From Failed Trajectories to Reliable LLM Agents: Diagnosing and Repairing Harness Flaws
Pith reviewed 2026-07-04 00:07 UTC · model grok-4.3
The pith
HarnessFix attributes agent failures to specific harness artifacts via normalized traces and generates targeted repairs that improve performance by 6.3% to 18.4%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
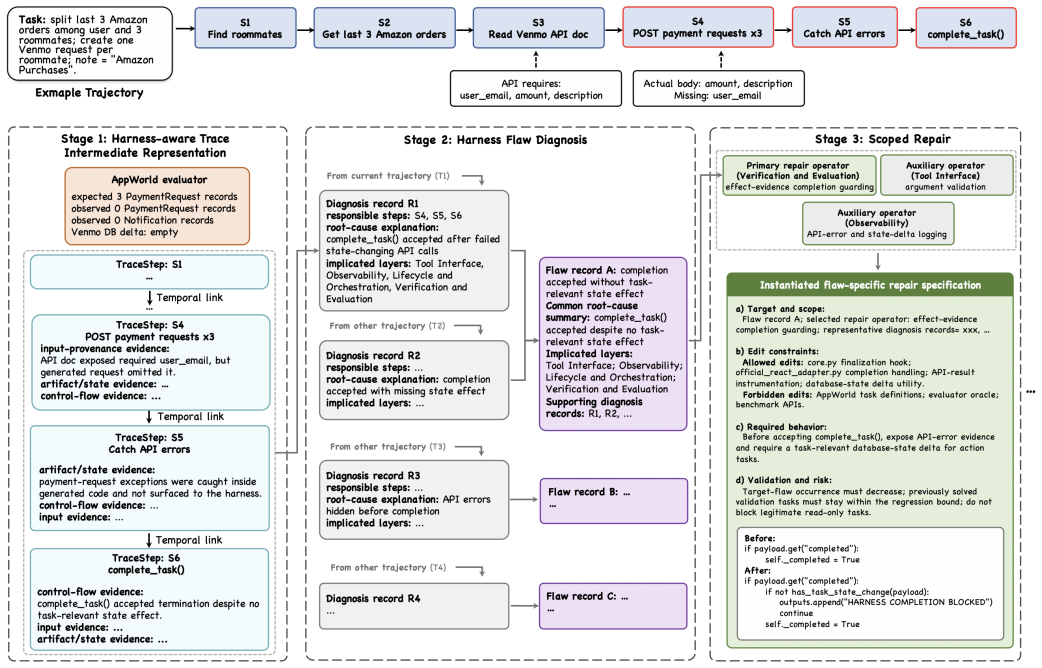
HarnessFix compiles raw execution traces and harness artifacts into HTIR, which normalizes fragmented trajectory evidence, captures step-level data-flow and control-flow relations, and aligns runtime steps with the harness artifacts that shape their behavior. It then attributes failures to responsible steps and harness artifacts, consolidates recurring diagnoses into repair-oriented flaw records, maps these records to scoped repair operators, generates patches under flaw-specific repair specifications, and accepts them through regression-aware validation.
What carries the argument
Harness-aware Trace Intermediate Representation (HTIR), which normalizes traces, captures data-flow and control-flow, and aligns steps with the harness artifacts that produced them.
If this is right
- Targeted, artifact-specific repairs outperform broad modifications derived from final outcomes alone.
- Failed trajectories supply structured evidence that can diagnose the mechanisms behind unreliable agent behavior.
- The same trace-to-repair pipeline applies across multiple agent benchmarks and harness implementations.
- Regression-aware validation prevents patches from degrading previously working functionality.
- Harness mechanisms can be iteratively refined by accumulating flaw records from many trajectories.
Where Pith is reading between the lines
- The same normalization and attribution approach could be tested on debugging harness-like layers in non-LLM systems such as workflow engines or robotic controllers.
- Flaw records might be reused across similar agents to build a shared library of common harness defects.
- An online version could monitor live traces and apply micro-patches without full re-evaluation.
- If attribution accuracy holds, the method offers a route to make agent improvement more interpretable than black-box prompt or workflow search.
Load-bearing premise
The HTIR attribution step identifies the harness artifact that is causally responsible for each failure rather than merely correlating with it.
