An Asymptotic Theory of Chain-of-Thought in In-Context Learning
Pith reviewed 2026-06-28 08:23 UTC · model grok-4.3
The pith
In a linear regression model of in-context learning, random matrix theory yields an exact formula for generalization error as a function of chain-of-thought depth, pretraining data, and context length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
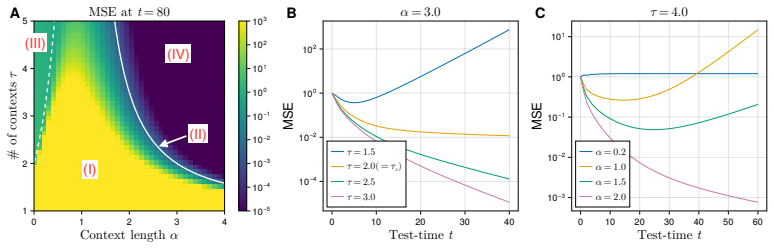
In the solvable model of in-context weight prediction for linear regression, where test-time chain-of-thought appears as iterative refinement of the weight-parameter estimate, high-dimensional random matrix theory produces an exact formula for generalization error in terms of reasoning depth, pretraining data amount, and context length. The formula locates a sharp phase transition separating exponential from polynomial improvement with depth, together with saturation and overthinking regimes, and shows that deeper reasoning is beneficial only when pretraining and in-context information are sufficiently rich; otherwise longer chains amplify errors or plateau. The same predictions are recovere
What carries the argument
Iterative refinement of the weight-parameter estimate, used as the explicit representation of chain-of-thought reasoning inside the linear regression model.
If this is right
- There exists a sharp phase transition that separates exponential improvement, polynomial improvement, saturation, and overthinking as reasoning depth grows.
- The optimal reasoning depth scales explicitly with the amount of pretraining data and the length of the context.
- Deeper reasoning improves generalization most when pretraining data and context are rich; otherwise additional steps produce error amplification or saturation.
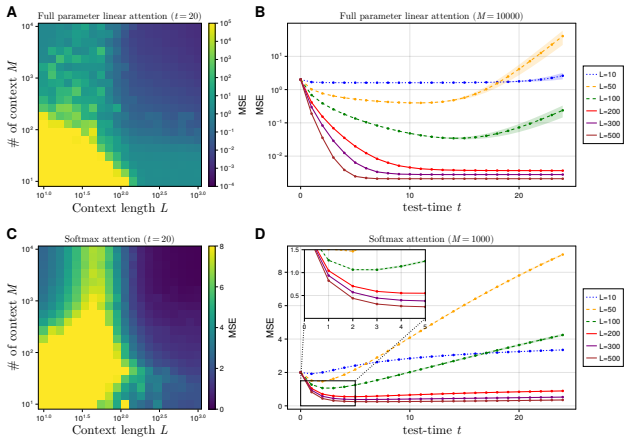
- The same phase-transition structure appears in numerical experiments on both linear attention and softmax attention models.
Where Pith is reading between the lines
- The phase-transition structure could be tested by measuring error versus depth on actual transformer models trained on synthetic regression tasks that match the paper's setup.
- If the transition persists under mild nonlinearities, inference-time compute budgets might be allocated by first estimating data richness and then stopping at the predicted optimal depth.
- The exact formula supplies a concrete benchmark against which other asymptotic theories of in-context learning can be compared by varying the underlying regression assumptions.
Load-bearing premise
The iterative refinement of the weight-parameter estimate in linear regression is a faithful model of chain-of-thought reasoning performed by large language models.
What would settle it
Train a linear attention model on the same regression task, vary reasoning depth while holding pretraining data and context length fixed, and check whether the measured generalization error curve exhibits the predicted sharp phase transition and quantitative match to the exact formula.
