Learned Non-Maximum Suppression for 3D Object Detection
Pith reviewed 2026-06-28 10:52 UTC · model grok-4.3
The pith
Two learned modules replace heuristic NMS and raise mAP plus NDS on nuScenes 3D detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
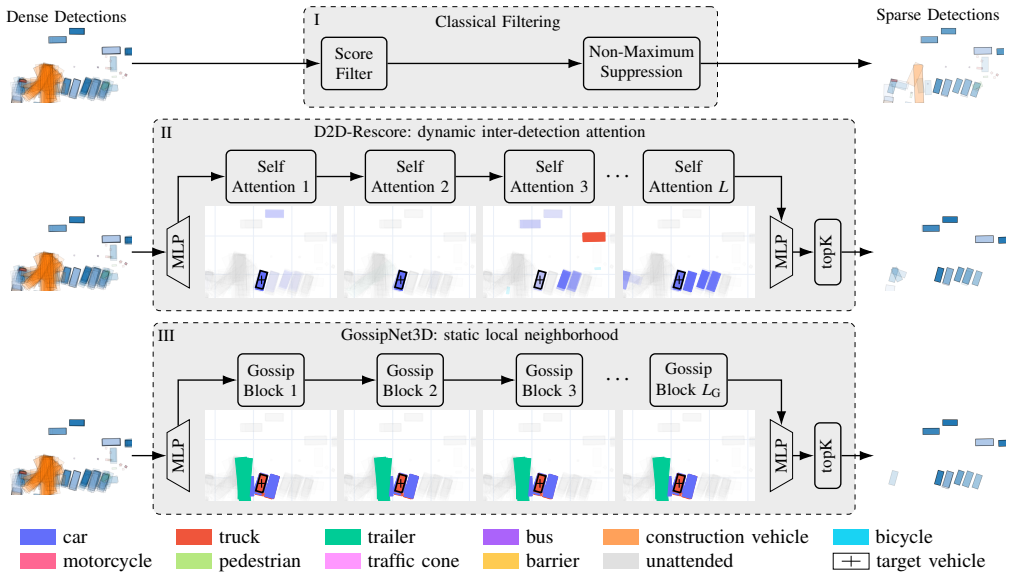
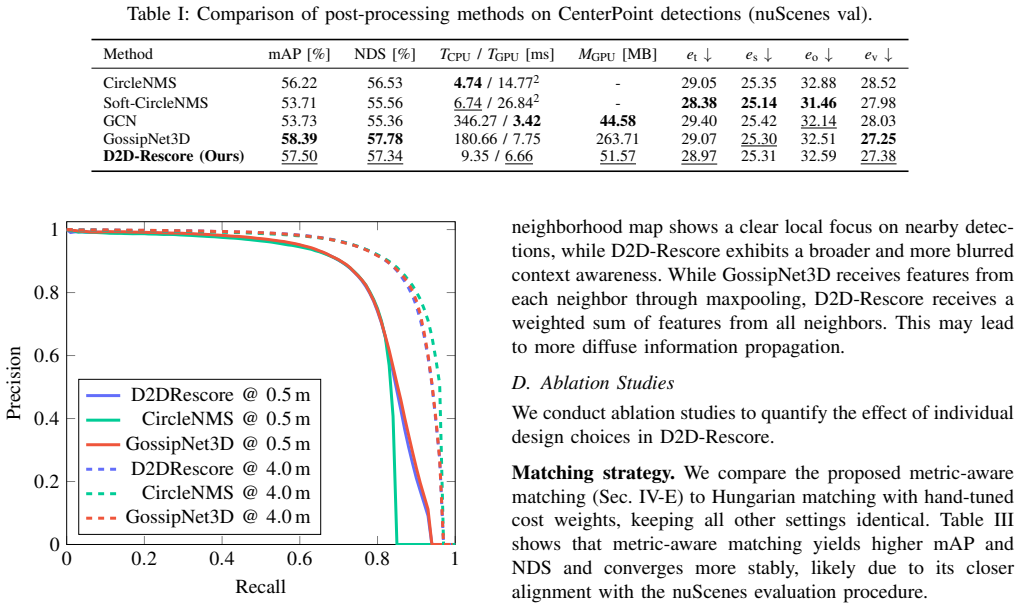
D2D-Rescore employs transformer-based detection-to-detection attention while GossipNet3D adapts localized message passing to three dimensions; both modules, trained with metric-aware matching, outperform CircleNMS on mAP, NDS, and true-positive metrics, especially for rare object classes, while adding negligible computation.
