M³Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
Pith reviewed 2026-06-28 06:13 UTC · model grok-4.3
The pith
M³Eval benchmark tests memory in multi-modal video models and finds they struggle to keep parallel streams disentangled while favoring spatial over temporal grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
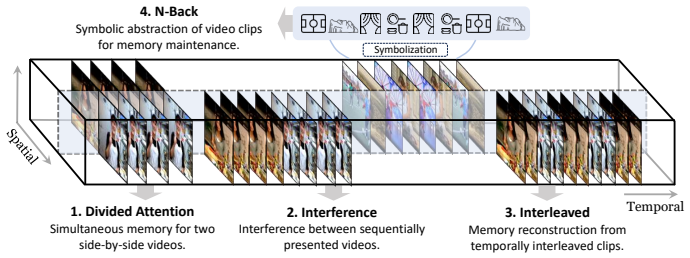
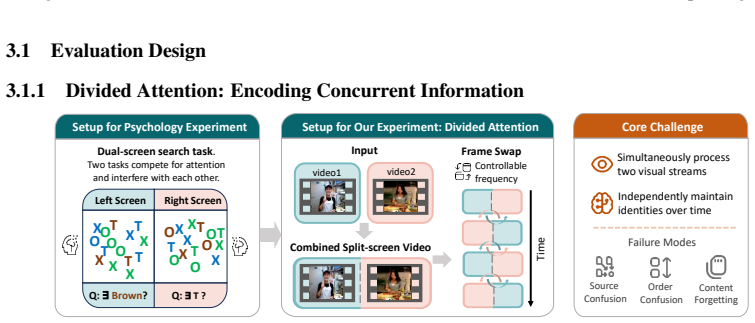
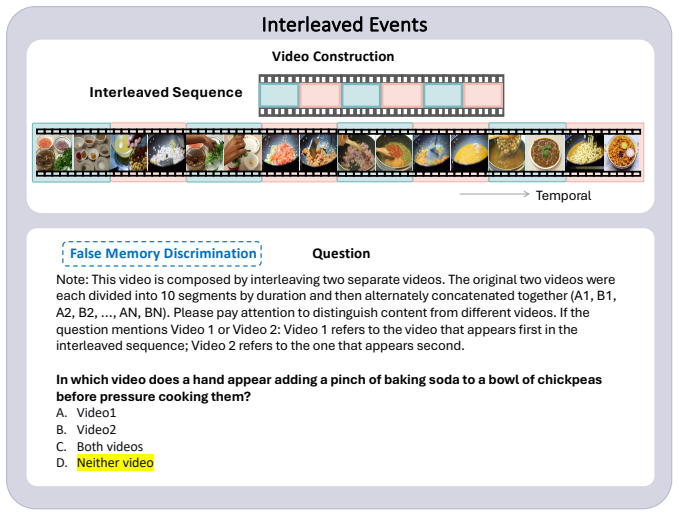
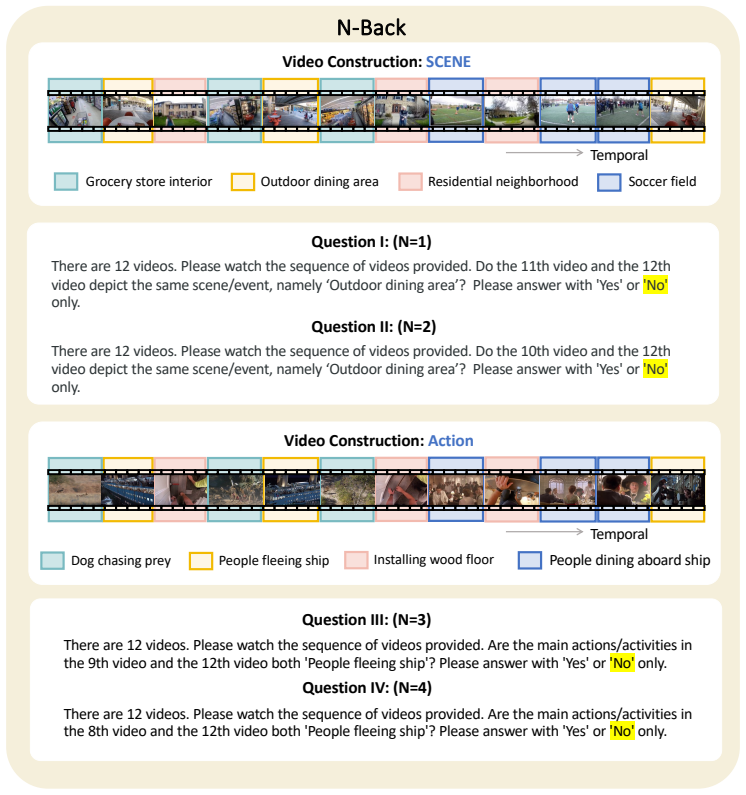
M³Eval supplies a set of video tasks that isolate memory aspects such as handling interference from parallel streams, distinguishing spatial versus temporal source grounding, and retaining symbolic content. When applied to existing multi-modal models the tasks expose four recurring limitations: failure to preserve disentangled representations under concurrent inputs, interference signatures that diverge from human data, more accurate memory attachment to spatial cues than to temporal sequence, and restricted capacity for symbolic recall.