Figures
read the original abstract
Chain-of-thought (CoT) reasoning has become a widely used mechanism for eliciting multi-step reasoning in large language models by generating intermediate reasoning steps at inference time. Yet the scaling behavior of generalization with CoT depth remains poorly understood. To address this question, we study a theoretically solvable model of CoT for in-context weight prediction in linear regression, where test-time reasoning is represented as an iterative refinement of the weight-parameter estimate. Using tools from random matrix theory under high-dimensional asymptotics, we derive an exact formula for the generalization error as a function of reasoning depth, pretraining data amount, and context length. Our analysis reveals a sharp phase transition separating exponential and polynomial improvement, saturation, and overthinking, and characterizes how the optimal reasoning depth scales. We further show that deeper reasoning is most effective with sufficiently rich pretraining and in-context information, whereas limited pretraining or context makes longer reasoning prone to error amplification or saturation. We also validate these predictions through experiments on fully learned linear attention and softmax attention models. Our results provide a unified theoretical account of how test-time CoT depth affects generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive, using random matrix theory under high-dimensional asymptotics, an exact formula for the generalization error of chain-of-thought reasoning in in-context learning for linear regression, where CoT depth is modeled as iterations refining the OLS weight estimate. The formula depends on reasoning depth, pretraining data amount, and context length, revealing a phase transition between exponential and polynomial improvement regimes, saturation, overthinking, and optimal depth scaling. Predictions are validated on learned linear and softmax attention models.
Significance. If the iterative linear regression model faithfully captures the effective computation in CoT for transformers, this work offers a rigorous asymptotic theory explaining scaling behaviors of generalization with CoT depth. The derivation of an exact formula via RMT is a notable strength, providing falsifiable predictions and a clean solvable model. However, the significance is limited by the centrality of the modeling assumption, which is not directly tested against real transformer mechanisms beyond the simplified dynamics.
major comments (3)
- [§2] §2 (Model): The iterative refinement of the OLS estimator is defined as the model for CoT reasoning. This choice is load-bearing for every subsequent result on phase transitions, optimal depth, and saturation, yet the manuscript provides no argument or evidence that the iteration reproduces the effective computation performed by attention layers on non-linear token representations.
- [§4] §4 (Main Results): The exact formula for generalization error is derived via RMT, but the abstract and visible claims do not list the full set of assumptions or show the derivation steps; without these it is impossible to confirm whether the formula is independent of post-hoc choices that could affect the reported phase-transition locations.
- [§5] §5 (Experiments): Validation is performed exclusively on linear and softmax attention models that implement the same iterative refinement dynamics; these experiments confirm consistency within the model but do not test whether the dynamics approximate CoT in actual large language models.
minor comments (1)
- [Abstract] The abstract could more explicitly state the modeling assumptions and the precise definition of the iterative refinement to allow readers to assess the scope of the claims without reading the full model section.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We respond to each major comment below, with clarifications on the scope of the work and indications of planned revisions.
read point-by-point responses
-
Referee: [§2] §2 (Model): The iterative refinement of the OLS estimator is defined as the model for CoT reasoning. This choice is load-bearing for every subsequent result on phase transitions, optimal depth, and saturation, yet the manuscript provides no argument or evidence that the iteration reproduces the effective computation performed by attention layers on non-linear token representations.
Authors: We agree that the iterative OLS refinement constitutes a central modeling assumption. The manuscript introduces this as a solvable proxy for studying the scaling of generalization error with CoT depth in linear in-context learning, chosen specifically to permit an exact RMT derivation. We will revise Section 2 to include additional discussion of the modeling rationale, its relation to iterative refinement in ICL, and explicit limitations with respect to non-linear token representations in full-scale transformers. revision: partial
-
Referee: [§4] §4 (Main Results): The exact formula for generalization error is derived via RMT, but the abstract and visible claims do not list the full set of assumptions or show the derivation steps; without these it is impossible to confirm whether the formula is independent of post-hoc choices that could affect the reported phase-transition locations.
Authors: We will revise the abstract and the opening of Section 4 to enumerate the principal assumptions (high-dimensional asymptotic regime, linear regression task, form of the iterative updates, and random matrix assumptions). We will also insert a concise outline of the main derivation steps in the main text while retaining full technical details in the appendix. These changes should make clear that the reported phase transitions follow directly from the asymptotic analysis without post-hoc adjustments. revision: yes
-
Referee: [§5] §5 (Experiments): Validation is performed exclusively on linear and softmax attention models that implement the same iterative refinement dynamics; these experiments confirm consistency within the model but do not test whether the dynamics approximate CoT in actual large language models.