What carries the argument
Transformer attention across detections and localized message passing in bird's-eye view for rescor ing and suppressing 3D proposals.
If this is right
- Detection scores rise without any change to the underlying 3D detector architecture.
- Small and infrequent object classes receive the largest accuracy gains.
- Added runtime cost stays minimal compared with standard CircleNMS.
- Training remains aligned with final evaluation through the shared matching rule.
Where Pith is reading between the lines
- The same filtering approach could be attached to other 3D detectors that output dense proposals.
- Adapting the matching strategy might allow the modules to improve results on benchmarks that use different overlap criteria.
- Reduced false positives from better suppression could directly lower collision risk in downstream planning modules.
Load-bearing premise
The metric-aware matching strategy keeps training and validation behavior consistent without introducing bias toward the specific benchmark protocol.
What would settle it
An experiment on a different dataset or with a mismatched evaluation metric in which the learned modules produce equal or lower scores than CircleNMS would falsify the performance claim.
Figures
read the original abstract
Post-processing is a critical stage in LiDAR-based 3D object detection, where dense and overlapping proposals must be filtered for compact and reliable perception. This work introduces two learned filtering modules that replace heuristic non-maximum suppression (NMS) by leveraging relations among detections. D2D-Rescore employs transformer-based detection-to-detection (D2D) attention, while GossipNet3D adapts the 2D GossipNet concept to 3D through localized message passing in bird's-eye view. A metric-aware matching strategy aligned with the nuScenes evaluation protocol ensures consistent training and validation behavior, improving overall detection performance. Both approaches improve mean average precision (mAP), nuScenes detection score (NDS), and true positive quality compared to CircleNMS, particularly for small and infrequent classes, while adding minimal computational overhead. These results demonstrate that learned, detection-level filtering can enhance 3D detector reliability without modifying the base network, offering a principled alternative to heuristic suppression. Code is available at https://github.com/rst-tu-dortmund/learned-3d-nms .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two learned post-processing modules to replace heuristic CircleNMS in LiDAR-based 3D object detection: D2D-Rescore, which uses transformer-based detection-to-detection attention, and GossipNet3D, which adapts 2D GossipNet via localized message passing in bird's-eye view. A metric-aware matching strategy aligned with the nuScenes evaluation protocol is used during training. The manuscript reports that both modules improve mAP, NDS, and true-positive quality metrics over CircleNMS, with larger gains on small and infrequent classes and only minimal added compute; code is released.
Significance. If the reported gains prove robust, the work supplies a general, detector-agnostic route to better suppression that does not require retraining the base network. The public code release is a clear strength that aids reproducibility.
major comments (1)
- [Abstract and §4] Abstract and §4 (experiments): the central empirical claim of consistent mAP/NDS/TP-quality gains rests on training with a metric-aware matcher that deliberately mirrors the nuScenes evaluation protocol. No ablation is described that retrains the same modules with a protocol-agnostic matcher (e.g., standard 3D IoU). Without this control, it remains possible that part of the reported improvement is an artifact of metric alignment rather than a genuine advance in learned suppression; this directly affects the interpretation of the headline results, especially the gains on small/infrequent classes.
minor comments (1)
- [Abstract] The abstract states that both modules add “minimal computational overhead” but supplies no concrete latency or FLOPs numbers; a table or sentence in §4.3 would make the overhead claim verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the role of the metric-aware matcher. We address this point directly below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experiments): the central empirical claim of consistent mAP/NDS/TP-quality gains rests on training with a metric-aware matcher that deliberately mirrors the nuScenes evaluation protocol. No ablation is described that retrains the same modules with a protocol-agnostic matcher (e.g., standard 3D IoU). Without this control, it remains possible that part of the reported improvement is an artifact of metric alignment rather than a genuine advance in learned suppression; this directly affects the interpretation of the headline results, especially the gains on small/infrequent classes.