What carries the argument
M³Eval, an evaluation framework whose tasks isolate memory dimensions through cognitively-grounded video scenarios that probe retention fidelity, interference robustness, and domain-specific grounding.
If this is right
- The benchmark supplies a reusable resource for testing memory mechanisms in future multi-modal models.
- Insights from the observed weaknesses can guide construction of memory modules that better preserve disentanglement and temporal precision.
- Systematic separation of memory evaluation from perception benchmarks becomes necessary as video understanding lengthens.
- Design choices for new models should target the identified gaps in spatial-temporal balance and symbolic retention.
Where Pith is reading between the lines
- The identified gaps could motivate training objectives that explicitly penalize cross-stream interference.
- Extending the tasks to longer or more complex video collections might reveal scaling behavior of the same weaknesses.
- Direct comparison of model outputs against human recall data on identical tasks could quantify how far the divergence extends.
- The benchmark format might transfer to evaluating memory in single-modality language or audio models.
Load-bearing premise
The constructed tasks successfully isolate the intended memory dimensions from perception and reasoning confounds.
What would settle it
Running the parallel-stream and interference tasks on the same models and finding either fully disentangled representations or interference patterns that match human data would falsify the reported weaknesses.
Figures


















read the original abstract
As multi-modal models advance towards long-form video understanding, memory emerges as a critical capability. Despite substantial efforts in developing video datasets and benchmarks, existing works primarily focus on perception and reasoning, without systematically evaluating memory: what models retain, how faithfully information is preserved, and how robust memory remains under interference. To address this gap, we introduce M$^3$Eval, the first comprehensive evaluation framework and benchmark for probing different memory dimensions in multi-modal models. Grounded in cognitive psychology, our design features carefully constructed tasks that isolate key aspects of memory. Leveraging M$^3$Eval, we conduct extensive experiments across representative multi-modal models, revealing consistent weaknesses and distinctive behaviors. We find that models struggle to maintain disentangled representations when processing parallel video streams, exhibit interference patterns differing substantially from those observed in human memory, ground memory sources more reliably in the spatial domain than the temporal domain, and demonstrate limited symbolic memory. Collectively, our benchmark provides a valuable resource for future research, while our findings highlight memory as a fundamental yet underexplored capability and offer insights for designing more effective memory mechanisms in multi-modal models. Our code and dataset are available at https://pku-value-lab.github.io/m3eval-homepage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces M³Eval, the first comprehensive benchmark for evaluating memory dimensions in multi-modal models via cognitively-grounded video tasks designed to isolate memory from perception and reasoning. Through experiments on representative models, it reports consistent weaknesses: difficulty maintaining disentangled representations under parallel video streams, interference patterns unlike those in human memory, more reliable spatial than temporal grounding of memory sources, and limited symbolic memory. Code and dataset are released at the provided URL.