Authors: The experiments are intended to confirm that the derived formula accurately describes the behavior of models that realize the assumed iterative dynamics, including trained linear and softmax attention. We will revise the experimental discussion and conclusion to state this scope more explicitly and to note that direct validation against CoT mechanisms in large language models lies outside the present theoretical study. revision: partial
Circularity Check
No significant circularity; derivation is self-contained within the posited linear model
full rationale
The paper explicitly constructs an exactly solvable proxy model in which CoT depth is defined as iterations of linear-regression weight refinement, then applies random-matrix asymptotics to obtain a closed-form generalization error. This modeling step is an assumption, not a derivation that reduces to its own inputs. The subsequent formulas for phase transitions, optimal depth, and saturation follow directly from the high-dimensional analysis of that dynamical system; they are not obtained by fitting parameters to the target quantities or by self-citation chains. Experiments on linear and softmax attention merely verify consistency inside the same simplified dynamics. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-dimensional asymptotics and random matrix theory yield an exact closed-form generalization error for the iterative linear estimator.
Reference graph
Works this paper leans on
-
[1]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/ forum?...
2022
-
[2]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neu- ral Information Processing Systems, volume 35, pages 22199–22213. Curran Associates, Inc., 2022. URL https://proceedings.neurips...
2022
-
[3]
Scaling LLM test- time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test- time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=4FWAwZtd2n
2025
-
[4]
Position: Will we run out of data? limits of llm scaling based on human-generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of llm scaling based on human-generated data. InForty-first International Conference on Machine Learning, 2024
2024
-
[5]
arXiv preprint arXiv:2405.21015 , year=
Ben Cottier, Robi Rahman, Loredana Fattorini, Nestor Maslej, Tamay Besiroglu, and David Owen. The rising costs of training frontier ai models.arXiv preprint arXiv:2405.21015, 2024. 10
-
[6]
Towards thinking-optimal scaling of test- time compute for LLM reasoning
Wenkai Yang, Shuming Ma, Yankai Lin, and Furu Wei. Towards thinking-optimal scaling of test- time compute for LLM reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=6ICFqmixlS
2025
-
[7]
Wu, Ilia Sucholutsky, Tania Lombrozo, and Thomas L
Ryan Liu, Jiayi Geng, Addison J. Wu, Ilia Sucholutsky, Tania Lombrozo, and Thomas L. Grif- fiths. Mind your step (by step): Chain-of-thought can reduce performance on tasks where think- ing makes humans worse, 2025. URLhttps://openreview.net/forum?id=rpbzBXdo4x
2025
-
[8]
Jianhao Huang, Zixuan Wang, and Jason D. Lee. Transformers learn to implement multi-step gradient descent with chain of thought. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=r3DF5sOo5B
2025
-
[9]
Understanding the role of training data in test-time scaling
Adel Javanmard, Baharan Mirzasoleiman, and Vahab Mirrokni. Understanding the role of training data in test-time scaling. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=Y9FfDNa2nJ
2026
-
[10]
Adel Javanmard, Baharan Mirzasoleiman, and Vahab Mirrokni. Theoretical perspectives on data quality and synergistic effects in pre- and post-training reasoning models, 2026. URL https://arxiv.org/abs/2603.01293
-
[11]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
2025
-
[12]
