Channel-Oriented Design for EEG-to-Music Reconstruction
Pith reviewed 2026-06-28 08:53 UTC · model grok-4.3
The pith
Early mixing of EEG channels destroys weak but discriminative signals needed for music reconstruction from brain activity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
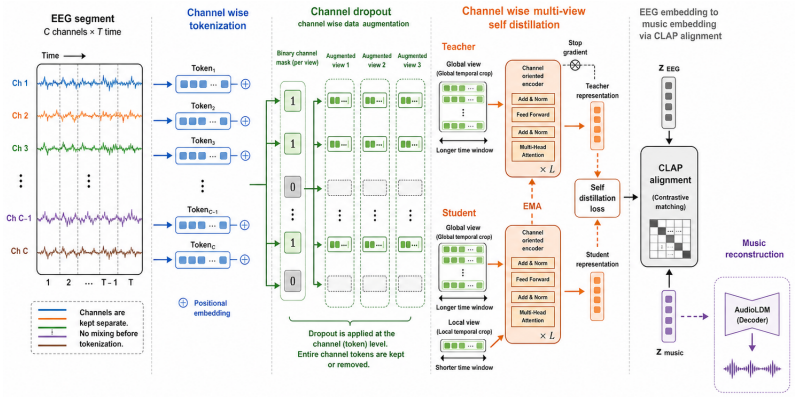
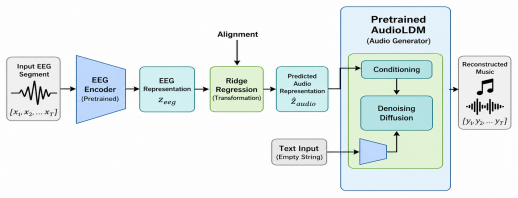
Early channel mixing destroys weak but discriminative EEG signals. The authors therefore introduce a channel-oriented design with three components: channel-wise tokenization that treats each electrode as an explicit token, channel-wise multi-view self-distillation that enforces consistency across temporal crops and random channel subsets, and channel-wise data augmentation via structured channel dropout. These elements preserve spatially localized neural evidence, improve robustness to noise and missing electrodes, and enable stable alignment to a semantic music representation space inside an encoding-alignment-decoding pipeline. A theoretical characterization identifies the conditions under
What carries the argument
Channel-oriented design that tokenizes each EEG electrode separately and applies per-channel operations to avoid early destructive mixing.
If this is right
- Channel-level preservation produces more stable alignment between EEG patterns and semantic music features.
- The design yields consistent gains over standard baselines on EEG-to-music tasks.
- Structured channel dropout improves invariance to electrode noise, artifacts, and missing channels.
- The theoretical condition specifies when retaining channel structure improves alignment quality.
Where Pith is reading between the lines
- The same per-channel treatment could be tested on other distributed neural decoding problems such as speech or visual imagery reconstruction.
- Datasets recorded with varying electrode counts would provide a direct check on the claimed invariance to missing channels.
- The method suggests examining whether early mixing harms performance in non-EEG multi-sensor recordings as well.
Load-bearing premise
Observed performance gains come primarily from the three channel-oriented components rather than from other modeling choices or training details.
What would settle it
An ablation experiment that removes the channel-wise tokenization, self-distillation, or data augmentation and measures no drop in music reconstruction metrics would falsify the central claim.
Figures
read the original abstract
Brain-computer interfaces aim to decode naturalistic stimuli from neural signals, yet most progress to date has focused on vision and language. In this article, we study a more challenging but far less explored setting, EEG-to-music reconstruction, where signals are weak, distributed, and highly susceptible to noise and channel variability. Our central finding is that early channel mixing destroys weak but discriminative EEG signals. To address this, we propose a channel-oriented design with three key components. Specifically, channel-wise tokenization treats each electrode as an explicit token to retain spatially localized neural evidence, channel-wise multi-view self-distillation enforces consistency across temporal crops and random channel subsets to learn robust and distributed representations, and channel-wise data augmentation introduces structured channel dropout to improve invariance to noise, artifacts, and missing electrodes. Together, these components preserve weak yet informative signals across channels and enable stable alignment to a semantic music representation space. We integrate this channel-oriented design within an encoding-alignment-decoding pipeline for EEG-to-music reconstruction. Theoretically, we characterize when preserving channel-level structure leads to improved alignment. Empirically, we compare with a range of state-of-the-art baselines and demonstrate consistent and significant performance gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that early channel mixing in EEG processing destroys weak but discriminative signals for music reconstruction, and proposes a channel-oriented design consisting of channel-wise tokenization, channel-wise multi-view self-distillation, and channel-wise data augmentation. These are integrated into an encoding-alignment-decoding pipeline to preserve signals and enable stable alignment to a semantic music space, supported by a theoretical characterization of when channel-level preservation improves alignment, and reported to yield consistent gains over baselines.