What would settle it
A controlled test in which a repair generated from an attributed flaw produces no performance gain on the same benchmark while a different, non-attributed change does improve results.
Figures


read the original abstract
LLM agents increasingly rely on agent harness: the runtime infrastructure around the base model that defines execution environments, tool interfaces, context, lifecycle orchestration, observability, verification, and governance. Existing self-improving agents and automatic harness evolution methods mainly improve agents through runtime supervision, prompt optimization, workflow search, or harness modification based on final outcomes. However, they often fail to diagnose where the responsible evidence lies in failed trajectories and which harness implementation mechanism causes the unreliable behavior, resulting in broad, indirect, or poorly scoped changes. This paper proposes HarnessFix, a trace-grounded and diagnosis-driven framework for repairing agent harnesses. HarnessFix compiles raw execution traces and harness artifacts into a Harness-aware Trace Intermediate Representation (HTIR), which normalizes fragmented trajectory evidence, captures step-level data-flow and control-flow relations, and aligns runtime steps with the harness artifacts that shape their behavior. It then attributes failures to responsible steps and harness artifacts, and consolidates recurring diagnoses into repair-oriented flaw records. Finally, HarnessFix maps these records to scoped repair operators, generates patches under flaw-specific repair specifications, and accepts them through regression-aware validation. We evaluate HarnessFix on four popular benchmarks, and results show that it improves the performance over the initial harnesses by 6.3% to 18.4%, significantly outperforming human-designed and self-evolution baselines. HarnessFix highlights the value of treating failed trajectories not only as feedback signals, but also as structured evidence for diagnosing and repairing the harness mechanisms behind agent failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HarnessFix, a trace-grounded framework for repairing LLM agent harnesses. Raw execution traces and harness artifacts are compiled into a Harness-aware Trace Intermediate Representation (HTIR) that normalizes trajectories, captures data-flow and control-flow relations, and aligns steps with the harness artifacts shaping them. Failures are attributed to responsible steps and artifacts, consolidated into repair-oriented flaw records, and mapped to scoped repair operators that generate and validate patches. Evaluation on four benchmarks reports performance gains of 6.3% to 18.4% over initial harnesses, outperforming human-designed and self-evolution baselines.
Significance. If the attribution mechanism is shown to isolate causal harness artifacts and the performance gains prove robust under proper statistical controls, the work would offer a structured alternative to outcome-only optimization for improving LLM agent reliability.
major comments (2)
- [Abstract] Abstract: the central claim of 6.3%–18.4% improvement and outperformance of baselines is stated without any description of baseline implementations, statistical tests, error bars, or experimental protocol, rendering the quantitative result unevaluable.
- [Abstract] HTIR attribution step (as described in the abstract): the claim that HTIR 'attributes failures to responsible steps and harness artifacts' provides no interventions, counterfactuals, or ablation evidence to distinguish causal responsibility from observational co-occurrence or data-flow correlation; this is load-bearing for the subsequent flaw records and repair operators.
minor comments (1)
- [Abstract] The abstract does not name the four benchmarks used for evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 6.3%–18.4% improvement and outperformance of baselines is stated without any description of baseline implementations, statistical tests, error bars, or experimental protocol, rendering the quantitative result unevaluable.
Authors: We agree the abstract would benefit from additional context on the evaluation. The full manuscript (Section 4) specifies the four benchmarks, baseline implementations (human-designed harness modifications and self-evolution methods), and reports performance with comparisons. We will revise the abstract to briefly reference the experimental protocol and note that gains are measured against initial harnesses and baselines. revision: yes
-
Referee: [Abstract] HTIR attribution step (as described in the abstract): the claim that HTIR 'attributes failures to responsible steps and harness artifacts' provides no interventions, counterfactuals, or ablation evidence to distinguish causal responsibility from observational co-occurrence or data-flow correlation; this is load-bearing for the subsequent flaw records and repair operators.