OpenAI o3 and o4-mini System Card, 2025
OpenAI. OpenAI o3 and o4-mini System Card, 2025. URLhttps://api.semanticscholar. org/CorpusID:277857808
2025
-
[13]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[14]
Scaling over scaling: Exploring test-time scaling plateau in large reasoning models, 2025
Jian Wang, Boyan Zhu, Chak Tou Leong, Yongqi Li, and Wenjie Li. Scaling over scaling: Exploring test-time scaling plateau in large reasoning models, 2025. URL https://arxiv. org/abs/2505.20522
-
[15]
Jinyan Su, Jennifer Healey, Preslav Nakov, and Claire Cardie. Between underthinking and overthinking: An empirical study of reasoning length and correctness in llms, 2025. URL https://arxiv.org/abs/2505.00127
-
[16]
Don’t overthink it
Michael Hassid, Gabriel Synnaeve, Yossi Adi, and Roy Schwartz. Don’t overthink it. preferring shorter thinking chains for improved LLM reasoning, 2026. URL https://openreview. net/forum?id=nhUlA8iMkD
2026
-
[17]
Indranil Halder and Cengiz Pehlevan. Demystifying llm-as-a-judge: Analytically tractable model for inference-time scaling.arXiv preprint arXiv:2512.19905, 2025
-
[18]
arXiv preprint arXiv:2502.17578 , year=
Rylan Schaeffer, Joshua Kazdan, John Hughes, Jordan Juravsky, Sara Price, Aengus Lynch, Erik Jones, Robert Kirk, Azalia Mirhoseini, and Sanmi Koyejo. How do large language monkeys get their power (laws)?arXiv preprint arXiv:2502.17578, 2025
-
[19]
Audrey Huang, Adam Block, Qinghua Liu, Nan Jiang, Akshay Krishnamurthy, and Dylan J Foster. Is best-of-n the best of them? coverage, scaling, and optimality in inference-time alignment.arXiv preprint arXiv:2503.21878, 2025
-
[20]
A simple model of inference scaling laws
Noam Levi. A simple model of inference scaling laws. InProceedings of the 42nd International Conference on Machine Learning, pages 33984–33998. ML Research Press, 2025
2025
-
[21]
Learning shrinks the hard tail: Training-dependent inference scaling in a solvable linear model
Noam Itzhak Levi. Learning shrinks the hard tail: Training-dependent inference scaling in a solvable linear model. InThe Fourteenth International Conference on Learning Representations,
-
[22]
URLhttps://openreview.net/forum?id=KUNywR7nQx. 11
-
[23]
What can transformers learn in-context? a case study of simple function classes
Shivam Garg, Dimitris Tsipras, Percy Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems,
-
[24]
URLhttps://openreview.net/forum?id=flNZJ2eOet
-
[25]
What learning algorithm is in-context learning? investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. InThe Eleventh Inter- national Conference on Learning Representations, 2023. URL https://openreview.net/ forum?id=0g0X4H8yN4I
2023
-
[26]
Transformers learn in-context by gradient descent
Johannes V on Oswald, Eyvind Niklasson, Ettore Randazzo, João Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InInternational Conference on Machine Learning, pages 35151–35174. PMLR, 2023
2023
-
[27]
Yedi Zhang, Aaditya K Singh, Peter E Latham, and Andrew Saxe. Training dynamics of in-context learning in linear attention.arXiv preprint arXiv:2501.16265, 2025
-
[28]
Asymp- totic theory of in-context learning by linear attention.Proceedings of the National Academy of Sciences, 122(28):e2502599122, 2025
Yue M Lu, Mary Letey, Jacob A Zavatone-Veth, Anindita Maiti, and Cengiz Pehlevan. Asymp- totic theory of in-context learning by linear attention.Proceedings of the National Academy of Sciences, 122(28):e2502599122, 2025
2025
-
[29]
Lu, and Cengiz Pehlevan
Mary Letey, Jacob A Zavatone-Veth, Yue M. Lu, and Cengiz Pehlevan. Pretrain–test task alignment governs generalization in in-context learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=KZLeg0MQ2r
2026
-
[30]