Significance. If the central empirical gains are shown to be driven by the channel-oriented components rather than other pipeline choices and if the theoretical characterization applies under the actual EEG noise and signal statistics, the work would advance EEG-to-music reconstruction by highlighting the risks of early mixing and the value of explicit channel preservation. The provision of a theoretical analysis alongside the empirical comparisons is a strength that distinguishes it from purely empirical BCI studies.
major comments (3)
- [Abstract] Abstract: the central claim that the three channel-oriented components (rather than the encoding-alignment-decoding skeleton or choice of music representation space) are what preserve signals and drive alignment gains requires isolation via ablations; no such controlled removal of individual components while holding other factors fixed is described, leaving open that gains could arise from unmentioned differences with baselines.
- [Abstract] Theoretical characterization paragraph: the modeling assumptions regarding signal weakness, noise structure, and channel independence are not stated to have been checked against the empirical EEG dataset statistics, so it is unclear whether the derived conditions for improved alignment actually hold in the experimental setting.
- [Abstract] Empirical comparison paragraph: the claim of 'consistent and significant performance gains' over state-of-the-art baselines cannot be evaluated without reported details on dataset sizes, error bars, statistical tests, or the exact baselines, which are required to assess whether the channel-oriented design is the load-bearing factor.
minor comments (1)
- [Abstract] The abstract would benefit from a brief quantitative statement of the reported gains (e.g., specific metrics or percentage improvements) to allow readers to gauge effect size without reading the full results section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for clearer isolation of contributions, verification of theoretical assumptions, and explicit reporting of experimental details. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the three channel-oriented components (rather than the encoding-alignment-decoding skeleton or choice of music representation space) are what preserve signals and drive alignment gains requires isolation via ablations; no such controlled removal of individual components while holding other factors fixed is described, leaving open that gains could arise from unmentioned differences with baselines.
Authors: We agree that controlled ablations isolating each of the three channel-oriented components (while holding the encoding-alignment-decoding pipeline and music space fixed) would more rigorously support the central claim. The submitted manuscript shows gains relative to baselines that perform early channel mixing but does not include such component-wise removals. In the revised version we will add these ablations, reporting performance drops when each component is removed individually. revision: yes
-
Referee: [Abstract] Theoretical characterization paragraph: the modeling assumptions regarding signal weakness, noise structure, and channel independence are not stated to have been checked against the empirical EEG dataset statistics, so it is unclear whether the derived conditions for improved alignment actually hold in the experimental setting.
Authors: The theoretical characterization derives general conditions under assumptions of weak per-channel signals and limited cross-channel correlation. The submitted manuscript does not include an explicit empirical check of these assumptions on the specific EEG dataset. In revision we will add a short analysis section verifying signal-to-noise characteristics, noise correlation structure, and inter-channel dependence statistics from the experimental data to confirm applicability of the derived conditions. revision: yes
-
Referee: [Abstract] Empirical comparison paragraph: the claim of 'consistent and significant performance gains' over state-of-the-art baselines cannot be evaluated without reported details on dataset sizes, error bars, statistical tests, or the exact baselines, which are required to assess whether the channel-oriented design is the load-bearing factor.
Authors: The full manuscript (Experiments section and supplementary tables) reports dataset sizes and splits, mean performance with standard deviations across random seeds, statistical significance via paired tests, and the precise baseline implementations with citations. These details already support the reported gains. To address the abstract-level concern we will revise the abstract to include a brief reference to the evaluation protocol and key statistical results. revision: partial
Circularity Check
No circularity: derivation remains self-contained with independent empirical and theoretical content.
