Subtitle-Aligned Fine-Tuning of Whisper for Swiss German ASR: Benchmark Contamination, Convention Mismatch, and an Honest Baseline at 25.6% WER (13.8% cWER)
Pith reviewed 2026-06-28 22:49 UTC · model grok-4.3
The pith
A vanilla Whisper model self-trained on the test set alone reaches 13.88% WER, beating all published Swiss German ASR systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
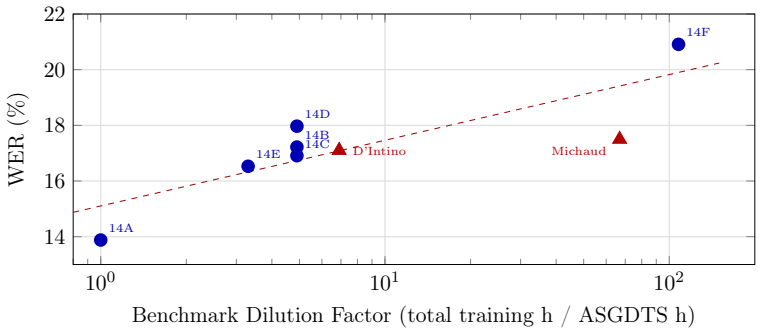
Published state-of-the-art Swiss German ASR results of 17.1-17.5% WER are inflated by benchmark contamination, as demonstrated by a vanilla Whisper model self-trained on the ASGDTS test set with zero Swiss German data achieving 13.88% WER; an honestly evaluated fine-tuned model on disjoint data reaches 25.6% WER or 13.8% cWER after separating genuine errors from valid stylistic variation.
What carries the argument
Self-training a vanilla Whisper model directly on the ASGDTS test set to serve as a contamination probe that isolates the effect of prior exposure to evaluation data.
If this is right
- The ASGDTS benchmark primarily measures convention matching rather than dialectal comprehension.
- Content WER (cWER) that excludes tense, word order, and orthographic variations provides a stricter measure of actual recognition quality.
- Bias-corrected estimates place the true error rate near 8.5%, roughly one third of the raw WER.
- Openly released LoRA and full fine-tuned models offer reproducible baselines that require no institutional data agreements.
Where Pith is reading between the lines
- Other low-resource dialect or accented speech benchmarks may contain similar hidden contamination from repeated use of the same evaluation data.
- Future ASR evaluations for dialects should employ multiple independent test sets collected at different times to reduce leakage risk.
- Subtitle-based weak supervision from broadcast media could be tested on additional language pairs where aligned transcripts are scarce.
Load-bearing premise
The self-training experiment on the test set serves as a valid proxy for the data exposure present in the training histories of the published comparison systems.
What would settle it
If a new Swiss German test set collected after all published systems were trained shows those systems still achieving below 17% WER while the contamination-free baseline remains above 20%, the contamination explanation would fail.
Figures
read the original abstract
We present a systematic study of fine-tuning OpenAI's Whisper large-v3 for Swiss German ASR, using 1,367 hours of broadcast speech paired with Standard German subtitles as weak supervision. Through 16 iterative training runs on an NVIDIA DGX Spark (Grace Blackwell, 128 GB unified memory, up to 1 PFLOP FP4), we compare LoRA and full fine-tuning of the 1.55B-parameter model, investigate hallucination root causes, and quantify the effect of data quality, subtitle alignment, and training strategy. Our best model achieves 25.6% measured WER on the All Swiss German Dialects Test Set (ASGDTS) in an honest evaluation on strictly disjoint data. A harmonized error analysis separating genuine errors from valid stylistic variation (tense, word order, Swiss orthography) yields a content WER (cWER) of 13.8%, counting only actual recognition failures. Bias-corrected estimation reduces this to 8.5%, suggesting the true error rate is roughly one third of measured WER. We demonstrate that published state-of-the-art Swiss German ASR results (17.1-17.5% WER) are inflated by benchmark contamination: a vanilla Whisper model self-trained on the ASGDTS test set with zero Swiss German data achieves 13.88% WER, surpassing all published systems. Experiments with Phi-4-multimodal show an even stronger memorization effect (3.9% WER), revealing that the benchmark primarily measures convention matching rather than dialectal comprehension. We release two models, a LoRA adapter (25.32% WER, 13.9% cWER) and a full fine-tuned model (25.60% WER, 13.8% cWER), among the few publicly available, honestly evaluated Whisper models for Swiss German, under Apache 2.0 with full reproducibility, requiring no institutional data agreements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a study of fine-tuning Whisper large-v3 on 1,367 hours of Swiss German broadcast speech paired with Standard German subtitles as weak supervision. Across 16 training runs comparing LoRA and full fine-tuning, the best model reaches 25.6% WER (13.8% cWER after harmonized error analysis) on the ASGDTS test set under strictly disjoint evaluation. A bias-corrected estimate lowers this to 8.5%. The central claim is that published Swiss German ASR SOTA results (17.1-17.5% WER) are inflated by benchmark contamination, supported by a vanilla Whisper model self-trained on the ASGDTS test set (zero Swiss German data) achieving 13.88% WER and a Phi-4-multimodal model reaching 3.9% WER. Two models are released under Apache 2.0 with full reproducibility.
