Textual Supervision Enhances Geospatial Representations in Vision-Language Models
Pith reviewed 2026-06-27 22:04 UTC · model grok-4.3
The pith
Textual supervision improves how vision models learn to represent locations in images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
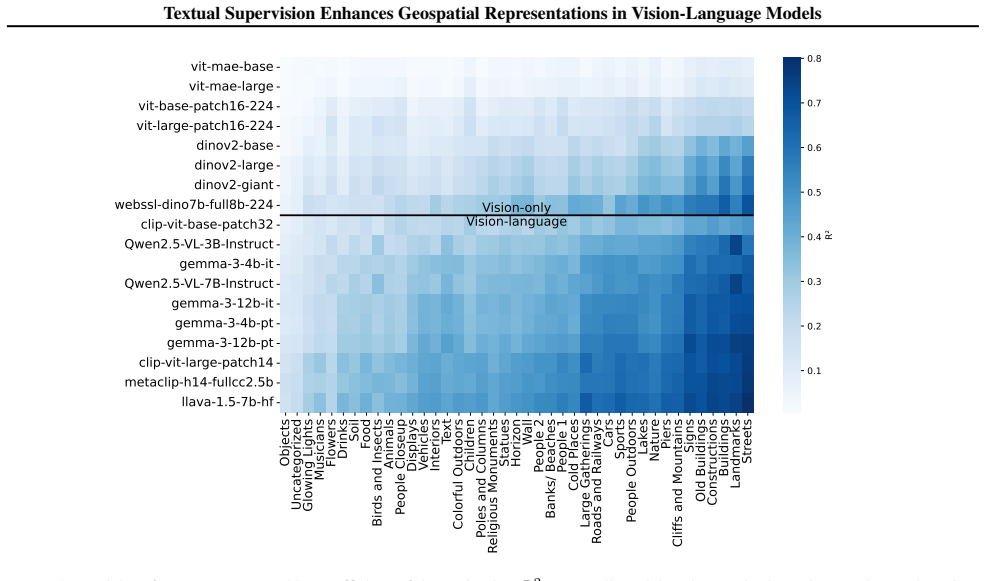
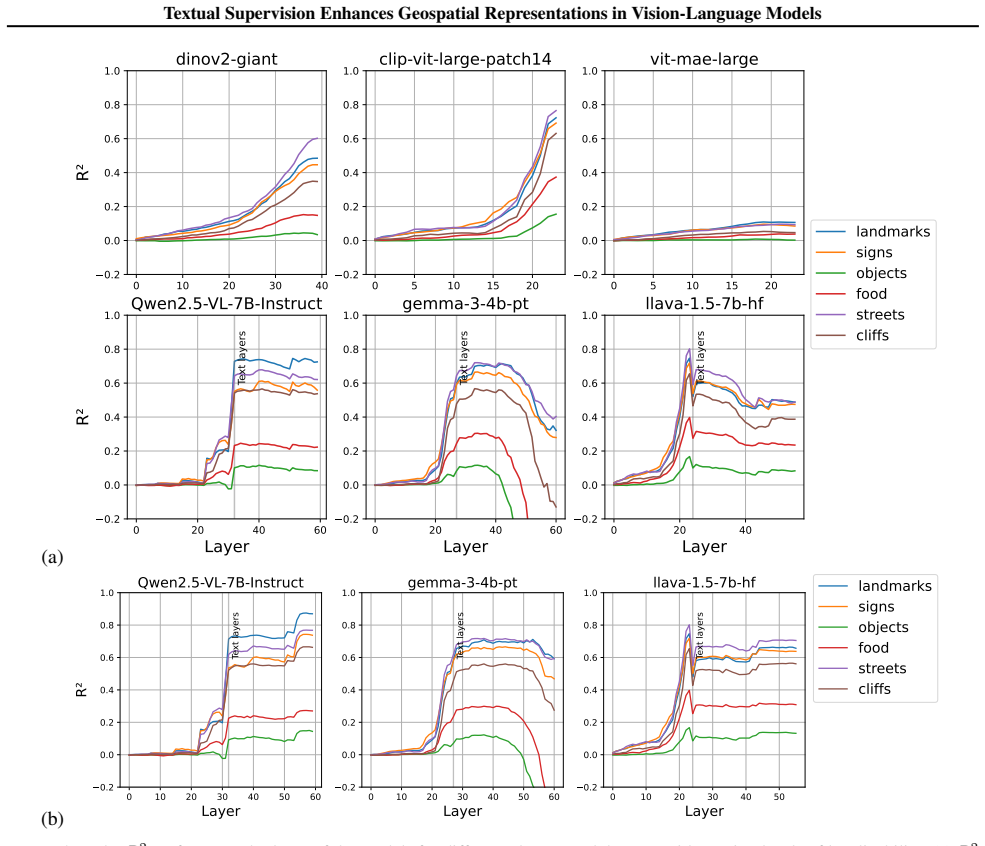
Vision-language models acquire stronger geospatial representations than vision-only architectures, and large-scale multimodal foundation models show further gains; this pattern demonstrates that textual supervision functions as an effective complementary modality for encoding spatial context during learning.