Authors: We agree that an explicit control experiment would strengthen the interpretation of the results. The metric-aware matcher was introduced to ensure training and evaluation operate under identical assignment criteria, which is a deliberate design choice to avoid train-test mismatch in the suppression objective. Nevertheless, the referee is correct that this leaves open the possibility that some gains arise from the alignment itself rather than from the learned D2D-Rescore or GossipNet3D modules. In the revised manuscript we will add an ablation that retrains both modules using a standard 3D IoU matcher (with the same hyperparameters otherwise) and report the resulting mAP, NDS, and TP metrics on nuScenes. This will allow readers to isolate the contribution of the learned suppression from the effect of metric alignment, particularly for the small and rare classes highlighted in the paper. revision: yes
Circularity Check
No significant circularity; empirical gains rest on independent training and evaluation
full rationale
The paper reports empirical mAP/NDS/TP-quality improvements from two learned post-processing modules (D2D-Rescore, GossipNet3D) versus CircleNMS on nuScenes. The metric-aware matching is presented as a training design choice aligned with the benchmark protocol to ensure consistent behavior; it does not appear in any equation that reduces a reported gain to a quantity fitted inside the same experiment. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central claims are therefore self-contained against external benchmarks and receive the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Center-based 3d object detection and tracking,
T. Yin, X. Zhou, and P. Krähenbühl, “Center-based 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021
2021
-
[2]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang et al., “Pointpillars: Fast encoders for object detection from point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019
2019
-
[3]
Dsvt: Dynamic sparse voxel trans- former with rotated sets,
H. Wang et al., “Dsvt: Dynamic sparse voxel trans- former with rotated sets,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[4]
Soft-nms–improving object detection with one line of code,
N. Bodla et al., “Soft-nms–improving object detection with one line of code,” inProceedings of the IEEE international conference on computer vision, 2017
2017
-
[5]
End-to-end object detection with transformers,
N. Carion et al., “End-to-end object detection with transformers,” inEuropean conference on computer vision, Springer, 2020
2020
-
[6]
Detr3d: 3d object detection from multi- view images via 3d-to-2d queries,
Y . Wang et al., “Detr3d: 3d object detection from multi- view images via 3d-to-2d queries,” inConference on robot learning, PMLR, 2022
2022
-
[7]
Li3detr: A lidar based 3d detection transformer,
G. K. Erabati and H. Araujo, “Li3detr: A lidar based 3d detection transformer,” inProceedings of the IEEE/CVF Winter conference on applications of computer vision, 2023
2023
-
[8]
Learning non- maximum suppression,
J. Hosang, R. Benenson, and B. Schiele, “Learning non- maximum suppression,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017
2017
-
[9]
Relation networks for object detection,
H. Hu et al., “Relation networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018
2018
-
[10]
End-to-end single shot detector using graph-based learnable duplicate removal,
S. Ding et al., “End-to-end single shot detector using graph-based learnable duplicate removal,” inDAGM German Conference on Pattern Recognition, Springer, 2022
2022
-
[11]
Internimage: Exploring large-scale vision foundation models with deformable convolu- tions,
W. Wang et al., “Internimage: Exploring large-scale vision foundation models with deformable convolu- tions,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023
2023
-
[12]
Rtmdet: An empirical study of designing real- time object detectors
C. Lyu et al., “Rtmdet: An empirical study of de- signing real-time object detectors,”arXiv preprint arXiv:2212.07784, 2022
-
[13]
Neural attention-driven non- maximum suppression for person detection,
C. Symeonidis et al., “Neural attention-driven non- maximum suppression for person detection,”IEEE transactions on image processing, vol. 32, 2023
2023
-
[14]
Petrv2: A unified framework for 3d perception from multi-camera images,
Y . Liu et al., “Petrv2: A unified framework for 3d perception from multi-camera images,” inProceedings of the IEEE/CVF international conference on computer vision, 2023
2023
-
[15]
Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via perspec- tive supervision,
C. Yang et al., “Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via perspec- tive supervision,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023
2023
-
[16]
Nuscenes: A multimodal dataset for autonomous driving,
H. Caesar et al., “Nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020
2020
-
[17]
Visibility guided nms: Efficient boosting of amodal object detection in crowded traffic scenes,
N. Gählert et al., “Visibility guided nms: Efficient boosting of amodal object detection in crowded traffic scenes,”arXiv preprint arXiv:2006.08547, 2020
-
[18]
Fourier features let networks learn high frequency functions in low dimensional domains,
M. Tancik et al., “Fourier features let networks learn high frequency functions in low dimensional domains,” Advances in neural information processing systems, vol. 33, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.