full rationale
The abstract and provided text describe a channel-oriented design (tokenization, self-distillation, augmentation) integrated into an encoding-alignment-decoding pipeline, plus a theoretical characterization of when channel preservation improves alignment. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes are quoted that would reduce the claimed gains to inputs by construction. The central claim rests on comparisons to baselines and the stated theoretical characterization, which are presented as external to the design choices themselves. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large-scale brain networks emerge from dynamic processing of musical timbre, key and rhythm.NeuroImage, 59(4):3677–3689, 2012
Vinoo Alluri, Petri Toiviainen, Iiro P J¨a¨askel¨ainen, Enrico Glerean, Mikko Sams, and Elvira Brattico. Large-scale brain networks emerge from dynamic processing of musical timbre, key and rhythm.NeuroImage, 59(4):3677–3689, 2012
2012
-
[2]
Dreamdiffusion: High-quality eeg-to-image generation with temporal masked signal modeling and clip alignment
Yunpeng Bai, Xintao Wang, Yan-Pei Cao, Yixiao Ge, Chun Yuan, and Ying Shan. Dreamdiffusion: High-quality eeg-to-image generation with temporal masked signal modeling and clip alignment. InEuropean Conference on Computer Vision, pages 472–488. Springer, 2024
2024
-
[3]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[4]
Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding
Zijiao Chen, Jiaxin Qing, Tiange Xiang, Wan Lin Yue, and Juan Helen Zhou. Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22710–22720, 2023
2023
-
[5]
Cinematic mindscapes: High-quality video reconstruction from brain activity.Advances in Neural Information Processing Systems, 36: 24841–24858, 2023
Zijiao Chen, Jiaxin Qing, and Juan Helen Zhou. Cinematic mindscapes: High-quality video reconstruction from brain activity.Advances in Neural Information Processing Systems, 36: 24841–24858, 2023
2023
-
[6]
Neuro-gpt: Towards a foundation model for eeg
Wenhui Cui, Woojae Jeong, Philipp Th¨olke, Takfarinas Medani, Karim Jerbi, Anand A Joshi, and Richard M Leahy. Neuro-gpt: Towards a foundation model for eeg. In2024 IEEE International Symposium on Biomedical Imaging (ISBI), pages 1–5. IEEE, 2024
2024
-
[7]
Lost in translation: An enculturation effect in music memory performance.Music Perception, 25(3): 213–223, 2008
Steven M Demorest, Steven J Morrison, M ¨unir Nuri Beken, and Daniel Jungbluth. Lost in translation: An enculturation effect in music memory performance.Music Perception, 25(3): 213–223, 2008
2008
-
[8]
Decoding the neural signatures of valence and arousal from portable EEG headset.Frontiers in Human Neuroscience, 16:1051463,
Nikhil Garg, Rohit Garg, Apoorv Anand, and Veeky Baths. Decoding the neural signatures of valence and arousal from portable EEG headset.Frontiers in Human Neuroscience, 16:1051463,
-
[9]
doi: 10.3389/fnhum.2022.1051463
-
[10]
Rethinking ImageNet pre-training
Kaiming He, Ross Girshick, and Piotr Doll´ar. Rethinking ImageNet pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4918–4927, 2019
2019
-
[11]
Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu. Large brain model for learning generic representations with tremendous eeg data in bci.arXiv preprint arXiv:2405.18765, 2024
-
[12]
Natural music evokes correlated eeg responses reflecting temporal structure and beat
Blair Kaneshiro, Duc T Nguyen, Anthony M Norcia, Jacek P Dmochowski, and Jonathan Berger. Natural music evokes correlated eeg responses reflecting temporal structure and beat. NeuroImage, 214:116559, 2020
2020
-
[13]
Brain correlates of music-evoked emotions.Nature Reviews Neuroscience, 15 (3):170–180, 2014
Stefan Koelsch. Brain correlates of music-evoked emotions.Nature Reviews Neuroscience, 15 (3):170–180, 2014
2014
-
[14]
Yuan-Pin Lin, Jeng-Ren Duann, Jyh-Horng Chen, and Tzyy-Ping Jung. Electroencephalographic dynamics of musical emotion perception revealed by independent spectral components. NeuroReport, 21(6):410–415, 2010. doi: 10.1097/WNR.0b013e32833774de
-
[15]
Audioldm: Text-to-audio generation with latent diffusion models
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audioldm: Text-to-audio generation with latent diffusion models. In International Conference on Machine Learning, pages 21450–21474. PMLR, 2023
2023
-
[16]
Nmed-t: A tempo-focused dataset of cortical and behavioral responses to naturalistic music
Steven Losorelli, Duc T Nguyen, Jacek P Dmochowski, and Blair Kaneshiro. Nmed-t: A tempo-focused dataset of cortical and behavioral responses to naturalistic music. InISMIR, volume 3, page 5, 2017
2017
-
[17]
Music and emotions in the brain: Familiarity matters.PLoS ONE, 6(11):e27241, 2011
