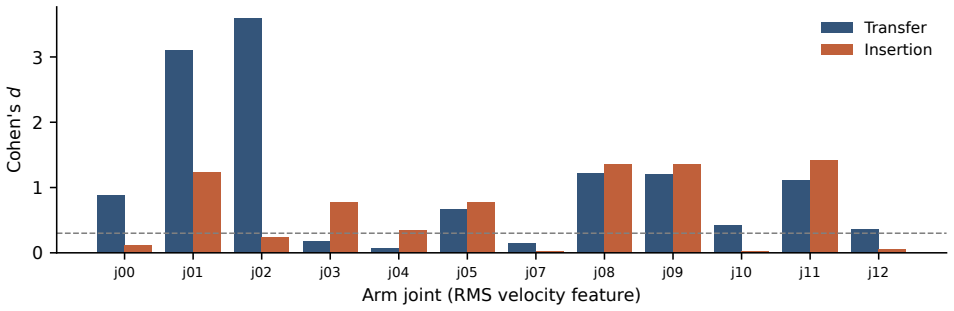
In cube transfer the false successes are almost fully recoverable from joint data alone, while in peg insertion proprioception recovers only part of them and a vision detector closes most of the gap. The proprioceptive separability rests on velocity differences far below any realistic sensor noise floor, so it is best read as an optimistic upper bound that a noiseless simulator inflates.
What carries the argument
Comparison of proprioceptive-only detectors against a vision-based detector, evaluated only on episodes the robot itself flagged as successful but that privileged simulator state shows were failures.
If this is right
- Imitation-learning pipelines for cube-transfer tasks can improve label quality using only existing joint sensors.
- Peg-insertion policies will need an added vision check to catch most false successes that proprioception misses.
- Any claim of proprioceptive false-success detection must be discounted by the gap between simulated velocities and real sensor noise.
- Task choice affects how much an external success verifier can be replaced by internal signals.
Where Pith is reading between the lines
- Sensor selection for new manipulation tasks could be guided by running similar simulated observability checks before hardware deployment.
- The gap between simulation and reality may be larger for velocity-based detection than for position-based checks.
- Extending the study to additional tasks would show whether cube transfer and peg insertion represent extremes or a spectrum of recoverability.
Load-bearing premise
That the simulator's noiseless proprioceptive velocities at the scale used for separation are representative of what a real robot could observe.
What would settle it
Running the same false-success episodes on a physical robot, adding measured sensor noise to the joint velocities, and checking whether the proprioceptive detector's separation accuracy collapses.
Figures


read the original abstract
Imitation-learning policies for robot manipulation inherit the quality of the success labels attached to their training episodes, and those labels are usually produced by the robot's own success check. A particularly damaging error is the false success: an episode the robot logs as a success when the task outcome was actually wrong. We ask a narrow but practical question about these episodes. Once an episode has already been flagged as a success, how much of the information needed to overturn that label is present in proprioception, and how much requires vision? We build a simulated testbed on two bimanual ALOHA tasks, induce failures through environment perturbations rather than label edits, label every episode by privileged simulator state that the detector never sees, and keep only episodes the robot flagged as successful. We then compare detectors restricted to proprioception against a vision-based detector. We find that recoverability spans a wide range: in cube transfer the false successes are almost fully recoverable from joint data alone, while in peg insertion proprioception recovers only part of them and a vision detector closes most of the gap. We also show that the proprioceptive separability we measure rests on velocity differences far below any realistic sensor noise floor, so it is best read as an optimistic upper bound that a noiseless simulator inflates. We release the generation and evaluation pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that false-success episodes in simulated bimanual robot manipulation (cube transfer and peg insertion) exhibit task-dependent recoverability from proprioception alone versus vision: nearly complete from joint data in cube transfer, but only partial in peg insertion where a vision detector closes most of the remaining gap. The proprioceptive separability is shown to rest on velocity differences below realistic sensor noise, and the results are explicitly scoped as an optimistic upper bound from noiseless simulation; the generation/evaluation pipeline is released.
Significance. If the scoped simulation results hold, the work supplies a concrete empirical characterization of information availability for overturning false success labels, which can inform detector design choices in imitation-learning pipelines. The explicit acknowledgment of the simulation-to-reality gap on sensor noise and the release of the pipeline are strengths that support reproducibility and prevent overgeneralization.
minor comments (2)
- [Abstract] Abstract: the qualitative phrases 'almost fully recoverable' and 'closes most of the gap' would be strengthened by reporting the corresponding quantitative detector metrics (accuracy, AUC, or F1) so readers can gauge effect sizes directly.
- [Experimental design] Experimental design section: while the perturbation-induced failure protocol is clearly motivated, a short table or sentence listing the specific perturbation magnitudes and their relation to the robot's success-check logic would help readers verify that the induced failures are non-trivial.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the work, for highlighting its significance in characterizing information availability for false-success detection, and for recommending minor revision. We appreciate the explicit recognition of the simulation scoping, noise discussion, and pipeline release as strengths.
Circularity Check
No significant circularity
full rationale
The paper reports an empirical comparison of proprioceptive vs. vision-based detectors on held-out simulated episodes, with labels from privileged simulator state. No derivation, equation, or prediction is defined in terms of a fitted parameter that is then re-used as output; the central claims rest on direct performance measurements rather than any self-referential construction. Self-citations are absent from the load-bearing steps, and the work explicitly flags its own optimistic simulation assumptions instead of smuggling them in as results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Simulator privileged state supplies accurate success/failure labels that the detector never sees
- domain assumption Environment perturbations induce failures whose signatures are observable in the chosen sensor streams
Reference graph
Works this paper leans on
-
[1]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, “Open X-Embodiment: Robotic learning datasets and RT-X models,”arXiv:2310.08864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
BridgeData V2: A dataset for robot learning at scale,
H. Walkeet al., “BridgeData V2: A dataset for robot learning at scale,” inProc. CoRL, 2023
2023
-
[3]
DROID: A large-scale in-the-wild robot manipu- lation dataset,
A. Khazatskyet al., “DROID: A large-scale in-the-wild robot manipu- lation dataset,” inProc. RSS, 2024
2024
-
[4]
LeRobot: An open-source library for end-to-end robot learning,
R. Cadene, S. Alibert, F. Capuano, M. Aractingi, A. Zouitine, P. Kooij- mans, J. Choghari, M. Russi, C. Pascal, S. Palma, M. Shukor, J. Moss, A. Soare, D. Aubakirova, Q. Lhoest, Q. Gallou´edec, and T. Wolf, “LeRobot: An open-source library for end-to-end robot learning,” inProc. Int. Conf. on Learning Representations (ICLR), 2026. arXiv:2602.22818
-
[5]
A multimodal anomaly detector for robot-assisted feeding using an LSTM-based variational autoencoder,
D. Park, Y . Hoshi, and C. C. Kemp, “A multimodal anomaly detector for robot-assisted feeding using an LSTM-based variational autoencoder,” IEEE RA-L, vol. 3, no. 3, pp. 1544–1551, 2018
2018
-
[6]
FINO-Net: A deep multimodal sensor fusion framework for manipulation failure detection,
A. Inceogluet al., “FINO-Net: A deep multimodal sensor fusion framework for manipulation failure detection,” inProc. IEEE/RSJ IROS, 2021
2021
-
[7]
arXiv preprint arXiv:2303.07280 , year=
Y . Duet al., “Vision-language models as success detectors,” arXiv:2303.07280, 2023
-
[8]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inProc. RSS, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.