Authors: HTIR attribution is based on explicit normalization of trajectories together with captured data-flow and control-flow relations that align steps to the harness artifacts shaping them; this supplies structural dependency chains rather than raw co-occurrence. While the current evaluation demonstrates end-to-end gains, we acknowledge the value of targeted validation for the attribution component. We will add an ablation isolating the attribution step in the revised manuscript. revision: partial
Circularity Check
No circularity: empirical framework evaluated on external benchmarks
full rationale
The paper describes an empirical framework (HarnessFix) that compiles traces into HTIR, attributes failures, and applies repair operators, with performance gains measured on four external benchmarks. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citation chains appear in the provided text. The central claims rest on observational alignment and benchmark results rather than any derivation that reduces to its own inputs by construction. This is the expected non-finding for a purely empirical systems paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
Think-Before-Speak: From Internal Evaluation to Public Expression in Multi-Agent Social Simulation
TBS is an interval-based multi-agent framework that separates private internal-state updates (dissonance appraisal, opinion climate, isolation risk, response strategy, willingness to speak) from public utterance selec...
-
Think-Before-Speak: From Internal Evaluation to Public Expression in Multi-Agent Social Simulation
TBS is an interval-based multi-agent LLM simulation framework that separates structured internal evaluative states from public utterance generation and shows these states vary systematically with turn-allocation, sile...
-
Cheap Code, Costly Judgment: A Case Study on Governable Agentic Software Engineering
A case study of AI-agentic software development yields a process model explaining how engineering judgment converts recurring structural failures into durable governance mechanisms.
Reference graph
Works this paper leans on
-
[1]
Agent harness engineering: A survey,
J. Li, X. Xiao, Y . Zhang, C. Liu, L. Zhao, X. Liao, Y . Ji, J. Wang, J. Gu, Y . Ge, W. Xu, X. Fang, X. Xu, T. Zhao, Y . Kim, T. Wang, J. Hamm, S. Krishnaswamy, J. Huan, and C. Reddy, “Agent harness engineering: A survey,” 2026. [Online]. Available: https://openreview.net/pdf?id=eONq7FdiHa
2026
-
[2]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inThe Twelfth International Conference on Learning Representations, 2024, oral presentation. [Online]. Available: https://openreview.net/forum?id=VTF8yNQM66
2024
-
[3]
SWE-bench Verified,
OpenAI, “SWE-bench Verified,” https://www.swebench.com/, 2024
2024
-
[4]
Terminal-Bench: Benchmarking agents on hard, realistic tasks in command line interfaces,
M. A. Merrillet al., “Terminal-Bench: Benchmarking agents on hard, realistic tasks in command line interfaces,” 2026
2026
-
[5]
GAIA: A benchmark for general AI assistants,
G. Mialonet al., “GAIA: A benchmark for general AI assistants,” 2023
2023
-
[6]
AppWorld: A controllable world of apps and people for benchmarking interactive coding agents,
H. Trivedi, T. Khot, M. Hartmann, R. Manku, V . Dong, E. Li, S. Gupta, A. Sabharwal, and N. Balasubramanian, “AppWorld: A controllable world of apps and people for benchmarking interactive coding agents,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024, pp. 16 022–16 076
2024
-
[7]
AgentDevel: Reframing Self-Evolving LLM Agents as Release Engineering,
D. Zhang, “AgentDevel: Reframing Self-Evolving LLM Agents as Release Engineering,” 2026. [Online]. Available: https://arxiv.org/abs/ 2601.04620
-
[8]
ReCreate: Reasoning and creating domain agents driven by experience,
Z. Hao, H. Wang, J. Luo, J. Zhang, Y . Zhou, Q. Lin, C. Wang, H. Dong, and J. Chen, “ReCreate: Reasoning and creating domain agents driven by experience,” inProceedings of the 64th Annual Meeting of the Association for Computational Linguistics, 2026