Significance. If the task isolation holds, this fills a clear gap by shifting focus from perception/reasoning to memory robustness in long-form video models, with findings that could guide mechanism design. Explicit credit is due for the public code and dataset release, which supports reproducibility and extension by the community.
major comments (2)
- [Abstract / task design] Abstract and task-construction description: the central claim that tasks 'isolate key aspects of memory' (and thereby make the reported weaknesses memory-specific) is load-bearing for all headline findings, yet no ablations, human-norming data, or controls are described that demonstrate performance is insensitive to perceptual noise or reasoning load variations.
- [Experiments] Experiments: no model list, statistical tests, or exclusion criteria are inspectable from the provided text, preventing verification that the 'consistent weaknesses' and 'distinctive behaviors' are robust rather than sensitive to post-hoc choices.
minor comments (1)
- [Abstract] Abstract: the phrase 'extensive experiments across representative multi-modal models' would benefit from an explicit enumeration of the models even in the abstract for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for recognizing the potential contribution of M³Eval along with the value of the released code and dataset. We address the two major comments below and will revise the manuscript to incorporate the requested clarifications and supporting analyses.
read point-by-point responses
-
Referee: [Abstract / task design] Abstract and task-construction description: the central claim that tasks 'isolate key aspects of memory' (and thereby make the reported weaknesses memory-specific) is load-bearing for all headline findings, yet no ablations, human-norming data, or controls are described that demonstrate performance is insensitive to perceptual noise or reasoning load variations.
Authors: We agree that explicit validation of task isolation is necessary to support the memory-specific interpretation of the results. The current manuscript grounds the tasks in cognitive psychology principles intended to separate memory from perception and reasoning, but does not include ablations, human-norming data, or targeted controls for perceptual noise and reasoning load. In revision we will add a dedicated subsection with these controls and preliminary human baselines to strengthen the isolation claim. revision: yes
-
Referee: [Experiments] Experiments: no model list, statistical tests, or exclusion criteria are inspectable from the provided text, preventing verification that the 'consistent weaknesses' and 'distinctive behaviors' are robust rather than sensitive to post-hoc choices.
Authors: The experiments section of the full manuscript lists the representative multi-modal models evaluated and provides implementation details. To improve inspectability and verifiability we will expand this section with an explicit model table, report appropriate statistical tests on the performance differences, and clearly document any exclusion criteria applied during data processing or evaluation. revision: yes
Circularity Check
Empirical benchmark construction with no derivation chain or self-referential reductions
full rationale
The paper introduces M³Eval as a benchmark for memory evaluation in multi-modal models, with tasks designed from cognitive psychology principles. The abstract and description contain no equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or ansatzes. Central claims consist of empirical observations from model evaluations on constructed tasks; the isolation of memory dimensions is presented as a design feature rather than a result that reduces to prior outputs by construction. No self-citation load-bearing steps appear. The work is self-contained as an empirical framework against external model testing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cognitive psychology supplies isolatable memory dimensions that can be faithfully instantiated as video tasks without substantial perceptual or reasoning confounds.
Reference graph
Works this paper leans on
-
[1]
Psychology press, 2014
John R Anderson and Gordon H Bower.Human associative memory. Psychology press, 2014
2014
-
[2]
Infinibench: A benchmark for large multi-modal models in long-form movies and tv shows
Kirolos Ataallah, Eslam Mohamed Bakr, Mahmoud Ahmed, Chenhui Gou, Khushbu Pahwa, Jian Ding, and Mohamed Elhoseiny. Infinibench: A benchmark for large multi-modal models in long-form movies and tv shows. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19496–19523, 2025
2025
-
[3]
Working memory.Comptes Rendus de l’Académie des Sciences-Series III- Sciences de la Vie, 321(2-3):167–173, 1998
Alan Baddeley. Working memory.Comptes Rendus de l’Académie des Sciences-Series III- Sciences de la Vie, 321(2-3):167–173, 1998
1998
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yuanchen Bei, Tianxin Wei, Xuying Ning, Yanjun Zhao, Zhining Liu, Xiao Lin, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. Mem-gallery: Benchmarking multimodal long-term conversational memory for mllm agents.arXiv preprint arXiv:2601.03515, 2026
-
[6]
Distributed practice in verbal recall tasks: A review and quantitative synthesis.Psychological bulletin, 132 (3):354, 2006
Nicholas J Cepeda, Harold Pashler, Edward Vul, John T Wixted, and Doug Rohrer. Distributed practice in verbal recall tasks: A review and quantitative synthesis.Psychological bulletin, 132 (3):354, 2006
2006
-
[7]
Hourvideo: 1-hour video- language understanding.Advances in Neural Information Processing Systems, 37:53168–53197, 2024
Keshigeyan Chandrasegaran, Agrim Gupta, Lea M Hadzic, Taran Kota, Jimming He, Cristóbal Eyzaguirre, Zane Durante, Manling Li, Jiajun Wu, and Li Fei-Fei. Hourvideo: 1-hour video- language understanding.Advances in Neural Information Processing Systems, 37:53168–53197, 2024
2024
-
[8]
Video-Holmes: Can MLLM Think Like Holmes for Complex Video Reasoning?
Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, and Ying Shan. Video-holmes: Can mllm think like holmes for complex video reasoning?arXiv preprint arXiv:2505.21374, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
The effects of divided attention on encoding and retrieval processes in human memory.Journal of Experimental Psychology: General, 125(2):159, 1996
Fergus IM Craik, Richard Govoni, Moshe Naveh-Benjamin, and Nicole D Anderson. The effects of divided attention on encoding and retrieval processes in human memory.Journal of Experimental Psychology: General, 125(2):159, 1996
1996
-
[10]
DeepSeek-V4: Towards highly efficient million-token context intelligence
DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence. Hugging Face model card, April 2026. URL https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro. Accessed: 2026-05-02
2026
-
[11]
On the prediction of occurrence of particular verbal intrusions in immediate recall
James Deese. On the prediction of occurrence of particular verbal intrusions in immediate recall. Journal of experimental psychology, 58(1):17, 1959
1959
-
[12]
Videoagent: A memory-augmented multimodal agent for video understanding
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented multimodal agent for video understanding. InEuropean Conference on Computer Vision, pages 75–92. Springer, 2024. 10
2024
-
[13]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
2025
-
[14]
Working memory capacity of chatgpt: An empirical study
Dongyu Gong, Xingchen Wan, and Dingmin Wang. Working memory capacity of chatgpt: An empirical study. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 10048–10056, 2024
2024
-
[15]
Gemini 3.1 pro model card, 2026
Google DeepMind. Gemini 3.1 pro model card, 2026. URL https://deepmind.google/ models/model-cards/gemini-3-1-pro/. Accessed: 2026-05-02
2026
-
[16]
Repetition and memory.Psychology of learning and motivation, 10: 47–91, 1976
Douglas L Hintzman. Repetition and memory.Psychology of learning and motivation, 10: 47–91, 1976
1976
-
[17]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Chenxu Hu, Jie Fu, Chenzhuang Du, Simian Luo, Junbo Zhao, and Hang Zhao. Chatdb: Augmenting llms with databases as their symbolic memory.arXiv preprint arXiv:2306.03901, 2023
-
[19]
Memory in the Age of AI Agents
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, et al. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Nemo: Needle in a montage for video-language understanding
Zi-Yuan Hu, Shuo Liang, Duo Zheng, Yanyang Li, Yeyao Tao, Shijia Huang, Wei Feng, Jia Qin, Jianguang Yu, Jing Huang, et al. Nemo: Needle in a montage for video-language understanding. arXiv preprint arXiv:2509.24563, 2025
-
[21]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Evaluating the long-term memory of large language models
Zixi Jia, Qinghua Liu, Hexiao Li, Yuyan Chen, and Jiqiang Liu. Evaluating the long-term memory of large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19759–19777, 2025
2025
-
[23]
The ai hippocampus: How far are we from human memory? arXiv preprint arXiv:2601.09113, 2026
Zixia Jia, Jiaqi Li, Yipeng Kang, Yuxuan Wang, Tong Wu, Quansen Wang, Xiaobo Wang, Shuyi Zhang, Junzhe Shen, Qing Li, et al. The ai hippocampus: How far are we from human memory? arXiv preprint arXiv:2601.09113, 2026
-
[24]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
2023
-
[25]
Source monitoring.Psychologi- cal bulletin, 114(1):3, 1993
Marcia K Johnson, Shahin Hashtroudi, and D Stephen Lindsay. Source monitoring.Psychologi- cal bulletin, 114(1):3, 1993
1993
-
[26]
Oxford University Press, 2024
Michael J Kahana and Anthony D Wagner.The Oxford handbook of human memory, two volume pack: foundations and applications. Oxford University Press, 2024
2024
-
[27]
Attention and effort.Experimental psychology, 1973
D KAHNEMAN. Attention and effort.Experimental psychology, 1973
1973
-
[28]
Age differences in short-term retention of rapidly changing information