What carries the argument
Evaluation across image clusters grouped by degree of localizability, which isolates how well each model family infers location from visual content alone.
If this is right
- Vision-language models consistently outperform vision-only models on spatial accuracy across all localizability groups.
- Larger multimodal foundation models extend the gains from textual supervision.
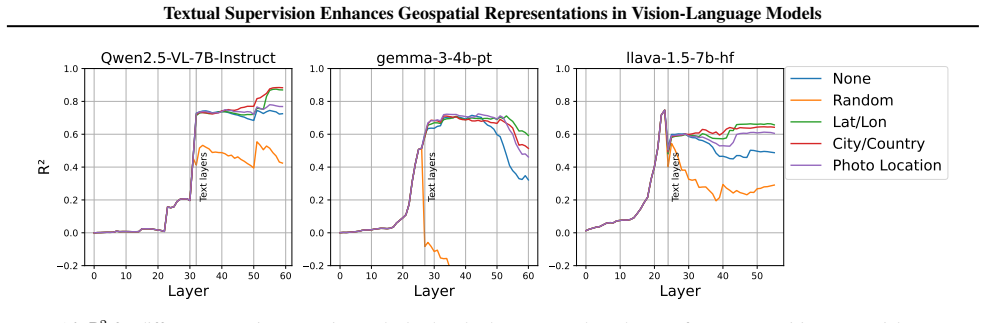
- Language serves as a complementary signal that helps encode spatial information not fully captured by pixels alone.
- Multimodal training constitutes a productive direction for improving geospatial capabilities in AI systems.
Where Pith is reading between the lines
- Training pipelines that pair images with descriptive text may prove especially useful for downstream tasks requiring location inference.
- The same textual supervision mechanism could be tested on other spatial domains such as indoor navigation or satellite imagery analysis.
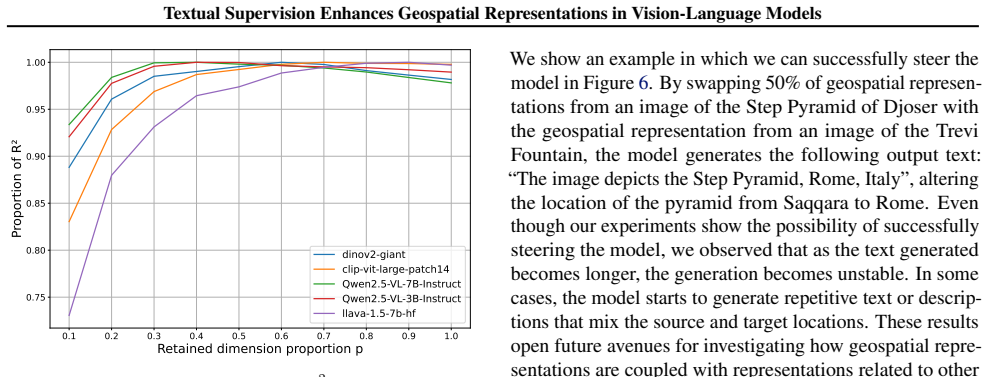
- If language helps with geospatial encoding, similar benefits might appear in related multimodal problems that involve relational reasoning over scenes.
Load-bearing premise
The chosen image clusters and their localizability grouping measure genuine differences in geospatial understanding rather than artifacts of training data or evaluation setup.