2026
-
[9]
Trajectory-informed memory generation for self- improving agent systems,
G. Fang, V . Isahagian, K. Jayaram, R. Kumar, V . Muthusamy, P. Oum, and G. Thomas, “Trajectory-informed memory generation for self- improving agent systems,”arXiv preprint arXiv:2603.10600, 2026
-
[10]
Which Agent causes task failures and when? on automated failure attribution of LLM Multi-Agent systems,
S. Zhang, M. Yin, J. Zhang, J. Liu, Z. Han, J. Zhang, B. Li, C. Wang, H. Wang, Y . Chen, and Q. Wu, “Which Agent causes task failures and when? on automated failure attribution of LLM Multi-Agent systems,” in Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025, pp. 1–12, spotlight paper
2025
-
[11]
Understanding Software Engineering Agents: A Study of Thought-Action-Result Trajectories,
I. Bouzenia and M. Pradel, “Understanding Software Engineering Agents: A Study of Thought-Action-Result Trajectories,” inProceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2025, pp. 1–12
2025
-
[12]
When Agents Fail: A Comprehensive Study of Bugs in LLM Agents with Automated Labeling
N. Islam, R. S. Ayon, D. G. Thomas, S. Ahmed, and M. Wardat, “When agents fail: A comprehensive study of bugs in llm agents with automated labeling,”arXiv preprint arXiv:2601.15232, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
A practical guide to building agents,
OpenAI, “A practical guide to building agents,” https://openai.com/ business/guides-and-resources/a-practical-guide-to-building-ai-agents/, 2025, accessed: 2026-05-09
2025
-
[14]
Effective context engineering for AI agents,
Anthropic, “Effective context engineering for AI agents,” https://www. anthropic.com/engineering/effective-context-engineering-for-ai-agents, Sep. 2025, accessed: 2026-04-30
2025
-
[15]
Automated breakpoint generation for debugging
C. Zhang, J. Yang, D. Yan, S. Yang, and Y . Chen, “Automated breakpoint generation for debugging.”J. Softw., vol. 8, no. 3, pp. 603–616, 2013
2013
-
[16]
Deterministic replay: A survey,
Y . Chen, S. Zhang, Q. Guo, L. Li, R. Wu, and T. Chen, “Deterministic replay: A survey,”ACM Computing Surveys (CSUR), vol. 48, no. 2, pp. 1–47, 2015
2015
-
[17]
Automatic software repair: A bibliography,
M. Monperrus, “Automatic software repair: A bibliography,”ACM Comput. Surv., vol. 51, no. 1, pp. 17:1–17:24, 2018. [Online]. Available: https://doi.org/10.1145/3105906
-
[18]
Impact of code language models on automated program repair,
C. S. Xia, Y . Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” in45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 2023, pp. 1482–1494. [Online]. Available: https://doi.org/10.1109/ICSE48619.2023.00129
-
[19]
Impact of code language models on automated program repair,
N. Jiang, K. Liu, T. Lutellier, and L. Tan, “Impact of code language models on automated program repair,” in45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 2023, pp. 1430–1442. [Online]. Available: https://doi.org/10.1109/ICSE48619.2023.00125
-
[20]
Improving the Efficiency of LLM Agent Systems through Trajectory Reduction,
Y .-A. Xiao, P. Gao, C. Peng, and Y . Xiong, “Improving the Efficiency of LLM Agent Systems through Trajectory Reduction,” 2025. [Online]. Available: https://arxiv.org/abs/2509.23586
-
[21]
Stop Wasting Your Tokens: Towards Efficient Runtime Multi-Agent Systems,
F. Lin, S. Chen, R. Fang, H. Wang, and T. Lin, “Stop Wasting Your Tokens: Towards Efficient Runtime Multi-Agent Systems,” 2025. [Online]. Available: https://arxiv.org/abs/2510.26585
-
[22]
Wink: Recovering from misbehaviors in coding agents,
R. Nanda, C. Maddila, S. Jha, E. M. Khan, M. Paltenghi, and S. Chandra, “Wink: Recovering from misbehaviors in coding agents,”arXiv preprint arXiv:2602.17037, 2026
-
[23]
Process-centric analysis of agentic software systems,