Wayne K Kirchner. Age differences in short-term retention of rapidly changing information. Journal of experimental psychology, 55(4):352, 1958
1958
-
[29]
Babilong: Testing the limits of llms with long context reasoning-in-a-haystack
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, and Mikhail Burtsev. Babilong: Testing the limits of llms with long context reasoning-in-a-haystack. Advances in Neural Information Processing Systems, 37:106519–106554, 2024. 11
2024
-
[30]
Prompt repetition improves non-reasoning llms.arXiv preprint arXiv:2512.14982, 2025
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Prompt repetition improves non-reasoning llms.arXiv preprint arXiv:2512.14982, 2025
-
[31]
Crossvid: A comprehensive benchmark for evaluating cross-video reasoning in multimodal large language models
Jingyao Li, Jingyun Wang, Molin Tan, Haochen Wang, Cilin Yan, Likun Shi, Jiayin Cai, Xiaolong Jiang, and Yao Hu. Crossvid: A comprehensive benchmark for evaluating cross-video reasoning in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 6244–6252, 2026
2026
-
[32]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
-
[33]
Two causally related needles in a video haystack.arXiv preprint arXiv:2505.19853, 2025
Miaoyu Li, Qin Chao, and Boyang Li. Two causally related needles in a video haystack.arXiv preprint arXiv:2505.19853, 2025
-
[34]
Jiafeng Liang, Hao Li, Chang Li, Jiaqi Zhou, Shixin Jiang, Zekun Wang, Changkai Ji, Zhihao Zhu, Runxuan Liu, Tao Ren, et al. Ai meets brain: Memory systems from cognitive neuroscience to autonomous agents.arXiv preprint arXiv:2512.23343, 2025
-
[35]
Streamingbench: Assessing the gap for mllms to achieve streaming video understanding
Junming Lin, Zheng Fang, Chi Chen, Haoxuan Cheng, Zihao Wan, Fuwen Luo, Ziyue Wang, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video understanding. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12147–12151. IEEE, 2026
2026
-
[36]
Ruixun Liu, Lingyu Kong, Derun Li, and Hang Zhao. Occvla: Vision-language-action model with implicit 3d occupancy supervision.arXiv preprint arXiv:2509.05578, 2025
-
[37]
Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory
Lin Long, Yichen He, Wentao Ye, Yiyuan Pan, Yuan Lin, Hang Li, Junbo Zhao, and Wei Li. Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory. arXiv preprint arXiv:2508.09736, 2025
-
[38]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
2024
-
[39]
A code in the node: The use of a story schema in retrieval.Discourse processes, 1(1):14–35, 1978
Jean M Mandler. A code in the node: The use of a story schema in retrieval.Discourse processes, 1(1):14–35, 1978
1978
-
[40]
Remembrance of things parsed: Story structure and recall.Cognitive psychology, 9(1):111–151, 1977
Jean M Mandler and Nancy S Johnson. Remembrance of things parsed: Story structure and recall.Cognitive psychology, 9(1):111–151, 1977
1977
-
[41]
Forgetting and the law of disuse.Psychological review, 39(4):352, 1932
John A McGeoch. Forgetting and the law of disuse.Psychological review, 39(4):352, 1932
1932
-
[42]
Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025
Junbo Niu, Yifei Li, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, et al. Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025
2025
-
[43]
Gpt-5.4 thinking system card, March 2026
OpenAI. Gpt-5.4 thinking system card, March 2026. URL https://openai.com/ zh-Hans-CN/index/introducing-gpt-5-4/. Accessed: 2026-05-02
2026
-
[44]
N-back working memory paradigm: A meta-analysis of normative functional neuroimaging studies.Human brain mapping, 25(1):46–59, 2005
Adrian M Owen, Kathryn M McMillan, Angela R Laird, and Ed Bullmore. N-back working memory paradigm: A meta-analysis of normative functional neuroimaging studies.Human brain mapping, 25(1):46–59, 2005
2005
-
[45]
Space and time in episodic memory: Effects of linearity and directionality on memory for spatial location and temporal order in children and adults.PLoS One, 13(11):e0206999, 2018