What would settle it
A controlled comparison in which a vision-only model trained on identical data and scale as a vision-language model matches or exceeds it on the localizability-grouped clusters would falsify the enhancement claim.
Figures














read the original abstract
Geospatial understanding is a critical yet underexplored dimension in the development of machine learning systems for tasks such as image geolocation and spatial reasoning. In this work, we analyze the geospatial representations acquired by three model families: vision-only architectures (e.g., ViT), vision-language models (e.g., CLIP), and large-scale multimodal foundation models (e.g., LLaVA, Qwen, and Gemma). By evaluating across image clusters, including people, landmarks, and everyday objects, grouped based on the degree of localizability, we reveal systematic gaps in spatial accuracy and show that textual supervision enhances the learning of geospatial representations. Our findings suggest the role of language as an effective complementary modality for encoding spatial context and multimodal learning as a key direction for advancing geospatial AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that textual supervision enhances geospatial representations in vision-language models. It supports this by comparing three model families—vision-only (e.g., ViT), vision-language (e.g., CLIP), and large-scale multimodal (e.g., LLaVA, Qwen, Gemma)—on image clusters (people, landmarks, everyday objects) grouped by localizability, revealing systematic gaps in spatial accuracy that are attributed to the presence of language supervision.
Significance. If substantiated, the finding would highlight language as a complementary modality for encoding spatial context and position multimodal learning as important for geospatial AI tasks such as image geolocation. The work identifies an underexplored dimension and suggests a concrete direction for model development.
major comments (2)
- [Abstract] The central claim attributes performance differences to textual supervision, yet the model families compared (ViT vs. CLIP vs. LLaVA/Qwen/Gemma) differ in parameter count, pretraining data volume/diversity, and objectives beyond language; no controlled ablations that hold vision backbone, data, and scale fixed while varying only textual supervision are described. This confound is load-bearing for the attribution.
- [Abstract] The localizability grouping of clusters (people, landmarks, objects) is presented as a measure of geospatial understanding, but no analysis addresses whether this grouping itself reflects training-data biases rather than intrinsic spatial capability; the abstract provides no quantitative results, metrics, error bars, or statistical tests to support the reported systematic gaps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to address these important points. We provide point-by-point responses below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The central claim attributes performance differences to textual supervision, yet the model families compared (ViT vs. CLIP vs. LLaVA/Qwen/Gemma) differ in parameter count, pretraining data volume/diversity, and objectives beyond language; no controlled ablations that hold vision backbone, data, and scale fixed while varying only textual supervision are described. This confound is load-bearing for the attribution.
Authors: We acknowledge that the manuscript compares representative models from established families rather than conducting controlled ablations that fix the vision backbone, dataset, and scale while varying only the presence of textual supervision. The comparisons reflect real-world model families to illustrate observed trends in geospatial accuracy. We will add an explicit discussion of these confounds, including a limitations paragraph noting that factors such as scale and data diversity may contribute to the differences, while emphasizing that the consistent pattern across families still supports the role of language supervision as a complementary signal. revision: partial
-
Referee: [Abstract] The localizability grouping of clusters (people, landmarks, objects) is presented as a measure of geospatial understanding, but no analysis addresses whether this grouping itself reflects training-data biases rather than intrinsic spatial capability; the abstract provides no quantitative results, metrics, error bars, or statistical tests to support the reported systematic gaps.