S. Liu, Y . Chen, R. Krishna, S. Sinha, J. Ganhotra, and R. Jabbarvand, “Process-centric analysis of agentic software systems,”Proceedings of the ACM on Programming Languages, vol. 10, no. OOPSLA1, pp. 1961– 1988, 2026
1961
-
[24]
Maestro: Joint Graph & Config Optimization for Reliable AI Agents,
W. Wang, P. Kattakinda, and S. Feizi, “Maestro: Joint Graph & Config Optimization for Reliable AI Agents,” 2025. [Online]. Available: https://arxiv.org/abs/2509.04642
-
[25]
Instruction-Level Weight Shaping: A Framework for Self-Improving AI Agents,
R. Costa, “Instruction-Level Weight Shaping: A Framework for Self-Improving AI Agents,” 2025. [Online]. Available: https://arxiv.org/ abs/2509.00251
-
[26]
SCOPE: Prompt evolution for enhancing agent effectiveness,
Z. Pei, H.-L. Zhen, S. Kai, S. J. Pan, Y . Wang, M. Yuan, and B. Yu, “SCOPE: Prompt evolution for enhancing agent effectiveness,” 2025
2025
-
[27]
Trace2Skill: Distill trajectory-local lessons into transferable agent skills,
J. Niet al., “Trace2Skill: Distill trajectory-local lessons into transferable agent skills,” 2026
2026
-
[28]
Effective harnesses for long-running agents,
Anthropic, “Effective harnesses for long-running agents,” https://www. anthropic.com/engineering/effective-harnesses-for-long-running-agents, 2025, accessed: 2026-05-09
2025
-
[29]
The long-horizon task mirage? diagnosing where and why agentic systems break,
X. J. Wang, H. Bai, Y . Sun, H. Wang, S. Zhang, W. Hu, M. Schroder, B. Mutlu, D. Song, and R. D. Nowak, “The long-horizon task mirage? diagnosing where and why agentic systems break,” 2026
2026
-
[30]
MiroThinker: Pushing the performance boundaries of open- source research agents via model, context, and interactive scaling,
MiroMind Team, S. Bai, L. Bing, C. Chen, G. Chen, Y . Chen, Z. Chen, Z. Chen, J. Dai, X. Dong, W. Dou, Y . Deng, Y . Fu, J. Ge, C. Han, T. Huang, Z. Huang, J. Jiao, S. Jiang, T. Jiao, X. Jian, L. Lei, R. Li, G. Luo, T. Li, X. Lin, Z. Liu, Z. Li, J. Ni, Q. Ren, P. Sun, S. Su, C. Tao, B. Wang, W. Wang, H. Wang, J. Wang, J. Wang, J. Wang, L. Wang, S. Wang, W...
2025
-
[31]
DeepResearchAgent: A hierarchical multi-agent framework for deep research,
Skywork AI, “DeepResearchAgent: A hierarchical multi-agent framework for deep research,” https://github.com/SkyworkAI/ DeepResearchAgent, 2025, accessed: 2026-05-30
2025
-
[32]
Open-source DeepResearch: Freeing our search agents,
A. Roucher, C. Fourrier, L. Tunstall, and L. von Werra, “Open-source DeepResearch: Freeing our search agents,” https://huggingface.co/blog/ open-deep-research, 2025, hugging Face blog; accessed 2026-05-30
2025
-
[33]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems, 2024. [Online]. Available: https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Harbor: A containerized framework for agent benchmarking,
Harbor Framework Contributors, “Harbor: A containerized framework for agent benchmarking,” https://github.com/harbor-framework/harbor, 2026, terminus-2 terminal-agent harness; accessed 2026-05-30
2026
-
[35]
MAESTRO: Multi-Agent Evaluation Suite for Testing, Reliability, and Observability,
T. Ma, Y . Chen, V . Anand, A. Cornacchia, A. R. Faustino, G. Liu, S. Zhang, H. Luo, S. A. Fahmy, Z. A. Qazi, and M. Canini, “MAESTRO: Multi-Agent Evaluation Suite for Testing, Reliability, and Observability,” 2026. [Online]. Available: https: //arxiv.org/abs/2601.00481
-
[36]
D. Guo, J. Wu, and S. M. Yiu, “Agenteval: Dag-structured step-level evaluation for agentic workflows with error propagation tracking,”arXiv preprint arXiv:2604.23581, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
GEPA: Reflective prompt evolution can outperform reinforcement learning,
L. A. Agrawal, S. Tan, D. Soylu, N. Ziems, R. Khare, K. Opsahl- Ong, A. Singhvi, H. Shandilya, M. J. Ryan, M. Jiang, C. Potts, K. Sen, A. G. Dimakis, I. Stoica, D. Klein, M. Zaharia, and O. Khattab, “GEPA: Reflective prompt evolution can outperform reinforcement learning,” inThe Fourteenth International Conference on Learning Representations, 2026, oral p...