Carlos Silva Pereira, Jo˜ao Teixeira, Patr´ıcia Figueiredo, Jo˜ao Xavier, S˜ao Lu´ıs Castro, and Elvira Brattico. Music and emotions in the brain: Familiarity matters.PLoS ONE, 6(11):e27241, 2011
2011
-
[18]
Transfusion: Understanding transfer learning for medical imaging
Maithra Raghu, Chiyuan Zhang, Jon Kleinberg, and Samy Bengio. Transfusion: Understanding transfer learning for medical imaging. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019. 10
2019
-
[19]
Eeg2mel: Reconstructing sound from brain responses to music.arXiv preprint arXiv:2207.13845, 2022
Adolfo G Ramirez-Aristizabal and Chris Kello. Eeg2mel: Reconstructing sound from brain responses to music.arXiv preprint arXiv:2207.13845, 2022
-
[20]
Lars Rogenmoser, Nina Zollinger, Stefan Elmer, and Lutz J ¨ancke. Independent component processes underlying emotions during natural music listening.Social Cognitive and Affective Neuroscience, 11(9):1428–1439, 2016. doi: 10.1093/scan/nsw048
-
[21]
Louis A. Schmidt and Laurel J. Trainor. Frontal brain electrical activity (EEG) distinguishes valence and intensity of musical emotions.Cognition and Emotion, 15(4):487–500, 2001. doi: 10.1080/02699930126048
-
[22]
Paul S Scotti, Mihir Tripathy, Cesar Kadir Torrico Villanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A Norman, et al. Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data.arXiv preprint arXiv:2403.11207, 2024
-
[23]
Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023
Yonghao Song, Bingchuan Liu, Xiang Li, Nanlin Shi, Yijun Wang, and Xiaorong Gao. Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023
-
[24]
The GTZAN dataset: Its contents, its faults, their effects on evaluation, and its future use
Bob L Sturm. The gtzan dataset: Its contents, its faults, their effects on evaluation, and its future use.arXiv preprint arXiv:1306.1461, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[25]
High-resolution image reconstruction with latent diffusion models from human brain activity
Yu Takagi and Shinji Nishimoto. High-resolution image reconstruction with latent diffusion models from human brain activity. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14453–14463, 2023
2023
-
[26]
Semantic reconstruction of con- tinuous language from non-invasive brain recordings.Nature Neuroscience, 26(5):858–866, 2023
Jerry Tang, Amanda LeBel, Shailee Jain, and Alexander G Huth. Semantic reconstruction of con- tinuous language from non-invasive brain recordings.Nature Neuroscience, 26(5):858–866, 2023
2023
-
[27]
EEGPT: Pretrained transformer for universal and reliable representation of EEG signals
Guangyu Wang, Wenchao Liu, Yuhong He, Cong Xu, Lin Ma, and Haifeng Li. EEGPT: Pretrained transformer for universal and reliable representation of EEG signals. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[28]
Cbramod: A criss-cross brain foundation model for eeg decoding.arXiv preprint arXiv:2412.07236, 2024
Jiquan Wang, Sha Zhao, Zhiling Luo, Yangxuan Zhou, Haiteng Jiang, Shijian Li, Tao Li, and Gang Pan. Cbramod: A criss-cross brain foundation model for eeg decoding.arXiv preprint arXiv:2412.07236, 2024
-
[29]
Eegmamba: An eeg foundation model with mamba.Neural Networks, page 107816, 2025
Jiquan Wang, Sha Zhao, Zhiling Luo, Yangxuan Zhou, Shijian Li, and Gang Pan. Eegmamba: An eeg foundation model with mamba.Neural Networks, page 107816, 2025
2025
-
[30]
Jiquan Wang, Sha Zhao, Yangxuan Zhou, Yiming Kang, Shijian Li, and Gang Pan. Deeperbrain: A neuro-grounded eeg foundation model towards universal bci.arXiv preprint arXiv:2601.06134, 2026
-
[31]
Eeg-dino: Learning eeg foundation models via hierarchical self-distillation
Xujia Wang, Xuhui Liu, Xi Liu, Qian Si, Zhaoliang Xu, Yang Li, and Xiantong Zhen. Eeg-dino: Learning eeg foundation models via hierarchical self-distillation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 196–205. Springer, 2025
2025
-
[32]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
2023
-
[33]
Spectral and temporal processing in human auditory cortex
Robert J Zatorre and Pascal Belin. Spectral and temporal processing in human auditory cortex. Cerebral Cortex, 11(10):946–953, 2001
2001
-
[34]
ReliefF-based EEG sensor selection methods for emotion recognition.Sensors, 16(10):1558, 2016
Jianhai Zhang, Ming Chen, Shaokai Zhao, Sanqing Hu, Zhiguo Shi, and Yu Cao. ReliefF-based EEG sensor selection methods for emotion recognition.Sensors, 16(10):1558, 2016. doi: 10.3390/s16101558. 11 A Proofs A.1 Proof of Lemma 4.1 This lemma requires the following assumptions for masking-induced augmentation kernels, all of which are standard in the litera...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.