Differential learning kinetics govern the transition from memorization to generalization during in-context learning
Alex Nguyen and Gautam Reddy. Differential learning kinetics govern the transition from memorization to generalization during in-context learning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=INyi7qUdjZ
2025
-
[31]
Theory of scaling laws for in-context regression: Depth, width, context and time
Blake Bordelon, Mary Letey, and Cengiz Pehlevan. Theory of scaling laws for in-context regression: Depth, width, context and time. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=qA42mWsnbl
2026
-
[32]
Learning linear regression with low-rank tasks in-context
Kaito Takanami, Takashi Takahashi, and Yoshiyuki Kabashima. Learning linear regression with low-rank tasks in-context. InThe 29th International Conference on Artificial Intelligence and Statistics, 2026. URLhttps://openreview.net/forum?id=bkhqasdf2u
2026
-
[33]
Show your work: Scratchpads for intermediate computation with language models, 2022
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models, 2022. URLhttps://openreview.net/forum?id=iedYJm92o0a
2022
-
[34]
Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. InES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models, 2025. URL https://openreview.net/forum? id=D6o6Bwtq7h
2025
-
[35]
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y . Fu. Parcae: Scaling laws for stable looped language models, 2026. URL https://arxiv.org/abs/2604.12946
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers
Harsh Kohli, Srinivasan Parthasarathy, Huan Sun, and Yuekun Yao. Loop, think, & generalize: Implicit reasoning in recurrent-depth transformers, 2026. URL https://arxiv.org/abs/ 2604.07822
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Two-Point Deterministic Equivalence for Stochastic Gradient Dynamics in Linear Models
Alexander Atanasov, Blake Bordelon, Jacob A Zavatone-Veth, Courtney Paquette, and Cengiz Pehlevan. Two-point deterministic equivalence for stochastic gradient dynamics in linear models.arXiv [cond-mat.dis-nn], 10 November 2025. doi: 10.48550/arXiv.2502.05074. URL http://dx.doi.org/10.48550/arXiv.2502.05074. 12
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.05074 2025
-
[38]
Applications of realizations (aka lineariza- tions) to free probability.Journal of Functional Analysis, 274(1):1–79, 2018
J William Helton, Tobias Mai, and Roland Speicher. Applications of realizations (aka lineariza- tions) to free probability.Journal of Functional Analysis, 274(1):1–79, 2018
2018
-
[39]
Simplified derivations for high-dimensional convex learning problems.SciPost Physics Lecture Notes, page 105, 2025
David Clark and Haim Sompolinsky. Simplified derivations for high-dimensional convex learning problems.SciPost Physics Lecture Notes, page 105, 2025
2025
-
[40]
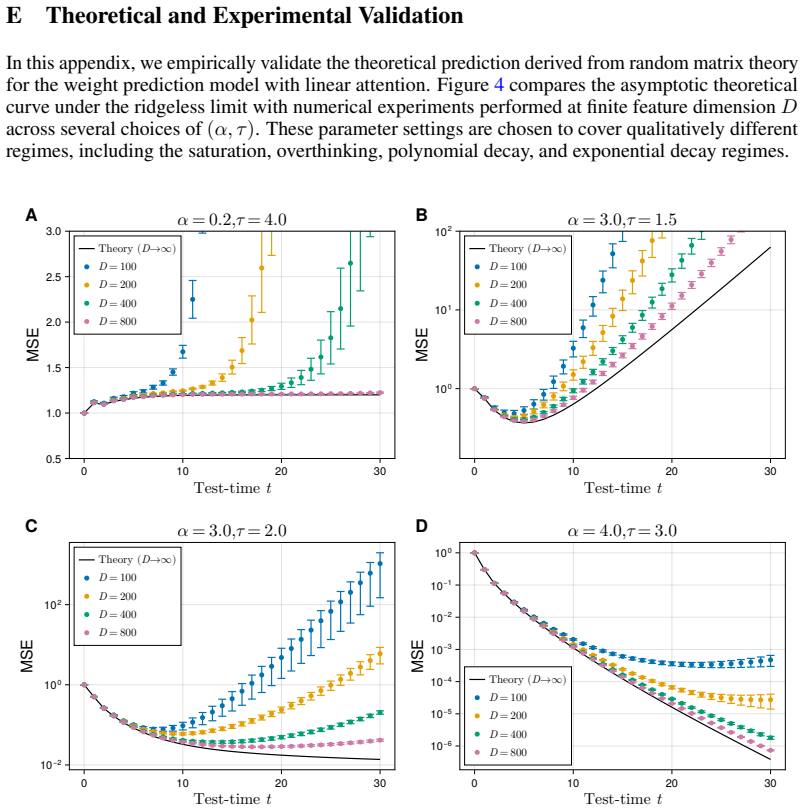
Yuyao Ge, Shenghua Liu, Yiwei Wang, Lingrui Mei, Lizhe Chen, Baolong Bi, and Xueqi Cheng. Innate reasoning is not enough: In-context learning enhances reasoning large language models with less overthinking, 2025. URLhttps://arxiv.org/abs/2503.19602. 13 Appendix In this appendix, we present a systematic asymptotic derivation of the high-dimensional theory ...
-
[41]
Tr(G [ℓ] 13) Tr(G[ℓ]
-
[42]
c m24(c m12 −u m 11) 1− u τ m21 + c τ m22 1− 1 τ m34 + c τ m44 + c m14(c m44 −m 34) 1− 1 τ m34 + c τ m44 # , (192) c24 − λ 2 m24 =c m 24 − 1 τ
Tr(G [ℓ] 23) 0 Tr(G [ℓ] 33) 0 Tr(G [ℓ] 43) ≍ m12 m13 m22 m23 0m 33 0m 43 .(118) Second term.Using (106), we compute L⊤ ℓ G[ℓ]Uℓ ≍ −m12 −√v m13 −m22 −√v m23 0− √v m33 0− √v m43 ,(119) and V ⊤ ℓ G[ℓ]Rℓ ≍ m12 m13 0v m 43 .(120) Moreover, from (111), I2 + ¯K= 1−m 12 −√v m13 0 1−vm 43 ,(121) 24 so its inverse is (I2 + ¯K) −1 = ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.