2026
-
[38]
Gödel agent: A self-referential agent framework for recursively self-improvement,
X. Yin, X. Wang, L. Pan, L. Lin, X. Wan, and W. Y . Wang, “Gödel agent: A self-referential agent framework for recursively self-improvement,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics, 2025, pp. 27 890–27 913. [Online]. Avail...
2025
-
[39]
SICA: A self-improving coding agent,
M. Robeyns, M. Szummer, and L. Aitchison, “SICA: A self-improving coding agent,” inICLR 2025 Workshop on Scaling Self-Improving Foundation Models, 2025, oral presentation. [Online]. Available: https://openreview.net/forum?id=rShJCyLsOr
2025
-
[40]
Darwin gödel machine: Open-ended evolution of self-improving agents,
J. Zhang, S. Hu, C. Lu, R. T. Lange, and J. Clune, “Darwin gödel machine: Open-ended evolution of self-improving agents,” in The Fourteenth International Conference on Learning Representations, 2026, poster presentation. [Online]. Available: https://openreview.net/ forum?id=pUpzQZTvGY
2026
-
[41]
Huxley-gödel machine: Human-level coding agent development by an approximation of the optimal self- improving machine,
W. Wang, P. Pi˛ ekos, N. Li, F. Laakom, Y . Chen, M. Ostaszewski, M. Zhuge, and J. Schmidhuber, “Huxley-gödel machine: Human-level coding agent development by an approximation of the optimal self- improving machine,” inThe Fourteenth International Conference on Learning Representations, 2026, oral presentation. [Online]. Available: https://openreview.net/...
2026
-
[42]
mini-swe-agent: A minimal LLM agent for software engineering,
SWE-agent Contributors, “mini-swe-agent: A minimal LLM agent for software engineering,” https://github.com/SWE-agent/mini-swe-agent, 2024, accessed: 2026-05-30
2024
-
[43]
OpenHands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y . Shao, N. Muennighoff, Y . Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “OpenHands: An open platform for AI software developers as generalist agents,” inThe Thirteenth International Conference on Le...
2025
-
[44]
Trae Research Team, P. Gao, Z. Tian, X. Meng, X. Wang, R. Hu, Y . Xiao, Y . Liu, Z. Zhang, J. Chen, C. Gao, Y . Lin, Y . Xiong, C. Peng, and X. Liu, “Trae Agent: An LLM-based agent for software engineering with test-time scaling,” 2025. [Online]. Available: https://arxiv.org/abs/2507.23370
-
[45]
CUGA: A computer-using general- ist agent,
CUGA Project Contributors, “CUGA: A computer-using general- ist agent,” https://github.com/cuga-project/cuga-agent, 2025, accessed: 2026-05-30
2025
-
[46]
OpenCode: An open-source coding agent,
OpenCode Contributors, “OpenCode: An open-source coding agent,” https://github.com/anomalyco/opencode, 2024, accessed: 2026-05-30
2024
-
[47]
Meta- harness: End-to-end optimization of model harnesses,
Y . Lee, R. Nair, Q. Zhang, K. Lee, O. Khattab, and C. Finn, “Meta- harness: End-to-end optimization of model harnesses,” 2026
2026
-
[48]
From flat logs to causal graphs: Hierarchical failure attribution for llm-based multi-agent systems,
Y . Wang, W. Wu, J. Wang, and Q. Wang, “From flat logs to causal graphs: Hierarchical failure attribution for llm-based multi-agent systems,” 2026. [Online]. Available: https://arxiv.org/abs/2602.23701
-
[49]
DoVer: Intervention-Driven Auto Debugging for LLM Multi-Agent Systems,
M. Ma, J. Zhang, F. Yang, Y . Kang, Q. Lin, T. Yang, S. Rajmohan, and D. Zhang, “DoVer: Intervention-Driven Auto Debugging for LLM Multi-Agent Systems,” inProceedings of the 12th International Confer- ence on Learning Representations (ICLR), 2026, pp. 1–16
2026
-
[50]
Harness engineering: Leveraging Codex in an agent- first world,
R. Lopopolo, “Harness engineering: Leveraging Codex in an agent- first world,” https://openai.com/index/harness-engineering/, Feb. 2026, accessed: 2026-04-30