Thanujeni Pathman, Christine Coughlin, and Simona Ghetti. Space and time in episodic memory: Effects of linearity and directionality on memory for spatial location and temporal order in children and adults.PLoS One, 13(11):e0206999, 2018
2018
-
[46]
What the mind’s eye tells the mind’s brain: A critique of mental imagery
Zenon W Pylyshyn. What the mind’s eye tells the mind’s brain: A critique of mental imagery. Psychological bulletin, 80(1):1, 1973. 12
1973
-
[47]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5. Accessed: 2026-05-02
2026
-
[48]
Some factors determining the degree of retroactive inhibition
Edward Stevens Robinson. Some factors determining the degree of retroactive inhibition. Psychological Monographs, 28(6):i, 1920
1920
-
[49]
Creating false memories: Remembering words not presented in lists.Journal of experimental psychology: Learning, Memory, and Cognition, 21(4):803, 1995
Henry L Roediger and Kathleen B McDermott. Creating false memories: Remembering words not presented in lists.Journal of experimental psychology: Learning, Memory, and Cognition, 21(4):803, 1995
1995
-
[50]
Retrieval without recollection: An experimental analysis of source amnesia.Journal of verbal learning and verbal behavior, 23(5):593–611, 1984
Daniel L Schacter, Joanne L Harbluk, and Donald R McLachlan. Retrieval without recollection: An experimental analysis of source amnesia.Journal of verbal learning and verbal behavior, 23(5):593–611, 1984
1984
-
[51]
Cambridge University Press, 2022
John W Schwieter and Zhisheng Edward Wen.The Cambridge handbook of working memory and language. Cambridge University Press, 2022
2022
-
[52]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024
2024
-
[53]
Moviechat+: Question-aware sparse memory for long video question answering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, and Gaoang Wang. Moviechat+: Question-aware sparse memory for long video question answering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[54]
Counting-stars: A multi-evidence, position-aware, and scalable benchmark for evaluating long-context large language models
Mingyang Song, Mao Zheng, and Xuan Luo. Counting-stars: A multi-evidence, position-aware, and scalable benchmark for evaluating long-context large language models. InProceedings of the 31st International Conference on Computational Linguistics, pages 3753–3763, 2025
2025
-
[55]
Reconvla: Reconstructive vision- language-action model as effective robot perceiver
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, and Haoang Li. Reconvla: Reconstructive vision- language-action model as effective robot perceiver. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18549–18557, 2026
2026
-
[56]
Membench: Towards more comprehensive evaluation on the memory of llm-based agents
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. Membench: Towards more comprehensive evaluation on the memory of llm-based agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19336–19352, 2025
2025
-
[57]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Neurophysiological distinctions between spatial and temporal context in episodic memory.International Journal of Psychophysiology, page 113302, 2025
César Torres-Morales and Selene Cansino. Neurophysiological distinctions between spatial and temporal context in episodic memory.International Journal of Psychophysiology, page 113302, 2025
2025
-
[59]
Illusory conjunctions in the perception of objects.Cognitive psychology, 14(1):107–141, 1982
Anne Treisman and Hilary Schmidt. Illusory conjunctions in the perception of objects.Cognitive psychology, 14(1):107–141, 1982
1982
-
[60]
A feature-integration theory of attention.Cognitive psychology, 12(1):97–136, 1980
Anne M Treisman and Garry Gelade. A feature-integration theory of attention.Cognitive psychology, 12(1):97–136, 1980
1980
-
[61]
Interference and forgetting.Psychological review, 64(1):49, 1957
Benton J Underwood. Interference and forgetting.Psychological review, 64(1):49, 1957
1957
-
[62]
Time Blindness: Why Video-Language Models Can't See What Humans Can?