Authors: The grouping is derived from the intrinsic properties of the depicted content (e.g., landmarks permit precise localization while people and generic objects do not). We agree that potential alignment with training-data biases was not explicitly analyzed and will add a short subsection examining this possibility, for instance by checking overlap with common pretraining corpora. We will also revise the abstract to include key quantitative metrics, error bars, and references to the statistical tests used to establish the systematic gaps. revision: yes
Circularity Check
No circularity: empirical model comparison with independent evaluation
full rationale
The paper is a purely empirical study comparing vision-only, vision-language, and multimodal models on geospatial tasks using image clusters grouped by localizability. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on observed performance gaps rather than reducing to inputs by construction. External benchmarks (model families) are treated as given, with no self-definitional loops or ansatz smuggling. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Demystifying
Xu, Hu and Xie, Saining and Tan, Xiaoqing Ellen and Huang, Po-Yao and Howes, Russell and Sharma, Vasu and Li, Shang-Wen and Ghosh, Gargi and Zettlemoyer, Luke and Feichtenhofer, Christoph , booktitle=. Demystifying
-
[5]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Fan, David and Tong, Shengbang and Zhu, Jiachen and Sinha, Koustuv and Liu, Zhuang and Chen, Xinlei and Rabbat, Michael and Ballas, Nicolas and LeCun, Yann and Bar, Amir and Xie, Saining , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[6]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle=
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[12]
arXiv preprint arXiv:2503.19786 , year=
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
-
[13]
arXiv preprint arXiv:2212.06727 , year=
What do vision transformers learn? a visual exploration , author=. arXiv preprint arXiv:2212.06727 , year=
-
[14]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[15]
Transactions on Machine Learning Research , issn=
Maxime Oquab and Timoth. Transactions on Machine Learning Research , issn=
-
[16]
Transactions on Machine Learning Research , issn=
Oriane Sim. Transactions on Machine Learning Research , issn=
-
[17]
Zhou, Jinghao and Wei, Chen and Wang, Huiyu and Shen, Wei and Xie, Cihang and Yuille, Alan and Kong, Tao , booktitle=. Image
-
[18]
Advances in Neural Information Processing Systems , volume=
Visual instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
5-vl technical report , author=
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[20]
2024 , booktitle=
Language Models Represent Space and Time , author=. 2024 , booktitle=
2024
-
[21]
Charting new territories: Exploring the geographic and geospatial capabilities of multimodal
Roberts, Jonathan and L. Charting new territories: Exploring the geographic and geospatial capabilities of multimodal. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
Vivanco Cepeda, Vicente and Nayak, Gaurav Kumar and Shah, Mubarak , journal=
-
[23]
The Thirteenth International Conference on Learning Representations , year=
Linear Representations of Political Perspective Emerge in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[24]
2017 , journal=
Understanding intermediate layers using linear classifier probes , author=. 2017 , journal=
2017
-
[25]
2016 , publisher=
Thomee, Bart and Shamma, David A and Friedland, Gerald and Elizalde, Benjamin and Ni, Karl and Poland, Douglas and Borth, Damian and Li, Li-Jia , journal=. 2016 , publisher=
2016
-
[26]
2009 , organization=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle=. 2009 , organization=
2009
-
[27]
Psychometrika , volume=
Who belongs in the family? , author=. Psychometrika , volume=. 1953 , publisher=
1953
-
[28]
2016 , organization=
Weyand, Tobias and Kostrikov, Ilya and Philbin, James , booktitle=. 2016 , organization=
2016
-
[29]
Haas, Lukas and Skreta, Michal and Alberti, Silas and Finn, Chelsea , booktitle=
-
[30]
, booktitle=
Hays, James and Efros, Alexei A. , booktitle=. 2008 , volume=
2008
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
arXiv preprint arXiv:1409.1556 , year=
Very deep convolutional networks for large-scale image recognition , author=. arXiv preprint arXiv:1409.1556 , year=
-
[33]
Technometrics , volume=
Generalized Cross-Validation as a Method for Choosing a Good Ridge Parameter , author=. Technometrics , volume=. 1979 , publisher=
1979
-
[34]
2011 , isbn =
Han, Jiawei and Kamber, Micheline and Pei, Jian , title =. 2011 , isbn =
2011
-
[35]
Moayeri, Mazda and Tabassi, Elham and Feizi, Soheil , booktitle=
-
[36]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
On the Scaling Laws of Geographical Representation in Language Models , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Geolocation Representation from Large Language Models are Generic Enhancers for Spatio-Temporal Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
MediaEval Benchmarking Initiative for Multimedia Evaluation , year=
The Placing Task at MediaEval 2016 , author=. MediaEval Benchmarking Initiative for Multimedia Evaluation , year=
2016
-
[39]
McInnes, Leland and Healy, John and Melville, James , journal=
-
[40]
Wu, Nemin and Cao, Qian and Wang, Zhangyu and Liu, Zeping and Qi, Yanlin and Zhang, Jielu and Ni, Joshua and Yao, Xiaobai and Ma, Hongxu and Mu, Lan and others , journal=
-
[41]
International Conference on Machine Learning , year=
Position: The Platonic Representation Hypothesis , author=. International Conference on Machine Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.