2026
-
[51]
Natural-language agent harnesses,
L. Pan, L. Zou, S. Guo, J. Ni, and H.-T. Zheng, “Natural-language agent harnesses,” 2026
2026
-
[52]
Synthesizing multi-agent harnesses for vulnerability discovery,
H. Liu, C. Shou, X. Liu, H. Wen, Y . Chen, R. J. Fang, and Y . Feng, “Synthesizing multi-agent harnesses for vulnerability discovery,” 2026
2026
-
[53]
AutoHarness: Improving LLM agents by automatically synthesizing a code harness,
X. Lou, M. Lázaro-Gredilla, A. Dedieu, C. Wendelken, W. Lehrach, and K. P. Murphy, “AutoHarness: Improving LLM agents by automatically synthesizing a code harness,” 2026
2026
-
[54]
Agentic harness engineering: Observability- driven automatic evolution of coding-agent harnesses,
J. Lin, S. Liu, C. Pan, L. Lin, S. Dou, Z. Xi, X. Huang, H. Yan, Z. Han, T. Gui, and Y .-G. Jiang, “Agentic harness engineering: Observability- driven automatic evolution of coding-agent harnesses,” 2026
2026
-
[55]
Automated design of agentic systems,
S. Hu, C. Lu, and J. Clune, “Automated design of agentic systems,” in The Thirteenth International Conference on Learning Representations, 2025
2025
-
[56]
AFlow: Automating agentic workflow generation,
J. Zhanget al., “AFlow: Automating agentic workflow generation,” in The Thirteenth International Conference on Learning Representations, 2025, oral presentation. [Online]. Available: https://openreview.net/ forum?id=z5uV AKwmjf
2025
-
[57]
AutoFlow: Automated workflow generation for large language model agents,
Z. Liet al., “AutoFlow: Automated workflow generation for large language model agents,” 2024
2024
-
[58]
AgentSquare: Automatic LLM agent search in modular design space,
Y . Shang, Y . Li, K. Zhao, L. Ma, J. Liu, F. Xu, and Y . Li, “AgentSquare: Automatic LLM agent search in modular design space,” 2024
2024
-
[59]
MaAS: Multi-agent architecture search via agentic supernet,
G. Zhang, L. Niu, J. Fang, K. Wang, L. Bai, and X. Wang, “MaAS: Multi-agent architecture search via agentic supernet,” inProceedings of the 42nd International Conference on Machine Learning, 2025. [Online]. Available: https://arxiv.org/abs/2502.04180
-
[60]
Large language models as tool makers,
T. Cai, X. Wang, T. Ma, X. Chen, and D. Zhou, “Large language models as tool makers,” inThe Twelfth International Conference on Learning Representations, 2024, poster presentation. [Online]. Available: https://openreview.net/forum?id=qV83K9d5WB
2024
-
[61]
CREATOR: Tool creation for disentangling abstract and concrete reasoning of large language models,
C. Qian, C. Han, Y . R. Fung, Y . Qin, Z. Liu, and H. Ji, “CREATOR: Tool creation for disentangling abstract and concrete reasoning of large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023. [Online]. Available: https://aclanthology.org/2023.findings-emnlp.462/
2023
-
[62]
ToolGen: Unified tool retrieval and calling via generation,
R. Wang, X. Han, L. Ji, S. Wang, T. Baldwin, and H. Li, “ToolGen: Unified tool retrieval and calling via generation,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[63]
SkillForge: Forging domain-specific, self-evolving agent skills in cloud technical support,
X. Liu, X. Luo, L. Li, G. Huang, J. Liu, and H. Qiao, “SkillForge: Forging domain-specific, self-evolving agent skills in cloud technical support,” inProceedings of the 49th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2026, industry Track. [Online]. Available: https://arxiv.org/abs/2604. 08618
2026
-
[64]
Agent workflow memory,
Z. Z. Wang, J. Mao, D. Fried, and G. Neubig, “Agent workflow memory,” 2024
2024
-
[65]
Agent KB: Leveraging cross-domain experience for agentic problem solving,