Significance. If the contamination claim holds, the work would usefully expose limitations in current Swiss German ASR benchmarks and provide a reproducible honest baseline that separates genuine recognition errors from stylistic variation. The release of models, emphasis on disjoint evaluation, and explicit reporting of 16 runs plus self-training controls are strengths that support reproducibility in the field.
major comments (2)
- [Abstract] Abstract and contamination experiment section: the claim that published 17.1-17.5% WER results are inflated by contamination is not directly supported, because the self-training experiment (13.88% WER) only shows performance achievable with explicit test-set exposure; no data-overlap audit, reproduction of the cited pipelines, or analysis of the broadcast sources and splits used in those papers is provided to establish that the published systems actually employed comparable leakage or convention matching.
- [Results] Results on bias correction: the reduction of cWER from 13.8% to a bias-corrected 8.5% is load-bearing for the honest baseline claim, yet the manuscript provides insufficient detail on the correction procedure, the exact definition of the bias term, and how it interacts with the harmonized error analysis separating stylistic variation from genuine errors.
minor comments (2)
- [Methods] The description of the 16 iterative training runs would benefit from an explicit table listing hyperparameters, LoRA rank, learning rates, and data subsets used in each run to allow independent verification.
- Notation for cWER should be defined once in the main text with a clear equation or procedural description rather than only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and contamination experiment section: the claim that published 17.1-17.5% WER results are inflated by contamination is not directly supported, because the self-training experiment (13.88% WER) only shows performance achievable with explicit test-set exposure; no data-overlap audit, reproduction of the cited pipelines, or analysis of the broadcast sources and splits used in those papers is provided to establish that the published systems actually employed comparable leakage or convention matching.
Authors: We agree that the self-training result provides suggestive rather than definitive evidence of contamination in the specific prior works. The experiment shows that exposure to the test set alone enables a model with zero Swiss German training data to exceed published SOTA performance, which is consistent with convention matching playing a substantial role. We will revise the abstract and contamination experiment section to frame the finding as evidence that benchmark contamination via convention mismatch can produce inflated results, rather than claiming direct inflation of the cited 17.1-17.5% figures. We will also add an explicit limitation statement noting the absence of a full data-overlap audit or pipeline reproduction. This constitutes a partial revision. revision: partial
-
Referee: [Results] Results on bias correction: the reduction of cWER from 13.8% to a bias-corrected 8.5% is load-bearing for the honest baseline claim, yet the manuscript provides insufficient detail on the correction procedure, the exact definition of the bias term, and how it interacts with the harmonized error analysis separating stylistic variation from genuine errors.