Ujjwal Upadhyay, Mukul Ranjan, Zhiqiang Shen, and Mohamed Elhoseiny. Time blindness: Why video-language models can’t see what humans can?arXiv preprint arXiv:2505.24867, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Symbolic working memory enhances language models for complex rule application
Siyuan Wang, Zhongyu Wei, Yejin Choi, and Xiang Ren. Symbolic working memory enhances language models for complex rule application. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17583–17604, 2024. 13
2024
-
[64]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958– 22967, 2025
2025
-
[65]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H Chi, et al. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Video-levelgauge: Investigating contextual positional bias in large video language models
Hou Xia, Zheren Fu, Fangcan Ling, Jiajun Li, Yi Tu, Zhendong Mao, and Yongdong Zhang. Video-levelgauge: Investigating contextual positional bias in large video language models. arXiv preprint arXiv:2508.19650, 2025
-
[69]
Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, and Huchuan Lu. Streaming video understanding and multi-round interaction with memory-enhanced knowl- edge.arXiv preprint arXiv:2501.13468, 2025
-
[70]
Egolife: Towards egocentric life assistant
Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xiamengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, et al. Egolife: Towards egocentric life assistant. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28885–28900, 2025
2025
-
[71]
Cambrian-S: Towards Spatial Supersensing in Video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis L. Brown, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, Daohan Lu, Rob Fergus, Yann LeCun, Li Fei- Fei, and Saining Xie. Cambrian-S: Towards spatial supersensing in video.arXiv preprint arXiv:2511.04670, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Zhenyu Yang, Yuhang Hu, Zemin Du, Dizhan Xue, Shengsheng Qian, Jiahong Wu, Fan Yang, Weiming Dong, and Changsheng Xu. Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding.arXiv preprint arXiv:2502.10810, 2025
-
[73]
Temporal associations and prior-list intrusions in free recall.Journal of Experimental Psychology: Learning, Memory, and Cognition, 32(4):792, 2006
Franklin M Zaromb, Marc W Howard, Emily D Dolan, Yevgeniy B Sirotin, Michele Tully, Arthur Wingfield, and Michael J Kahana. Temporal associations and prior-list intrusions in free recall.Journal of Experimental Psychology: Learning, Memory, and Cognition, 32(4):792, 2006
2006
-
[74]
Working memory identifies reasoning limits in language models
Chunhui Zhang, Yiren Jian, Zhongyu Ouyang, and Soroush V osoughi. Working memory identifies reasoning limits in language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16896–16922, 2024
2024
-
[75]
A survey on the memory mechanism of large language model-based agents
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems, 43(6):1–47, 2025
2025
-
[76]
Zijia Zhao, Haoyu Lu, Yuqi Huo, Yifan Du, Tongtian Yue, Longteng Guo, Bingning Wang, Weipeng Chen, and Jing Liu. Needle in a video haystack: A scalable synthetic evaluator for video mllms.arXiv preprint arXiv:2406.09367, 2024
-
[77]
Lifelongagentbench: Evaluating llm agents as lifelong learners.arXiv preprint arXiv:2505.11942, 2025
Junhao Zheng, Xidi Cai, Qiuke Li, Duzhen Zhang, ZhongZhi Li, Yingying Zhang, Le Song, and Qianli Ma. Lifelongagentbench: Evaluating llm agents as lifelong learners.arXiv preprint arXiv:2505.11942, 2025
-
[78]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691–13701, 2025. 14
2025
-
[79]
Wenqi Zhou, Kai Cao, Hao Zheng, Yunze Liu, Xinyi Zheng, Miao Liu, Per Ola Kristensson, Walterio Mayol-Cuevas, Fan Zhang, Weizhe Lin, et al. X-lebench: A benchmark for extremely long egocentric video understanding.arXiv preprint arXiv:2501.06835, 2025
-
[80]
Nannan Zhu, Yonghao Dong, Teng Wang, Xueqian Li, Shengjun Deng, Yijia Wang, Zheng Hong, Tiantian Geng, Guo Niu, Hanyan Huang, et al. Cvbench: Evaluating cross-video synergies for complex multimodal understanding and reasoning.arXiv preprint arXiv:2508.19542, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.