X. Tanget al., “Agent KB: Leveraging cross-domain experience for agentic problem solving,” 2025
2025
-
[66]
A-MEM: Agentic memory for LLM agents,
W. Xuet al., “A-MEM: Agentic memory for LLM agents,” 2025
2025
-
[67]
MemInsight: Autonomous memory augmentation for LLM agents,
R. Salamaet al., “MemInsight: Autonomous memory augmentation for LLM agents,” 2025
2025
-
[68]
Agentic context engineering: Evolving contexts for self-improving language models,
Q. Zhang, C. Hu, S. Upasani, B. Ma, F. Hong, V . Kamanuru, J. Rainton, C. Wu, M. Ji, H. Li, U. Thakker, J. Zou, and K. Olukotun, “Agentic context engineering: Evolving contexts for self-improving language models,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=eC4ygDs02R
2026
-
[69]
Group-evolving agents: Open-ended self-improvement via experience sharing,
Z. Weng, A. Antoniades, D. Nathani, Z. Zhang, X. Pu, and X. E. Wang, “Group-evolving agents: Open-ended self-improvement via experience sharing,” 2026
2026
-
[70]
Self-evolving multi-agent collaboration networks for software development,
Y . Hu, Y . Cai, Y . Du, X. Zhu, X. Liu, Z. Yu, Y . Hou, S. Tang, and S. Chen, “Self-evolving multi-agent collaboration networks for software development,” 2024
2024
-
[71]
Autogenesis: A self-evolving agent protocol,
SkyworkAI, “Autogenesis: A self-evolving agent protocol,” 2026
2026
-
[72]
EvoTest: Evolutionary test-time learning for self-improving agentic systems,
Y . He, J. Liu, Y . Liu, Y . Li, T. Cao, Z. Hu, X. Xu, and B. Hooi, “EvoTest: Evolutionary test-time learning for self-improving agentic systems,” in The Fourteenth International Conference on Learning Representations,
-
[73]
EvoTest: Evolutionary Test-Time Learning for Self-Improving Agentic Systems
[Online]. Available: https://arxiv.org/abs/2510.13220
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Inference-time scaling of verification: Self-evolving deep research agents via test-time rubric-guided verification,
Y . Wan, T. Fang, Z. Li, Y . Huo, W. Wang, H. Mi, D. Yu, and M. R. Lyu, “Inference-time scaling of verification: Self-evolving deep research agents via test-time rubric-guided verification,” 2026
2026
-
[75]
A survey for llm agent trajectory analysis: From failure attribution to enhancement,
J. Wang, Y . Wang, M. Chen, X. Xie, C. Chen, F. Mu, Z. Liu, and Q. Wang, “A survey for llm agent trajectory analysis: From failure attribution to enhancement,” 2026
2026
-
[76]
SWE-TRACE: Optimizing long-horizon SWE agents through rubric process reward models and heuristic test-time scaling,
H. Hanet al., “SWE-TRACE: Optimizing long-horizon SWE agents through rubric process reward models and heuristic test-time scaling,” 2026
2026
-
[77]
View-oriented conversation compiler for agent trace analysis,
L. Zhang and M. Agrawala, “View-oriented conversation compiler for agent trace analysis,” 2026
2026
-
[78]
Beyond resolution rates: Behavioral drivers of coding agent success and failure,
T. Mehtiyev and W. Assunção, “Beyond resolution rates: Behavioral drivers of coding agent success and failure,” 2026
2026
-
[79]
Who is Introducing the Failure? Automatically Attributing Failures of Multi-Agent Systems via Spectrum Analysis,
Y . Ge, L. Xie, Z. Li, Y . Pei, and T. Zhang, “Who is Introducing the Failure? Automatically Attributing Failures of Multi-Agent Systems via Spectrum Analysis,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2026, pp. 1–12
2026
-
[80]
Agen- Tracer: Who is inducing failure in the LLM agentic systems?
G. Zhang, J. Wang, J. Chen, W. Zhou, K. Wang, and S. Yan, “Agen- Tracer: Who is inducing failure in the LLM agentic systems?” 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.