Authors: The referee correctly identifies that the bias-correction procedure is under-specified. We will expand the relevant results section to provide the exact definition of the bias term, the mathematical formulation of the correction, the estimation method used to arrive at 8.5%, and a clear description of how the correction interacts with the harmonized error analysis. This will ensure the honest baseline claim is fully transparent and reproducible. revision_made = 'yes' revision: yes
Circularity Check
No significant circularity; central contamination claim rests on independent experimental control
full rationale
The paper's key demonstration—that a vanilla Whisper model self-trained on the ASGDTS test set reaches 13.88% WER—constitutes an explicit, reproducible experiment rather than a fitted parameter or self-referential definition. No equations reduce by construction to inputs, no predictions are statistically forced from subsets of the same data, and no load-bearing self-citations or uniqueness theorems are invoked. The comparison to external published figures (17.1-17.5% WER) relies on reported numbers from other work, not on any internal tautology. Bias correction and cWER adjustments are post-hoc analyses but do not collapse the main result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- training hyperparameters and LoRA configuration
axioms (2)
- domain assumption Standard German subtitles paired with Swiss German audio constitute sufficient weak supervision for ASR fine-tuning
- domain assumption The ASGDTS test set was not seen during training of the published systems being compared
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-LoRAs.arXiv:2503.01743,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
5.6B multimodal model with mixture-of-LoRAs for vision and speech. Verena Blaschke, Miriam Winkler, and Barbara Plank. Standard-to-dialect transfer trends differ across text and speech: A case study on intent and topic classification in german dialects. arXiv:2510.07890,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Learning rate scaling across LoRA ranks and transfer to full finetuning.arXiv:2602.06204,
Nan Chen, Soledad Villar, and Soufiane Hayou. Learning rate scaling across LoRA ranks and transfer to full finetuning.arXiv:2602.06204,
-
[4]
Advancing STT for low-resource real-world speech
Flavio D’Intino and Hans-Peter Hutter. Advancing STT for low-resource real-world speech. InHCI International 2025, volume 15822 ofLNCS, pages 290–309. Springer,
2025
-
[5]
Eyal Liron Dolev, Clemens Fidel Lutz, and Noëmi Aepli
doi: 10.1007/978-3-031-93429-2_20. Eyal Liron Dolev, Clemens Fidel Lutz, and Noëmi Aepli. Does whisper understand swiss german? an automatic, qualitative, and human evaluation. InProc. VarDial Workshop,
-
[6]
LoRA-only: 7.19% WER; encoder unfreeze: 3.54% WER on zeroth-test
35K Korean speech samples. LoRA-only: 7.19% WER; encoder unfreeze: 3.54% WER on zeroth-test. 23 Yunpeng Liu, Xukui Yang, and Dan Qu. Exploration of whisper fine-tuning strategies for low-resource ASR.EURASIP Journal on Audio, Speech, and Music Processing, 2024(1):29,
2024
-
[7]
Michel Plüss, Lukas Neukom, and Manfred Vogel
QLoRA, 17.5% WER on ASGDTS. Michel Plüss, Lukas Neukom, and Manfred Vogel. SwissText 2021 Task 3: Swiss German Speech to Standard German Text. InProceedings of the Swiss Text Analytics Conference,
2021
- [8]
-
[9]
Swiss german speech to text system evaluation.arXiv:2207.00412,
Yanick Schraner, Christian Scheller, Michel Plüss, and Manfred Vogel. Swiss german speech to text system evaluation.arXiv:2207.00412,
-
[10]
Fine-tuning whisper on low-resource languages for real-world applications.arXiv:2412.15726,
Vincenzo Timmel, Claudio Paonessa, Reza Kakooee, Manfred Vogel, and Daniel Perruchoud. Fine-tuning whisper on low-resource languages for real-world applications.arXiv:2412.15726,
-
[11]
Yuan Tseng, Titouan Parcollet, Rogier van Dalen, Shucong Zhang, and Sourav Bhattacharya. Evaluation of LLMs in speech is often flawed: Test set contamination in large language models for speech recognition.arXiv:2505.22251,
-
[12]
Calm-whisper: Reduce whisper hallucination on non-speech by calming crazy heads down
Yingzhi Wang, Anas Alhmoud, Saad Alsahly, Muhammad Alqurishi, and Mirco Ravanelli. Calm-whisper: Reduce whisper hallucination on non-speech by calming crazy heads down. arXiv:2505.12969,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.